Publication Bias
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Orchard Plot: Cultivating a Forest Plot for Use in Ecology, Evolution
1BRIEF METHOD NOTE 2The Orchard Plot: Cultivating a Forest Plot for Use in Ecology, 3Evolution and Beyond 4Shinichi Nakagawa1, Malgorzata Lagisz1,5, Rose E. O’Dea1, Joanna Rutkowska2, Yefeng Yang1, 5Daniel W. A. Noble3,5, and Alistair M. Senior4,5. 61 Evolution & Ecology Research Centre and School of Biological, Earth and Environmental 7Sciences, University of New South Wales, Sydney, NSW 2052, Australia 82 Institute of Environmental Sciences, Faculty of Biology, Jagiellonian University, Kraków, Poland 93 Division of Ecology and Evolution, Research School of Biology, The Australian National 10University, Canberra, ACT, Australia 114 Charles Perkins Centre and School of Life and Environmental Sciences, University of Sydney, 12Camperdown, NSW 2006, Australia 135 These authors contributed equally 14* Correspondence: S. Nakagawa & A. M. Senior 15e-mail: [email protected] 16email: [email protected] 17Short title: The Orchard Plot 18 1 19Abstract 20‘Classic’ forest plots show the effect sizes from individual studies and the aggregate effect from a 21meta-analysis. However, in ecology and evolution meta-analyses routinely contain over 100 effect 22sizes, making the classic forest plot of limited use. We surveyed 102 meta-analyses in ecology and 23evolution, finding that only 11% use the classic forest plot. Instead, most used a ‘forest-like plot’, 24showing point estimates (with 95% confidence intervals; CIs) from a series of subgroups or 25categories in a meta-regression. We propose a modification of the forest-like plot, which we name 26the ‘orchard plot’. Orchard plots, in addition to showing overall mean effects and CIs from meta- 27analyses/regressions, also includes 95% prediction intervals (PIs), and the individual effect sizes 28scaled by their precision. -

Pat Croskerry MD Phd
Thinking (and the factors that influence it) Pat Croskerry MD PhD Scottish Intensive Care Society St Andrews, January 2011 RECOGNIZED Intuition Pattern Pattern Initial Recognition Executive Dysrationalia Calibration Output information Processor override T override Repetition NOT Analytical RECOGNIZED reasoning Dual Process Model Medical Decision Making Intuitive Analytical Orthodox Medical Decision Making (Analytical) Rational Medical Decision-Making • Knowledge base • Differential diagnosis • Best evidence • Reviews, meta-analysis • Biostatistics • Publication bias, citation bias • Test selection and interpretation • Bayesian reasoning • Hypothetico-deductive reasoning .„Cognitive thought is the tip of an enormous iceberg. It is the rule of thumb among cognitive scientists that unconscious thought is 95% of all thought – .this 95% below the surface of conscious awareness shapes and structures all conscious thought‟ Lakoff and Johnson, 1999 Rational blind-spots • Framing • Context • Ambient conditions • Individual factors Individual Factors • Knowledge • Intellect • Personality • Critical thinking ability • Decision making style • Gender • Ageing • Circadian type • Affective state • Fatigue, sleep deprivation, sleep debt • Cognitive load tolerance • Susceptibility to group pressures • Deference to authority Intelligence • Measurement of intelligence? • IQ most widely used barometer of intellect and cognitive functioning • IQ is strongest single predictor of job performance and success • IQ tests highly correlated with each other • Population -
Graphical Methods for Detecting Bias in Meta-Analysis
See discussions, stats, and author profiles for this publication at: https://www.researchgate.net/publication/13513488 Graphical methods for detecting bias in meta-analysis Article in Family medicine · October 1998 Source: PubMed CITATIONS READS 26 702 1 author: Robert Ferrer University of Texas Health Science Center at San Antonio 79 PUBLICATIONS 2,097 CITATIONS SEE PROFILE Some of the authors of this publication are also working on these related projects: Small Troubles, Adaptive Responses View project All content following this page was uploaded by Robert Ferrer on 06 January 2014. The user has requested enhancement of the downloaded file. Vol. 30, No. 8 579 Research Series Graphical Methods for Detecting Bias in Meta-analysis Robert L. Ferrer, MD, MPH The trustworthiness of meta-analysis, a set of techniques used to quantitatively combine results from different studies, has recently been questioned. Problems with meta-analysis stem from bias in selecting studies to include in a meta-analysis and from combining study results when it is inappro- priate to do so. Simple graphical techniques address these problems but are infrequently applied. Funnel plots display the relationship of effect size versus sample size and help determine whether there is likely to have been selection bias in including studies in the meta-analysis. The L’Abbé plot displays the outcomes in both the treatment and control groups of included studies and helps to decide whether the studies are too heterogeneous to appropriately combine into a single measure of effect. (Fam Med 1998;30(8):579-83.) Our faith in the answers provided by scientific in- multiple studies to see the patterns that clarify a line quiry rests on our confidence that its methods are of scientific inquiry. -
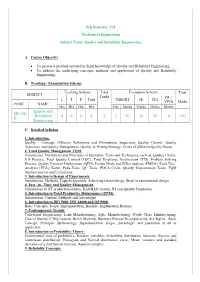
D Quality and Reliability Engineering 4 0 0 4 4 3 70 30 20 0
B.E Semester: VII Mechanical Engineering Subject Name: Quality and Reliability Engineering A. Course Objective To present a problem oriented in depth knowledge of Quality and Reliability Engineering. To address the underlying concepts, methods and application of Quality and Reliability Engineering. B. Teaching / Examination Scheme Teaching Scheme Total Evaluation Scheme Total SUBJECT Credit PR. / L T P Total THEORY IE CIA VIVO Marks CODE NAME Hrs Hrs Hrs Hrs Hrs Marks Marks Marks Marks Quality and ME706- Reliability 4 0 0 4 4 3 70 30 20 0 120 D Engineering C. Detailed Syllabus 1. Introduction: Quality – Concept, Different Definitions and Dimensions, Inspection, Quality Control, Quality Assurance and Quality Management, Quality as Wining Strategy, Views of different Quality Gurus. 2. Total Quality Management TQM: Introduction, Definitions and Principles of Operation, Tools and Techniques, such as, Quality Circles, 5 S Practice, Total Quality Control (TQC), Total Employee Involvement (TEI), Problem Solving Process, Quality Function Deployment (QFD), Failure Mode and Effect analysis (FMEA), Fault Tree Analysis (FTA), Kizen, Poka-Yoke, QC Tools, PDCA Cycle, Quality Improvement Tools, TQM Implementation and Limitations. 3. Introduction to Design of Experiments: Introduction, Methods, Taguchi approach, Achieving robust design, Steps in experimental design 4. Just –in –Time and Quality Management: Introduction to JIT production system, KANBAN system, JIT and Quality Production. 5. Introduction to Total Productive Maintenance (TPM): Introduction, Content, Methods and Advantages 6. Introduction to ISO 9000, ISO 14000 and QS 9000: Basic Concepts, Scope, Implementation, Benefits, Implantation Barriers 7. Contemporary Trends: Concurrent Engineering, Lean Manufacturing, Agile Manufacturing, World Class Manufacturing, Cost of Quality (COQ) system, Bench Marking, Business Process Re-engineering, Six Sigma - Basic Concept, Principle, Methodology, Implementation, Scope, Advantages and Limitation of all as applicable. -

Science for Judges Ii
BERGERINTRO.DOC 4/23/2004 12:32 PM SCIENCE FOR JUDGES II INTRODUCTION Margaret A. Berger* This issue of the Journal of Law and Policy contains a second installment of articles about science-related questions that arise in the litigation context. As previously explained, these essays are expanded and edited versions of presentations made to federal and state judges at programs funded by the Common Benefit Trust established in the Silicone Breast Implant Products Liability Litigation.1 These conferences are held at Brooklyn Law School under the auspices of its Center for Health Law and Policy, in collaboration with the Federal Judicial Center, the National Center for State Courts, and the National Academies of Science=s Panel on Science, Technology and Law. Science for Judges II focused on two principal topics: (1) the practice of epidemiology and its role in judicial proceedings; and (2) the production of science through the regulatory process of administrative agencies. Epidemiology has played a significant role in toxic tort actions in proving causation, often the most crucial issue in dispute. A failure to prove causation means a victory for the defense. Many courts consider epidemiologic evidence the “gold standard” of proof, and some judges go so far as to hold that a plaintiff cannot prevail in proving causation in the absence of confirmatory epidemiologic studies.2 The three papers on epidemiology by * Suzanne J. and Norman Miles Professor of Law, Brooklyn Law School. Professor Berger is the Director of the Science for Judges Program. 1 See Margaret A. Berger, Introduction, Science for Judges, 12 J. -

Quality Assurance: Best Practices in Clinical SAS® Programming
NESUG 2012 Management, Administration and Support Quality Assurance: Best Practices in Clinical SAS® Programming Parag Shiralkar eClinical Solutions, a Division of Eliassen Group Abstract SAS® programmers working on clinical reporting projects are often under constant pressure of meeting tight timelines, producing best quality SAS® code and of meeting needs of customers. As per regulatory guidelines, a typical clinical report or dataset generation using SAS® software is considered as software development. Moreover, since statistical reporting and clinical programming is a part of clinical trial processes, such processes are required to follow strict quality assurance guidelines. While SAS® programmers completely focus on getting best quality deliverable out in a timely manner, quality assurance needs often get lesser priorities or may get unclearly understood by clinical SAS® programming staff. Most of the quality assurance practices are often focused on ‘process adherence’. Statistical programmers using SAS® software and working on clinical reporting tasks need to maintain adequate documentation for the processes they follow. Quality control strategy should be planned prevalently before starting any programming work. Adherence to standard operating procedures, maintenance of necessary audit trails, and necessary and sufficient documentation are key aspects of quality. This paper elaborates on best quality assurance practices which statistical programmers working in pharmaceutical industry are recommended to follow. These quality practices -

Data Quality Monitoring and Surveillance System Evaluation
TECHNICAL DOCUMENT Data quality monitoring and surveillance system evaluation A handbook of methods and applications www.ecdc.europa.eu ECDC TECHNICAL DOCUMENT Data quality monitoring and surveillance system evaluation A handbook of methods and applications This publication of the European Centre for Disease Prevention and Control (ECDC) was coordinated by Isabelle Devaux (senior expert, Epidemiological Methods, ECDC). Contributing authors John Brazil (Health Protection Surveillance Centre, Ireland; Section 2.4), Bruno Ciancio (ECDC; Chapter 1, Section 2.1), Isabelle Devaux (ECDC; Chapter 1, Sections 3.1 and 3.2), James Freed (Public Health England, United Kingdom; Sections 2.1 and 3.2), Magid Herida (Institut for Public Health Surveillance, France; Section 3.8 ), Jana Kerlik (Public Health Authority of the Slovak Republic; Section 2.1), Scott McNabb (Emory University, United States of America; Sections 2.1 and 3.8), Kassiani Mellou (Hellenic Centre for Disease Control and Prevention, Greece; Sections 2.2, 2.3, 3.3, 3.4 and 3.5), Gerardo Priotto (World Health Organization; Section 3.6), Simone van der Plas (National Institute of Public Health and the Environment, the Netherlands; Chapter 4), Bart van der Zanden (Public Health Agency of Sweden; Chapter 4), Edward Valesco (Robert Koch Institute, Germany; Sections 3.1 and 3.2). Project working group members: Maria Avdicova (Public Health Authority of the Slovak Republic), Sandro Bonfigli (National Institute of Health, Italy), Mike Catchpole (Public Health England, United Kingdom), Agnes -

Quality Control and Reliability Engineering 1152Au128 3 0 0 3
L T P C QUALITY CONTROL AND RELIABILITY ENGINEERING 1152AU128 3 0 0 3 1. Preamble This course provides the essentiality of SQC, sampling and reliability engineering. Study on various types of control charts, six sigma and process capability to help the students understand various quality control techniques. Reliability engineering focuses on the dependability, failure mode analysis, reliability prediction and management of a system 2. Pre-requisite NIL 3. Course Outcomes Upon the successful completion of the course, learners will be able to Level of learning CO Course Outcomes domain (Based on Nos. C01 Explain the basic concepts in Statistical Process Control K2 Apply statistical sampling to determine whether to accept or C02 K2 reject a production lot Predict lifecycle management of a product by applying C03 K2 reliability engineering techniques. C04 Analyze data to determine the cause of a failure K2 Estimate the reliability of a component by applying RDB, C05 K2 FMEA and Fault tree analysis. 4. Correlation with Programme Outcomes Cos PO1 PO2 PO3 PO4 PO5 PO6 PO7 PO8 PO9 PO10 PO11 PO12 PSO1 PSO2 CO1 H H H M L H M L CO2 H H H M L H H M CO3 H H H M L H L H CO4 H H H M L H M M CO5 H H H M L H L H H- High; M-Medium; L-Low 5. Course content UNIT I STATISTICAL QUALITY CONTROL L-9 Methods and Philosophy of Statistical Process Control - Control Charts for Variables and Attributes Cumulative Sum and Exponentially Weighted Moving Average Control Charts - Other SPC Techniques Process - Capability Analysis - Six Sigma Concept. -

Interpreting Subgroups and the STAMPEDE Trial
“Thursday’s child has far to go” -- Interpreting subgroups and the STAMPEDE trial Melissa R Spears MRC Clinical Trials Unit at UCL, London Nicholas D James Institute of Cancer and Genomic Sciences, University of Birmingham Matthew R Sydes MRC Clinical Trials Unit at UCL STAMPEDE is a multi-arm multi-stage randomised controlled trial protocol, recruiting men with locally advanced or metastatic prostate cancer who are commencing long-term androgen deprivation therapy. Opening to recruitment with five research questions in 2005 and adding in a further five questions over the past six years, it has reported survival data on six of these ten RCT questions over the past two years. [1-3] Some of these results have been of practice-changing magnitude, [4, 5] but, in conversation, we have noticed some misinterpretation, both over-interpretation and under-interpretation, of subgroup analyses by the wider clinical community which could impact negatively on practice. We suspect, therefore, that such problems in interpretation may be common. Our intention here is to provide comment on interpretation of subgroup analysis in general using examples from STAMPEDE. Specifically we would like to highlight some possible implications from the misinterpretation of subgroups and how these might be avoided, particularly where these contravene the very design of the research question. In this, we would hope to contribute to the conversation on subgroup analyses. [6-11] For each comparison in STAMPEDE, or indeed virtually any trial, the interest is the effect of the research treatment under investigation on the primary outcome measure across the whole population. Upon reporting the primary outcome measure, the consistency of effect across pre-specified subgroups, including stratification factors at randomisation, is presented; these are planned analyses. -

Cognitive Biases in Software Engineering: a Systematic Mapping Study
Cognitive Biases in Software Engineering: A Systematic Mapping Study Rahul Mohanani, Iflaah Salman, Burak Turhan, Member, IEEE, Pilar Rodriguez and Paul Ralph Abstract—One source of software project challenges and failures is the systematic errors introduced by human cognitive biases. Although extensively explored in cognitive psychology, investigations concerning cognitive biases have only recently gained popularity in software engineering research. This paper therefore systematically maps, aggregates and synthesizes the literature on cognitive biases in software engineering to generate a comprehensive body of knowledge, understand state of the art research and provide guidelines for future research and practise. Focusing on bias antecedents, effects and mitigation techniques, we identified 65 articles (published between 1990 and 2016), which investigate 37 cognitive biases. Despite strong and increasing interest, the results reveal a scarcity of research on mitigation techniques and poor theoretical foundations in understanding and interpreting cognitive biases. Although bias-related research has generated many new insights in the software engineering community, specific bias mitigation techniques are still needed for software professionals to overcome the deleterious effects of cognitive biases on their work. Index Terms—Antecedents of cognitive bias. cognitive bias. debiasing, effects of cognitive bias. software engineering, systematic mapping. 1 INTRODUCTION OGNITIVE biases are systematic deviations from op- knowledge. No analogous review of SE research exists. The timal reasoning [1], [2]. In other words, they are re- purpose of this study is therefore as follows: curring errors in thinking, or patterns of bad judgment Purpose: to review, summarize and synthesize the current observable in different people and contexts. A well-known state of software engineering research involving cognitive example is confirmation bias—the tendency to pay more at- biases. -

Statistical Quality Control Methods in Infection Control and Hospital Epidemiology, Part I: Introduction and Basic Theory Author(S): James C
Statistical Quality Control Methods in Infection Control and Hospital Epidemiology, Part I: Introduction and Basic Theory Author(s): James C. Benneyan Source: Infection Control and Hospital Epidemiology, Vol. 19, No. 3 (Mar., 1998), pp. 194-214 Published by: The University of Chicago Press Stable URL: http://www.jstor.org/stable/30143442 Accessed: 25/06/2010 18:26 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=ucpress. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit service that helps scholars, researchers, and students discover, use, and build upon a wide range of content in a trusted digital archive. We use information technology and tools to increase productivity and facilitate new forms of scholarship. For more information about JSTOR, please contact [email protected]. The University of Chicago Press is collaborating with JSTOR to digitize, preserve and extend access to Infection Control and Hospital Epidemiology. -

Meta4diag: Bayesian Bivariate Meta-Analysis of Diagnostic Test Studies for Routine Practice
meta4diag: Bayesian Bivariate Meta-analysis of Diagnostic Test Studies for Routine Practice J. Guo and A. Riebler Department of Mathematical Sciences, Norwegian University of Science and Technology, Trondheim, PO 7491, Norway. July 8, 2016 Abstract This paper introduces the R package meta4diag for implementing Bayesian bivariate meta-analyses of diagnostic test studies. Our package meta4diag is a purpose-built front end of the R package INLA. While INLA offers full Bayesian inference for the large set of latent Gaussian models using integrated nested Laplace approximations, meta4diag extracts the features needed for bivariate meta-analysis and presents them in an intuitive way. It allows the user a straightforward model- specification and offers user-specific prior distributions. Further, the newly proposed penalised complexity prior framework is supported, which builds on prior intuitions about the behaviours of the variance and correlation parameters. Accurate posterior marginal distributions for sensitivity and specificity as well as all hyperparameters, and covariates are directly obtained without Markov chain Monte Carlo sampling. Further, univariate estimates of interest, such as odds ratios, as well as the SROC curve and other common graphics are directly available for interpretation. An in- teractive graphical user interface provides the user with the full functionality of the package without requiring any R programming. The package is available through CRAN https://cran.r-project.org/web/packages/meta4diag/ and its usage will be illustrated using three real data examples. arXiv:1512.06220v2 [stat.AP] 7 Jul 2016 1 1 Introduction A meta-analysis summarises the results from multiple studies with the purpose of finding a general trend across the studies.