Aliasing Contracts, a Novel, Dynamically-Checked Alias Protection Scheme for Object- Oriented Programming Languages
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
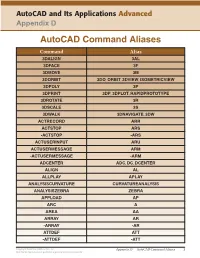
Autocad Command Aliases
AutoCAD and Its Applications Advanced Appendix D AutoCAD Command Aliases Command Alias 3DALIGN 3AL 3DFACE 3F 3DMOVE 3M 3DORBIT 3DO, ORBIT, 3DVIEW, ISOMETRICVIEW 3DPOLY 3P 3DPRINT 3DP, 3DPLOT, RAPIDPROTOTYPE 3DROTATE 3R 3DSCALE 3S 3DWALK 3DNAVIGATE, 3DW ACTRECORD ARR ACTSTOP ARS -ACTSTOP -ARS ACTUSERINPUT ARU ACTUSERMESSAGE ARM -ACTUSERMESSAGE -ARM ADCENTER ADC, DC, DCENTER ALIGN AL ALLPLAY APLAY ANALYSISCURVATURE CURVATUREANALYSIS ANALYSISZEBRA ZEBRA APPLOAD AP ARC A AREA AA ARRAY AR -ARRAY -AR ATTDEF ATT -ATTDEF -ATT Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 1 May not be reproduced or posted to a publicly accessible website. Command Alias ATTEDIT ATE -ATTEDIT -ATE, ATTE ATTIPEDIT ATI BACTION AC BCLOSE BC BCPARAMETER CPARAM BEDIT BE BLOCK B -BLOCK -B BOUNDARY BO -BOUNDARY -BO BPARAMETER PARAM BREAK BR BSAVE BS BVSTATE BVS CAMERA CAM CHAMFER CHA CHANGE -CH CHECKSTANDARDS CHK CIRCLE C COLOR COL, COLOUR COMMANDLINE CLI CONSTRAINTBAR CBAR CONSTRAINTSETTINGS CSETTINGS COPY CO, CP CTABLESTYLE CT CVADD INSERTCONTROLPOINT CVHIDE POINTOFF CVREBUILD REBUILD CVREMOVE REMOVECONTROLPOINT CVSHOW POINTON Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 2 May not be reproduced or posted to a publicly accessible website. Command Alias CYLINDER CYL DATAEXTRACTION DX DATALINK DL DATALINKUPDATE DLU DBCONNECT DBC, DATABASE, DATASOURCE DDGRIPS GR DELCONSTRAINT DELCON DIMALIGNED DAL, DIMALI DIMANGULAR DAN, DIMANG DIMARC DAR DIMBASELINE DBA, DIMBASE DIMCENTER DCE DIMCONSTRAINT DCON DIMCONTINUE DCO, DIMCONT DIMDIAMETER DDI, DIMDIA DIMDISASSOCIATE DDA DIMEDIT DED, DIMED DIMJOGGED DJO, JOG DIMJOGLINE DJL DIMLINEAR DIMLIN, DLI DIMORDINATE DOR, DIMORD DIMOVERRIDE DOV, DIMOVER DIMRADIUS DIMRAD, DRA DIMREASSOCIATE DRE DIMSTYLE D, DIMSTY, DST DIMTEDIT DIMTED DIST DI, LENGTH DIVIDE DIV DONUT DO DRAWINGRECOVERY DRM DRAWORDER DR Copyright Goodheart-Willcox Co., Inc. -

CS101 Lecture 9
How do you copy/move/rename/remove files? How do you create a directory ? What is redirection and piping? Readings: See CCSO’s Unix pages and 9-2 cp option file1 file2 First Version cp file1 file2 file3 … dirname Second Version This is one version of the cp command. file2 is created and the contents of file1 are copied into file2. If file2 already exits, it This version copies the files file1, file2, file3,… into the directory will be replaced with a new one. dirname. where option is -i Protects you from overwriting an existing file by asking you for a yes or no before it copies a file with an existing name. -r Can be used to copy directories and all their contents into a new directory 9-3 9-4 cs101 jsmith cs101 jsmith pwd data data mp1 pwd mp1 {FILES: mp1_data.m, mp1.m } {FILES: mp1_data.m, mp1.m } Copy the file named mp1_data.m from the cs101/data Copy the file named mp1_data.m from the cs101/data directory into the pwd. directory into the mp1 directory. > cp ~cs101/data/mp1_data.m . > cp ~cs101/data/mp1_data.m mp1 The (.) dot means “here”, that is, your pwd. 9-5 The (.) dot means “here”, that is, your pwd. 9-6 Example: To create a new directory named “temp” and to copy mv option file1 file2 First Version the contents of an existing directory named mp1 into temp, This is one version of the mv command. file1 is renamed file2. where option is -i Protects you from overwriting an existing file by asking you > cp -r mp1 temp for a yes or no before it copies a file with an existing name. -

Using the GNU Compiler Collection (GCC)
Using the GNU Compiler Collection (GCC) Using the GNU Compiler Collection by Richard M. Stallman and the GCC Developer Community Last updated 23 May 2004 for GCC 3.4.6 For GCC Version 3.4.6 Published by: GNU Press Website: www.gnupress.org a division of the General: [email protected] Free Software Foundation Orders: [email protected] 59 Temple Place Suite 330 Tel 617-542-5942 Boston, MA 02111-1307 USA Fax 617-542-2652 Last printed October 2003 for GCC 3.3.1. Printed copies are available for $45 each. Copyright c 1988, 1989, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with the Invariant Sections being \GNU General Public License" and \Funding Free Software", the Front-Cover texts being (a) (see below), and with the Back-Cover Texts being (b) (see below). A copy of the license is included in the section entitled \GNU Free Documentation License". (a) The FSF's Front-Cover Text is: A GNU Manual (b) The FSF's Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Short Contents Introduction ...................................... 1 1 Programming Languages Supported by GCC ............ 3 2 Language Standards Supported by GCC ............... 5 3 GCC Command Options ......................... -

Memory Tagging and How It Improves C/C++ Memory Safety Kostya Serebryany, Evgenii Stepanov, Aleksey Shlyapnikov, Vlad Tsyrklevich, Dmitry Vyukov Google February 2018
Memory Tagging and how it improves C/C++ memory safety Kostya Serebryany, Evgenii Stepanov, Aleksey Shlyapnikov, Vlad Tsyrklevich, Dmitry Vyukov Google February 2018 Introduction 2 Memory Safety in C/C++ 2 AddressSanitizer 2 Memory Tagging 3 SPARC ADI 4 AArch64 HWASAN 4 Compiler And Run-time Support 5 Overhead 5 RAM 5 CPU 6 Code Size 8 Usage Modes 8 Testing 9 Always-on Bug Detection In Production 9 Sampling In Production 10 Security Hardening 11 Strengths 11 Weaknesses 12 Legacy Code 12 Kernel 12 Uninitialized Memory 13 Possible Improvements 13 Precision Of Buffer Overflow Detection 13 Probability Of Bug Detection 14 Conclusion 14 Introduction Memory safety in C and C++ remains largely unresolved. A technique usually called “memory tagging” may dramatically improve the situation if implemented in hardware with reasonable overhead. This paper describes two existing implementations of memory tagging: one is the full hardware implementation in SPARC; the other is a partially hardware-assisted compiler-based tool for AArch64. We describe the basic idea, evaluate the two implementations, and explain how they improve memory safety. This paper is intended to initiate a wider discussion of memory tagging and to motivate the CPU and OS vendors to add support for it in the near future. Memory Safety in C/C++ C and C++ are well known for their performance and flexibility, but perhaps even more for their extreme memory unsafety. This year we are celebrating the 30th anniversary of the Morris Worm, one of the first known exploitations of a memory safety bug, and the problem is still not solved. -

Shell Variables
Shell Using the command line Orna Agmon ladypine at vipe.technion.ac.il Haifux Shell – p. 1/55 TOC Various shells Customizing the shell getting help and information Combining simple and useful commands output redirection lists of commands job control environment variables Remote shell textual editors textual clients references Shell – p. 2/55 What is the shell? The shell is the wrapper around the system: a communication means between the user and the system The shell is the manner in which the user can interact with the system through the terminal. The shell is also a script interpreter. The simplest script is a bunch of shell commands. Shell scripts are used in order to boot the system. The user can also write and execute shell scripts. Shell – p. 3/55 Shell - which shell? There are several kinds of shells. For example, bash (Bourne Again Shell), csh, tcsh, zsh, ksh (Korn Shell). The most important shell is bash, since it is available on almost every free Unix system. The Linux system scripts use bash. The default shell for the user is set in the /etc/passwd file. Here is a line out of this file for example: dana:x:500:500:Dana,,,:/home/dana:/bin/bash This line means that user dana uses bash (located on the system at /bin/bash) as her default shell. Shell – p. 4/55 Starting to work in another shell If Dana wishes to temporarily use another shell, she can simply call this shell from the command line: [dana@granada ˜]$ bash dana@granada:˜$ #In bash now dana@granada:˜$ exit [dana@granada ˜]$ bash dana@granada:˜$ #In bash now, going to hit ctrl D dana@granada:˜$ exit [dana@granada ˜]$ #In original shell now Shell – p. -

Statically Detecting Likely Buffer Overflow Vulnerabilities
Statically Detecting Likely Buffer Overflow Vulnerabilities David Larochelle [email protected] University of Virginia, Department of Computer Science David Evans [email protected] University of Virginia, Department of Computer Science Abstract Buffer overflow attacks may be today’s single most important security threat. This paper presents a new approach to mitigating buffer overflow vulnerabilities by detecting likely vulnerabilities through an analysis of the program source code. Our approach exploits information provided in semantic comments and uses lightweight and efficient static analyses. This paper describes an implementation of our approach that extends the LCLint annotation-assisted static checking tool. Our tool is as fast as a compiler and nearly as easy to use. We present experience using our approach to detect buffer overflow vulnerabilities in two security-sensitive programs. 1. Introduction ed a prototype tool that does this by extending LCLint [Evans96]. Our work differs from other work on static detection of buffer overflows in three key ways: (1) we Buffer overflow attacks are an important and persistent exploit semantic comments added to source code to security problem. Buffer overflows account for enable local checking of interprocedural properties; (2) approximately half of all security vulnerabilities we focus on lightweight static checking techniques that [CWPBW00, WFBA00]. Richard Pethia of CERT have good performance and scalability characteristics, identified buffer overflow attacks as the single most im- but sacrifice soundness and completeness; and (3) we portant security problem at a recent software introduce loop heuristics, a simple approach for engineering conference [Pethia00]; Brian Snow of the efficiently analyzing many loops found in typical NSA predicted that buffer overflow attacks would still programs. -

Aliasing Restrictions of C11 Formalized in Coq
Aliasing restrictions of C11 formalized in Coq Robbert Krebbers Radboud University Nijmegen December 11, 2013 @ CPP, Melbourne, Australia int f(int *p, int *q) { int x = *p; *q = 314; return x; } If p and q alias, the original value n of *p is returned n p q Optimizing x away is unsound: 314 would be returned Alias analysis: to determine whether pointers can alias Aliasing Aliasing: multiple pointers referring to the same object Optimizing x away is unsound: 314 would be returned Alias analysis: to determine whether pointers can alias Aliasing Aliasing: multiple pointers referring to the same object int f(int *p, int *q) { int x = *p; *q = 314; return x; } If p and q alias, the original value n of *p is returned n p q Alias analysis: to determine whether pointers can alias Aliasing Aliasing: multiple pointers referring to the same object int f(int *p, int *q) { int x = *p; *q = 314; return x *p; } If p and q alias, the original value n of *p is returned n p q Optimizing x away is unsound: 314 would be returned Aliasing Aliasing: multiple pointers referring to the same object int f(int *p, int *q) { int x = *p; *q = 314; return x; } If p and q alias, the original value n of *p is returned n p q Optimizing x away is unsound: 314 would be returned Alias analysis: to determine whether pointers can alias It can still be called with aliased pointers: x union { int x; float y; } u; y u.x = 271; return h(&u.x, &u.y); &u.x &u.y C89 allows p and q to be aliased, and thus requires it to return 271 C99/C11 allows type-based alias analysis: I A compiler -

Linux Cheat Sheet
1 of 4 ########################################### # 1.1. File Commands. # Name: Bash CheatSheet # # # # A little overlook of the Bash basics # ls # lists your files # # ls -l # lists your files in 'long format' # Usage: A Helpful Guide # ls -a # lists all files, including hidden files # # ln -s <filename> <link> # creates symbolic link to file # Author: J. Le Coupanec # touch <filename> # creates or updates your file # Date: 2014/11/04 # cat > <filename> # places standard input into file # Edited: 2015/8/18 – Michael Stobb # more <filename> # shows the first part of a file (q to quit) ########################################### head <filename> # outputs the first 10 lines of file tail <filename> # outputs the last 10 lines of file (-f too) # 0. Shortcuts. emacs <filename> # lets you create and edit a file mv <filename1> <filename2> # moves a file cp <filename1> <filename2> # copies a file CTRL+A # move to beginning of line rm <filename> # removes a file CTRL+B # moves backward one character diff <filename1> <filename2> # compares files, and shows where differ CTRL+C # halts the current command wc <filename> # tells you how many lines, words there are CTRL+D # deletes one character backward or logs out of current session chmod -options <filename> # lets you change the permissions on files CTRL+E # moves to end of line gzip <filename> # compresses files CTRL+F # moves forward one character gunzip <filename> # uncompresses files compressed by gzip CTRL+G # aborts the current editing command and ring the terminal bell gzcat <filename> # -

Teach Yourself Perl 5 in 21 Days
Teach Yourself Perl 5 in 21 days David Till Table of Contents: Introduction ● Who Should Read This Book? ● Special Features of This Book ● Programming Examples ● End-of-Day Q& A and Workshop ● Conventions Used in This Book ● What You'll Learn in 21 Days Week 1 Week at a Glance ● Where You're Going Day 1 Getting Started ● What Is Perl? ● How Do I Find Perl? ❍ Where Do I Get Perl? ❍ Other Places to Get Perl ● A Sample Perl Program ● Running a Perl Program ❍ If Something Goes Wrong ● The First Line of Your Perl Program: How Comments Work ❍ Comments ● Line 2: Statements, Tokens, and <STDIN> ❍ Statements and Tokens ❍ Tokens and White Space ❍ What the Tokens Do: Reading from Standard Input ● Line 3: Writing to Standard Output ❍ Function Invocations and Arguments ● Error Messages ● Interpretive Languages Versus Compiled Languages ● Summary ● Q&A ● Workshop ❍ Quiz ❍ Exercises Day 2 Basic Operators and Control Flow ● Storing in Scalar Variables Assignment ❍ The Definition of a Scalar Variable ❍ Scalar Variable Syntax ❍ Assigning a Value to a Scalar Variable ● Performing Arithmetic ❍ Example of Miles-to-Kilometers Conversion ❍ The chop Library Function ● Expressions ❍ Assignments and Expressions ● Other Perl Operators ● Introduction to Conditional Statements ● The if Statement ❍ The Conditional Expression ❍ The Statement Block ❍ Testing for Equality Using == ❍ Other Comparison Operators ● Two-Way Branching Using if and else ● Multi-Way Branching Using elsif ● Writing Loops Using the while Statement ● Nesting Conditional Statements ● Looping Using -

User-Directed Loop-Transformations in Clang
User-Directed Loop-Transformations in Clang Michael Kruse Hal Finkel Argonne Leadership Computing Facility Argonne Leadership Computing Facility Argonne National Laboratory Argonne National Laboratory Argonne, USA Argonne, USA [email protected] hfi[email protected] Abstract—Directives for the compiler such as pragmas can Only #pragma unroll has broad support. #pragma ivdep made help programmers to separate an algorithm’s semantics from popular by icc and Cray to help vectorization is mimicked by its optimization. This keeps the code understandable and easier other compilers as well, but with different interpretations of to optimize for different platforms. Simple transformations such as loop unrolling are already implemented in most mainstream its meaning. However, no compiler allows applying multiple compilers. We recently submitted a proposal to add generalized transformations on a single loop systematically. loop transformations to the OpenMP standard. We are also In addition to straightforward trial-and-error execution time working on an implementation in LLVM/Clang/Polly to show its optimization, code transformation pragmas can be useful for feasibility and usefulness. The current prototype allows applying machine-learning assisted autotuning. The OpenMP approach patterns common to matrix-matrix multiplication optimizations. is to make the programmer responsible for the semantic Index Terms—OpenMP, Pragma, Loop Transformation, correctness of the transformation. This unfortunately makes it C/C++, Clang, LLVM, Polly hard for an autotuner which only measures the timing difference without understanding the code. Such an autotuner would I. MOTIVATION therefore likely suggest transformations that make the program Almost all processor time is spent in some kind of loop, and return wrong results or crash. -

Configuring Your Login Session
SSCC Pub.# 7-9 Last revised: 5/18/99 Configuring Your Login Session When you log into UNIX, you are running a program called a shell. The shell is the program that provides you with the prompt and that submits to the computer commands that you type on the command line. This shell is highly configurable. It has already been partially configured for you, but it is possible to change the way that the shell runs. Many shells run under UNIX. The shell that SSCC users use by default is called the tcsh, pronounced "Tee-Cee-shell", or more simply, the C shell. The C shell can be configured using three files called .login, .cshrc, and .logout, which reside in your home directory. Also, many other programs can be configured using the C shell's configuration files. Below are sample configuration files for the C shell and explanations of the commands contained within these files. As you find commands that you would like to include in your configuration files, use an editor (such as EMACS or nuTPU) to add the lines to your own configuration files. Since the first character of configuration files is a dot ("."), the files are called "dot files". They are also called "hidden files" because you cannot see them when you type the ls command. They can only be listed when using the -a option with the ls command. Other commands may have their own setup files. These files almost always begin with a dot and often end with the letters "rc", which stands for "run commands". -

Configuration and Administration of Networking for Fedora 23
Fedora 23 Networking Guide Configuration and Administration of Networking for Fedora 23 Stephen Wadeley Networking Guide Draft Fedora 23 Networking Guide Configuration and Administration of Networking for Fedora 23 Edition 1.0 Author Stephen Wadeley [email protected] Copyright © 2015 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. The original authors of this document, and Red Hat, designate the Fedora Project as the "Attribution Party" for purposes of CC-BY-SA. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. For guidelines on the permitted uses of the Fedora trademarks, refer to https://fedoraproject.org/wiki/ Legal:Trademark_guidelines. Linux® is the registered trademark of Linus Torvalds in the United States and other countries. Java® is a registered trademark of Oracle and/or its affiliates. XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries.