Primepcr™Assay Validation Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Misexpression of Cancer/Testis (Ct) Genes in Tumor Cells and the Potential Role of Dream Complex and the Retinoblastoma Protein Rb in Soma-To-Germline Transformation
Michigan Technological University Digital Commons @ Michigan Tech Dissertations, Master's Theses and Master's Reports 2019 MISEXPRESSION OF CANCER/TESTIS (CT) GENES IN TUMOR CELLS AND THE POTENTIAL ROLE OF DREAM COMPLEX AND THE RETINOBLASTOMA PROTEIN RB IN SOMA-TO-GERMLINE TRANSFORMATION SABHA M. ALHEWAT Michigan Technological University, [email protected] Copyright 2019 SABHA M. ALHEWAT Recommended Citation ALHEWAT, SABHA M., "MISEXPRESSION OF CANCER/TESTIS (CT) GENES IN TUMOR CELLS AND THE POTENTIAL ROLE OF DREAM COMPLEX AND THE RETINOBLASTOMA PROTEIN RB IN SOMA-TO- GERMLINE TRANSFORMATION", Open Access Master's Thesis, Michigan Technological University, 2019. https://doi.org/10.37099/mtu.dc.etdr/933 Follow this and additional works at: https://digitalcommons.mtu.edu/etdr Part of the Cancer Biology Commons, and the Cell Biology Commons MISEXPRESSION OF CANCER/TESTIS (CT) GENES IN TUMOR CELLS AND THE POTENTIAL ROLE OF DREAM COMPLEX AND THE RETINOBLASTOMA PROTEIN RB IN SOMA-TO-GERMLINE TRANSFORMATION By Sabha Salem Alhewati A THESIS Submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE In Biological Sciences MICHIGAN TECHNOLOGICAL UNIVERSITY 2019 © 2019 Sabha Alhewati This thesis has been approved in partial fulfillment of the requirements for the Degree of MASTER OF SCIENCE in Biological Sciences. Department of Biological Sciences Thesis Advisor: Paul Goetsch. Committee Member: Ebenezer Tumban. Committee Member: Zhiying Shan. Department Chair: Chandrashekhar Joshi. Table of Contents List of figures .......................................................................................................................v -

Clinical, Molecular, and Immune Analysis of Dabrafenib-Trametinib
Supplementary Online Content Chen G, McQuade JL, Panka DJ, et al. Clinical, molecular and immune analysis of dabrafenib-trametinib combination treatment for metastatic melanoma that progressed during BRAF inhibitor monotherapy: a phase 2 clinical trial. JAMA Oncology. Published online April 28, 2016. doi:10.1001/jamaoncol.2016.0509. eMethods. eReferences. eTable 1. Clinical efficacy eTable 2. Adverse events eTable 3. Correlation of baseline patient characteristics with treatment outcomes eTable 4. Patient responses and baseline IHC results eFigure 1. Kaplan-Meier analysis of overall survival eFigure 2. Correlation between IHC and RNAseq results eFigure 3. pPRAS40 expression and PFS eFigure 4. Baseline and treatment-induced changes in immune infiltrates eFigure 5. PD-L1 expression eTable 5. Nonsynonymous mutations detected by WES in baseline tumors This supplementary material has been provided by the authors to give readers additional information about their work. © 2016 American Medical Association. All rights reserved. Downloaded From: https://jamanetwork.com/ on 09/30/2021 eMethods Whole exome sequencing Whole exome capture libraries for both tumor and normal samples were constructed using 100ng genomic DNA input and following the protocol as described by Fisher et al.,3 with the following adapter modification: Illumina paired end adapters were replaced with palindromic forked adapters with unique 8 base index sequences embedded within the adapter. In-solution hybrid selection was performed using the Illumina Rapid Capture Exome enrichment kit with 38Mb target territory (29Mb baited). The targeted region includes 98.3% of the intervals in the Refseq exome database. Dual-indexed libraries were pooled into groups of up to 96 samples prior to hybridization. -

The Hypothalamus As a Hub for SARS-Cov-2 Brain Infection and Pathogenesis
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.08.139329; this version posted June 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The hypothalamus as a hub for SARS-CoV-2 brain infection and pathogenesis Sreekala Nampoothiri1,2#, Florent Sauve1,2#, Gaëtan Ternier1,2ƒ, Daniela Fernandois1,2 ƒ, Caio Coelho1,2, Monica ImBernon1,2, Eleonora Deligia1,2, Romain PerBet1, Vincent Florent1,2,3, Marc Baroncini1,2, Florence Pasquier1,4, François Trottein5, Claude-Alain Maurage1,2, Virginie Mattot1,2‡, Paolo GiacoBini1,2‡, S. Rasika1,2‡*, Vincent Prevot1,2‡* 1 Univ. Lille, Inserm, CHU Lille, Lille Neuroscience & Cognition, DistAlz, UMR-S 1172, Lille, France 2 LaBoratorY of Development and PlasticitY of the Neuroendocrine Brain, FHU 1000 daYs for health, EGID, School of Medicine, Lille, France 3 Nutrition, Arras General Hospital, Arras, France 4 Centre mémoire ressources et recherche, CHU Lille, LiCEND, Lille, France 5 Univ. Lille, CNRS, INSERM, CHU Lille, Institut Pasteur de Lille, U1019 - UMR 8204 - CIIL - Center for Infection and ImmunitY of Lille (CIIL), Lille, France. # and ƒ These authors contriButed equallY to this work. ‡ These authors directed this work *Correspondence to: [email protected] and [email protected] Short title: Covid-19: the hypothalamic hypothesis 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.06.08.139329; this version posted June 19, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -

Us 2018 / 0305689 A1
US 20180305689A1 ( 19 ) United States (12 ) Patent Application Publication ( 10) Pub . No. : US 2018 /0305689 A1 Sætrom et al. ( 43 ) Pub . Date: Oct. 25 , 2018 ( 54 ) SARNA COMPOSITIONS AND METHODS OF plication No . 62 /150 , 895 , filed on Apr. 22 , 2015 , USE provisional application No . 62/ 150 ,904 , filed on Apr. 22 , 2015 , provisional application No. 62 / 150 , 908 , (71 ) Applicant: MINA THERAPEUTICS LIMITED , filed on Apr. 22 , 2015 , provisional application No. LONDON (GB ) 62 / 150 , 900 , filed on Apr. 22 , 2015 . (72 ) Inventors : Pål Sætrom , Trondheim (NO ) ; Endre Publication Classification Bakken Stovner , Trondheim (NO ) (51 ) Int . CI. C12N 15 / 113 (2006 .01 ) (21 ) Appl. No. : 15 /568 , 046 (52 ) U . S . CI. (22 ) PCT Filed : Apr. 21 , 2016 CPC .. .. .. C12N 15 / 113 ( 2013 .01 ) ; C12N 2310 / 34 ( 2013. 01 ) ; C12N 2310 /14 (2013 . 01 ) ; C12N ( 86 ) PCT No .: PCT/ GB2016 /051116 2310 / 11 (2013 .01 ) $ 371 ( c ) ( 1 ) , ( 2 ) Date : Oct . 20 , 2017 (57 ) ABSTRACT The invention relates to oligonucleotides , e . g . , saRNAS Related U . S . Application Data useful in upregulating the expression of a target gene and (60 ) Provisional application No . 62 / 150 ,892 , filed on Apr. therapeutic compositions comprising such oligonucleotides . 22 , 2015 , provisional application No . 62 / 150 ,893 , Methods of using the oligonucleotides and the therapeutic filed on Apr. 22 , 2015 , provisional application No . compositions are also provided . 62 / 150 ,897 , filed on Apr. 22 , 2015 , provisional ap Specification includes a Sequence Listing . SARNA sense strand (Fessenger 3 ' SARNA antisense strand (Guide ) Mathew, Si Target antisense RNA transcript, e . g . NAT Target Coding strand Gene Transcription start site ( T55 ) TY{ { ? ? Targeted Target transcript , e . -

WO 2016/004387 Al 7 January 2016 (07.01.2016) P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2016/004387 Al 7 January 2016 (07.01.2016) P O P C T (51) International Patent Classification: (81) Designated States (unless otherwise indicated, for every A61P 35/00 (2006.01) kind of national protection available): AE, AG, AL, AM, AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, (21) International Application Number: BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, PCT/US20 15/039 108 DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, (22) International Filing Date: HN, HR, HU, ID, IL, IN, IR, IS, JP, KE, KG, KN, KP, KR, 2 July 2015 (02.07.2015) KZ, LA, LC, LK, LR, LS, LU, LY, MA, MD, ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, NO, NZ, OM, (25) Filing Language: English PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, RW, SA, SC, (26) Publication Language: English SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, ZM, ZW. (30) Priority Data: 62/020,3 10 2 July 2014 (02.07.2014) US (84) Designated States (unless otherwise indicated, for every kind of regional protection available): ARIPO (BW, GH, (71) Applicant: H. LEE MOFFITT CANCER CENTER GM, KE, LR, LS, MW, MZ, NA, RW, SD, SL, ST, SZ, AND RESEARCH INSTITUTE, INC. [US/US]; 12902 TZ, UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, RU, Magnolia Dr., Tampa, FL 336 12-9497 (US). -

Supplementary Data
1 SUPPLEMENTARY FILES – DESCRIPTION AND LEGENDS Supplementary Data: Validation of amplicons, analysis of grade III IDC-NST of indeterminate phenotype and quantification of PPM1D protein levels by densitometric analysis. Supplementary Figure 1: Validation of CCND1 and EGFR amplifications in a series of 91 grade III-IDC-NST and CCNE1 amplifications on selected cases. (A) i) H&E ii) CISH iii) IHC for a) luminal tumour for CCND1 showing amplification and protein over-expression, b) basal-like tumour for CCND1 with normal copy number and no protein expression, c) EGFR non-amplified tumour with no protein expression d) EGFR amplified tumour showing strong protein expression. Amplification of CCNE1 in basal-like breast cancers. (B) Genome plots of two cases exhibiting amplification with the smallest region of overlap highlighted (i). FISH confirmation of CCNE1 amplification with RP11-327I05 (CCNE1) (red), showing amplification > 5 copies per nucleus (Bii). Supplementary Figure 2: Microarray-based comparative genomic hybridisation analysis of five grade III invasive ductal carcinomas of no special type of indeterminate phenotype. A) Representative genome plots. Log2 ratios are plotted on the Y axis against each clone according to genomic location on the X axis. The centromere is represented by a vertical dotted line. BACs categorised as displaying genomic gains as defined by aws ratios > 0.08 are highlighted in green and those categorised as genomic losses as defined by aws ratios < -0.08 are highlighted in red. Bi) The proportion of tumours in which each clone is gained (green bars) or lost (red bars) is plotted (Y axis) for each BAC clone according to genomic location (X axis). -
Explorations in Olfactory Receptor Structure and Function by Jianghai
Explorations in Olfactory Receptor Structure and Function by Jianghai Ho Department of Neurobiology Duke University Date:_______________________ Approved: ___________________________ Hiroaki Matsunami, Supervisor ___________________________ Jorg Grandl, Chair ___________________________ Marc Caron ___________________________ Sid Simon ___________________________ [Committee Member Name] Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Neurobiology in the Graduate School of Duke University 2014 ABSTRACT Explorations in Olfactory Receptor Structure and Function by Jianghai Ho Department of Neurobiology Duke University Date:_______________________ Approved: ___________________________ Hiroaki Matsunami, Supervisor ___________________________ Jorg Grandl, Chair ___________________________ Marc Caron ___________________________ Sid Simon ___________________________ [Committee Member Name] An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Neurobiology in the Graduate School of Duke University 2014 Copyright by Jianghai Ho 2014 Abstract Olfaction is one of the most primitive of our senses, and the olfactory receptors that mediate this very important chemical sense comprise the largest family of genes in the mammalian genome. It is therefore surprising that we understand so little of how olfactory receptors work. In particular we have a poor idea of what chemicals are detected by most of the olfactory receptors in the genome, and for those receptors which we have paired with ligands, we know relatively little about how the structure of these ligands can either activate or inhibit the activation of these receptors. Furthermore the large repertoire of olfactory receptors, which belong to the G protein coupled receptor (GPCR) superfamily, can serve as a model to contribute to our broader understanding of GPCR-ligand binding, especially since GPCRs are important pharmaceutical targets. -

Supplemental Table 1 (S1). the Chromosomal Regions and Genes Exhibiting Loss of Heterozygosity That Were Shared Between the HLRCC-Rccs of Both Patients 1 and 2
Supplementary material J Clin Pathol Supplemental Table 1 (S1). The chromosomal regions and genes exhibiting loss of heterozygosity that were shared between the HLRCC-RCCs of both Patients 1 and 2. Chromosome Position Genes 1 p13.1 ATP1A1, ATP1A1-AS1, LOC101929023, CD58, IGSF3, MIR320B1, C1orf137, CD2, PTGFRN, CD101, LOC101929099 1 p21.1* COL11A1, LOC101928436, RNPC3, AMY2B, ACTG1P4, AMY2A, AMY1A, AMY1C, AMY1B 1 p36.11 LOC101928728, ARID1A, PIGV, ZDHHC18, SFN, GPN2, GPATCH3, NR0B2, NUDC, KDF1, TRNP1, FAM46B, SLC9A1, WDTC1, TMEM222, ACTG1P20, SYTL1, MAP3K6, FCN3, CD164L2, GPR3, WASF2, AHDC1, FGR, IFI6 1 q21.3* KCNN3, PMVK, PBXIP1, PYGO2, LOC101928120, SHC1, CKS1B, MIR4258, FLAD1, LENEP, ZBTB7B, DCST2, DCST1, LOC100505666, ADAM15, EFNA4, EFNA3, EFNA1, SLC50A1, DPM3, KRTCAP2, TRIM46, MUC1, MIR92B, THBS3, MTX1, GBAP1, GBA, FAM189B, SCAMP3, CLK2, HCN3, PKLR, FDPS, RUSC1-AS1, RUSC1, ASH1L, MIR555, POU5F1P4, ASH1L-AS1, MSTO1, MSTO2P, YY1AP1, SCARNA26A, DAP3, GON4L, SCARNA26B, SYT11, RIT1, KIAA0907, SNORA80E, SCARNA4, RXFP4, ARHGEF2, MIR6738, SSR2, UBQLN4, LAMTOR2, RAB25, MEX3A, LMNA, SEMA4A, SLC25A44, PMF1, PMF1-BGLAP 1 q24.2–44* LOC101928650, GORAB, PRRX1, MROH9, FMO3, MIR1295A, MIR1295B, FMO6P, FMO2, FMO1, FMO4, TOP1P1, PRRC2C, MYOC, VAMP4, METTL13, DNM3, DNM3-IT1, DNM3OS, MIR214, MIR3120, MIR199A2, C1orf105, PIGC, SUCO, FASLG, TNFSF18, TNFSF4, LOC100506023, LOC101928673, PRDX6, SLC9C2, ANKRD45, LOC730159, KLHL20, CENPL, DARS2, GAS5- AS1, GAS5, SNORD81, SNORD47, SNORD80, SNORD79, SNORD78, SNORD44, SNORA103, SNORD77, SNORD76, SNORD75, SNORD74, -
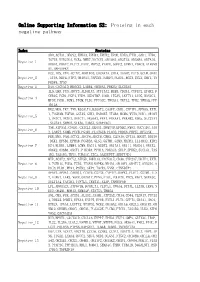
Online Supporting Information S2: Proteins in Each Negative Pathway
Online Supporting Information S2: Proteins in each negative pathway Index Proteins ADO,ACTA1,DEGS2,EPHA3,EPHB4,EPHX2,EPOR,EREG,FTH1,GAD1,HTR6, IGF1R,KIR2DL4,NCR3,NME7,NOTCH1,OR10S1,OR2T33,OR56B4,OR7A10, Negative_1 OR8G1,PDGFC,PLCZ1,PROC,PRPS2,PTAFR,SGPP2,STMN1,VDAC3,ATP6V0 A1,MAPKAPK2 DCC,IDS,VTN,ACTN2,AKR1B10,CACNA1A,CHIA,DAAM2,FUT5,GCLM,GNAZ Negative_2 ,ITPA,NEU4,NTF3,OR10A3,PAPSS1,PARD3,PLOD1,RGS3,SCLY,SHC1,TN FRSF4,TP53 Negative_3 DAO,CACNA1D,HMGCS2,LAMB4,OR56A3,PRKCQ,SLC25A5 IL5,LHB,PGD,ADCY3,ALDH1A3,ATP13A2,BUB3,CD244,CYFIP2,EPHX2,F CER1G,FGD1,FGF4,FZD9,HSD17B7,IL6R,ITGAV,LEFTY1,LIPG,MAN1C1, Negative_4 MPDZ,PGM1,PGM3,PIGM,PLD1,PPP3CC,TBXAS1,TKTL2,TPH2,YWHAQ,PPP 1R12A HK2,MOS,TKT,TNN,B3GALT4,B3GAT3,CASP7,CDH1,CYFIP1,EFNA5,EXTL 1,FCGR3B,FGF20,GSTA5,GUK1,HSD3B7,ITGB4,MCM6,MYH3,NOD1,OR10H Negative_5 1,OR1C1,OR1E1,OR4C11,OR56A3,PPA1,PRKAA1,PRKAB2,RDH5,SLC27A1 ,SLC2A4,SMPD2,STK36,THBS1,SERPINC1 TNR,ATP5A1,CNGB1,CX3CL1,DEGS1,DNMT3B,EFNB2,FMO2,GUCY1B3,JAG Negative_6 2,LARS2,NUMB,PCCB,PGAM1,PLA2G1B,PLOD2,PRDX6,PRPS1,RFXANK FER,MVD,PAH,ACTC1,ADCY4,ADCY8,CBR3,CLDN16,CPT1A,DDOST,DDX56 ,DKK1,EFNB1,EPHA8,FCGR3A,GLS2,GSTM1,GZMB,HADHA,IL13RA2,KIR2 Negative_7 DS4,KLRK1,LAMB4,LGMN,MAGI1,NUDT2,OR13A1,OR1I1,OR4D11,OR4X2, OR6K2,OR8B4,OXCT1,PIK3R4,PPM1A,PRKAG3,SELP,SPHK2,SUCLG1,TAS 1R2,TAS1R3,THY1,TUBA1C,ZIC2,AASDHPPT,SERPIND1 MTR,ACAT2,ADCY2,ATP5D,BMPR1A,CACNA1E,CD38,CYP2A7,DDIT4,EXTL Negative_8 1,FCER1G,FGD3,FZD5,ITGAM,MAPK8,NR4A1,OR10V1,OR4F17,OR52D1,O R8J3,PLD1,PPA1,PSEN2,SKP1,TACR3,VNN1,CTNNBIP1 APAF1,APOA1,CARD11,CCDC6,CSF3R,CYP4F2,DAPK1,FLOT1,GSTM1,IL2 -

OR2G6 (NM 001013355) Human Tagged ORF Clone – RC223138
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for RC223138 OR2G6 (NM_001013355) Human Tagged ORF Clone Product data: Product Type: Expression Plasmids Product Name: OR2G6 (NM_001013355) Human Tagged ORF Clone Tag: Myc-DDK Symbol: OR2G6 Vector: pCMV6-Entry (PS100001) E. coli Selection: Kanamycin (25 ug/mL) Cell Selection: Neomycin ORF Nucleotide >RC223138 representing NM_001013355 Sequence: Red=Cloning site Blue=ORF Green=Tags(s) TTTTGTAATACGACTCACTATAGGGCGGCCGGGAATTCGTCGACTGGATCCGGTACCGAGGAGATCTGCC GCCGCGATCGCC ATGGAGGAAACCAACAACAGCTCTGAAAAGGGATTTCTTCTCCTGGGATTTTCAGATCAGCCTCAGCTAG AGAGGTTTCTTTTTGCCATCATTTTGTACTTCTACGTCTTGAGCCTTCTGGGGAACACTGCCCTCATACT AGTATGTTGTCTGGACTCCAGACTCCACACTCCAATGTACTTCTTCCTCAGCAACCTCTCGTGTGTGGAC ATCTGCTTTACCACCAGTGTTGCCCCACAGTTGCTGGTTACCATGAATAAGAAAGACAAAACCATGAGCT ACGGTGGCTGTGTGGCCCAGCTCTATGTGGCCATGGGGTTGGGCTCGTCTGAGTGTATTCTCTTGGCCGT CATGGCTTATGACCGCTATGCTGCTGTCTGCCGGCCACTGCGCTACATAGCCATTATGCACCCCAGGTTC TGTGCGTCTCTGGCCGGTGGAGCATGGCTCAGCGGCCTCATCACCTCCCTAATTCAGTGCTCCCTCACTG TGCAGCTGCCCCTCTGTGGTCATCGCACACTGGATCATATTTTCTGTGAGGTGCCAGTGCTCATCAAACT GGCCTGTGTGGATACGACTTTCAACGAGGCAGAACTCTTTGTGGCCAGTGTAGTCTTTCTAATTGTCCCG GTGTTACTCATCTTAGTCTCCTATGGCTTTATCACTCAAGCTGTGTTAAGGATAAAATCAGCTGCGGGCC GCCAAAAGGCCTTTGGGACCTGTTCGTCTCACCTGGTTGTGGTCATCATTTTCTATGGGACCATCATATT CATGTACCTTCAACCGGCCAATAGGAGATCCAAAAACCAGGGAAAGTTTGTTTCTCTTTTCTATACCATA GTCACCCCACTTTTAAACCCCATTATCTACACTCTGAGAAACAAAGATGTGAAAGGGGCCTTGAGGACCC -

1 Supplementary Material Figure S1. Volcano Plot of Differentially
Supplementary material Figure S1. Volcano Plot of differentially expressed genes between preterm infants fed own mother’s milk (OMM) or pasteurized donated human milk (DHM). Table S1. The 10 most representative biological processes filtered for enrichment p- value in preterm infants. Biological Processes p-value Quantity of DEG* Transcription, DNA-templated 3.62x10-24 189 Regulation of transcription, DNA-templated 5.34x10-22 188 Transport 3.75x10-17 140 Cell cycle 1.03x10-13 65 Gene expression 3.38x10-10 60 Multicellular organismal development 6.97x10-10 86 1 Protein transport 1.73x10-09 56 Cell division 2.75x10-09 39 Blood coagulation 3.38x10-09 46 DNA repair 8.34x10-09 39 Table S2. Differential genes in transcriptomic analysis of exfoliated epithelial intestinal cells between preterm infants fed own mother’s milk (OMM) and pasteurized donated human milk (DHM). Gene name Gene Symbol p-value Fold-Change (OMM vs. DHM) (OMM vs. DHM) Lactalbumin, alpha LALBA 0.0024 2.92 Casein kappa CSN3 0.0024 2.59 Casein beta CSN2 0.0093 2.13 Cytochrome c oxidase subunit I COX1 0.0263 2.07 Casein alpha s1 CSN1S1 0.0084 1.71 Espin ESPN 0.0008 1.58 MTND2 ND2 0.0138 1.57 Small ubiquitin-like modifier 3 SUMO3 0.0037 1.54 Eukaryotic translation elongation EEF1A1 0.0365 1.53 factor 1 alpha 1 Ribosomal protein L10 RPL10 0.0195 1.52 Keratin associated protein 2-4 KRTAP2-4 0.0019 1.46 Serine peptidase inhibitor, Kunitz SPINT1 0.0007 1.44 type 1 Zinc finger family member 788 ZNF788 0.0000 1.43 Mitochondrial ribosomal protein MRPL38 0.0020 1.41 L38 Diacylglycerol -

Supplementary Methods
doi: 10.1038/nature06162 SUPPLEMENTARY INFORMATION Supplementary Methods Cloning of human odorant receptors 423 human odorant receptors were cloned with sequence information from The Olfactory Receptor Database (http://senselab.med.yale.edu/senselab/ORDB/default.asp). Of these, 335 were predicted to encode functional receptors, 45 were predicted to encode pseudogenes, 29 were putative variant pairs of the same genes, and 14 were duplicates. We adopted the nomenclature proposed by Doron Lancet 1. OR7D4 and the six intact odorant receptor genes in the OR7D4 gene cluster (OR1M1, OR7G2, OR7G1, OR7G3, OR7D2, and OR7E24) were used for functional analyses. SNPs in these odorant receptors were identified from the NCBI dbSNP database (http://www.ncbi.nlm.nih.gov/projects/SNP) or through genotyping. OR7D4 single nucleotide variants were generated by cloning the reference sequence from a subject or by inducing polymorphic SNPs by site-directed mutagenesis using overlap extension PCR. Single nucleotide and frameshift variants for the six intact odorant receptors in the same gene cluster as OR7D4 were generated by cloning the respective genes from the genomic DNA of each subject. The chimpanzee OR7D4 orthologue was amplified from chimpanzee genomic DNA (Coriell Cell Repositories). Odorant receptors that contain the first 20 amino acids of human rhodopsin tag 2 in pCI (Promega) were expressed in the Hana3A cell line along with a short form of mRTP1 called RTP1S, (M37 to the C-terminal end), which enhances functional expression of the odorant receptors 3. For experiments with untagged odorant receptors, OR7D4 RT and S84N variants without the Rho tag were cloned into pCI.