Coverage-Guided Fuzzing of Grpc Interface
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Dynamic Optimization of IA-32 Applications Under Dynamorio by Timothy Garnett
Dynamic Optimization of IA-32 Applications Under DynamoRIO by Timothy Garnett Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the Degree of Master of Engineering in Computer Science Abstract The ability of compilers to optimize programs statically is diminishing. The advent and increased use of shared libraries, dynamic class loading, and runtime binding means that the compiler has, even with difficult to accurately obtain profiling data, less and less knowledge of the runtime state of the program. Dynamic optimization systems attempt to fill this gap by providing the ability to optimize the application at runtime when more of the system's state is known and very accurate profiling data can be obtained. This thesis presents two uses of the DynamoRIO runtime introspection and modification system to optimize applications at runtime. The first is a series of optimizations for interpreters running under DynamoRIO's logical program counter extension. The optimizations include extensions to DynamoRIO to allow the interpreter writer add a few annotations to the source code of his interpreter that enable large amounts of optimization. For interpreters instrumented as such, improvements in performance of 20 to 60 percent were obtained. The second use is a proof of concept for accelerating the performance of IA-32 applications running on the Itanium processor by dynamically translating hot trace paths into Itanium IA-64 assembly through DynamoRIO while allowing the less frequently executed potions of the application to run in Itanium's native IA-32 hardware emulation. This transformation yields speedups of almost 50 percent on small loop intensive benchmarks. -
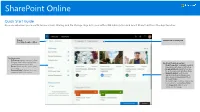
Sharepoint Online
SharePoint Online Quick Start Guide Do more wherever you are with secure access, sharing, and file storage. Sign in to your Office 365 subscription and select SharePoint from the App launcher. Search Create a site or news post Find Sites, People, or Files. Find your sites • Following displays sites you follow, like your team's site or a site from Check out featured content another group you work with. • News from sites highlights updates • Recent shows any site you've gone from sites you follow or visit often. to recently. • Frequent sites shows sites you like • Featured links* displays sites your to go to and recent activity in them. company wants to showcase. • Suggested sites* (not shown) appear based on searches you've done and recommendations from Microsoft Graph. • Microsoft Graph must be enabled by your admin to see Featured links and Suggested sites on your SharePoint homepage. SharePoint Online Work with files Select a site from the SharePoint homepage or enter its URL into your browser. Then select Documents in the left navigation pane. Open Share Copy link Move to/Copy to Open and edit a file online Share files directly from Get a link to the selected file Move or copy to another or in a desktop app. SharePoint. Files are private to insert in an IM, email, or destination in your OneDrive until shared. site. or any SharePoint site. Details Pane Document See file information, recent View and work with the files activity, manage access stored on a SharePoint site. permissions, and edit file Download properties. Download a copy of a file to work offline that takes local device space. -

Consuming Office 365 REST API Paolo Pialorsi – [email protected] – Piasys.Com About Me
Consuming Office 365 REST API Paolo Pialorsi – [email protected] – PiaSys.com About me • Project Manager, Consultant, Trainer • About 50 Microsoft certification exams passed, including MC(S)M • MVP Office 365 • Focused on SharePoint since 2002 • Author of 10 books about XML, SOAP, .NET, LINQ, and SharePoint • Speaker at main IT conferences @PaoloPia - [email protected] - http://www.pialorsi.com/blog.aspx Introducing Office 365 REST API What are the Office 365 REST API? • Set of services with REST (REpresentational State Transfer) endpoints • Available services • Microsoft Exchange Online • Mail, Contacts, Calendars • Microsoft OneDrive for Business • My Files • Microsoft SharePoint Online • Sites • Microsoft Azure Active Directory • Authentication, Directory Graph The SharePoint client APIs _api Office 365 REST APIs How to consume the APIs? • Directly via REST endpoints • Indirectly via high-level client libraries • .NET client libraries • JavaScript client libraries • Open Source SDKs for iOS and Android • Supported platforms for .NET client libraries • .NET Windows Store Apps • Windows Forms Application • WPF Application • ASP.NET Web Forms/MVC • Xamarin Android and iOS Applications • Multi-device hybrid apps DEMO Playing with the APIs using Fiddler .NET Environment Configuration • Microsoft Visual Studio 2013 • Microsoft Office Developer Tools for Visual Studio 2013 • A Microsoft Office 365 tenant (can be a developer tenant) • Some NuGet packages • OWIN OpenId Connect • For ASP.NET only DEMO Preparing a development environment Understanding -

Store and Share Files Inside and Outside Your Organization to Work Securely Across Organizational Boundaries
Store and share files inside and outside your organization to work securely across organizational boundaries Cumbersome restrictions and limitations on mobile devices, apps, and remote access can be taxing from an IT perspective and frustrating for your employees. Users need to be able to create, access, and share files from anywhere, but you also need to ensure that these actions are safe and secure. Microsoft 365 offers security solutions that can help secure your collaboration and productivity apps, including third-party apps, so that your employees can connect and communicate wherever they are, using the tools they are familiar with, as securely as if they were right at their desks. How can I securely share documents outside my organization? Microsoft Azure Information Protection Azure Information Protection provides classification, labeling, and protection so you can track and control how information is used. Data can be classified as public or confidential according to standards you define for content, context, and source. These classifications can be applied automatically or manually, or you can suggest classifications so that your employees can decide what to apply. Azure Information Protection is integrated with other Microsoft cloud services, such as Microsoft Office 365 and Azure AD. It can be used with your in-house line-of-business applications and information protection solutions from software vendors, whether these applications and solutions are on-premises or in the cloud. To classify documents using Azure Information Protection, you must first configure your company’s classification policy. Configure the policy by signing in to the Azure portal as an administrator, selecting Azure Information Protection in the apps list. -

Building Windows Phone 7 Applications with Sharepoint 2010 Products and Unified Access Gateway
Building Windows Phone 7 applications with SharePoint 2010 Products and Unified Access Gateway This document is provided “as-is”. Information and views expressed in this document, including URL and other Internet Web site references, may change without notice. You bear the risk of using it. Some examples depicted herein are provided for illustration only and are fictitious. No real association or connection is intended or should be inferred. This document does not provide you with any legal rights to any intellectual property in any Microsoft product. You may copy and use this document for your internal, reference purposes. You may modify this document for your internal, reference purposes. Microsoft, SharePoint , Silverlight, Visual Studio, and Windows Phone 7 are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. © 2011 Microsoft Corporation. All rights reserved. Building Windows Phone 7 applications with SharePoint 2010 Products and Unified Access Gateway Dave Pae Microsoft Corporation Todd Baginski Aptillon, Inc. Matthew McDermott Aptillon, Inc. Ben Ari Microsoft Corporation March 2011 Applies to: Microsoft® SharePoint® Server 2010, Microsoft SharePoint Foundation 2010, Microsoft Forefront Unified Access Gateway, Windows Phone 7™ Summary: This white paper addresses business scenarios for the development of mobile applications that use the features of SharePoint 2010 Products for collaboration while authenticating through Microsoft Forefront Unified Access Gateway (UAG). The main body of the paper introduces the concepts and code required to access SharePoint list data in a secure manner from Windows Phone 7. The Appendix details the installation and configuration of a developer instance of UAG for the purposes of testing and developing mobile applications with SharePoint 2010 Products. -

Dynamic Binary Translation & Instrumentation
Dynamic Binary Translation & Instrumentation Pin Building Customized Program Analysis Tools with Dynamic Instrumentation CK Luk, Robert Cohn, Robert Muth, Harish Patil, Artur Klauser, Geoff Lowney, Steven Wallace, Kim Hazelwood Intel Vijay Janapa Reddi University of Colorado http://rogue.colorado.edu/Pin PLDI’05 2 Instrumentation • Insert extra code into programs to collect information about execution • Program analysis: • Code coverage, call-graph generation, memory-leak detection • Architectural study: • Processor simulation, fault injection • Existing binary-level instrumentation systems: • Static: • ATOM, EEL, Etch, Morph • Dynamic: • Dyninst, Vulcan, DTrace, Valgrind, Strata, DynamoRIO C Pin is a new dynamic binary instrumentation system PLDI’05 3 A Pintool for Tracing Memory Writes #include <iostream> #include "pin.H" executed immediately before a FILE* trace; write is executed • Same source code works on the 4 architectures VOID RecordMemWrite(VOID* ip, VOID* addr, UINT32 size) { fprintf(trace,=> “%p: Pin Wtakes %p %dcare\n”, of ip, different addr, size); addressing modes } • No need to manually save/restore application state VOID Instruction(INS ins, VOID *v) { if (INS_IsMemoryWrite(ins))=> Pin does it for you automatically and efficiently INS_InsertCall(ins, IPOINT_BEFORE, AFUNPTR(RecordMemWrite), IARG_INST_PTR, IARG_MEMORYWRITE_EA, IARG_MEMORYWRITE_SIZE, IARG_END); } int main(int argc, char * argv[]) { executed when an instruction is PIN_Init(argc, argv); dynamically compiled trace = fopen(“atrace.out”, “w”); INS_AddInstrumentFunction(Instruction, -

Pin: Building Customized Program Analysis Tools with Dynamic Instrumentation
Pin: Building Customized Program Analysis Tools with Dynamic Instrumentation Chi-Keung Luk Robert Cohn Robert Muth Harish Patil Artur Klauser Geoff Lowney Steven Wallace Vijay Janapa Reddi Kim Hazelwood Intel Corporation ¡ University of Colorado ¢¤£¦¥¨§ © £ ¦£ "! #%$&'( £)&(¦*+©-,.+/01$©-!2 ©-,2¦3 45£) 67©2, £¦!2 "0 Abstract 1. Introduction Robust and powerful software instrumentation tools are essential As software complexity increases, instrumentation—a technique for program analysis tasks such as profiling, performance evalu- for inserting extra code into an application to observe its behavior— ation, and bug detection. To meet this need, we have developed is becoming more important. Instrumentation can be performed at a new instrumentation system called Pin. Our goals are to pro- various stages: in the source code, at compile time, post link time, vide easy-to-use, portable, transparent, and efficient instrumenta- or at run time. Pin is a software system that performs run-time tion. Instrumentation tools (called Pintools) are written in C/C++ binary instrumentation of Linux applications. using Pin’s rich API. Pin follows the model of ATOM, allowing the The goal of Pin is to provide an instrumentation platform for tool writer to analyze an application at the instruction level with- building a wide variety of program analysis tools for multiple archi- out the need for detailed knowledge of the underlying instruction tectures. As a result, the design emphasizes ease-of-use, portabil- set. The API is designed to be architecture independent whenever ity, transparency, efficiency, and robustness. This paper describes possible, making Pintools source compatible across different archi- the design of Pin and shows how it provides these features. -

Sharepoint Online “The New Way to Work Together" Agenda
SHAREPOINT ONLINE “THE NEW WAY TO WORK TOGETHER" AGENDA WHAT IS SHAREPOINT? ~ FEATURES OF SHAREPOINT ~ EXAMPLES OF SITES ~ HELP AND OTHER RESOURCES ~ QUESTIONS WHAT IS SHAREPOINT ONLINE? • A cloud-based service hosted by Microsoft Office. SharePoint Online is available with Office 365 suite of products or as a standalone product. • Online collaboration tool that provides content management, enterprise search, collaboration, and information-sharing capabilities. • Introduces new ways to share your work and work with others, organize your projects and teams and discover people and information. • Employees can create sites to share documents and information with colleagues, partners, and customers • All you need is a web browser, such as Internet Explorer, Chrome, or Firefox. HOW TO ACCESS SHAREPOINT ONLINE? To log on to the SharePoint site, you will use your scsu.edu email address and password. You will be asked if you would like to log into your work or school account or your Microsoft Account. You will select your work or school account and log in using your email address and password. FEATURES OF SHAREPOINT Features of SharePoint include: Project Sites Document Management Lists and Document Libraries Search Centers Wiki and Blogs Office Web Apps Workflows Used as a secure place to store, organize, share, and access information from almost any device. 10 THINGS YOU CAN DO WITH SHAREPOINT 1. Upload files to OneDrive for Business 2. Open a document in a document library 3. Work with others on the same document, at the same time 4. Share documents 5. Share sites 10 THINGS YOU CAN DO WITH SHAREPOINT 6. -

Microsoft Sharepoint Workspace 2010 Product Guide
Microsoft SharePoint Workspace 2010 Product Guide Microsoft SharePoint Workspace 2010: An Overview ................................................................................ 1 SharePoint Workspace: At-a-Glance ............................................................................................................... 3 Sync with SharePoint 2010 sites .................................................................................................................................... 3 Take all or some of your SharePoint site content offline..................................................................................... 3 Add content with Direct Folder Access ....................................................................................................................... 3 Search all available spaces ............................................................................................................................................... 3 Simplified log-in ................................................................................................................................................................... 4 Microsoft SharePoint Mobile 2010 ............................................................................................................................... 4 Groove workspaces ............................................................................................................................................................. 4 Get easier access to the right tools, at the right time .......................................................................................... -
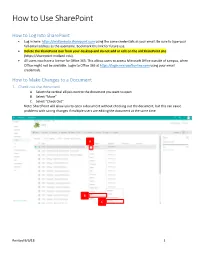
How to Use Sharepoint (Pdf)
How to Use SharePoint How to Log Into SharePoint Log in here: https://midlandedu.sharepoint.com using the same credentials as your email. Be sure to type your full email address as the username. Bookmark this link for future use. Delete the SharePoint icon from your desktop and do not add or edit on the old SharePoint site (https://sharepoint.midland.edu). All users now have a license for Office 365. This allows users to access Microsoft Office outside of campus, when Office might not be available. Login to Office 365 at https://login.microsoftonline.com using your email credentials. How to Make Changes to a Document 1. Check out the document A. Select the vertical ellipsis next to the document you want to open B. Select “More” C. Select “Check Out” Note: SharePoint will allow you to open a document without checking out the document, but this can cause problems with saving changes if multiple users are editing the document at the same time. A B C Revised 9/6/18 1 2. Open the word document in the Microsoft Word Application A. Once the document is checked out (step 1) a green arrow will appear on the Microsoft Word icon. Hovering over the green arrow will show who has the document checked out. B. Select the vertical ellipsis next to the document you want to open C. Select “Open” D. Select “Open in Word” Note: Do not open documents in Microsoft Word Online or Excel Online, the formatting will appear incorrectly. A B C D Revised 9/6/18 2 3. -

NET Technology Guide for Business Applications // 1
.NET Technology Guide for Business Applications Professional Cesar de la Torre David Carmona Visit us today at microsoftpressstore.com • Hundreds of titles available – Books, eBooks, and online resources from industry experts • Free U.S. shipping • eBooks in multiple formats – Read on your computer, tablet, mobile device, or e-reader • Print & eBook Best Value Packs • eBook Deal of the Week – Save up to 60% on featured titles • Newsletter and special offers – Be the first to hear about new releases, specials, and more • Register your book – Get additional benefits Hear about it first. Get the latest news from Microsoft Press sent to your inbox. • New and upcoming books • Special offers • Free eBooks • How-to articles Sign up today at MicrosoftPressStore.com/Newsletters Wait, there’s more... Find more great content and resources in the Microsoft Press Guided Tours app. The Microsoft Press Guided Tours app provides insightful tours by Microsoft Press authors of new and evolving Microsoft technologies. • Share text, code, illustrations, videos, and links with peers and friends • Create and manage highlights and notes • View resources and download code samples • Tag resources as favorites or to read later • Watch explanatory videos • Copy complete code listings and scripts Download from Windows Store Free ebooks From technical overviews to drilldowns on special topics, get free ebooks from Microsoft Press at: www.microsoftvirtualacademy.com/ebooks Download your free ebooks in PDF, EPUB, and/or Mobi for Kindle formats. Look for other great resources at Microsoft Virtual Academy, where you can learn new skills and help advance your career with free Microsoft training delivered by experts. -

Getting to Know Windows 10 for Employees
Getting to know Windows 10 for employees Microsoft IT Showcase microsoft.com/itshowcase Familiar and better than ever Windows 10 is the best combination of the Windows you Windows 10 was designed to be the safest Windows already know, plus lots of great improvements you’ll love. ever. The Creators Update adds comprehensive security It helps you do what matters, faster. capabilities and privacy tools on top of what was already available in Windows 10. Our new Creators Update is designed to spark and The new Surface devices for Windows 10 are a balance unleash creativity, bringing 3D and mixed reality to of craftsmanship, performance, and versatility, designed everyone. Combined with Office 365, Cortana, and with you at the center. Microsoft Edge, you’ll have new ways of working that increase and enhance your productivity. And the IT management tools, services, and advances like AutoPilot and Microsoft Store for Business will make the work of IT organizations easier and more systematic. Microsoft IT Showcase microsoft.com/itshowcase Getting to know Windows 10 Creators Update Boost productivity • Start menu • Task view • Edge • Quick access menu • Virtual desktop • Office365 • Using tiles • Personalization • Windows Ink • Snap enhancements • Action center and notifications • Paint 3D • Tablet mode • Cortana Comprehensive security Devices and Windows 10 S Modern IT • Windows Hello • Meet the Surface family • AutoPilot • Windows Defender features • Windows 10 S • Microsoft Store for Business • Microsoft Edge • Security Guards • Windows Information Protection Microsoft IT Showcase microsoft.com/itshowcase The Start menu: More options, easy access Windows 10 brings back the familiar Windows desktop and Start menu from Windows 7.