Costume Core: Metadata for Historic Clothing Arden Kirkland Syracuse University, [email protected]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Clothing Terms from Around the World
Clothing terms from around the world A Afghan a blanket or shawl of coloured wool knitted or crocheted in strips or squares. Aglet or aiglet is the little plastic or metal cladding on the end of shoelaces that keeps the twine from unravelling. The word comes from the Latin word acus which means needle. In times past, aglets were usually made of metal though some were glass or stone. aiguillette aglet; specifically, a shoulder cord worn by designated military aides. A-line skirt a skirt with panels fitted at the waist and flaring out into a triangular shape. This skirt suits most body types. amice amice a liturgical vestment made of an oblong piece of cloth usually of white linen and worn about the neck and shoulders and partly under the alb. (By the way, if you do not know what an "alb" is, you can find it in this glossary...) alb a full-length white linen ecclesiastical vestment with long sleeves that is gathered at the waist with a cincture aloha shirt Hawaiian shirt angrakha a long robe with an asymmetrical opening in the chest area reaching down to the knees worn by males in India anklet a short sock reaching slightly above the ankle anorak parka anorak apron apron a garment of cloth, plastic, or leather tied around the waist and used to protect clothing or adorn a costume arctic a rubber overshoe reaching to the ankle or above armband a band usually worn around the upper part of a sleeve for identification or in mourning armlet a band, as of cloth or metal, worn around the upper arm armour defensive covering for the body, generally made of metal, used in combat. -

The Complete Costume Dictionary
The Complete Costume Dictionary Elizabeth J. Lewandowski The Scarecrow Press, Inc. Lanham • Toronto • Plymouth, UK 2011 Published by Scarecrow Press, Inc. A wholly owned subsidiary of The Rowman & Littlefield Publishing Group, Inc. 4501 Forbes Boulevard, Suite 200, Lanham, Maryland 20706 http://www.scarecrowpress.com Estover Road, Plymouth PL6 7PY, United Kingdom Copyright © 2011 by Elizabeth J. Lewandowski Unless otherwise noted, all illustrations created by Elizabeth and Dan Lewandowski. All rights reserved. No part of this book may be reproduced in any form or by any electronic or mechanical means, including information storage and retrieval systems, without written permission from the publisher, except by a reviewer who may quote passages in a review. British Library Cataloguing in Publication Information Available Library of Congress Cataloging-in-Publication Data Lewandowski, Elizabeth J., 1960– The complete costume dictionary / Elizabeth J. Lewandowski ; illustrations by Dan Lewandowski. p. cm. Includes bibliographical references. ISBN 978-0-8108-4004-1 (cloth : alk. paper) — ISBN 978-0-8108-7785-6 (ebook) 1. Clothing and dress—Dictionaries. I. Title. GT507.L49 2011 391.003—dc22 2010051944 ϱ ™ The paper used in this publication meets the minimum requirements of American National Standard for Information Sciences—Permanence of Paper for Printed Library Materials, ANSI/NISO Z39.48-1992. Printed in the United States of America For Dan. Without him, I would be a lesser person. It is the fate of those who toil at the lower employments of life, to be rather driven by the fear of evil, than attracted by the prospect of good; to be exposed to censure, without hope of praise; to be disgraced by miscarriage or punished for neglect, where success would have been without applause and diligence without reward. -

Guide to the Wear and Appearance of Army Uniforms and Insignia
Department of the Army Pamphlet 670–1 Uniform and Insignia Guide to the Wear and Appearance of Army Uniforms and Insignia Headquarters Department of the Army Washington, DC 31 March 2014 UNCLASSIFIED SUMMARY DA PAM 670–1 Guide to the Wear and Appearance of Army Uniforms and Insignia This administrative revision, dated 10 April 2014- o Makes administrative changes (paras 13-14e and f, 14-15e and f, 21-12b(4), and 22-16b(4)). o Updates paragraph references and figures (paras 22-17d(6), (7), (8), (10), and (14) and figs 14-13, 21-55, 22-56, and 22-63). This new pamphlet, dated 31 March 2014- o Provides the implementation procedures for wear and appearance of Army uniforms and insignia (throughout). Headquarters Department of the Army Department of the Army Pamphlet 670–1 Washington, DC 31 March 2014 Uniform and Insignia Guide to the Wear and Appearance of Army Uniforms and Insignia Applicability. This pamphlet applies to t o t h e p o l i c y p r o p o n e n t . R e f e r t o A R t h e A c t i v e A r m y , t h e A r m y N a t i o n a l 25–30 for specific guidance. Guard/Army National Guard of the United States, and the U.S. Army Reserve, unless Suggested improvements. Users are otherwise stated. invited to send comments and suggested improvements on DA Form 2028 (Recom- Proponent and exception authority. m e n d e d C h a n g e s t o P u b l i c a t i o n s a n d T h e p r o p o n e n t o f t h i s p a m p h l e t i s t h e Deputy Chief of Staff, G–1. -

Table of Contents Service Khakis 2
Table of Contents Service Khakis 2 - Collar Insignia 4 Navy Working Uniform 7 - Insignia, Chest (Embroidered) 9 Service Dress Blues 11 Summer Whites 15 - Shoulder Boards (Hard) 18 Physical Training Uniform 20 References (1) General Navy Uniform Regulations https://www.public.navy.mil/bupers-npc/support/uniforms/uniformregulations/Pages/defa ult.aspx (2) US Naval Academy Uniform Regulations https://www.usna.edu/UniformRegs/index.php (3) Battalion Handbook Rev 14AUG14 https://nrotc.utah.edu/_documents/BATT%20HAND%202014%2008142014.pdf 1 Service Khakis Required Uniform Components: ● Shirt, Khaki, Service ● Trousers, Khaki, Service ● Cap, Combination, Khaki ● Shoes, Dress, Black ● Socks, Black ● Undershirt, White ● Belt, Khaki, w/Gold Clip ● Buckle, Gold ● Collar Insignia ● Ribbons Optional Items: ● Cap, Garrison, Khaki ● Gloves, Black Non-Leather ● Gloves, Black Leather ● Jacket, Black (Eisenhower) ● Name/Identification Tag ● Cold Weather Parka ● All-Weather Coat, Double Breasted Optional Items list is not exhaustive; refer to reference 1 2 Shirt, Khaki, Service Article 3501.46 Correct Wear When worn, it is tucked into service slacks. Women's shirts button to the left and men's shirts button to the right. The shirt and trousers/slacks/skirt fabric must match (i.e. CNT with CNT and poly/wool with poly/wool). Trousers, Khaki, Service Article 3501.94 Correct Wear Button all buttons, close all fasteners, and wear a belt through all loops. Trousers shall hang approximately 2 inches from the floor at the back of the shoe. Trousers should be tailored to include a 2 inch hem to provide material for adjustments. Cap, Combination, Khaki Article 3501.9 Description A military style cap with black visor,rigid standing front, flaring circular rim and black cap band worn with detachable khaki or white cap cover, as required. -

Uniform Regulations, Comdtinst M1020.6K
Commander US Coast Guard Stop 7200 United States Coast Guard 2703 Martin Luther King Jr Ave SE Personnel Service Center Washington DC 20593-7200 Staff Symbol: PSC-PSD (mu) Phone: (202) 795-6659 COMDTINST M1020.6K 7 JUL 2020 COMMANDANT INSTRUCTION M1020.6K Subj: UNIFORM REGULATIONS Ref: (a) Coast Guard External Affairs Manual, COMDTINST M5700.13 (series) (b) U. S. Coast Guard Personal Property Management Manual, COMDTINST M4500.5 (series) (c) Military Separations, COMDTINST M1000.4 (series) (d) Tattoo, Body Marking, Body Piercing, and Mutilation Policy, COMDTINST 1000.1 (series) (e) Coast Guard Pay Manual, COMDTINST M7220.29 (series) (f) Military Qualifications and Insignia, COMDTINST M1200.1 (series) (g) Coast Guard Military Medals and Awards Manual, COMDTINST M1650.25 (series) (h)Financial Resource Management Manual (FRMM), COMDTINST M7100.3 (series) (i) Rescue and Survival Systems Manual, COMDTINST M10470.10 (series) (j) Coast Guard Aviation Life Support Equipment (ALSE) Manual, COMDTINST M13520.1 (series) (k) Coast Guard Air Operations Manual, COMDTINST M3710.1 (series) (l) Coast Guard Helicopter Rescue Swimmer Manual, COMDTINST M3710.4 (series) (m) U. S. Coast Guard Maritime Law Enforcement Manual (MLEM), COMDTINST M16247.1 (series) (FOUO) [To obtain a copy of this reference contact Commandant (CG-MLE) at (202) 372-2164.] (n) Coast Guard Medical Manual, COMDTINST M6000.1 (series) (o) Standards For Coast Guard Personnel Wearing the Navy Working Uniform (NWU), COMDTINST 1020.10 (series) 1. PURPOSE. This Manual establishes the authority, policies, procedures, and standards governing the uniform, appearance, and grooming of all Coast Guard personnel Active, Reserve, Retired, Auxiliary and other service members assigned to duty with the Coast Guard. -

The Meanings of Qipao As Traditional Dress: Chinese and Taiwanese Perspectives Chui Chu Yang Iowa State University
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 2007 The meanings of qipao as traditional dress: Chinese and Taiwanese perspectives Chui Chu Yang Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the Social and Cultural Anthropology Commons Recommended Citation Yang, Chui Chu, "The meanings of qipao as traditional dress: Chinese and Taiwanese perspectives" (2007). Retrospective Theses and Dissertations. 15604. https://lib.dr.iastate.edu/rtd/15604 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. The meanings of qipao as traditional dress: Chinese and Taiwanese perspectives By Chui Chu Yang A dissertation submitted to the graduate faculty in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Major: Textiles and Clothing Program of Study Committee: Susan J. Torntore, Co-major Professor Mary Lynn Damhorst, Co-major Professor Jean Parsons Lorna Michael Butler Shu Min Huang Iowa State University Ames, Iowa 2007 Copyright © Chui Chu Yang, 2007. All rights reserved. UMI Number: 3289410 UMI Microform 3289410 Copyright 2008 by ProQuest Information and Learning Company. All rights reserved. This microform edition is protected against unauthorized copying under Title 17, United States Code. ProQuest Information and Learning Company 300 North Zeeb Road P.O. Box 1346 Ann Arbor, MI 48106-1346 ii TABLE OF CONTENTS LIST OF TABLES …………………………….……………………………………………v LIST OF FIGURES…………………………….…………………………………………vii ABSTRACT ……………………………………………..…………………………………ix CHAPTER 1: INTRODUCTION......................................................................................... -
Costume Core Controlled Vocabularies - 4Th Draft, May 2016
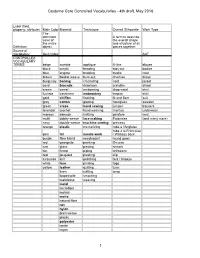
Costume Core Controlled Vocabularies - 4th draft, May 2016 Label (field, property, attribute) Main Color Material Technique Overall Silhouette Work Type The dominant A term to describe color of the overall shape the entire and structure of all Definition object. pieces together. Source of Vocabulary Quilt Index AAT CONTROLLED VOCABULARY TERMS beige acetate applique A-line blouse black acrylic beading bias-cut bodice blue angora braiding bustle coat brown basket weave burn-out chemise dress burgundy boning crocheting coat jacket coral brocade drawloom crinoline shawl cream camel embossing drop-waist shirt fuchsia cashmere embroidery empire skirt gold chiffon flocking fit and flare suit gray cotton glazing hourglass sweater green crepe hand sewing jumper trousers lavender crochet hand weaving mantua underwear maroon damask knitting pinafore vest multi dobby weave lace making Polonaise (and many more) navy double-weave machine sewing princess orange elastic mercerizing robe a l'Anglaise robe a la Francaise pink felt needle work / Watteau back purple fiber blend needlepoint round gown red georgette painting S-curve rust glass piecing sheath tan hemp piping shirtwaist teal jacquard pleating slip turquoise knit polishing tent / trapeze white lace printing toga yellow leather quilting tunic linen ruffling wrap looped pile smocking matelasse weaving metal microfiber mohair moire natural fiber net nylon plain weave plastic polyester ramie rayon 1 Costume Core Controlled Vocabularies - 4th draft, May 2016 Grain Closure Placement Closure Type Neckline Torso A term to describe whether the length/height of the object is cut on the A term to describe straight of grain the location of A term to describe A term to describe (lengthwise or placement of A term to describe the structural the structural crosswise) or on closures on the the type of closures characteristics of characteristics of the bias. -

What Is the Best Way to Begin Learning About Fashion, Trends, and Fashion Designers?
★ What is the best way to begin learning about fashion, trends, and fashion designers? Edit I know a bit, but not much. What are some ways to educate myself when it comes to fashion? Edit Comment • Share (1) • Options Follow Question Promote Question Related Questions • Fashion and Style : Apart from attending formal classes, what are some of the ways for someone interested in fashion designing to learn it as ... (continue) • Fashion and Style : How did the fashion trend of wearing white shoes/sneakers begin? • What's the best way of learning about the business behind the fashion industry? • Fashion and Style : What are the best ways for a new fashion designer to attract customers? • What are good ways to learn more about the fashion industry? More Related Questions Share Question Twitter Facebook LinkedIn Question Stats • Latest activity 11 Mar • This question has 1 monitor with 351833 topic followers. 4627 people have viewed this question. • 39 people are following this question. • 11 Answers Ask to Answer Yolanda Paez Charneco Add Bio • Make Anonymous Add your answer, or answer later. Kathryn Finney, "Oprah of the Internet" . One of the ... (more) 4 votes by Francisco Ceruti, Marie Stein, Unsah Malik, and Natasha Kazachenko Actually celebrities are usually the sign that a trend is nearing it's end and by the time most trends hit magazine like Vogue, they're on the way out. The best way to discover and follow fashion trends is to do one of three things: 1. Order a Subscription to Women's Wear Daily. This is the industry trade paper and has a lot of details on what's happen in fashion from both a trend and business level. -

1 a Aba a Fabric Woven from the Hair of Camels Or Goats. a Loose
A aba a fabric woven from the hair of camels or goats. A loose sleeveless outer garment worn as traditional dress by men in the Middle East. If you are not sure where the Middle East is located, you may wish to find a map from our World section. abaca a naturally occurring fiber found in the stem of the abaca plant. A member of the banana family, Musa Textilis. The fiber is also called Manila Hemp, and is used extensively in the manufacture of marine cordage, abrasive backing papers, tea bags, and other products requiring high tensile strength. accent / novelty yarns these yarns are very very fine and are not intended to be used by themselves; they are intended to be knit with another yarn and will provide additional color and texture to a finished fabric. They do possibly change the gauge of your fabric, so a swatch is recommended whenever you are going to use an accent yarn to make the necessary adjustment to your needle size. (this definition was kindly provided by Karen at Red Meadow Fiber Arts) acrilan (trademark) used for an acrylic fiber. acrylic fiber a quick-drying synthetic textile fiber made by polymerization of acrylonitrile usually with other monomers. adhesives are an essential part of the manufacturing process for a variety of apparel applications ranging from applying labels, decorative trim and waterproofing tapes to innovative solutions like stitchless garment construction. afghan a blanket or shawl of colored wool knitted or crocheted in strips or squares. aiguillette aglet; specifically, a shoulder cord worn by designated military aides. -

Simulation Design of Traditional Costumes Based on Digital Printing Technology
Journal of Fiber Bioengineering and Informatics 9:1 (2016) 19{28 doi:10.3993/jfbim00190 Simulation Design of Traditional Costumes Based on Digital Printing Technology ∗ Zongwen Huang Beijing Institute of Fashion Technology, the School of Fashion Art Engineering Beijing 100029, China Abstract This paper deals with the research on simulation design of traditional Chinese costumes in digital method. We take Chi-pao (Cheongsam), the Mandarin gown of the Qing Dynasty as the research object and conduct a comprehensive analysis of its structures, colors, patterns and other traditional crafts. Then a simulation digital design is made and cutting pieces are printed through digital printer. The finished product shows that the simulation of traditional costumes through this method is feasible to achieve satisfactory results. Thus, simulation design can be used as one of the ways to research, inherit and spread the traditional Chinese costumes. Keywords: Simulation Design; Traditional Costumes; Garment CAD; Digital Printing; Embroidery 1 Introduction After thousands of years of development, Chinese costumes have within itself rich meanings, and have become a source of inspiration for many designers. Digital technology provides a new method for the research on and inheritance of traditional costumes, with fruitful research results. Research on traditional costumes with digital technology is mainly on the following aspects: First, using digital technology for academic classification, information storage and the building of multimedia information database of the traditional costumes [1, 2]; Second, using multimedia virtual scene modeling, multimedia virtual scene display, to demonstrate three-dimensional, full touch interactive costume models, to facilitate a more perceptual, in-depth understanding of traditional costumes [3-5]; Third, developing computer-aided traditional costume design systems so as the classified display and interactive design of traditional costumes are made possible [6]. -

Chinese Influence on Western Women's Dress in American Vogue Magazine, 1960-2009 Yao Zeng Louisiana State University and Agricultural and Mechanical College
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2011 Chinese influence on western women's dress in American Vogue magazine, 1960-2009 Yao Zeng Louisiana State University and Agricultural and Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Human Ecology Commons Recommended Citation Zeng, Yao, "Chinese influence on western women's dress in American Vogue magazine, 1960-2009" (2011). LSU Doctoral Dissertations. 3735. https://digitalcommons.lsu.edu/gradschool_dissertations/3735 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. CHINESE INFLUENCE ON WESTERN WOMEN‟S DRESS IN AMERICAN VOGUE MAGAZINE, 1960-2009 A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College In partial fulfillment of the Requirements for the degree of Doctor of Philosophy in The School of Human Ecology By Yao Zeng B.A., Wuhan Textile University, 1998 M.S., Louisiana State University, 2008 December 2011 ACKOWLEDGMENTS I could not have finished this research project without the graduate assistantship from the Agriculture Center and School of Human Ecology of Louisiana State University, as well as the many people who stood behind me and supported me. I would like to extend my special gratitude to several individuals, in particular, without whom I would not have been able to complete this dissertation and earn my doctorate degree. -

CCI 421.01 EFFECTIVE DATE: 4 August 2020
U.S. DEPARTMENT OF HEALTH COMMISSIONED CORPS INSTRUCTION AND HUMAN SERVICES CCI 421.01 EFFECTIVE DATE: 4 August 2020 By Order of the Assistant Secretary for Health: ADM Brett P. Giroir, M.D. SUBJECT: Uniforms for Male Officers 1. PURPOSE: This Instruction prescribes the various uniforms, uniform articles, and uniform accessories to be worn by male officers of the U.S. Public Health Service (USPHS) Commissioned Corps. This Instruction also provides information on prescribable and optional uniform items, occasions for wearing the uniform, and uniform requirements. 2. APPLICABILITY: This Instruction applies to all male members of the Regular Corps and the Ready Reserve when on active duty. 3. AUTHORITY: 3-1. 42 U.S.C. § 216(a), "Regulations" 3-2. 42 U.S.C. § 217, “Use of Service in Time of War or Emergency” 3-3. 42 U.S.C. § 238g, “Wearing of Uniforms” 3-4. 18 U.S.C. § 702, "Uniform of Armed Forces and Public Health Service" 3-5. Executive Order 11140, "Delegating Certain Functions of the President Relating to the Public Health Service" 3-6. 68 FR 70507, "Statements of Organizations, Functions, and Delegations of Authority" 3-7. Commissioned Corps Directive (CCD) 131.01, "Uniform Regulations" 4. PROPONENT: The proponent of this Instruction is the Assistant Secretary for Health (ASH). The responsibility for ensuring the day-to-day management of the USPHS Commissioned Corps belongs to the Surgeon General (SG). 5. SUMMARY OF REVISIONS AND UPDATES: This is the fifth issuance of this Instruction within the electronic Commissioned Corps Issuance System (eCCIS) and replaces Commissioned Corps Instruction (CCI) 421.01, “Uniforms for Male Officers,” dated 15 December 2015.