1 SUPPLEMENTARY INFORMATION 1 2 an Archaeal Symbiont
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
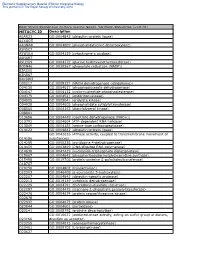
METACYC ID Description A0AR23 GO:0004842 (Ubiquitin-Protein Ligase
Electronic Supplementary Material (ESI) for Integrative Biology This journal is © The Royal Society of Chemistry 2012 Heat Stress Responsive Zostera marina Genes, Southern Population (α=0. -

The Pennsylvania State University the Graduate School Department
The Pennsylvania State University The Graduate School Department of Chemistry SUBSTRATE POSITIONING AND CHANNELING OF ESCHERICHIA COLI QUINOLINATE SYNTHASE A Thesis in Chemistry by Lauren A. Sites 2012 Lauren A. Sites Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science December 2012 ii The thesis of Lauren A. Sites was reviewed and approved* by the following: Squire J. Booker Associate Professor of Chemistry Thesis Advisor Carsten Krebs Professor of Chemistry Scott A. Showalter Assistant Professor of Chemistry Kenneth S. Feldman Professor of Chemistry Head of Department *Signatures are on file in the Graduate School iii ABSTRACT The essential cofactor nicotinamide adenine dinucleotide (NAD) is consumed in many metabolic reactions in the cell, necessitating the need to synthesize NAD. In most bacteria, the de novo pathway to form NAD begins with two unique enzymes that have been extensively studied herein. The first enzyme in the pathway, L-aspartate oxidase, performs a two-electron oxidation of L-aspartate to form iminoaspartate. This flavin containing enzyme can undergo multiple catalytic turnovers given the oxidants, fumarate or molecular oxygen, to afford the oxidized form of the enzyme. The second enzyme in the pathway, quinolinate synthase or NadA, condenses iminoaspartate and dihydroxyacetone phosphate to form quinolinic acid, the backbone of the pyridine ring of NAD. Many have postulated that these two enzymes can operate as an enzyme complex, yet no substantial evidence of this complex has been demonstrated. Investigations to examine the possible protein-protein interactions of the two enzymes were carried out, yet no obvious interaction was seen by the techniques employed. -

Supplemental Information to Mammadova-Bach Et Al., “Laminin Α1 Orchestrates VEGFA Functions in the Ecosystem of Colorectal Carcinogenesis”
Supplemental information to Mammadova-Bach et al., “Laminin α1 orchestrates VEGFA functions in the ecosystem of colorectal carcinogenesis” Supplemental material and methods Cloning of the villin-LMα1 vector The plasmid pBS-villin-promoter containing the 3.5 Kb of the murine villin promoter, the first non coding exon, 5.5 kb of the first intron and 15 nucleotides of the second villin exon, was generated by S. Robine (Institut Curie, Paris, France). The EcoRI site in the multi cloning site was destroyed by fill in ligation with T4 polymerase according to the manufacturer`s instructions (New England Biolabs, Ozyme, Saint Quentin en Yvelines, France). Site directed mutagenesis (GeneEditor in vitro Site-Directed Mutagenesis system, Promega, Charbonnières-les-Bains, France) was then used to introduce a BsiWI site before the start codon of the villin coding sequence using the 5’ phosphorylated primer: 5’CCTTCTCCTCTAGGCTCGCGTACGATGACGTCGGACTTGCGG3’. A double strand annealed oligonucleotide, 5’GGCCGGACGCGTGAATTCGTCGACGC3’ and 5’GGCCGCGTCGACGAATTCACGC GTCC3’ containing restriction site for MluI, EcoRI and SalI were inserted in the NotI site (present in the multi cloning site), generating the plasmid pBS-villin-promoter-MES. The SV40 polyA region of the pEGFP plasmid (Clontech, Ozyme, Saint Quentin Yvelines, France) was amplified by PCR using primers 5’GGCGCCTCTAGATCATAATCAGCCATA3’ and 5’GGCGCCCTTAAGATACATTGATGAGTT3’ before subcloning into the pGEMTeasy vector (Promega, Charbonnières-les-Bains, France). After EcoRI digestion, the SV40 polyA fragment was purified with the NucleoSpin Extract II kit (Machery-Nagel, Hoerdt, France) and then subcloned into the EcoRI site of the plasmid pBS-villin-promoter-MES. Site directed mutagenesis was used to introduce a BsiWI site (5’ phosphorylated AGCGCAGGGAGCGGCGGCCGTACGATGCGCGGCAGCGGCACG3’) before the initiation codon and a MluI site (5’ phosphorylated 1 CCCGGGCCTGAGCCCTAAACGCGTGCCAGCCTCTGCCCTTGG3’) after the stop codon in the full length cDNA coding for the mouse LMα1 in the pCIS vector (kindly provided by P. -

Enzymatic Encoding Methods for Efficient Synthesis Of
(19) TZZ__T (11) EP 1 957 644 B1 (12) EUROPEAN PATENT SPECIFICATION (45) Date of publication and mention (51) Int Cl.: of the grant of the patent: C12N 15/10 (2006.01) C12Q 1/68 (2006.01) 01.12.2010 Bulletin 2010/48 C40B 40/06 (2006.01) C40B 50/06 (2006.01) (21) Application number: 06818144.5 (86) International application number: PCT/DK2006/000685 (22) Date of filing: 01.12.2006 (87) International publication number: WO 2007/062664 (07.06.2007 Gazette 2007/23) (54) ENZYMATIC ENCODING METHODS FOR EFFICIENT SYNTHESIS OF LARGE LIBRARIES ENZYMVERMITTELNDE KODIERUNGSMETHODEN FÜR EINE EFFIZIENTE SYNTHESE VON GROSSEN BIBLIOTHEKEN PROCEDES DE CODAGE ENZYMATIQUE DESTINES A LA SYNTHESE EFFICACE DE BIBLIOTHEQUES IMPORTANTES (84) Designated Contracting States: • GOLDBECH, Anne AT BE BG CH CY CZ DE DK EE ES FI FR GB GR DK-2200 Copenhagen N (DK) HU IE IS IT LI LT LU LV MC NL PL PT RO SE SI • DE LEON, Daen SK TR DK-2300 Copenhagen S (DK) Designated Extension States: • KALDOR, Ditte Kievsmose AL BA HR MK RS DK-2880 Bagsvaerd (DK) • SLØK, Frank Abilgaard (30) Priority: 01.12.2005 DK 200501704 DK-3450 Allerød (DK) 02.12.2005 US 741490 P • HUSEMOEN, Birgitte Nystrup DK-2500 Valby (DK) (43) Date of publication of application: • DOLBERG, Johannes 20.08.2008 Bulletin 2008/34 DK-1674 Copenhagen V (DK) • JENSEN, Kim Birkebæk (73) Proprietor: Nuevolution A/S DK-2610 Rødovre (DK) 2100 Copenhagen 0 (DK) • PETERSEN, Lene DK-2100 Copenhagen Ø (DK) (72) Inventors: • NØRREGAARD-MADSEN, Mads • FRANCH, Thomas DK-3460 Birkerød (DK) DK-3070 Snekkersten (DK) • GODSKESEN, -

Part One Amino Acids As Building Blocks
Part One Amino Acids as Building Blocks Amino Acids, Peptides and Proteins in Organic Chemistry. Vol.3 – Building Blocks, Catalysis and Coupling Chemistry. Edited by Andrew B. Hughes Copyright Ó 2011 WILEY-VCH Verlag GmbH & Co. KGaA, Weinheim ISBN: 978-3-527-32102-5 j3 1 Amino Acid Biosynthesis Emily J. Parker and Andrew J. Pratt 1.1 Introduction The ribosomal synthesis of proteins utilizes a family of 20 a-amino acids that are universally coded by the translation machinery; in addition, two further a-amino acids, selenocysteine and pyrrolysine, are now believed to be incorporated into proteins via ribosomal synthesis in some organisms. More than 300 other amino acid residues have been identified in proteins, but most are of restricted distribution and produced via post-translational modification of the ubiquitous protein amino acids [1]. The ribosomally encoded a-amino acids described here ultimately derive from a-keto acids by a process corresponding to reductive amination. The most important biosynthetic distinction relates to whether appropriate carbon skeletons are pre-existing in basic metabolism or whether they have to be synthesized de novo and this division underpins the structure of this chapter. There are a small number of a-keto acids ubiquitously found in core metabolism, notably pyruvate (and a related 3-phosphoglycerate derivative from glycolysis), together with two components of the tricarboxylic acid cycle (TCA), oxaloacetate and a-ketoglutarate (a-KG). These building blocks ultimately provide the carbon skeletons for unbranched a-amino acids of three, four, and five carbons, respectively. a-Amino acids with shorter (glycine) or longer (lysine and pyrrolysine) straight chains are made by alternative pathways depending on the available raw materials. -

Generated by SRI International Pathway Tools Version 25.0, Authors S
An online version of this diagram is available at BioCyc.org. Biosynthetic pathways are positioned in the left of the cytoplasm, degradative pathways on the right, and reactions not assigned to any pathway are in the far right of the cytoplasm. Transporters and membrane proteins are shown on the membrane. Periplasmic (where appropriate) and extracellular reactions and proteins may also be shown. Pathways are colored according to their cellular function. Gcf_000238675-HmpCyc: Bacillus smithii 7_3_47FAA Cellular Overview Connections between pathways are omitted for legibility. -

Association Between the Gut Microbiota and Blood Pressure in a Population Cohort of 6953 Individuals
Journal of the American Heart Association ORIGINAL RESEARCH Association Between the Gut Microbiota and Blood Pressure in a Population Cohort of 6953 Individuals Joonatan Palmu , MD; Aaro Salosensaari , MSc; Aki S. Havulinna , DSc (Tech); Susan Cheng , MD, MPH; Michael Inouye, PhD; Mohit Jain, MD, PhD; Rodolfo A. Salido , BSc; Karenina Sanders , BSc; Caitriona Brennan, BSc; Gregory C. Humphrey, BSc; Jon G. Sanders , PhD; Erkki Vartiainen , MD, PhD; Tiina Laatikainen , MD, PhD; Pekka Jousilahti, MD, PhD; Veikko Salomaa , MD, PhD; Rob Knight , PhD; Leo Lahti , DSc (Tech); Teemu J. Niiranen , MD, PhD BACKGROUND: Several small-scale animal studies have suggested that gut microbiota and blood pressure (BP) are linked. However, results from human studies remain scarce and conflicting. We wanted to elucidate the multivariable-adjusted as- sociation between gut metagenome and BP in a large, representative, well-phenotyped population sample. We performed a focused analysis to examine the previously reported inverse associations between sodium intake and Lactobacillus abun- dance and between Lactobacillus abundance and BP. METHODS AND RESULTS: We studied a population sample of 6953 Finns aged 25 to 74 years (mean age, 49.2±12.9 years; 54.9% women). The participants underwent a health examination, which included BP measurement, stool collection, and 24-hour urine sampling (N=829). Gut microbiota was analyzed using shallow shotgun metagenome sequencing. In age- and sex-adjusted models, the α (within-sample) and β (between-sample) diversities of taxonomic composition were strongly re- lated to BP indexes (P<0.001 for most). In multivariable-adjusted models, β diversity was only associated with diastolic BP (P=0.032). -

Supplementary Materials
1 Supplementary Materials: Supplemental Figure 1. Gene expression profiles of kidneys in the Fcgr2b-/- and Fcgr2b-/-. Stinggt/gt mice. (A) A heat map of microarray data show the genes that significantly changed up to 2 fold compared between Fcgr2b-/- and Fcgr2b-/-. Stinggt/gt mice (N=4 mice per group; p<0.05). Data show in log2 (sample/wild-type). 2 Supplemental Figure 2. Sting signaling is essential for immuno-phenotypes of the Fcgr2b-/-lupus mice. (A-C) Flow cytometry analysis of splenocytes isolated from wild-type, Fcgr2b-/- and Fcgr2b-/-. Stinggt/gt mice at the age of 6-7 months (N= 13-14 per group). Data shown in the percentage of (A) CD4+ ICOS+ cells, (B) B220+ I-Ab+ cells and (C) CD138+ cells. Data show as mean ± SEM (*p < 0.05, **p<0.01 and ***p<0.001). 3 Supplemental Figure 3. Phenotypes of Sting activated dendritic cells. (A) Representative of western blot analysis from immunoprecipitation with Sting of Fcgr2b-/- mice (N= 4). The band was shown in STING protein of activated BMDC with DMXAA at 0, 3 and 6 hr. and phosphorylation of STING at Ser357. (B) Mass spectra of phosphorylation of STING at Ser357 of activated BMDC from Fcgr2b-/- mice after stimulated with DMXAA for 3 hour and followed by immunoprecipitation with STING. (C) Sting-activated BMDC were co-cultured with LYN inhibitor PP2 and analyzed by flow cytometry, which showed the mean fluorescence intensity (MFI) of IAb expressing DC (N = 3 mice per group). 4 Supplemental Table 1. Lists of up and down of regulated proteins Accession No. -

Supplementary Table S1. Table 1. List of Bacterial Strains Used in This Study Suppl
Supplementary Material Supplementary Tables: Supplementary Table S1. Table 1. List of bacterial strains used in this study Supplementary Table S2. List of plasmids used in this study Supplementary Table 3. List of primers used for mutagenesis of P. intermedia Supplementary Table 4. List of primers used for qRT-PCR analysis in P. intermedia Supplementary Table 5. List of the most highly upregulated genes in P. intermedia OxyR mutant Supplementary Table 6. List of the most highly downregulated genes in P. intermedia OxyR mutant Supplementary Table 7. List of the most highly upregulated genes in P. intermedia grown in iron-deplete conditions Supplementary Table 8. List of the most highly downregulated genes in P. intermedia grown in iron-deplete conditions Supplementary Figures: Supplementary Figure 1. Comparison of the genomic loci encoding OxyR in Prevotella species. Supplementary Figure 2. Distribution of SOD and glutathione peroxidase genes within the genus Prevotella. Supplementary Table S1. Bacterial strains Strain Description Source or reference P. intermedia V3147 Wild type OMA14 isolated from the (1) periodontal pocket of a Japanese patient with periodontitis V3203 OMA14 PIOMA14_I_0073(oxyR)::ermF This study E. coli XL-1 Blue Host strain for cloning Stratagene S17-1 RP-4-2-Tc::Mu aph::Tn7 recA, Smr (2) 1 Supplementary Table S2. Plasmids Plasmid Relevant property Source or reference pUC118 Takara pBSSK pNDR-Dual Clonetech pTCB Apr Tcr, E. coli-Bacteroides shuttle vector (3) plasmid pKD954 Contains the Porpyromonas gulae catalase (4) -

Yeast Genome Gazetteer P35-65
gazetteer Metabolism 35 tRNA modification mitochondrial transport amino-acid metabolism other tRNA-transcription activities vesicular transport (Golgi network, etc.) nitrogen and sulphur metabolism mRNA synthesis peroxisomal transport nucleotide metabolism mRNA processing (splicing) vacuolar transport phosphate metabolism mRNA processing (5’-end, 3’-end processing extracellular transport carbohydrate metabolism and mRNA degradation) cellular import lipid, fatty-acid and sterol metabolism other mRNA-transcription activities other intracellular-transport activities biosynthesis of vitamins, cofactors and RNA transport prosthetic groups other transcription activities Cellular organization and biogenesis 54 ionic homeostasis organization and biogenesis of cell wall and Protein synthesis 48 plasma membrane Energy 40 ribosomal proteins organization and biogenesis of glycolysis translation (initiation,elongation and cytoskeleton gluconeogenesis termination) organization and biogenesis of endoplasmic pentose-phosphate pathway translational control reticulum and Golgi tricarboxylic-acid pathway tRNA synthetases organization and biogenesis of chromosome respiration other protein-synthesis activities structure fermentation mitochondrial organization and biogenesis metabolism of energy reserves (glycogen Protein destination 49 peroxisomal organization and biogenesis and trehalose) protein folding and stabilization endosomal organization and biogenesis other energy-generation activities protein targeting, sorting and translocation vacuolar and lysosomal -

Circuits Regulating Superoxide and Nitric Oxide
antioxidants Article Circuits Regulating Superoxide and Nitric Oxide Production and Neutralization in Different Cell Types: Expression of Participating Genes and Changes Induced by Ionizing Radiation 1,2, 1,2, 1 1,2, Patryk Bil y, Sylwia Ciesielska y, Roman Jaksik and Joanna Rzeszowska-Wolny * 1 Department of Systems Biology and Engineering, Faculty of Automatic Control, Electronics and Computer Science, Silesian University of Technology, 44-100 Gliwice, Poland; [email protected] (P.B.); [email protected] (S.C.); [email protected] (R.J.) 2 Biotechnology Centre, Silesian University of Technology, 44-100 Gliwice, Poland * Correspondence: [email protected] These authors contributed equally. y Received: 30 June 2020; Accepted: 29 July 2020; Published: 3 August 2020 Abstract: Superoxide radicals, together with nitric oxide (NO), determine the oxidative status of cells, which use different pathways to control their levels in response to stressing conditions. Using gene expression data available in the Cancer Cell Line Encyclopedia and microarray results, we compared the expression of genes engaged in pathways controlling reactive oxygen species and NO production, neutralization, and changes in response to the exposure of cells to ionizing radiation (IR) in human cancer cell lines originating from different tissues. The expression of NADPH oxidases and NO synthases that participate in superoxide radical and NO production was low in all cell types. Superoxide dismutase, glutathione peroxidase, thioredoxin, and peroxiredoxins participating in radical neutralization showed high expression in nearly all cell types. Some enzymes that may indirectly influence superoxide radical and NO levels showed tissue-specific expression and differences in response to IR. -

Genome-Scale Fitness Profile of Caulobacter Crescentus Grown in Natural Freshwater
Supplemental Material Genome-scale fitness profile of Caulobacter crescentus grown in natural freshwater Kristy L. Hentchel, Leila M. Reyes Ruiz, Aretha Fiebig, Patrick D. Curtis, Maureen L. Coleman, Sean Crosson Tn5 and Tn-Himar: comparing gene essentiality and the effects of gene disruption on fitness across studies A previous analysis of a highly saturated Caulobacter Tn5 transposon library revealed a set of genes that are required for growth in complex PYE medium [1]; approximately 14% of genes in the genome were deemed essential. The total genome insertion coverage was lower in the Himar library described here than in the Tn5 dataset of Christen et al (2011), as Tn-Himar inserts specifically into TA dinucleotide sites (with 67% GC content, TA sites are relatively limited in the Caulobacter genome). Genes for which we failed to detect Tn-Himar insertions (Table S13) were largely consistent with essential genes reported by Christen et al [1], with exceptions likely due to differential coverage of Tn5 versus Tn-Himar mutagenesis and differences in metrics used to define essentiality. A comparison of the essential genes defined by Christen et al and by our Tn5-seq and Tn-Himar fitness studies is presented in Table S4. We have uncovered evidence for gene disruptions that both enhanced or reduced strain fitness in lake water and M2X relative to PYE. Such results are consistent for a number of genes across both the Tn5 and Tn-Himar datasets. Disruption of genes encoding three metabolic enzymes, a class C β-lactamase family protein (CCNA_00255), transaldolase (CCNA_03729), and methylcrotonyl-CoA carboxylase (CCNA_02250), enhanced Caulobacter fitness in Lake Michigan water relative to PYE using both Tn5 and Tn-Himar approaches (Table S7).