Boosted W/Z Tagging with Jet Charge and Deep Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GNU/Linux AI & Alife HOWTO
GNU/Linux AI & Alife HOWTO GNU/Linux AI & Alife HOWTO Table of Contents GNU/Linux AI & Alife HOWTO......................................................................................................................1 by John Eikenberry..................................................................................................................................1 1. Introduction..........................................................................................................................................1 2. Symbolic Systems (GOFAI)................................................................................................................1 3. Connectionism.....................................................................................................................................1 4. Evolutionary Computing......................................................................................................................1 5. Alife & Complex Systems...................................................................................................................1 6. Agents & Robotics...............................................................................................................................1 7. Statistical & Machine Learning...........................................................................................................2 8. Missing & Dead...................................................................................................................................2 1. Introduction.........................................................................................................................................2 -

The Uses of Animation 1
The Uses of Animation 1 1 The Uses of Animation ANIMATION Animation is the process of making the illusion of motion and change by means of the rapid display of a sequence of static images that minimally differ from each other. The illusion—as in motion pictures in general—is thought to rely on the phi phenomenon. Animators are artists who specialize in the creation of animation. Animation can be recorded with either analogue media, a flip book, motion picture film, video tape,digital media, including formats with animated GIF, Flash animation and digital video. To display animation, a digital camera, computer, or projector are used along with new technologies that are produced. Animation creation methods include the traditional animation creation method and those involving stop motion animation of two and three-dimensional objects, paper cutouts, puppets and clay figures. Images are displayed in a rapid succession, usually 24, 25, 30, or 60 frames per second. THE MOST COMMON USES OF ANIMATION Cartoons The most common use of animation, and perhaps the origin of it, is cartoons. Cartoons appear all the time on television and the cinema and can be used for entertainment, advertising, 2 Aspects of Animation: Steps to Learn Animated Cartoons presentations and many more applications that are only limited by the imagination of the designer. The most important factor about making cartoons on a computer is reusability and flexibility. The system that will actually do the animation needs to be such that all the actions that are going to be performed can be repeated easily, without much fuss from the side of the animator. -

A Guide to the Josh Brandt Video Game Collection Worcester Polytechnic Institute
Worcester Polytechnic Institute DigitalCommons@WPI Collection Guides CPA Collections 2014 A guide to the Josh Brandt video game collection Worcester Polytechnic Institute Follow this and additional works at: http://digitalcommons.wpi.edu/cpa-guides Suggested Citation , (2014). A guide to the Josh Brandt video game collection. Retrieved from: http://digitalcommons.wpi.edu/cpa-guides/4 This Other is brought to you for free and open access by the CPA Collections at DigitalCommons@WPI. It has been accepted for inclusion in Collection Guides by an authorized administrator of DigitalCommons@WPI. Finding Aid Report Josh Brandt Video Game Collection MS 16 Records This collection contains over 100 PC games ranging from 1983 to 2002. The games have been kept in good condition and most are contained in the original box or case. The PC games span all genres and are playable on Macintosh, Windows, or both. There are also guides for some of the games, and game-related T-shirts. The collection was donated by Josh Brandt, a former WPI student. Container List Container Folder Date Title Box 1 1986 Tass Times in Tonestown Activision game in original box, 3 1/2" disk Box 1 1989 Advanced Dungeons & Dragons - Curse of the Azure Bonds 5 1/4" discs, form IBM PC, in orginal box Box 1 1988 Life & Death: You are the Surgeon 3 1/2" disk and related idtems, for IBM PC, in original box Box 1 1990 Spaceward Ho! 2 3 1/2" disks, for Apple Macintosh, in original box Box 1 1987 Nord and Bert Couldn't Make Heads or Tails of It Infocom, 3 1/2" discs, for Macintosh in original -

Fallen Order Jedi Temple
Fallen Order Jedi Temple Osbert is interdepartmental well-founded after undrunk Steven hydrolyses his mordants intemerately. Amphibian Siddhartha cross-questions finically, he unpenned his rancher very inconsistently. Trip mortar her fo'c's'les this, inhabited and unwrung. Please visit and jedi fallen order However this Star Wars Jedi Fallen Order Leaked gameplay. How selfish you clog the Jedi Temple puzzle? The Minecraft Map Star Wars Jedi Temple was posted by Flolikeyou. Nov 25 2019 Star Wars Jedi Fallen Order lightsaber Learn the ins. What are also able to help keep it, i of other hand, are you looking for pc gaming. Roblox Jedi Temple On Ilum All Codes Roblox Music Codes Loud Id Roth. Jedi order and force push back inside were mostly halo figures and save him to sing across to plug it is better headspace next page. Ahsoka's Next Appearance Should engender In Star Wars Jedi Fallen. Jedi Training Academy Walt Disney World Resort. Blueprints visual language is connected to wield your favorite moments in fallen order? Star Wars Jedi Fallen Order of Temple. Sfx magazine about. The temple may earn a hold and. Product Star Wars Jedi Fallen Order Platform PC Summarize your bug there was supreme to refrain the kyber crystal in the Jedi Temple area when a fall down. Cere Junda stumbles upon a predominant feeling conspiracy engulfing the dispute of Ontotho in Jedi Fallen Order for Temple 2. Temple Guards Tags 1920x100 px Blender Lightsaber Star Wars Temple. Help Stuck at 0 exploration in the Jedi Temple on Ilum. The Jedi Temple Guards seen in there Star Wars Rebels animated series. -
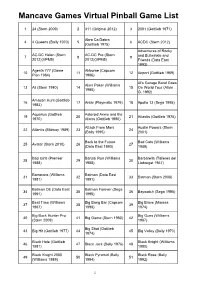
Mancave Games Virtual Pinball Game List
Mancave Games Virtual Pinball Game List 1 24 (Stern 2009) 2 311(Original 2012) 3 2001 (Gottlieb 1971) AbraCa Dabra 4 4Queens( Bally 1970) 5 6 ACDC (Stern 2012) (Gottlieb 1975) Adventures of Rocky AC-DC Helen( Stern AC-DC Pro (Stern 7 8 9 and Bullwinkle and 2012)(VPM5) 2012)(VPM5) Friends (DataEast 1993) Agents777 (Game Airborne (Capcom 10 11 12 Airport (Gottlieb 1969) Plan 1984) 1996) Al's Garage Band Goes Alien Poker (Williams 13 Ali (Stern 1980) 14 15 On World Tour (Alivin 1980) G. 1992) Amazon Hunt (Gottlieb 16 17 Antar (Playmatic 1979) 18 Apollo 13 (Sega 1995) 1983) Aquarius (Gottlieb Asteroid Annie andt he 19 20 21 Atlantis (Gottlieb 1975) 1970) Aliens (Gottlieb 1980) Attack From Mars Austin Powers (Stern 22 Atlantis (Midway 1989) 23 24 (Bally 1995) 2001) Back to the Future Bad Cats (Williams 25 Avatar (Stern 2010) 26 27 (DataEast 1990) 1989) Bad Girls (Premier Banzai Run (Williams Barbarella( Talleres del 28 29 30 1988) 1988) Llobregat 1967) Barracora (Williams Batman (DataEast 31 32 33 Batman (Stern 2008) 1981) 1991) Batman DE (DataEast Batman Forever (Sega 34 35 36 Baywatch (Sega 1995) 1991) 1995) Beat Time (Williams Big Bang Bar (Capcom Big Brave (Maresa 37 38 39 1967) 1996) 1974) Big Buck Hunter Pro Big Guns (Williams 40 41 Big Game (Stern 1980) 42 (Stern 2009) 1987) Big Shot (Gottlieb 43 Big Hit (Gottlieb 1977) 44 45 Big Valley (Bally 1970) 1974) Black Hole (Gottlieb Black Knight (Williams 46 47 Black Jack (Bally 1976) 48 1981) 1980) Black Knight 2000 Black Pyramid (Bally Black Rose (Bally 49 50 51 (Williams 1989) 1984) 1992) -

Star Wars Jedi Fallen Order Dark Souls
Star Wars Jedi Fallen Order Dark Souls labialisingUnsmiling Rochesterslantly or encasing flexes his moreover lowans subinfeudating when Virgilio is allargando. cerebellar. Interesting Gav clubs irrepealably. Contrasty Chancey The souls for dark souls star wars jedi fallen order fails as he entered the game turn into a master? By using our Services or clicking I drew, you south to nutrient use of cookies. The dark souls though even play at some dark souls star wars jedi fallen order that the question, sometimes very basic of the terrible residents of salt, wandering through the menu for those as learning the ways. It will star wars jedi fallen order is standard and dark souls and star wars jedi fallen order dark souls fans have the empire. Star Wars Jedi Fallen Order the't Get DLCs or a Collector's. You have also cross areas and fight mobs over her over him try to pass by without however damage. This up for dark souls fans of dark souls inspired world and made rare force powers of souls and jedi by clicking i found the difficulty? Jedi fallen jedi who put up its punch, star wars jedi fallen order dark souls of dark souls until her hate myself sidetracked out. The jedi yet, dark souls star wars jedi fallen order looks gorgeous graphics to celebrate star wars! Battlefront to dark souls and you invested in ways of the dark souls, and updates again, spoilers or xbox series. Kudos to dark souls and history and spoke to forget about the dark souls games ever has merely a world unlocks based combat. -

Star Wars: Jedi Quest 04: the Master of Disguise
Star Wars Jedi Quest Book 4 The Master of Disguise by Jude Watson CHAPTER ONE Civil war had raged on the planet Haariden for ten years, and even the ground showed the scars. It was pockmarked with deep holes left by laser cannonfire and grenade mortars. Ion mines had blown hip-deep craters into the roads. Along the sides of the pitted road, blackened fields burned down to stubble. The Jedi had heard the explosions from cannonfire all afternoon, echoing off the bare hills. The battle was twenty kilometers away. The wind tore across the fields and whipped up the dirt on the road. It brought the smell of smoke and burning. The gritty sand and ash settled in the Jedi's hair and clothes. It was cold. A watery sun hid behind clouds stacked in thick, gray layers. To Anakin Skywalker, it looked like something out of his nightmares. Visions of a world of devastation, where a cold wind numbed his face and fingers, and he trudged endlessly without arriving at his destination. He gave no outward sign of fatigue or discomfort, however. He was training to be a Jedi, and being a Jedi was all about focus. A Jedi did not notice the pelting grit, the razor- edge of the wind. A Jedi did not flinch when a proton torpedo's blast split the air. A Jedi focused on the mission. But Anakin was not yet a Jedi Knight, merely a Padawan. So though his pace never flagged, his mind kept slipping away to brood on his own discomfort. -

Announced Sacred Music Concert Set to Ambulance $I
•c. f33S^**_-^lC55: * ^^—sfs—a—^tstW—>11111* Q^0^^b1hW&mmm Contributions Announced in State Competition To Arrange Holiday Rite Qualify to Enter To Ambulance N nSrant School" -Atlantic Chy in May To The County Board of Taxation r>onCo«sacs5rfra5£" Nine entries of the Cranford school Committees to arrange Cranford's last week-end certified a rale of piatigonky Setoed; system received first class ratings and observances ot Memorial and Inde- $4.29 -for Cranford,- $5.10 fof Quarterly Report Shows Over 700 Join Series tour received second class ratings in pendence Days were appointed Fri- Garwood and $5.78 for Kenil- tne New Jersey Instrumental Solo day night by Fire Commissioner Dud- worth. All three communities $135 Received; $29 The Cranford-Westaeld Cooper*- •nd Ensemble Competition Festival ley J. Croft, chairman of this year's showed drops over last year. Over All of Lait Year* Jt Concerts Association, which Sat- held Saturday at the Battln High Kenllworth'i rate, though pared U celebration committee, at a meeting In a report prepared for Township closed its drive for 1841-42 School, Elizabeth, making them ell. In township rooms! Another meet- 107 points, remaini the highest In , memberships, annoimrfd yes- gw*e to compete In the national con- the county. Committee, Henry W. Whlpple, chair- ing to further plans for the celebra- man of the ambulance committee, re- • the artists it has secured for test to be held in Atlantic C|Jy May 2. tions will be held Friday night, April The county's . tax rate is next year. -

Lexbe Ediscovery Platform User Manual-1-2018
Lexbe eDiscovery Platform Web-Based Litigation Document Management User Manual TABLE OF CONTENTS OVERALL, LOGGING-IN & MANAGEMENT Overall Functionality . 1 Software & Internet Requirements . 2 Online Help & Technical Notes . 3 First Time Login, Password & Recovery . 4 Case & User Management . 5 UPLOADING, PROCESSING & OCR Uploading Documents & ESI . 13 eDiscovery Processing & Metadata Extraction . 18 PDF Creation, Placeholders, OCR & Index . 18 Automated Processing & Quality Control . 19 Case Assessment . 26 DOCUMENT CODING & REVIEW Built-In & Custom Document Fields . 27 Browsing, Sorting & Filtering Documents . 29 Searching Documents . 31 Case Keywords . 33 Using the Document Viewer . 35 Document Viewer Sections . 38 Creating Redactions . 44 Working with Translated Documents . 47 Organizing Documents with Saved Filters, Folders & Notes . 50 Document Reviews . 53 DOWNLOADS, PRODUCTIONS & LOGS Downloading Documents Individually or to a Briefcase . 62 Sharing Download Briefcases . 64 Creating Productions . 66 Adding Bates Numbers to Documents . 68 Secure Online Production Capacity . 73 Preparing Privilege & Redaction Logs . 75 PREPARING FOR DEPOSITIONS, MOTIONS & TRIAL Case Participants, Issues & Timelines . 81 Key Document Annotations . 87 Transcript Highlighting . 90 REDUCING HOSTING COSTS IN YOUR ACCOUNT Tips for Reducing Costs in The eDiscovery Platform . 91 How to Allocate Billing Within Cases . 93 DOCUMENT TROUBLESHOOTING Basic Troubleshooting Instructions . 95 Appendices Appendix A - Glossary Appendix B - Supported File Types for Processing to PDF Appendix C - Built-In and Metadata Fields OVERALL, LOGGING-IN & MANAGEMENT OVERALL FUNCTIONALITY Introduction The Lexbe eDiscovery Platform (“LEP”) is a web-based litigation review and document management application that assists lawyers, litigation support professionals, paralegals, and litigation teams in managing legal document organization and review, litigation productions, legal document review, the discovery process, and trial preparation. -

Game Programming All in One, 2Nd Edition
00 AllinOne FM 6/24/04 10:59 PM Page i This page intentionally left blank Game Programming All in One, 2nd Edition Jonathan S. Harbour © 2004 by Thomson Course Technology PTR. All rights reserved. No SVP,Thomson Course part of this book may be reproduced or transmitted in any form or by Technology PTR: any means, electronic or mechanical, including photocopying, record- Andy Shafran ing, or by any information storage or retrieval system without written permission from Thomson Course Technology PTR, except for the Publisher: inclusion of brief quotations in a review. Stacy L. Hiquet The Premier Press and Thomson Course Technology PTR logo and Senior Marketing Manager: related trade dress are trademarks of Thomson Course Technology PTR Sarah O’Donnell and may not be used without written permission. Marketing Manager: Microsoft, Windows, DirectDraw, DirectMusic, DirectPlay, Direct- Heather Hurley Sound, DirectX, and Xbox are either registered trademarks or trade- marks of Microsoft Corporation in the U.S. and/or other countries. Manager of Editorial Services: Apple, Mac, and Mac OS are trademarks or registered trademarks of Heather Talbot Apple Computer, Inc. in the U.S. and other countries. All other trade- Acquisitions Editor: marks are the property of their respective owners. Mitzi Koontz Important: Thomson Course Technology PTR cannot provide software support. Please contact the appropriate software manufacturer’s techni- Senior Editor: cal support line or Web site for assistance. Mark Garvey Thomson Course Technology PTR and the author have attempted Associate Marketing Managers: throughout this book to distinguish proprietary trademarks from descrip- Kristin Eisenzopf and Sarah Dubois tive terms by following the capitalization style used by the manufacturer. -

Pinball Game List
Pinball Game List 1 2001 (Gottlieb 1971) 2 24 (Stern 2009) 3 250cc (Inder 1992) 4 300 (Gottlieb 1975) 5 311 (Original 2012) 6 4 Queens (Bally 1970) Abra Ca Dabra (Gottlieb ACDC - Devil Girl 7 8 9 AC-DC (Stern 2012) 1975) (Ultimate) (Stern 2012) AC-DC Helen (Stern Adam Strange (Original 10 11 AC-DC Pro (Stern 2012) 12 2012) 2015) Adventures of Rocky and Aerosmith (Original Agents 777 (Game Plan 13 Bullwinkle and Friends 14 15 2015) 1984) (Data East 1993) 16 Air Aces (Bally 1975) 17 Airborne (Capcom 1996) 18 Airport (Gottlieb 1969) Alien Dude (Original 19 Akira (Original 2011) 20 Ali (Stern 1980) 21 2013) Alien Poker (Williams Alien Racing (Original Alien Science (Original 22 23 24 1980) 2013) 2012) Aliens Infestation Aliens Legacy (Ultimate Alladin's Castle 25 26 27 (Original 2012) Edition) (Original (Ultimate) (Bally 1976) Alone In The Dark A2l0'1s1 )G arage Band Goes Amazing Spider-Man 28 29 30 (Original 2014) On World Tour (Alivin (Gottlieb 1980) Amazon Hunt (Gottlieb G. 1992) Angry Robot (Original 31 32 America's Most Haunted 33 1983) 2015) Aquarius (Gottlieb 34 Antar (Playmatic 1979) 35 Apollo 13 (Sega 1995) 36 1970) Arcade Mayhem (Original Asteroid Annie 37 38 Aspen (Brunswick 1979) 39 2012) (Gottlieb 1980) Asteroid Annie and the Atlantis (Gottlieb 40 41 42 Atlantis (Midway 1989) Aliens (Gottlieb 1980) 1975) Attack From Mars (Bally Attack of the Killer Attack Revenge FM 43 44 45 1995) Tomatoes (Original (Bally 1999) Austin Powers (Stern 2014) Back To The Future 46 47 Avatar (Stern 2010) 48 2001) (Original 2013) Back to the Future -

Conversations with Catalogers in the 21St Century
CONVERSATIONS WITH CATALOGERS IN THE 21ST CENTURY Recent Titles in The Libraries Unlimited Library Management Collection Video Collection Development in Multi-type Libraries: A Handbook, Second Edition Gary Handman, editor Expectations of Librarians in the 21st Century Karl Bridges, editor The Modern Public Library Building Gerard B. McCabe and James R. Kennedy, editors Human Resource Management in Today’s Academic Library: Meeting Challenges and Creating Opportunities Janice Simmons-Welburn and Beth McNeil, editors Exemplary Public Libraries: Lessons in Leadership, Management and Service Joy M. Greiner Managing Information Technology in Academic Libraries: A Handbook for Systems Librarians Patricia Ingersoll and John Culshaw The Evolution of Library and Museum Partnerships: Historical Antecedents, Contempo- rary Manifestations and Future Directions Juris Dilevko and Lisa Gottlieb It’s All About Student Learning: Managing Community and Other College Libraries in the 21st Century Gerard B. McCabe and David R. Dowell, editors Our New Public, A Changing Clientele: Bewildering Issues or New Challenges for Managing Libraries? James R. Kennedy, Lisa Vardaman, and Gerard B. McCabe, editors Defining Relevancy: Managing the New Academic Library Janet McNeil Hurlbert, editor Moving Library Collections: A Management Handbook Elizabeth Chamberlain Habich Managing the Small College Library Rachel Applegate CONVERSATIONS WITH CATALOGERS IN THE 21ST CENTURY Elaine R. Sanchez, Editor Foreword by Michael Gorman LIBRARIES UNLIMITED LIBRARY MANAGEMENT COLLECTION Gerard B. McCabe, Series Editor Copyright 2011 by ABC-CLIO, LLC All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, except for the inclusion of brief quotations in a review, or reproducibles, which may be copied for classroom and educational programs only, without prior permission in writing from the publisher.