Arxiv:1912.08795V2 [Cs.LG] 16 Jun 2020 the Teacher and Student Network Logits
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Training Autoencoders by Alternating Minimization
Under review as a conference paper at ICLR 2018 TRAINING AUTOENCODERS BY ALTERNATING MINI- MIZATION Anonymous authors Paper under double-blind review ABSTRACT We present DANTE, a novel method for training neural networks, in particular autoencoders, using the alternating minimization principle. DANTE provides a distinct perspective in lieu of traditional gradient-based backpropagation techniques commonly used to train deep networks. It utilizes an adaptation of quasi-convex optimization techniques to cast autoencoder training as a bi-quasi-convex optimiza- tion problem. We show that for autoencoder configurations with both differentiable (e.g. sigmoid) and non-differentiable (e.g. ReLU) activation functions, we can perform the alternations very effectively. DANTE effortlessly extends to networks with multiple hidden layers and varying network configurations. In experiments on standard datasets, autoencoders trained using the proposed method were found to be very promising and competitive to traditional backpropagation techniques, both in terms of quality of solution, as well as training speed. 1 INTRODUCTION For much of the recent march of deep learning, gradient-based backpropagation methods, e.g. Stochastic Gradient Descent (SGD) and its variants, have been the mainstay of practitioners. The use of these methods, especially on vast amounts of data, has led to unprecedented progress in several areas of artificial intelligence. On one hand, the intense focus on these techniques has led to an intimate understanding of hardware requirements and code optimizations needed to execute these routines on large datasets in a scalable manner. Today, myriad off-the-shelf and highly optimized packages exist that can churn reasonably large datasets on GPU architectures with relatively mild human involvement and little bootstrap effort. -

ML-Based Interactive Data Visualization System for Diversity and Fairness Issues 1
Jusub Kim : ML-based Interactive Data Visualization System for Diversity and Fairness Issues 1 https://doi.org/10.5392/IJoC.2019.15.4.001 ML-based Interactive Data Visualization System for Diversity and Fairness Issues Sey Min Department of Art & Technology Sogang University, Seoul, Republic of Korea Jusub Kim Department of Art & Technology Sogang University, Seoul, Republic of Korea ABSTRACT As the recent developments of artificial intelligence, particularly machine-learning, impact every aspect of society, they are also increasingly influencing creative fields manifested as new artistic tools and inspirational sources. However, as more artists integrate the technology into their creative works, the issues of diversity and fairness are also emerging in the AI-based creative practice. The data dependency of machine-learning algorithms can amplify the social injustice existing in the real world. In this paper, we present an interactive visualization system for raising the awareness of the diversity and fairness issues. Rather than resorting to education, campaign, or laws on those issues, we have developed a web & ML-based interactive data visualization system. By providing the interactive visual experience on the issues in interesting ways as the form of web content which anyone can access from anywhere, we strive to raise the public awareness of the issues and alleviate the important ethical problems. In this paper, we present the process of developing the ML-based interactive visualization system and discuss the results of this project. The proposed approach can be applied to other areas requiring attention to the issues. Key words: AI Art, Machine Learning, Data Visualization, Diversity, Fairness, Inclusiveness. -

Q-Learning in Continuous State and Action Spaces
-Learning in Continuous Q State and Action Spaces Chris Gaskett, David Wettergreen, and Alexander Zelinsky Robotic Systems Laboratory Department of Systems Engineering Research School of Information Sciences and Engineering The Australian National University Canberra, ACT 0200 Australia [cg dsw alex]@syseng.anu.edu.au j j Abstract. -learning can be used to learn a control policy that max- imises a scalarQ reward through interaction with the environment. - learning is commonly applied to problems with discrete states and ac-Q tions. We describe a method suitable for control tasks which require con- tinuous actions, in response to continuous states. The system consists of a neural network coupled with a novel interpolator. Simulation results are presented for a non-holonomic control task. Advantage Learning, a variation of -learning, is shown enhance learning speed and reliability for this task.Q 1 Introduction Reinforcement learning systems learn by trial-and-error which actions are most valuable in which situations (states) [1]. Feedback is provided in the form of a scalar reward signal which may be delayed. The reward signal is defined in relation to the task to be achieved; reward is given when the system is successfully achieving the task. The value is updated incrementally with experience and is defined as a discounted sum of expected future reward. The learning systems choice of actions in response to states is called its policy. Reinforcement learning lies between the extremes of supervised learning, where the policy is taught by an expert, and unsupervised learning, where no feedback is given and the task is to find structure in data. -

Building Intelligent Systems with Large Scale Deep Learning Jeff Dean Google Brain Team G.Co/Brain
Building Intelligent Systems with Large Scale Deep Learning Jeff Dean Google Brain team g.co/brain Presenting the work of many people at Google Google Brain Team Mission: Make Machines Intelligent. Improve People’s Lives. How do we do this? ● Conduct long-term research (>200 papers, see g.co/brain & g.co/brain/papers) ○ Unsupervised learning of cats, Inception, word2vec, seq2seq, DeepDream, image captioning, neural translation, Magenta, ML for robotics control, healthcare, … ● Build and open-source systems like TensorFlow (see tensorflow.org and https://github.com/tensorflow/tensorflow) ● Collaborate with others at Google and Alphabet to get our work into the hands of billions of people (e.g., RankBrain for Google Search, GMail Smart Reply, Google Photos, Google speech recognition, Google Translate, Waymo, …) ● Train new researchers through internships and the Google Brain Residency program Main Research Areas ● General Machine Learning Algorithms and Techniques ● Computer Systems for Machine Learning ● Natural Language Understanding ● Perception ● Healthcare ● Robotics ● Music and Art Generation Main Research Areas ● General Machine Learning Algorithms and Techniques ● Computer Systems for Machine Learning ● Natural Language Understanding ● Perception ● Healthcare ● Robotics ● Music and Art Generation research.googleblog.com/2017/01 /the-google-brain-team-looking-ba ck-on.html 1980s and 1990s Accuracy neural networks other approaches Scale (data size, model size) 1980s and 1990s more Accuracy compute neural networks other approaches Scale -

Audio Event Classification Using Deep Learning in an End-To-End Approach
Audio Event Classification using Deep Learning in an End-to-End Approach Master thesis Jose Luis Diez Antich Aalborg University Copenhagen A. C. Meyers Vænge 15 2450 Copenhagen SV Denmark Title: Abstract: Audio Event Classification using Deep Learning in an End-to-End Approach The goal of the master thesis is to study the task of Sound Event Classification Participant(s): using Deep Neural Networks in an end- Jose Luis Diez Antich to-end approach. Sound Event Classifi- cation it is a multi-label classification problem of sound sources originated Supervisor(s): from everyday environments. An auto- Hendrik Purwins matic system for it would many applica- tions, for example, it could help users of hearing devices to understand their sur- Page Numbers: 38 roundings or enhance robot navigation systems. The end-to-end approach con- Date of Completion: sists in systems that learn directly from June 16, 2017 data, not from features, and it has been recently applied to audio and its results are remarkable. Even though the re- sults do not show an improvement over standard approaches, the contribution of this thesis is an exploration of deep learning architectures which can be use- ful to understand how networks process audio. The content of this report is freely available, but publication (with reference) may only be pursued due to agreement with the author. Contents 1 Introduction1 1.1 Scope of this work.............................2 2 Deep Learning3 2.1 Overview..................................3 2.2 Multilayer Perceptron...........................4 -

Comparative Analysis of Recurrent Neural Network Architectures for Reservoir Inflow Forecasting
water Article Comparative Analysis of Recurrent Neural Network Architectures for Reservoir Inflow Forecasting Halit Apaydin 1 , Hajar Feizi 2 , Mohammad Taghi Sattari 1,2,* , Muslume Sevba Colak 1 , Shahaboddin Shamshirband 3,4,* and Kwok-Wing Chau 5 1 Department of Agricultural Engineering, Faculty of Agriculture, Ankara University, Ankara 06110, Turkey; [email protected] (H.A.); [email protected] (M.S.C.) 2 Department of Water Engineering, Agriculture Faculty, University of Tabriz, Tabriz 51666, Iran; [email protected] 3 Department for Management of Science and Technology Development, Ton Duc Thang University, Ho Chi Minh City, Vietnam 4 Faculty of Information Technology, Ton Duc Thang University, Ho Chi Minh City, Vietnam 5 Department of Civil and Environmental Engineering, Hong Kong Polytechnic University, Hong Kong, China; [email protected] * Correspondence: [email protected] or [email protected] (M.T.S.); [email protected] (S.S.) Received: 1 April 2020; Accepted: 21 May 2020; Published: 24 May 2020 Abstract: Due to the stochastic nature and complexity of flow, as well as the existence of hydrological uncertainties, predicting streamflow in dam reservoirs, especially in semi-arid and arid areas, is essential for the optimal and timely use of surface water resources. In this research, daily streamflow to the Ermenek hydroelectric dam reservoir located in Turkey is simulated using deep recurrent neural network (RNN) architectures, including bidirectional long short-term memory (Bi-LSTM), gated recurrent unit (GRU), long short-term memory (LSTM), and simple recurrent neural networks (simple RNN). For this purpose, daily observational flow data are used during the period 2012–2018, and all models are coded in Python software programming language. -

Training Deep Networks Without Learning Rates Through Coin Betting
Training Deep Networks without Learning Rates Through Coin Betting Francesco Orabona∗ Tatiana Tommasi∗ Department of Computer Science Department of Computer, Control, and Stony Brook University Management Engineering Stony Brook, NY Sapienza, Rome University, Italy [email protected] [email protected] Abstract Deep learning methods achieve state-of-the-art performance in many application scenarios. Yet, these methods require a significant amount of hyperparameters tuning in order to achieve the best results. In particular, tuning the learning rates in the stochastic optimization process is still one of the main bottlenecks. In this paper, we propose a new stochastic gradient descent procedure for deep networks that does not require any learning rate setting. Contrary to previous methods, we do not adapt the learning rates nor we make use of the assumed curvature of the objective function. Instead, we reduce the optimization process to a game of betting on a coin and propose a learning-rate-free optimal algorithm for this scenario. Theoretical convergence is proven for convex and quasi-convex functions and empirical evidence shows the advantage of our algorithm over popular stochastic gradient algorithms. 1 Introduction In the last years deep learning has demonstrated a great success in a large number of fields and has attracted the attention of various research communities with the consequent development of multiple coding frameworks (e.g., Caffe [Jia et al., 2014], TensorFlow [Abadi et al., 2015]), the diffusion of blogs, online tutorials, books, and dedicated courses. Besides reaching out scientists with different backgrounds, the need of all these supportive tools originates also from the nature of deep learning: it is a methodology that involves many structural details as well as several hyperparameters whose importance has been growing with the recent trend of designing deeper and multi-branches networks. -

Bridging Reinforcement Learning and Creativity: Implementing Reinforcement Learning in Processing
Bridging Reinforcement Learning and Creativity: Implementing Reinforcement Learning in Processing Jieliang Luo Media Arts & Technology Sam Green Computer Science University of California, Santa Barbara SIGGRAPH Asia 2018 Tokyo, Japan December 6th, 2018 Course Agenda • What is Reinforcement Learning (10 mins) ▪ Introduce the core concepts of reinforcement learning • A Brief Survey of Artworks in Deep Learning (5 mins) • Why Processing Community (5 mins) • A Q-Learning Algorithm (35 mins) ▪ Explain a fundamental reinforcement learning algorithm • Implementing Tabular Q-Learning in P5.js (40 mins) ▪ Discuss how to create a reinforcement learning environment ▪ Show how to implement the tabular q-learning algorithm in P5.js • Questions & Answers (5 mins) Bridging Reinforcement Learning and Creativity, Jieliang Luo & Sam Green Psychology Pictures Bridging Reinforcement Learning and Creativity, Jieliang Luo & Sam Green What is Reinforcement Learning • Branch of machine learning • Learns through trial & error, rewards & punishment • Draws from psychology, neuroscience, computer science, optimization Bridging Reinforcement Learning and Creativity, Jieliang Luo & Sam Green Reinforcement Learning Framework Agent Environment Bridging Reinforcement Learning and Creativity, Jieliang Luo & Sam Green https://www.youtube.com/watch?v=V1eYniJ0Rnk Bridging Reinforcement Learning and Creativity, Jieliang Luo & Sam Green https://www.youtube.com/watch?v=ZhsEKTo7V04 Bridging Reinforcement Learning and Creativity, Jieliang Luo & Sam Green Bridging Reinforcement -

The Perceptron
The Perceptron Volker Tresp Summer 2019 1 Elements in Learning Tasks • Collection, cleaning and preprocessing of training data • Definition of a class of learning models. Often defined by the free model parameters in a learning model with a fixed structure (e.g., a Perceptron) (model structure learning: search about model structure) • Selection of a cost function which is a function of the data and the free parameters (e.g., a score related to the number of misclassifications in the training data as a function of the model parameters); a good model has a low cost • Optimizing the cost function via a learning rule to find the best model in the class of learning models under consideration. Typically this means the learning of the optimal parameters in a model with a fixed structure 2 Prototypical Learning Task • Classification of printed or handwritten digits • Application: automatic reading of postal codes • More general: OCR (optical character recognition) 3 Transformation of the Raw Data (2-D) into Pattern Vectors (1-D), which are then the Rows in a Learning Matrix 4 Binary Classification for Digit \5" 5 Data Matrix for Supervised Learning 6 M number of inputs (input attributes) Mp number of free parameters N number of training patterns T xi = (xi;0; : : : ; xi;M ) input vector for the i-th pattern xi;j j-th component of xi T X = (x1;:::; xN ) (design matrix) yi target for the i-th pattern T y = (y1; : : : ; yN ) vector of targets y^i model prediction for xi T di = (xi;0; : : : ; xi;M ; yi) i-th pattern D = fd1;:::; dN g (training data) T x = (x0; x1; : : : ; xM ) , generic (test) input y target for x y^ model estimate fw(x) a model function with parameters w f(x) the\true"but unknown function that generated the data Fine Details on the Notation • x is a generic input and xj is its j-th component. -

Learning Semantics of Raw Audio
Learning Semantics of Raw Audio Davis Foote, Daylen Yang, Mostafa Rohaninejad Group name: “Audio Style Transfer” Introduction Variational Inference Numerically modeling semantics has given some useful exciting results in the We would like to have a latent space in which arithmetic operations domains of images [1] and natural language [2]. We would like to be able to correspond to semantic operations in the observed space. To that end, we operate on raw audio signals at a similar level of abstraction. Consider the adopt the following model, adapted from [1]: problem of trying to interpolate two voices into a voice that sounds “in We interpret the hidden variables � as the latent code. between” the two. Averaging the signals will result in the two voices There is a prior over latent codes �� � and a conditional speaking at once. If this operation were performed in a latent space in which distribution �� � � . In order to be able to encode a data dimensions have semantic meaning, then we would see results which match point, we also need to learn an approximation to the human perception of what this interpolation should mean. posterior distribution, �� � � . We can optimize all these We follow two distinct branches in pursuing this goal. First, motivated by parameters at once using the Auto-Encoding Variational aesthetic results in style transfer [3] and generation of novel styles [4], we Bayes algorithm [1]. Some very simple results (ours) of implement a deep classifier for various musical tags in hopes that the various sampling from this model trained on MNIST are shown: layer activations will encode meaningful high-level audio features. -
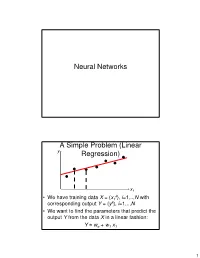
Neural Networks a Simple Problem (Linear Regression)
Neural Networks A Simple Problem (Linear y Regression) x1 k • We have training data X = { x1 }, i=1,.., N with corresponding output Y = { yk}, i=1,.., N • We want to find the parameters that predict the output Y from the data X in a linear fashion: Y ≈ wo + w1 x1 1 A Simple Problem (Linear y Notations:Regression) Superscript: Index of the data point in the training data set; k = kth training data point Subscript: Coordinate of the data point; k x1 = coordinate 1 of data point k. x1 k • We have training data X = { x1 }, k=1,.., N with corresponding output Y = { yk}, k=1,.., N • We want to find the parameters that predict the output Y from the data X in a linear fashion: k k y ≈ wo + w1 x1 A Simple Problem (Linear y Regression) x1 • It is convenient to define an additional “fake” attribute for the input data: xo = 1 • We want to find the parameters that predict the output Y from the data X in a linear fashion: k k k y ≈ woxo + w1 x1 2 More convenient notations y x • Vector of attributes for each training data point:1 k k k x = [ xo ,.., xM ] • We seek a vector of parameters: w = [ wo,.., wM] • Such that we have a linear relation between prediction Y and attributes X: M k k k k k k y ≈ wo xo + w1x1 +L+ wM xM = ∑wi xi = w ⋅ x i =0 More convenient notations y By definition: The dot product between vectors w and xk is: M k k w ⋅ x = ∑wi xi i =0 x • Vector of attributes for each training data point:1 i i i x = [ xo ,.., xM ] • We seek a vector of parameters: w = [ wo,.., wM] • Such that we have a linear relation between prediction Y and attributes X: M k k k k k k y ≈ wo xo + w1x1 +L+ wM xM = ∑wi xi = w ⋅ x i =0 3 Neural Network: Linear Perceptron xo w o Output prediction M wi w x = w ⋅ x x ∑ i i i i =0 w M Input attribute values xM Neural Network: Linear Perceptron Note: This input unit corresponds to the “fake” attribute xo = 1. -

Learning-Rate Annealing Methods for Deep Neural Networks
electronics Article Learning-Rate Annealing Methods for Deep Neural Networks Kensuke Nakamura 1 , Bilel Derbel 2, Kyoung-Jae Won 3 and Byung-Woo Hong 1,* 1 Computer Science Department, Chung-Ang University, Seoul 06974, Korea; [email protected] 2 Computer Science Department, University of Lille, 59655 Lille, France; [email protected] 3 Biotech Research and Innovation Centre (BRIC), University of Copenhagen, Nørregade 10, 1165 Copenhagen, Denmark; [email protected] * Correspondence: [email protected] Abstract: Deep neural networks (DNNs) have achieved great success in the last decades. DNN is optimized using the stochastic gradient descent (SGD) with learning rate annealing that overtakes the adaptive methods in many tasks. However, there is no common choice regarding the scheduled- annealing for SGD. This paper aims to present empirical analysis of learning rate annealing based on the experimental results using the major data-sets on the image classification that is one of the key applications of the DNNs. Our experiment involves recent deep neural network models in combination with a variety of learning rate annealing methods. We also propose an annealing combining the sigmoid function with warmup that is shown to overtake both the adaptive methods and the other existing schedules in accuracy in most cases with DNNs. Keywords: learning rate annealing; stochastic gradient descent; image classification 1. Introduction Citation: Nakamura, K.; Derbel, B.; Deep learning is a machine learning paradigm based on deep neural networks (DNNs) Won, K.-J.; Hong, B.-W. Learning-Rate that have achieved great success in various fields including segmentation, recognition, Annealing Methods for Deep Neural and many others.