Examination and Comparison of the Handwriting Characteristics Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grammatica Et Verba Glamor and Verve
“GippertOVprint” — 2014/4/24 — 22:14 — page 81 —#1 Grammatica et verba Glamor and verve Studies in South Asian, historical, and Indo-European linguistics in honor of Hans Henrich Hock on the occasion of his seventy-fifth birthday edited by Shu-Fen Chen and Benjamin Slade Beech Stave Press Ann Arbor New York • “GippertOVprint” — 2014/4/24 — 22:14 — page 82 —#2 © Beech Stave Press, Inc. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Typeset with LATEX using the Galliard typeface designed by Matthew Carter and Greek Old Face by Ralph Hancock. The typeface on the cover is Post Hock by Steve Peter. Library of Congress Cataloging-in-Publication Data Grammatica et verba : glamor and verve : studies in South Asian, historical, and Indo- European linguistics in honor of Hans Henrich Hock on the occasion of his seventy- fifth birthday / edited by Shu-Fen Chen and Benjamin Slade. pages cm Includes bibliographical references. ISBN ---- (alk. paper) . Indo-European languages. Lexicography. Historical linguistics. I. Hock, Hans Henrich, - honoree. II. Chen, Shu-Fen, editor of compilation. III. Slade, Ben- jamin, editor of compilation. –dc Printed in the United States of America “GippertOVprint” — 2014/4/24 — 22:14 — page 83 —#3 TableHHHHHH ofHHHHHHHHHHHHHHH ContentsHHHHHHHHHHHH Preface . vii Bibliography of Hans Henrich Hock . ix List of Contributors . xxi , Traces of Archaic Human Language Structure Anvita Abbi in the Great Andamanese Language. , A Study of Punctuation Errors in the Chinese Diamond Sutra Shu-Fen Chen Based on Sanskrit Texts . -

South Asian Art a Resource for Classroom Teachers
South Asian Art A Resource for Classroom Teachers South Asian Art A Resource for Classroom Teachers Contents 2 Introduction 3 Acknowledgments 4 Map of South Asia 6 Religions of South Asia 8 Connections to Educational Standards Works of Art Hinduism 10 The Sun God (Surya, Sun God) 12 Dancing Ganesha 14 The Gods Sing and Dance for Shiva and Parvati 16 The Monkeys and Bears Build a Bridge to Lanka 18 Krishna Lifts Mount Govardhana Jainism 20 Harinegameshin Transfers Mahavira’s Embryo 22 Jina (Jain Savior-Saint) Seated in Meditation Islam 24 Qasam al-Abbas Arrives from Mecca and Crushes Tahmasp with a Mace 26 Prince Manohar Receives a Magic Ring from a Hermit Buddhism 28 Avalokiteshvara, Bodhisattva of Compassion 30 Vajradhara (the source of all teachings on how to achieve enlightenment) CONTENTS Introduction The Philadelphia Museum of Art is home to one of the most important collections of South Asian and Himalayan art in the Western Hemisphere. The collection includes sculptures, paintings, textiles, architecture, and decorative arts. It spans over two thousand years and encompasses an area of the world that today includes multiple nations and nearly a third of the planet’s population. This vast region has produced thousands of civilizations, birthed major religious traditions, and provided fundamental innovations in the arts and sciences. This teaching resource highlights eleven works of art that reflect the diverse cultures and religions of South Asia and the extraordinary beauty and variety of artworks produced in the region over the centuries. We hope that you enjoy exploring these works of art with your students, looking closely together, and talking about responses to what you see. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -
Census of India Website at Censusinfo.Html
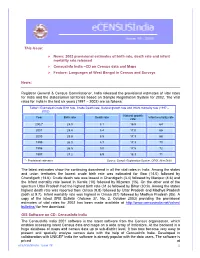
This Issue: News: 2002 provisional estimates of birth rate, death rate and infant mortality rate released CensusInfo India –CD on Census data and Maps Feature: Languages of West Bengal in Census and Surveys News: Registrar General & Census Commissioner, India released the provisional estimates of vital rates for India and the states/union territories based on Sample Registration System for 2002. The vital rates for India in the last six years (1997 – 2002) are as follows: Table1: Estimated Crude Birth rate, Crude Death rate, Natural growth rate and Infant mortality rate (1997 – 2002) Natural growth Year Birth rate Death rate Infant mortality rate rate 2002* 25.0 8.1 16.9 64 2001 25.4 8.4 17.0 66 2000 25.8 8.5 17.3 68 1999 26.0 8.7 17.3 70 1998 26.5 9.0 17.5 72 1997 27.2 8.9 18.3 71 * - Provisional estimates Source: Sample Registration System, ORGI, New Delhi The latest estimates show the continuing downtrend in all the vital rates in India. Among the states and union territories the lowest crude birth rate was estimated for Goa (14.0) followed by Chandigarh (14.6). Crude death rate was lowest in Chandigarh (3.4) followed by Manipur (4.6) and the Infant mortality rate lowest in Kerala (10) followed by Mizoram (15). On the other end of the spectrum Uttar Pradesh had the highest birth rate (31.6) followed by Bihar (30.9). Among the states highest death rate was reported from Orissa (9.8) followed by Uttar Pradesh and Madhya Pradesh (both at 9.7). -

Finite-State Script Normalization and Processing Utilities: the Nisaba Brahmic Library
Finite-state script normalization and processing utilities: The Nisaba Brahmic library Cibu Johny† Lawrence Wolf-Sonkin‡ Alexander Gutkin† Brian Roark‡ Google Research †United Kingdom and ‡United States {cibu,wolfsonkin,agutkin,roark}@google.com Abstract In addition to such normalization issues, some scripts also have well-formedness constraints, i.e., This paper presents an open-source library for efficient low-level processing of ten ma- not all strings of Unicode characters from a single jor South Asian Brahmic scripts. The library script correspond to a valid (i.e., legible) grapheme provides a flexible and extensible framework sequence in the script. Such constraints do not ap- for supporting crucial operations on Brahmic ply in the basic Latin alphabet, where any permuta- scripts, such as NFC, visual normalization, tion of letters can be rendered as a valid string (e.g., reversible transliteration, and validity checks, for use as an acronym). The Brahmic family of implemented in Python within a finite-state scripts, however, including the Devanagari script transducer formalism. We survey some com- mon Brahmic script issues that may adversely used to write Hindi, Marathi and many other South affect the performance of downstream NLP Asian languages, do have such constraints. These tasks, and provide the rationale for finite-state scripts are alphasyllabaries, meaning that they are design and system implementation details. structured around orthographic syllables (aksara)̣ as the basic unit.1 One or more Unicode characters 1 Introduction combine when rendering one of thousands of leg- The Unicode Standard separates the representation ible aksara,̣ but many combinations do not corre- of text from its specific graphical rendering: text spond to any aksara.̣ Given a token in these scripts, is encoded as a sequence of characters, which, at one may want to (a) normalize it to a canonical presentation time are then collectively rendered form; and (b) check whether it is a well-formed into the appropriate sequence of glyphs for display. -

Relation Between Harappan and Brahmi Scripts
Relation Between Harappan And Brahmi Scripts Subhajit Ganguly Email: [email protected] Copyright © Subhajit Ganguly, 2012 Abstract: Around 45 odd signs out of the total number of Harappan signs found make up almost 100 percent of the inscriptions, in some form or other, as said earlier. Out of these 45 signs, around 40 are readily distinguishable. These form an almost exclusive and unique set. The primary signs are seen to have many variants, as in Brahmi. Many of these provide us with quite a vivid picture of their evolution, depending upon the factors of time, place and usefulness. Even minor adjustments in such signs, depending upon these factors, are noteworthy. Many of the signs in this list are the same as or are very similar to the corresponding Brahmi signs. These are similarities that simply cannot arise from mere chance. It is also to be noted that the most frequently used signs in the Brahmi look so similar to the most frequent Harappan symbols. The Harappan script transformed naturally into the Brahmi, depending upon the factors channelizing evolution of scripts. Brahmi Signs: hough a few variants of the Brahmi alphabet system have been known to exist, with the evolution of Brahmi characters, the core signs are seen to be quite consistent over T time. The syntax of their usage has also been found to be roughly consistent throughout this evolution process. Lists of Brahmi numerals, vowels and consonants are provided here in fig. 2and fig. 3 , respectively: 1 Fig. 2 : Brahmi numerals from 1-9. 2 Fig. 3 : Brahmi vowels and consonants. -

Conditioning Factors for Fertility Decline in Bengal: History, Language Identity, and Openness to Innovations
Conditioning Factors for Fertility Decline in Bengal: History, Language Identity, and Openness to Innovations ALAKA MALWADE BASU SAJEDA AMIN DECLINES IN FERTILITY in the contemporary world tend to be explained in contemporary terms. Immediate causes are sought and generally center around issues of changing demand and supply. More specifically, the pro- ponents of the importance of changing demand stress the changing struc- tural conditions that alter the costs and benefits of children, while the “sup- ply-siders” give central importance to family planning programs which purportedly increase awareness and practice of contraception so that birth control becomes both desirable and possible. In recent years, these explanations have become enriched by another class of explanations that focus on the spread of positive attitudes toward controlled fertility and toward contraception. These attitudes may arise through means that are only tangentially related to changing economic en- vironments or to government population policy. In particular, they may develop through a process of diffusion of ideas from individuals already posi- tively inclined in this direction. Montgomery and Casterline (1998) provide a clear definition of such diffusion of attitudes in the context of social change: they refer to diffusion as “a process in which individuals’ decisions…are affected by the knowledge, attitudes, and behavior of others with whom they come in contact” (p. 39). These “others” may be of different kinds—peer groups, elites, family, friends, and so on—and the contact may occur in a vari- ety of ways. Montgomery and Casterline (1998) postulate three principal mechanisms for these “social effects”: social learning, social influence, and social norms. -

Proposal to Encode 0C34 TELUGU LETTER LLLA
Proposal to encode 0C34 TELUGU LETTER LLLA Shriramana Sharma, Suresh Kolichala, Nagarjuna Venna, Vinodh Rajan jamadagni, suresh.kolichala, vnagarjuna and vinodh.vinodh: *-at-gmail.com 2012Jan-17 §1. Character to be encoded 0C34 TELUGU LETTER LLLA §2. Background LLLA is the Unicode term for the native form in South Indian scripts of the voiced retroflex approximant. It is an ill-informed notion that it is limited or unique to one particular language or script. Such written forms are already known to exist in Tamil, Malayalam and Kannada and characters for the same are already encoded in Unicode. Evidence for the native presence of corresponding written forms of LLLA in other South Indian scripts, which may or may not be identical to characters already encoded, is forthcoming. This document provides evidence for Telugu LLLA identical to Kannada LLLA and requests its encoding. Similar evidence is to be expected for other South Indian scripts in future as well. §3. Attestation Currently the Telugu script does not use LLLA. However historic usage before the 10th century is undeniably attested. When the literary Telugu language was effectively standardized by the time of the Mahābhārata of Nannayya in the 11th century, this letter had disappeared from use. It is clear that this disappeared from the Telugu language long before it disappeared from Kannada. However, it was definitely used as part of the Telugu script and language and is considered a Telugu character by Telugu epigraphist scholars. Even though the pre-10th-century Telugu writing had much (more) in common with the Kannada writing of those days and is perhaps better analysed as a single proto-Telugu Kannada script, and hence the older written form would not be a part of the modern Telugu 1 script currently encoded in the block 0C00-0C7F, the modern written form used when transcribing the older form is most definitely a part of the modern Telugu script and hence should be encoded as part of it. -

Neo-Vernacularization of South Asian Languages
LLanguageanguage EEndangermentndangerment andand PPreservationreservation inin SSouthouth AAsiasia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 Language Endangerment and Preservation in South Asia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 PUBLISHED AS A SPECIAL PUBLICATION OF LANGUAGE DOCUMENTATION & CONSERVATION LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA Special Publication No. 7 (January 2014) ed. by Hugo C. Cardoso LANGUAGE DOCUMENTATION & CONSERVATION Department of Linguistics, UHM Moore Hall 569 1890 East-West Road Honolulu, Hawai’i 96822 USA http:/nflrc.hawaii.edu/ldc UNIVERSITY OF HAWAI’I PRESS 2840 Kolowalu Street Honolulu, Hawai’i 96822-1888 USA © All text and images are copyright to the authors, 2014 Licensed under Creative Commons Attribution Non-Commercial No Derivatives License ISBN 978-0-9856211-4-8 http://hdl.handle.net/10125/4607 Contents Contributors iii Foreword 1 Hugo C. Cardoso 1 Death by other means: Neo-vernacularization of South Asian 3 languages E. Annamalai 2 Majority language death 19 Liudmila V. Khokhlova 3 Ahom and Tangsa: Case studies of language maintenance and 46 loss in North East India Stephen Morey 4 Script as a potential demarcator and stabilizer of languages in 78 South Asia Carmen Brandt 5 The lifecycle of Sri Lanka Malay 100 Umberto Ansaldo & Lisa Lim LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA iii CONTRIBUTORS E. ANNAMALAI ([email protected]) is director emeritus of the Central Institute of Indian Languages, Mysore (India). He was chair of Terralingua, a non-profit organization to promote bi-cultural diversity and a panel member of the Endangered Languages Documentation Project, London. -

Proposal for the Encoding of Brāhmī in Plane 1 of ISO/IEC 10646
ISO/IEC JTC 1/SC 2/WG 2 PROPOSAL SUMMARY FORM TO ACCOMPANY SUBMISSIONS FOR ADDITIONS TO THE REPERTOIRE OF ISO/IEC 106461 Please fill all the sections A, B and C below. (Please read Principles and Procedures Document for guidelines and details before filling this form.) See http://www.dkuug.dk/JTC1/SC2/WG2/docs/summaryform.html for latest Form. See http://www.dkuug.dk/JTC1/SC2/WG2/docs/principles.html for latest Principles and Procedures document. See http://www.dkuug.dk/JTC1/SC2/WG2/docs/roadmaps.html for latest roadmaps. A. Administrative 1. Title: Proposal for the Encoding of Brāhmī in Plane 1 of ISO/IEC 10646. 2. Requesters' names: Stefan Baums, Andrew Glass. 3. Requester type (Member body/Liaison/Individual contribution): Individual contribution. 4. Submission date: DRAFT 27 July 2003. 5. Requester's reference (if applicable): N/A. 6. This is a complete proposal. B. Technical - General 1. This proposal is for a new script (set of characters). Proposed name of script: Brāhmī. 2. Number of characters in proposal: 120. 3. Proposed category (see section II, Character Categories): C. 4. Proposed Level of Implementation (1, 2 or 3) (see clause 14, ISO/IEC 10646-1: 2000): 3. Is a rationale provided for the choice? Yes. If Yes, reference: Combining marks are used. 5. Is a repertoire including character names provided? Yes. a. If Yes, are the names in accordance with the 'character naming guidelines in Annex L of ISO/IEC 10646-1: 2000? Yes. b. Are the character shapes attached in a legible form suitable for review? Yes. -

Root Based Stemmer for Telugu Script
International Journal of Engineering and Advanced Technology (IJEAT) ISSN: 2249 – 8958, Volume-8 Issue-6, August 2019 Root Based Stemmer for Telugu Script Narla Swapna Abstract: In this paper, a new stemmer has been proposed The process of stemming is, reducing the inflected or named as “Root based stemmer”. This stemmer is strictly based resultant words to their base words. In general, a stem is a on Dravidian script. Stemming can be used to pick up the written word form. The stem need not be the same to the effectiveness of information retrieval. In proposed Root based morphological root of the word, it is usually enough that stemming technique, each and every token is compared against correlated words map to the identical stem, even if this stem with all the words of a valid root words dictionary until a match is found. Then extract the matched string or substring from a token is not in itself a valid root. In Text classification, stemming and identified as valid root. The present work is aimed to build tries to cut off details like exact form of a word and produce dictionary based stemmer to extract valid root words for Indian word bases as features. In 1960s, the stemming algorithms languages especially for Telugu and compare the results with have been developed in the department of computer science. existing stemmers. While replicating a document, the choice of the suitable Keywords: stemming, Information retrieval, Telugu documentary unit is the first step. A documentary unit consists of set of words extracted from the sentences. The I. -

(RSEP) Request October 16, 2017 Registry Operator INFIBEAM INCORPORATION LIMITED 9Th Floor
Registry Services Evaluation Policy (RSEP) Request October 16, 2017 Registry Operator INFIBEAM INCORPORATION LIMITED 9th Floor, A-Wing Gopal Palace, NehruNagar Ahmedabad, Gujarat 380015 Request Details Case Number: 00874461 This service request should be used to submit a Registry Services Evaluation Policy (RSEP) request. An RSEP is required to add, modify or remove Registry Services for a TLD. More information about the process is available at https://www.icann.org/resources/pages/rsep-2014- 02-19-en Complete the information requested below. All answers marked with a red asterisk are required. Click the Save button to save your work and click the Submit button to submit to ICANN. PROPOSED SERVICE 1. Name of Proposed Service Removal of IDN Languages for .OOO 2. Technical description of Proposed Service. If additional information needs to be considered, attach one PDF file Infibeam Incorporation Limited (“infibeam”) the Registry Operator for the .OOO TLD, intends to change its Registry Service Provider for the .OOO TLD to CentralNic Limited. Accordingly, Infibeam seeks to remove the following IDN languages from Exhibit A of the .OOO New gTLD Registry Agreement: - Armenian script - Avestan script - Azerbaijani language - Balinese script - Bamum script - Batak script - Belarusian language - Bengali script - Bopomofo script - Brahmi script - Buginese script - Buhid script - Bulgarian language - Canadian Aboriginal script - Carian script - Cham script - Cherokee script - Coptic script - Croatian language - Cuneiform script - Devanagari script