Open Targets Platform: New Developments and Updates Two Years On
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Staurotypus Turtles and Aves Share the Same Origin of Sex Chromosomes but Evolved Different Types of Heterogametic Sex Determination
The Staurotypus Turtles and Aves Share the Same Origin of Sex Chromosomes but Evolved Different Types of Heterogametic Sex Determination Taiki Kawagoshi1, Yoshinobu Uno1, Chizuko Nishida2, Yoichi Matsuda1,3* 1 Laboratory of Animal Genetics, Department of Applied Molecular Biosciences, Graduate School of Bioagricultural Sciences, Nagoya University, Nagoya, Japan, 2 Department of Natural History Sciences, Faculty of Science, Hokkaido University, Sapporo, Japan, 3 Avian Bioscience Research Center, Graduate School of Bioagricultural Sciences, Nagoya University, Nagoya, Japan Abstract Reptiles have a wide diversity of sex-determining mechanisms and types of sex chromosomes. Turtles exhibit temperature- dependent sex determination and genotypic sex determination, with male heterogametic (XX/XY) and female heterogametic (ZZ/ZW) sex chromosomes. Identification of sex chromosomes in many turtle species and their comparative genomic analysis are of great significance to understand the evolutionary processes of sex determination and sex chromosome differentiation in Testudines. The Mexican giant musk turtle (Staurotypus triporcatus, Kinosternidae, Testudines) and the giant musk turtle (Staurotypus salvinii) have heteromorphic XY sex chromosomes with a low degree of morphological differentiation; however, their origin and linkage group are still unknown. Cross-species chromosome painting with chromosome-specific DNA from Chinese soft-shelled turtle (Pelodiscus sinensis) revealed that the X and Y chromosomes of S. triporcatus have homology with P. sinensis chromosome 6, which corresponds to the chicken Z chromosome. We cloned cDNA fragments of S. triporcatus homologs of 16 chicken Z-linked genes and mapped them to S. triporcatus and S. salvinii chromosomes using fluorescence in situ hybridization. Sixteen genes were localized to the X and Y long arms in the same order in both species. -

Role of Transfer RNA Modification and Aminoacylation in the Etiology of Congenital Intellectual Disability
Franz et al. J Transl Genet Genom 2020;4:50-70 Journal of Translational DOI: 10.20517/jtgg.2020.13 Genetics and Genomics Review Open Access Role of transfer RNA modification and aminoacylation in the etiology of congenital intellectual disability Martin Franz#, Lisa Hagenau#, Lars R. Jensen, Andreas W. Kuss Department of Functional Genomics, Interfaculty Institute for Genetics and Functional Genomics, University Medicine Greifswald, Greifswald 17475, Germany. #Authors cotributed equally. Correspondence to: Prof. Andreas W. Kuss; Dr. Lars R. Jensen, Department of Functional Genomics, University Medicine Greifswald, C_FunGene, Felix-Hausdorff-Str. 8, Greifswald 17475, Germany. E-mail: [email protected]; [email protected] How to cite this article: Franz M, Hagenau L, Jensen LR, Kuss AW. Role of transfer RNA modification and aminoacylation in the etiology of congenital intellectual disability. J Transl Genet Genom 2020;4:50-70. http://dx.doi.org/10.20517/jtgg.2020.13 Received: 14 Feb 2020 First Decision: 17 Mar 2020 Revised: 30 Mar 2020 Accepted: 23 Apr 2020 Available online: 16 May 2020 Science Editor: Tjitske Kleefstra Copy Editor: Jing-Wen Zhang Production Editor: Tian Zhang Abstract Transfer RNA (tRNA) modification and aminoacylation are post-transcriptional processes that play a crucial role in the function of tRNA and thus represent critical steps in gene expression. Knowledge of the exact processes and effects of the defects in various tRNAs remains incomplete, but a rapidly increasing number of publications over the last decade has shown a growing amount of evidence as to the importance of tRNAs for normal human development, including brain formation and the development and maintenance of higher cognitive functions as well. -

A Master Autoantigen-Ome Links Alternative Splicing, Female Predilection, and COVID-19 to Autoimmune Diseases
bioRxiv preprint doi: https://doi.org/10.1101/2021.07.30.454526; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. A Master Autoantigen-ome Links Alternative Splicing, Female Predilection, and COVID-19 to Autoimmune Diseases Julia Y. Wang1*, Michael W. Roehrl1, Victor B. Roehrl1, and Michael H. Roehrl2* 1 Curandis, New York, USA 2 Department of Pathology, Memorial Sloan Kettering Cancer Center, New York, USA * Correspondence: [email protected] or [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/2021.07.30.454526; this version posted August 4, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Abstract Chronic and debilitating autoimmune sequelae pose a grave concern for the post-COVID-19 pandemic era. Based on our discovery that the glycosaminoglycan dermatan sulfate (DS) displays peculiar affinity to apoptotic cells and autoantigens (autoAgs) and that DS-autoAg complexes cooperatively stimulate autoreactive B1 cell responses, we compiled a database of 751 candidate autoAgs from six human cell types. At least 657 of these have been found to be affected by SARS-CoV-2 infection based on currently available multi-omic COVID data, and at least 400 are confirmed targets of autoantibodies in a wide array of autoimmune diseases and cancer. -

PROTEOME of the HUMAN CHROMOSOME 18: GENE-CENTRIC IDENTIFICATION of TRANSCRIPTS, PROTEINS and PEPTIDES Addendum to the Roadmap
PROTEOME OF THE HUMAN CHROMOSOME 18: GENE-CENTRIC IDENTIFICATION OF TRANSCRIPTS, PROTEINS AND PEPTIDES Addendum to the Roadmap: HEALTH ASPECTS 1. PROTEOMICS MEETS MEDICINE At its very beginning, one of the goals of human proteomics became a disease biomarker discovery. Many works compared diseased and normal tissues and liquids to get diagnostic profiles by many proteomics methods. Of them, some cancer proteome profiling studies were considered too optimistic in terms of clinical applicability due to incorrect experimental design [Petricoin], thereby conferring the negative expectations from proteomics in translational medicine [Diamantidis, Nature]. The interlaboratory reproducibility of proteomics pipelines also was considered as a shortage in some papers, e.g. in the works of Bell et al [2009] who tested the proteome MS methods with 20-protein standard sample. These difficulties at the early stage of proteomics were partly caused by the fact that many attempts were mostly directed to the technique adjustment rather than to the clinically relevant result. However, the recent advances in mass-spectrometry including the use of MRM to quantify peptides of proteome [Anderson Hunter 2006] made the community to have a view of cautious optimism on the problem of translation to medicine [Nilsson 2010]. A reproducibility problem stated in [Bell 2009] was shown to be mainly caused by the bioinformatics misinterpretation whereas the MS itself worked properly. The readiness of MRM-based platforms to the clinical use is illustrated by the attempt to pass FDA with the mock application which describes MS-based quantitation test for 10 proteins [Regnier FE 2010]. In its current state, the test has not got a clearance. -

Network Pharmacological Mechanism Research of Herba Drynariae Rhizoma-Epimedii Folium in Treating Osteoarthritis
Yangtze Medicine, 2021, 5, 90-105 https://www.scirp.org/journal/ym ISSN Online: 2475-7349 ISSN Print: 2475-7330 Network Pharmacological Mechanism Research of Herba Drynariae Rhizoma-Epimedii Folium in Treating Osteoarthritis Zonghui Dai1*, Hui Chen1*, Yongtao Xu2# 1Department of Medicine, Yangtze University, Jingzhou, China 2Department of Orthopedics, Jingzhou Central Hospital, Second Clinical Medical Hospital, Yangtze University, Jingzhou, China How to cite this paper: Dai, Z.H., Chen, Abstract H. and Xu, Y.T. (2021) Network Pharma- cological Mechanism Research of Herba Objective: To investigate the potential mechanism of Drynariae Rhizo- Drynariae Rhizoma-Epimedii Folium in ma-Epimedii Folium in the treatment of osteoarthritis (OA) based on network Treating Osteoarthritis. Yangtze Medicine, pharmacology. Methods: The potential active constituents and targets of Dry- 5, 90-105. https://doi.org/10.4236/ym.2021.52010 nariae Rhizoma-Epimedii Folium were screened through the traditional Chi- nese medicine (TCM) systems pharmacology database and analysis platform Received: June 14, 2020 (TCMSP). Genecards database is used to find relevant targets of OA. The tar- Accepted: April 12, 2021 gets of “Drynariae Rhizoma-Epimedii Folium” were mapped to the targets of Published: April 15, 2021 OA, and used Cytoscape software to build a “drug-ingredient-target-di- sease” Copyright © 2021 by author(s) and regulatory network and protein protein interaction (PPI) network. R software Scientific Research Publishing Inc. was used to analyze the Gene ontology (GO) function and Kyoto encyclope- This work is licensed under the Creative dia of genes and genomes (KEGG) pathway enrichment of traditional Chi- Commons Attribution International License (CC BY 4.0). -

Mouse Nars Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Nars Knockout Project (CRISPR/Cas9) Objective: To create a Nars knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Nars gene (NCBI Reference Sequence: NM_001142950 ; Ensembl: ENSMUSG00000024587 ) is located on Mouse chromosome 18. 15 exons are identified, with the ATG start codon in exon 1 and the TAA stop codon in exon 15 (Transcript: ENSMUST00000237400). Exon 2~8 will be selected as target site. Cas9 and gRNA will be co-injected into fertilized eggs for KO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Exon 2 starts from about 2.62% of the coding region. Exon 2~8 covers 33.93% of the coding region. The size of effective KO region: ~7637 bp. The KO region does not have any other known gene. Page 1 of 9 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 2 3 4 5 6 7 8 15 Legends Exon of mouse Nars Knockout region Page 2 of 9 https://www.alphaknockout.com Overview of the Dot Plot (up) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 1007 bp section upstream of Exon 2 is aligned with itself to determine if there are tandem repeats. Tandem repeats are found in the dot plot matrix. The gRNA site is selected outside of these tandem repeats. Overview of the Dot Plot (down) Window size: 15 bp Forward Reverse Complement Sequence 12 Note: The 2000 bp section downstream of Exon 8 is aligned with itself to determine if there are tandem repeats. -
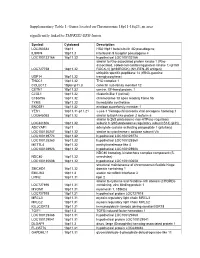
Supplementary Table 1: Genes Located on Chromosome 18P11-18Q23, an Area Significantly Linked to TMPRSS2-ERG Fusion
Supplementary Table 1: Genes located on Chromosome 18p11-18q23, an area significantly linked to TMPRSS2-ERG fusion Symbol Cytoband Description LOC260334 18p11 HSA18p11 beta-tubulin 4Q pseudogene IL9RP4 18p11.3 interleukin 9 receptor pseudogene 4 LOC100132166 18p11.32 hypothetical LOC100132166 similar to Rho-associated protein kinase 1 (Rho- associated, coiled-coil-containing protein kinase 1) (p160 LOC727758 18p11.32 ROCK-1) (p160ROCK) (NY-REN-35 antigen) ubiquitin specific peptidase 14 (tRNA-guanine USP14 18p11.32 transglycosylase) THOC1 18p11.32 THO complex 1 COLEC12 18pter-p11.3 collectin sub-family member 12 CETN1 18p11.32 centrin, EF-hand protein, 1 CLUL1 18p11.32 clusterin-like 1 (retinal) C18orf56 18p11.32 chromosome 18 open reading frame 56 TYMS 18p11.32 thymidylate synthetase ENOSF1 18p11.32 enolase superfamily member 1 YES1 18p11.31-p11.21 v-yes-1 Yamaguchi sarcoma viral oncogene homolog 1 LOC645053 18p11.32 similar to BolA-like protein 2 isoform a similar to 26S proteasome non-ATPase regulatory LOC441806 18p11.32 subunit 8 (26S proteasome regulatory subunit S14) (p31) ADCYAP1 18p11 adenylate cyclase activating polypeptide 1 (pituitary) LOC100130247 18p11.32 similar to cytochrome c oxidase subunit VIc LOC100129774 18p11.32 hypothetical LOC100129774 LOC100128360 18p11.32 hypothetical LOC100128360 METTL4 18p11.32 methyltransferase like 4 LOC100128926 18p11.32 hypothetical LOC100128926 NDC80 homolog, kinetochore complex component (S. NDC80 18p11.32 cerevisiae) LOC100130608 18p11.32 hypothetical LOC100130608 structural maintenance -

Novel Genes Associated with Colorectal Cancer Are Revealed by High Resolution Cytogenetic Analysis in a Patient Specific Manner
Novel Genes Associated with Colorectal Cancer Are Revealed by High Resolution Cytogenetic Analysis in a Patient Specific Manner Hisham Eldai1., Sathish Periyasamy1., Saeed Al Qarni2, Maha Al Rodayyan2, Sabeena Muhammed Mustafa1, Ahmad Deeb3, Ebthehal Al Sheikh2, Mohammed Afzal Khan4, Mishal Johani5, Zeyad Yousef6, Mohammad Azhar Aziz2*. 1 Bioinformatics, King Abdullah International Medical Research Center, Riyadh, Saudi Arabia, 2 Medical Biotechnology, King Abdullah International Medical Research Center, Riyadh, Saudi Arabia, 3 Research Office, King Abdullah International Medical Research Center, Riyadh, Saudi Arabia, 4 Anatomic pathology, National Guard Health Affairs, Riyadh, Saudi Arabia, 5 Endoscopy, National Guard Health Affairs, Riyadh, Saudi Arabia, 6 Surgery, National Guard Health Affairs, Riyadh, Saudi Arabia Abstract Genomic abnormalities leading to colorectal cancer (CRC) include somatic events causing copy number aberrations (CNAs) as well as copy neutral manifestations such as loss of heterozygosity (LOH) and uniparental disomy (UPD). We studied the causal effect of these events by analyzing high resolution cytogenetic microarray data of 15 tumor-normal paired samples. We detected 144 genes affected by CNAs. A subset of 91 genes are known to be CRC related yet high GISTIC scores indicate 24 genes on chromosomes 7, 8, 18 and 20 to be strongly relevant. Combining GISTIC ranking with functional analyses and degree of loss/gain we identify three genes in regions of significant loss (ATP8B1, NARS, and ATP5A1) and eight in regions of gain (CTCFL, SPO11, ZNF217, PLEKHA8, HOXA3, GPNMB, IGF2BP3 and PCAT1) as novel in their association with CRC. Pathway and target prediction analysis of CNA affected genes and microRNAs, respectively indicates TGF-b signaling pathway to be involved in causing CRC. -

Multiscale Genomic Analysis of The
University of Tennessee Health Science Center UTHSC Digital Commons Theses and Dissertations (ETD) College of Graduate Health Sciences 5-2009 Multiscale Genomic Analysis of the Corticolimbic System: Uncovering the Molecular and Anatomic Substrates of Anxiety-Related Behavior Khyobeni Mozhui University of Tennessee Health Science Center Follow this and additional works at: https://dc.uthsc.edu/dissertations Part of the Mental and Social Health Commons, Nervous System Commons, and the Neurosciences Commons Recommended Citation Mozhui, Khyobeni , "Multiscale Genomic Analysis of the Corticolimbic System: Uncovering the Molecular and Anatomic Substrates of Anxiety-Related Behavior" (2009). Theses and Dissertations (ETD). Paper 180. http://dx.doi.org/10.21007/etd.cghs.2009.0219. This Dissertation is brought to you for free and open access by the College of Graduate Health Sciences at UTHSC Digital Commons. It has been accepted for inclusion in Theses and Dissertations (ETD) by an authorized administrator of UTHSC Digital Commons. For more information, please contact [email protected]. Multiscale Genomic Analysis of the Corticolimbic System: Uncovering the Molecular and Anatomic Substrates of Anxiety-Related Behavior Document Type Dissertation Degree Name Doctor of Philosophy (PhD) Program Anatomy and Neurobiology Research Advisor Robert W. Williams, Ph.D. Committee John D. Boughter, Ph.D. Eldon E. Geisert, Ph.D. Kristin M. Hamre, Ph.D. Jeffery D. Steketee, Ph.D. DOI 10.21007/etd.cghs.2009.0219 This dissertation is available at UTHSC Digital -

Dissection of a QTL Hotspot on Mouse Distal Chromosome 1 That
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Faculty Papers and Publications in Animal Science Animal Science Department 2008 Dissection of a QTL Hotspot on Mouse Distal Chromosome 1 that Modulates Neurobehavioral Phenotypes and Gene Expression Khyobeni Mozhui University of Tennessee Health Science Center Daniel C. Bastiaansen University of Nebraska-Lincoln, [email protected] Thomas Schikorski University of Tennessee Health Science Center Xusheng Wang University of Tennessee Health Science Center Lu Lu University of Tennessee Health Science Center See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/animalscifacpub Part of the Genetics and Genomics Commons, and the Meat Science Commons Mozhui, Khyobeni; Bastiaansen, Daniel C.; Schikorski, Thomas; Wang, Xusheng; Lu, Lu; and Williams, Robert W., "Dissection of a QTL Hotspot on Mouse Distal Chromosome 1 that Modulates Neurobehavioral Phenotypes and Gene Expression" (2008). Faculty Papers and Publications in Animal Science. 936. https://digitalcommons.unl.edu/animalscifacpub/936 This Article is brought to you for free and open access by the Animal Science Department at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Faculty Papers and Publications in Animal Science by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Authors Khyobeni Mozhui, Daniel C. Bastiaansen, Thomas Schikorski, Xusheng Wang, Lu Lu, and Robert W. Williams This article is available at DigitalCommons@University of Nebraska - Lincoln: https://digitalcommons.unl.edu/animalscifacpub/936 Dissection of a QTL Hotspot on Mouse Distal Chromosome 1 that Modulates Neurobehavioral Phenotypes and Gene Expression Khyobeni Mozhui, Daniel C. Ciobanu, Thomas Schikorski, Xusheng Wang, Lu Lu, Robert W. -

Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations Fall 2010 Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Renuka Nayak University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Computational Biology Commons, and the Genomics Commons Recommended Citation Nayak, Renuka, "Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress" (2010). Publicly Accessible Penn Dissertations. 1559. https://repository.upenn.edu/edissertations/1559 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/1559 For more information, please contact [email protected]. Coexpression Networks Based on Natural Variation in Human Gene Expression at Baseline and Under Stress Abstract Genes interact in networks to orchestrate cellular processes. Here, we used coexpression networks based on natural variation in gene expression to study the functions and interactions of human genes. We asked how these networks change in response to stress. First, we studied human coexpression networks at baseline. We constructed networks by identifying correlations in expression levels of 8.9 million gene pairs in immortalized B cells from 295 individuals comprising three independent samples. The resulting networks allowed us to infer interactions between biological processes. We used the network to predict the functions of poorly-characterized human genes, and provided some experimental support. Examining genes implicated in disease, we found that IFIH1, a diabetes susceptibility gene, interacts with YES1, which affects glucose transport. Genes predisposing to the same diseases are clustered non-randomly in the network, suggesting that the network may be used to identify candidate genes that influence disease susceptibility. -
Drosophila Models of Pathogenic Copy-Number Variant Genes Show Global and Non-Neuronal Defects During Development
bioRxiv preprint doi: https://doi.org/10.1101/855338; this version posted November 26, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 Drosophila models of pathogenic copy-number variant genes show global and 2 non-neuronal defects during development 3 4 Tanzeen Yusuff1,4, Matthew Jensen1,4, Sneha Yennawar1,4, Lucilla Pizzo1, Siddharth 5 Karthikeyan1, Dagny J. Gould1, Avik Sarker1, Yurika Matsui1,2, Janani Iyer1, Zhi-Chun Lai1,2, 6 and Santhosh Girirajan1,3* 7 8 1. Department of Biochemistry and Molecular Biology, Pennsylvania State University, 9 University Park, PA 16802 10 2. Department of Biology, Pennsylvania State University, University Park, PA 16802 11 3. Department of Anthropology, Pennsylvania State University, University Park, PA 16802 12 13 4 contributed equally to work 14 15 16 *Correspondence: 17 Santhosh Girirajan, MBBS, PhD 18 205A Life Sciences Building 19 Pennsylvania State University 20 University Park, PA 16802 21 E-mail: [email protected] 22 Phone: 814-865-0674 23 1 bioRxiv preprint doi: https://doi.org/10.1101/855338; this version posted November 26, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 24 ABSTRACT 25 While rare pathogenic CNVs are associated with both neuronal and non-neuronal phenotypes, 26 functional studies evaluating these regions have focused on the molecular basis of neuronal 27 defects.