A Brief Introduction to the BSP Model 1 Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alberto J. L. Carrillo Canán Mcluhan, Flusser and the Mediatic Approach to Mind
FLUSSER STUDIES 06 1 Alberto J. L. Carrillo Canán McLuhan, Flusser and the Mediatic Approach to Mind All the alphabets in use in the Western world, from that of Russia to that of the Basques, from that of Portugal to that of Peru, are derivatives of the Graeco-Roman letters. Their unique separation of sight and sound from semantic and verbal content made them a most radical technology for the translation and homogeneization of cultures. All other forms of writing had served merely one culture, and had served to separate that culture from others. Marshall McLuhan Nowadays there are at least three main theoretical paradigms about mind. One is traditional philosophy about the mind-body problem, which is increasingly influenced by cognitive science. This paradigm presupposes the mind as trans-historical entity. Another paradigm lies implicit in semiotics and narratology: mind becomes dissolved in symbolic systems; accordingly, mind is not trans-historical, but it neither changes historically, it changes as symbolic systems do – and they do not change following some historical thread but in a merely contingent way. For the semiotic paradigm, thus, mind is as contingent as are the different semiotic systems. Finally, mediatic theory is rapidly becoming a new paradigm for the humanities in general, as semiotics was before it. Mediatic theory historicizes mind to the extent in which it is possible to reach an historical explanation of technological change and development, for this change is somehow mirrored by the structure of mind. Furthermore, technology is not clearly linked to any ethnical ground, on the contrary, it possesses structures that permeate any ethnical community, thus, mind structures related to technology structures can be both historical and more or less universal. -

Kenneth Burke at the Edges of Language by Debra Hawhee
English Faculty Works English Winter 2012 Reviewed Work: Moving Bodies: Kenneth Burke at the Edges of Language by Debra Hawhee Steven J. Mailloux Loyola Marymount University, [email protected] Follow this and additional works at: https://digitalcommons.lmu.edu/engl_fac Part of the English Language and Literature Commons Recommended Citation Mailloux, Steven. "Reviewed Work: Moving Bodies: Kenneth Burke at the Edges of Language by Debra Hawhee." Rhetorica: A Journal of the History of Rhetoric, vol. 30, no. 1, 2012, pp. 94–97. This Article is brought to you for free and open access by the English at Digital Commons @ Loyola Marymount University and Loyola Law School. It has been accepted for inclusion in English Faculty Works by an authorized administrator of Digital Commons@Loyola Marymount University and Loyola Law School. For more information, please contact [email protected]. Reviews Debra Hawhee, Moving Bodies: Kenneth Burke at the Edges of Language, Columbia: University of South Carolina Press, 2009. 215 pp. ISBN 978-1-57003-809-9 “There are only bodies and languages.” Alain Badiou’s proposition at the beginning of Logics of Worlds neatly sums up the rhetorical theory of Kenneth Burke as elaborated by Debra Hawhee in Moving Bodies. Hawhee’s book is an excellent study of Burke’s career-long preoccupation with hu- mans as “bodies that learn language.” Hawhee selectively tracks this pre- occupation from Burke’s earliest fiction through his engagements with bod- ily mysticism, drug research, endocrinology, constitutional medicine, and gesture-speech evolution to his final recapitulations organized around the opposition between nonsymbolic motion and symbolic action. -

Forms of Parallelism
Forms of Parallelism To understand parallelism is to lay the foundation for understanding almost every other writing form in ancient scripture. Without a doubt, “the prevalent poetic form of . scripture is not the ode, the lamentation, nor the psalm, but parallelism.”1 Not surprisingly, we nd parallelism in ancient languages around the world, such as Mayan, Greek, and Akkadian. In the more modern languages, such as English, German, French, and Spanish, we nd rhyming poetry that has a dened rhythm, is governed by a set line length, is nonredundant, and progresses from a denite beginning to a denite end. However, this is not true of ancient Hebrew poetry, which relied on repetitions, various other forms of redundancies, and parallelistic, symmetrical structures to achieve beauty, emphasis, and clarity of understanding. An interesting dimension of parallelism is described in this way: “The purpose of parallelism, like the general purpose of imagery, is to transfer the usual perception of an object into the sphere of a new perception—that is, to make a unique semantic modication.”2 In other words, the use of parallelism is not a mere matter of cosmetic style; it effects meaning and perception by introducing an idea from one angle and then semantically shifting the focus on that item to another angle. While the essence of each literary form is fairly clear, the boundaries between the forms often overlap. Thus an example of one form can often be an example of another form as well. At least 240 different dened Hebrew writing forms are identiable in the Old Testament. -

Repetition and Parallelism
SAGE Flex for Public Speaking Repetition and Parallelism Brief: Repetition and parallelism are stylistic devices used in many languages and cultures around the world in poetry, epics, songs, written prose, and speech. Learning Objective: Demonstrate when and how to use repetition and parallelism: Key Terms: • Parallelism: The proximity of two or more phrases with identical or similar constructions, especially those expressing the same sentiment, but with slight modifications. • Repetition: The reuse of words, phrases, ideas, or themes in your speech. Repetition and Parallelism Repetition and parallelism are stylistic devices used in many languages and cultures around the world in poetry, epics, songs, written prose, and speech. Repetition is the reuse of words, phrases, ideas or themes in your speech. Parallelism—a related device—is the proximity of two or more phrases with identical or similar constructions, especially those expressing the same sentiment, but with slight modifications. The Purpose of Repetition and Parallelism Repetition and parallelism provide emphasis, structure, order, and balance in your speech, in addition to clarifying your argument. Your audience is more likely to remember something that has been repeated. Parallelism functions similarly, but without rote repetition of words or ideas. Instead, parallelism draws on a sense of repetition. How to Use Repetition Repetition is effective in small doses, but you don't want to sound like a broken record. Consider using repetition of the same phrase or words only for those ideas that you would like to emphasize most throughout your speech. You can also use them in close proximity for an especially dramatic effect. For example, consider the following quotation from Sojourner Truth’s famous speech, “Ain’t I a Woman?” 1 SAGE Flex for Public Speaking That man over there says that women need to be helped into carriages, and lifted over ditches, and to have the best place everywhere. -

TOWARD a SYSTEMIC THEORY of SYMBOLIC ACTION by PATRICK
TOWARD A SYSTEMIC THEORY OF SYMBOLIC ACTION By PATRICK MICHAEL McKERCHER B.A., San Diego State University, 1981 M.A., San Diego State University, 1984 A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY in THE FACULTY OF GRADUATE STUDIES DEPARTMENT OF ENGLISH We accept this thesis as conforming to the required standard THE UNIVERSITY OF BRITISH COLUMBIA March, 1993 Patrick Michael McKercher, 1993 ________ ___________________________ In presenting this thesis in partial fulfilment of the requirements for an advanced Library shall make it degree at the University of British Columbia, I agree that the agree that permission for extensive freely available for reference and study. I further copying of this thesis for scholarly purposes may be granted by the head of my department or by his or her representatives. It is understood that copying or publication of this thesis for financial gain shall not be allowed without my written permission. (Signature) Department of AflJL The University of British Columbia Vancouver, Canada Date DE6 (2/88) ABSTRACT Though Kenneth Burke has often been dismissed as a brilliant but idiosyncratic thinker, this dissertation will argue that he is actually a precocious systems theorist. The systemic and systematic aspects of Burke’s work will be demonstrated by comparing it to the General Systems Theory (GST) of biologist Ludwig von Bertalanffy. Though beginning from very different starting points, Bertalanffy and Burke develop similar aims, methods, and come to remarkably similar conclusions about the nature and function of language. The systemic nature of Burke’s language philosophy will also become evident through an analysis of the Burkean corpus. -

The Friendly Media Phenomenon: a Cross-National Analysis of Cross-Cutting Exposure
Political Communication ISSN: 1058-4609 (Print) 1091-7675 (Online) Journal homepage: http://www.tandfonline.com/loi/upcp20 The Friendly Media Phenomenon: A Cross-National Analysis of Cross-Cutting Exposure Seth K. Goldman & Diana C. Mutz To cite this article: Seth K. Goldman & Diana C. Mutz (2011) The Friendly Media Phenomenon: A Cross-National Analysis of Cross-Cutting Exposure, Political Communication, 28:1, 42-66, DOI: 10.1080/10584609.2010.544280 To link to this article: http://dx.doi.org/10.1080/10584609.2010.544280 Published online: 08 Feb 2011. Submit your article to this journal Article views: 644 View related articles Citing articles: 21 View citing articles Full Terms & Conditions of access and use can be found at http://www.tandfonline.com/action/journalInformation?journalCode=upcp20 Download by: [University of Pennsylvania] Date: 25 January 2016, At: 16:55 Political Communication,28:42–66,2011 Copyright © Taylor & Francis Group, LLC ISSN: 1058-4609 print / 1091-7675 online DOI: 10.1080/10584609.2010.544280 The Friendly Media Phenomenon: A Cross-National Analysis of Cross-Cutting Exposure SETH K. GOLDMAN and DIANA C. MUTZ We hypothesize that in the real world, as opposed to the lab, the norm is for people to experience friendly media that favor their political predispositions when political favoritism is perceived at all. For this reason, media are generally limited in their abil- ity to create cross-cutting exposure. We test this hypothesis using representative survey data drawn from 11 different countries with varying media systems. We further hypoth- esize that television will contribute more to cross-cutting exposure than newspapers. -

University Microfilms International 300 N, ZEEB RD., ANN ARBOR, Ml 48106
INFORMATION TO USERS This was produced from a copy of a document sent to us for microfilming. While the most advanced technological means to photograph and reproduce this document have been used, the quality is heavily dependent upon the quality of the material submitted. The following explanation of techniques is provided to help you understand markings or notations which may appear on this reproduction. 1.The sign or “target” for pages apparently lacking from the document photographed is “ Missing Page(s)” . if it was possible to obtain the missing page(s) or section, they are spliced into the film along with adjacent pages. This may have necessitated cutting through an image and duplicating adjacent pages to assure you of complete continuity. 2. When an image on the film is obliterated with a round black mark it is an indication that the film inspector noticed either blurred copy because of movement during exposure, or duplicate copy. Unless we meant to delete copyrighted materials that should not have been filmed, you will find a good image of the page in the adjacent frame. If copyrighted materials were deleted you will find a target note listing the pages in the adjacent frame. 3. When a map, drawing or chart, etc., is part of the material being photo graphed the photographer has followed a definite method in “sectioning” the material. It is customary to begin filming at the upper left hand corner of a large sheet and tocontinue from left to right in equal sections with small overlaps. If necessary, sectioning is continued again—beginning below the first row and continuing on until complete. -

Grammatical Parallelism in the Translation of Advertising Texts with Particular Reference to English and Arabic
Asian Social Science; Vol. 9, No. 10; 2013 ISSN 1911-2017 E-ISSN 1911-2025 Published by Canadian Center of Science and Education Grammatical Parallelism in the Translation of Advertising Texts with Particular Reference to English and Arabic Mohammad Issa Mehawesh1 1 Faculty of Arts, Department of English Language and Translation, Zarqa University, Zarqa, Jordan Correspondence: Mohammad Issa Mehawesh, Faculty of Arts, Department of English Language and Translation, Zarqa University, PO box 132222, Zarqa 13132, Jordan. Tel: 962-7-9749-2506. E-mail: [email protected] Received: April 6, 2013 Accepted: June 4, 2013 Online Published: August 1, 2013 doi:10.5539/ass.v9n10p254 URL: http://dx.doi.org/10.5539/ass.v9n10p254 This research is funded by the Deanship of Research and Graduate Studies at Zarqa University /Jordan. Abstract Advertising is a specific genre which uses many techniques to persuade no matter the circumstances. One of the techniques used in advertising is grammatical parallelism. This study is generally intended to investigate and describe grammatical parallelism in the translation of advertising texts with particular reference to English and Arabic. The study should also provide an insight into the techniques of advertising in two different cultures in order to demonstrate that the cultural background is evident in advertising. Furthermore, the study will point up some of the main problems posed by the translation of advertising texts, taking into consideration that advertising translation, both production and products, is a part of a socio-cultural system. We will also focus mainly on the textual part, particularly, grammatical parallelism in the translation of English and Arabic advertisements. -

Marshall Mcluhan: a Prophet Before His Global Mirror Pedro Gelabert
McLuhan Galaxy Conference Understanding Media, Today Barcelona, May, 23rd-25th CONFERENCE PROCEEDINGS Edited by Matteo Ciastellardi, Cristina Miranda de Almeida, Carlos A. Scolari McLuhan Galaxy Conference Understanding Media, Today Conference Proceedings First Edition in English: May 2011 Collection Sehen, Editorial Universidad Oberta de Catalunya, Barcelona, España Printing: Book-Print S.L ISBN: 978-84-9388021-7 Legal Deposit B: Edited by Matteo Ciastellardi, Cristina Miranda de Almeida, Carlos A. Scolari Cover Image: Daniela Seminara Cover Layout: Mikel Azpiri Landa The full paper can be published in the proceedings and in any other scientific/ academic publications derived from McLuhan Galaxy Conference, according the Creative Commons Attribution Non-Commercial License. McLuhan Galaxy Conference Understanding Media, Today Barcelona, May, 23rd-25th CONFERENCE PROCEEDINGS Edited by Matteo Ciastellardi, Cristina Miranda de Almeida, Carlos A. Scolari McLuhan Galaxy Conference 4 Index Forewords Derrick de Kerckhove and Carlos A. Scolari . 10 I. General Framework of the Conference by Matteo Ciastellardi, Carlos A. Scolari and Cristina Miranda de Almeida. .12 II. Conference’s credits . 15 Organizers 15 Co-funding 15 Scientific Committee 15 UPF and IN3/ UOC Board Committee 15 CCCB-Lab Board Committee 16 Institutional Conference Partners 16 Opening Ceremony Participants 16 Keynote Speakers 16 Round Table Chairs and Speakers 17 Special Proposals on Video Wall Project 17 Parallel Session Chairs 17 Peer Reviewers 18 Press Support 19 Graphic Design 19 Management Support 19 Other Collaborations 19 III. Short Curricula keynote speakers and round table participants 3 1 Keynote Speakers’ curricula 20 3 2 Round Table participants’ curricula 24 5 Index IV. Papers (Content-based not in alphabetical order). -

Automatically Exploiting Cross-Invocation Parallelism Using
AUTOMATICALLY EXPLOITING CROSS-INVOCATION PARALLELISM USING RUNTIME INFORMATION JIALU HUANG ADISSERTATION PRESENTED TO THE FACULTY OF PRINCETON UNIVERSITY IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY RECOMMENDED FOR ACCEPTANCE BY THE DEPARTMENT OF COMPUTER SCIENCE ADVISOR:PROFESSOR DAVID I. AUGUST OCTOBER 2012 c Copyright by Jialu Huang, 2013. All Rights Reserved Abstract Automatic parallelization is a promising approach to producing scalable multi-threaded programs for multi-core architectures. Most existing techniques parallelize independent loops and insert global synchronizations at the end of each loop invocation. For programs with few loop invocations, these global synchronizations do not limit parallel execution per- formance. However, for programs with many loop invocations, those synchronizations can easily become the performance bottleneck since they frequently force all threads to wait, losing potential parallelization opportunities. To address this problem, some automatic parallelization techniques apply static analyses to enable cross-invocation parallelization. Instead of waiting, threads can execute iterations from follow-up invocations if they do not cause any conflict. However, static analysis must be conservative and cannot handle irregular dependence patterns manifested by particular program inputs at runtime. In order to enable more parallelization across loop invocations, this thesis presents two novel automatic parallelization techniques: DOMORE and SPECCROSS. Unlike existing techniques relying on static analyses, these two techniques take advantage of runtime in- formation to achieve much more aggressive parallelization. DOMORE constructs a custom runtime engine which non-speculatively observes dependences at runtime and synchronizes iterations only when necessary; while SPECCROSS applies software speculative barriers to permit some of the threads to execute past the invocation boundaries. -

Media and Communications Nick Couldry
University of Pennsylvania ScholarlyCommons Departmental Papers (ASC) Annenberg School for Communication 2017 Media and Communications Nick Couldry Clemencia Rodriguez Göran Bolin Julie Cohen Gerard Goggin See next page for additional authors Follow this and additional works at: https://repository.upenn.edu/asc_papers Part of the Social Influence and Political Communication Commons Recommended Citation Couldry, N., Rodriguez, C., Bolin, G., Cohen, J., Goggin, G., Kraidy, M. M., Iwabuchi, K., Lee, K., Qiu, J., Volkmer, I., Wasserman, H., & Zhao, Y. (2017). Media and Communications. Report of the International Panel on Social Progress, 523-562. https://doi.org/ 10.1017/9781108399647.006 Contributing Authors (not listed above): Olessia Koltsova, Inaya Rakhmani, Omar Rincón, Claudia Magallanes-Blanco, Pradip Thomas This paper is posted at ScholarlyCommons. https://repository.upenn.edu/asc_papers/719 For more information, please contact [email protected]. Media and Communications Disciplines Communication | Social and Behavioral Sciences | Social Influence and Political Communication Comments Contributing Authors (not listed above): Olessia Koltsova, Inaya Rakhmani, Omar Rincón, Claudia Magallanes-Blanco, Pradip Thomas Author(s) Nick Couldry, Clemencia Rodriguez, Göran Bolin, Julie Cohen, Gerard Goggin, Marwan M. Kraidy, Koichi Iwabuchi, Kwang-Suk Lee, Jack Qiu, Ingrid Volkmer, Herman Wasserman, and Yuezhi Zhao This report is available at ScholarlyCommons: https://repository.upenn.edu/asc_papers/719 523 13 Media and Communications* -
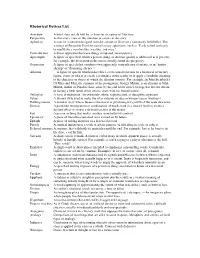
Rhetorical Devices List
Rhetorical Devices List Anecdote A brief story or tale told by a character in a piece of literature Perspective A character's view of the situation or events in the story Aphorism A concise statement designed to make a point or illustrate a commonly held belief. The writings of Benjamin Franklin contain many aphorisms, such as "Early to bed and early to rise/Make a man healthy, wealthy, and wise." Contradiction A direct opposition between things compared; inconsistency Apostrophe A figure of speech in which a person, thing, or abstract quality is addressed as if present; for example, the invocation to the muses usually found in epic poetry. Oxymoron A figure of speech that combines two apparently contradictory elements, as in "jumbo shrimp" or "deafening silence." Allusion —A figure of speech which makes brief, even casual reference to a historical or literary figure, event, or object to create a resonance in the reader or to apply a symbolic meaning to the character or object of which the allusion consists. For example, in John Steinbeck's Of Mice and Men, the surname of the protagonist, George Milton, is an allusion to John Milton, author of Paradise Lost, since by the end of the novel, George has lost the dream of having a little ranch of his own to share with his friend Lennie. Syllogism A form of deduction. An extremely subtle, sophisticated, or deceptive argument Satire A literary style used to make fun of or ridicule an idea or human vice or weakness Bildungsroman A novel or story whose theme is the moral or psychological growth of the main character.