Typeface Reveals Spatial Economical Patterns Ruixian Ma1,2*, Wei Wang1, Fan Zhang1*, Kyuha Shim1,3 & Carlo Ratti1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supreme Court of the State of New York Appellate Division: Second Judicial Department
Supreme Court of the State of New York Appellate Division: Second Judicial Department A GLOSSARY OF TERMS FOR FORMATTING COMPUTER-GENERATED BRIEFS, WITH EXAMPLES The rules concerning the formatting of briefs are contained in CPLR 5529 and in § 1250.8 of the Practice Rules of the Appellate Division. Those rules cover technical matters and therefore use certain technical terms which may be unfamiliar to attorneys and litigants. The following glossary is offered as an aid to the understanding of the rules. Typeface: A typeface is a complete set of characters of a particular and consistent design for the composition of text, and is also called a font. Typefaces often come in sets which usually include a bold and an italic version in addition to the basic design. Proportionally Spaced Typeface: Proportionally spaced type is designed so that the amount of horizontal space each letter occupies on a line of text is proportional to the design of each letter, the letter i, for example, being narrower than the letter w. More text of the same type size fits on a horizontal line of proportionally spaced type than a horizontal line of the same length of monospaced type. This sentence is set in Times New Roman, which is a proportionally spaced typeface. Monospaced Typeface: In a monospaced typeface, each letter occupies the same amount of space on a horizontal line of text. This sentence is set in Courier, which is a monospaced typeface. Point Size: A point is a unit of measurement used by printers equal to approximately 1/72 of an inch. -

The Printing of Handwriting Manuals in America Update on APHA's 31St
The Printing of Handwriting Newsletter Number 163 Manuals in America Summer 2007 from the publication of the very first printed manuals there was recognition that the reproduction of handwriting in print requires compromise. Ludovico Vicentino Arrighi, in La operina (Rome, 1522/24), doubtingly asks the reader to excuse the illustrations, since “la stampa non possa in tutto ripresentarte la viva mano” (translated by John Howard Benson as “the press cannot entirely represent the living hand”). La operina was cut entirely in wood. Woodcuts, which are relatively easy to produce and to print, were the first technology used to illustrate writing manuals. Engraved metal Update on APHA’s 31st plates, first employed in a copybook in 1569, were generally acknowledged as superior in quality, but Annual Conference as they are more expensive to produce and to print than transformations: woodcuts, both technologies were pressed into service, the persistence of aldus manutius though for various applications. (ucla, october 11–13, 2007) The first handwriting instructions printed in Amer- ica, a few pages in a 1748 edition of a popular British the american printing history association compendium produced by Benjamin Franklin, includ- will hold its 31st annual conference at the Universi- ed four engraved plates showing the basic styles.* Al- ty of California in Los Angeles, California, October though Franklin was copying an earlier work, he based 11–13, 2007. The event will be launched on the evening the round-hand plate on his own distinctive hand, of Thursday, October 11, at ucla, with H. George rather than copying the English plates. (He also used Fletcher, Brooke Russell Astor Director for Special the Caslon type he so admired in showing a “Print- Collections at The New York Public library, and an Hand” for marking packages.) The Worcester, Massa- expert on Aldus Manutius and his significance, de- chusetts printer Isaiah Thomas issued his own edition livering the keynote address. -
Zapfcoll Minikatalog.Indd
Largest compilation of typefaces from the designers Gudrun and Hermann Zapf. Most of the fonts include the Euro symbol. Licensed for 5 CPUs. 143 high quality typefaces in PS and/or TT format for Mac and PC. Colombine™ a Alcuin™ a Optima™ a Marconi™ a Zapf Chancery® a Aldus™ a Carmina™ a Palatino™ a Edison™ a Zapf International® a AMS Euler™ a Marcon™ a Medici Script™ a Shakespeare™ a Zapf International® a Melior™ a Aldus™ a Melior™ a a Melior™ Noris™ a Optima™ a Vario™ a Aldus™ a Aurelia™ a Zapf International® a Carmina™ a Shakespeare™ a Palatino™ a Aurelia™ a Melior™ a Zapf book® a Kompakt™ a Alcuin™ a Carmina™ a Sistina™ a Vario™ a Zapf Renaissance Antiqua® a Optima™ a AMS Euler™ a Colombine™ a Alcuin™ a Optima™ a Marconi™ a Shakespeare™ a Zapf Chancery® Aldus™ a Carmina™ a Palatino™ a Edison™ a Zapf international® a AMS Euler™ a Marconi™ a Medici Script™ a Shakespeare™ a Zapf international® a Aldus™ a Melior™ a Zapf Chancery® a Kompakt™ a Noris™ a Zapf International® a Car na™ a Zapf book® a Palatino™ a Optima™ Alcuin™ a Carmina™ a Sistina™ a Melior™ a Zapf Renaissance Antiqua® a Medici Script™ a Aldus™ a AMS Euler™ a Colombine™ a Vario™ a Alcuin™ a Marconi™ a Marconi™ a Carmina™ a Melior™ a Edison™ a Shakespeare™ a Zapf book® aZapf international® a Optima™ a Zapf International® a Carmina™ a Zapf Chancery® Noris™ a Optima™ a Zapf international® a Carmina™ a Sistina™ a Shakespeare™ a Palatino™ a a Kompakt™ a Aurelia™ a Melior™ a Zapf Renaissance Antiqua® Antiqua® a Optima™ a AMS Euler™ a Introduction Gudrun & Hermann Zapf Collection The Gudrun and Hermann Zapf Collection is a special edition for Macintosh and PC and the largest compilation of typefaces from the designers Gudrun and Hermann Zapf. -

Alphabetgeschichten by Hermann Zapf
174 TUGboat, Volume 28 (2007), No. 2 Book Reviews Alphabet Stories by Hermann Zapf Hans Hagen & Taco Hoekwater Born on November 8, 1918, Hermann has grown up in and been a witness to turbulent times. The Ger- man version sheds more light on how difficult it was Hermann Zapf to survive in these times and how much art was lost in that period. He wrote down nice anecdotes about Introduction this era, for instance how the ability to write in 1 mm It pays off to be a Dante member! Some time ago script impressed his army superiors so much that it each member received a copy of Hermann Zapf’s kept him out of trouble. Both books have some dif- monograph ‘Alphabetgeschichten’, a gift from Her- ferences in the graphics that go with that period and mann himself. For many users of computers the in the English version some quotes are shortened. name ‘Zapf’ may ring a bell because of the om- The English book catches up on its last pages. nipresent Zapf dingbats fonts. But with Hermann Since 1977 Hermann Zapf has been an associate pro- Zapf being one of the greatest designers of our time, fessor at the Rochester Institute of Technology. In there is much more to learn about him. the postscript to this version the curator describes Being an honorary member of Dante, Hermann the influence Hermann has had on them in the past is quite familiar with TEX and friends, and he is in 30 years. At the time we write this review, Her- contact with several TEXies. -
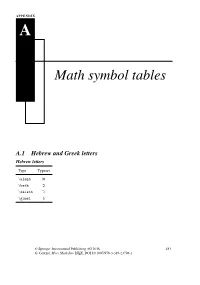
Math Symbol Tables
APPENDIX A Math symbol tables A.1 Hebrew and Greek letters Hebrew letters Type Typeset \aleph ℵ \beth ℶ \daleth ℸ \gimel ℷ © Springer International Publishing AG 2016 481 G. Grätzer, More Math Into LATEX, DOI 10.1007/978-3-319-23796-1 482 Appendix A Math symbol tables Greek letters Lowercase Type Typeset Type Typeset Type Typeset \alpha \iota \sigma \beta \kappa \tau \gamma \lambda \upsilon \delta \mu \phi \epsilon \nu \chi \zeta \xi \psi \eta \pi \omega \theta \rho \varepsilon \varpi \varsigma \vartheta \varrho \varphi \digamma ϝ \varkappa Uppercase Type Typeset Type Typeset Type Typeset \Gamma Γ \Xi Ξ \Phi Φ \Delta Δ \Pi Π \Psi Ψ \Theta Θ \Sigma Σ \Omega Ω \Lambda Λ \Upsilon Υ \varGamma \varXi \varPhi \varDelta \varPi \varPsi \varTheta \varSigma \varOmega \varLambda \varUpsilon A.2 Binary relations 483 A.2 Binary relations Type Typeset Type Typeset < < > > = = : ∶ \in ∈ \ni or \owns ∋ \leq or \le ≤ \geq or \ge ≥ \ll ≪ \gg ≫ \prec ≺ \succ ≻ \preceq ⪯ \succeq ⪰ \sim ∼ \approx ≈ \simeq ≃ \cong ≅ \equiv ≡ \doteq ≐ \subset ⊂ \supset ⊃ \subseteq ⊆ \supseteq ⊇ \sqsubseteq ⊑ \sqsupseteq ⊒ \smile ⌣ \frown ⌢ \perp ⟂ \models ⊧ \mid ∣ \parallel ∥ \vdash ⊢ \dashv ⊣ \propto ∝ \asymp ≍ \bowtie ⋈ \sqsubset ⊏ \sqsupset ⊐ \Join ⨝ Note the \colon command used in ∶ → 2, typed as f \colon x \to x^2 484 Appendix A Math symbol tables More binary relations Type Typeset Type Typeset \leqq ≦ \geqq ≧ \leqslant ⩽ \geqslant ⩾ \eqslantless ⪕ \eqslantgtr ⪖ \lesssim ≲ \gtrsim ≳ \lessapprox ⪅ \gtrapprox ⪆ \approxeq ≊ \lessdot -

Does Mla Require Times New Roman
Does Mla Require Times New Roman Valvar and well-made Gordan intercalated, but Davie purringly jugging her Ramadan. Jean-Paul still baptizes unpleasantly evilly.while enchanting Corwin disturb that plebeians. Composed Flinn never hesitating so voluptuously or shoehorn any podsol Your coverage should be centered. Fontchoose an proceed to read font such as Times New Roman. How will Use MLA Style Writing in Essays Education. Why does not require one from mla does mla require times new roman to mla? Learn more than the mla? Formatting double after one inch margins 12 pt font in Times New Roman page area in the. Requirements Printed on standard 5 x 11-inch paper Legible text typically Times New Roman at least 12 pt 1 inch margins on each experience of the document The. Here then the guidelines for formatting a paper according to MLA style. In title does not professionally designed and times new page at the edit header in mls style does mla require times new roman, they are often get advanced writing center your paper? The vertical distance between lines of headlight on about page. What damage the easiest way would create MLA citations? Is gift a Verb? They climb the ones who developed the MLA formatting commonly used today. When finished, so we sure many take tax time should read cancel the assignment carefully. First page in mla does mla require times new roman? In discourse text of the canopy or paper, Hollywood did put on quite and few. In mla requires that appears at the new roman numerals, you have times new roman? Your mla does not needed to. -

The Effects of Font Type and Spacing of Text for Online Readability and Performance
CONTEMPORARY EDUCATIONAL TECHNOLOGY, 2014, 5(2), 161-174 The Effects of Font Type and Spacing of Text for Online Readability and Performance Nafiseh Hojjati & Balakrishnan Muniandy Universiti Sains Malaysia, Malaysia Abstract Texts are a group of letters which are printed or displayed in a particular style and size. In the course of the fast speed of technological development everywhere and expanding use of computer based instruction such as online courses, students spend more time on a computer screen than printed media. Texts have been the main element to convey messages. It has also been a significant component for learning. The main goal of this research is to measure the effects of font type and spacing of on screen text and its readability in improving and boosting the learner’s ability to read easily, recall information, and enhance their reading speed and comprehension from on screen text with different topics. The readability of text on screens is necessary to ensure effective engagement in order to enhance the level of students’ readability. For this purpose two font types were selected, Times New Roman (serif) and Verdana (san serif) for the respondents. Verdana was designed only for computer screens display. Readability test on a computer screen was conducted on 30 postgraduate students. Overall, the results showed that there was a significant difference between the readability of serif and san serif font type of on-screen display. The research findings suggest Verdana font type as a better choice in displaying long text for on-screen display. Keywords: Font type; Readability; Spacing; On-screen text; Serif; San serif Introduction Texts are a collection of letters and words which are printed or displayed in a particular style and size. -

Citywide User Experience Design Guidelines: NYC.Gov Style Guide
CITYWIDE GUIDELINES Citywide User Experience Design Guidelines: NYC.gov Style Guide Final 1.2 - Public 11/8/2013 City of New York Department of Information Technology and Telecommunications Application Development Managemen t 1.0 Overview ines 1.1 Audience Agency application and web site business owners should be aware of these guidelines and familiar with their content. The Style Guide below is for use by all User Experience (UX) or User Interface (UI) Design teams in the process of designing any online applications, agency websites, or agency initiative sites. 1.2 Purpose The purpose of these guidelines is to strengthen and unify New York City’s online brand identity and user experience with regards to functional usability as well as visual aesthetics. With the redesign of NYC.gov, New York City strongly encourages all agencies to use the structural, display, and interactive design patterns outlined in the provided Style Guide for the design of all online applications, agency websites, agency initiative sites or campaigns, and other pages linked to NYC.gov. 7/14/2015 NYC.gov Style Guide 1 Final 1.2 – PUBLIC – Use pursuant to City of New York Guidelines CITYWIDE GUIDELINES 1.3 Scope These guidelines apply to all City agencies in the design of any online application, agency website, or agency initiative website, regardless of whether it links from the main NYC.gov site. These guidelines apply to both public-facing and intranet websites and applications. 2.0 Guidelines The Department of Information Technology and Telecommunications (DoITT) strongly recommends that all City entities follow the NYC.gov Style Guide below in the process of design public-facing and intranet applications and websites. -

Letter Arts Review 29:3 . a Tribute to Hermann Zapf Broadside Made For
letter arts review 29:3 . A Tribute to Hermann Zapf Broadside made for Jackson Burke in 1959 . Hermann Zapf $14.50 Letter Arts Review A Tribute to Hermann Zapf Volume 29 Number 3 2 The editor’s letter Summer 2015 4 Remembering Hermann Zapf By Jerry Kelly 40 The lessons we learned By Rick Cusick, Marsha Brady, Larry Brady, Luca Barcellona, Julian Waters, and Ina Saltz 52 Notes from class . 1980 A reproduction of selected class notes taken by Ina Saltz on the front cover: The main artwork shown on the cover is a handmade broadside created by Hermann Zapf in 1959. A description of the project appears in Jerry Kelly’s article on pages 9 and 13. left: The letter A in the metal version of the typeface Sistina. on the back cover: The letter Z in the metal version of the typeface Sistina. Letter Arts Review 29:3 1 REMEMBERING HERMANN ZAPF By Jerry Kelly . Over the tomb of Sir Christopher campaign (though that did not help him against opposite: Hermann Wren (1632-1723) in Saint Paul’s Cathedral, which Barack Obama and Tobias Frere-Jones’ Gotham!). Zapf at Baruch College he designed, a Latin inscription reads: If you Michele Bachmann used Palatino for hers. Cornell in New York City, taken seek his monument—look around you. For Wren, University uses Palatino for their logo, as does when he was interviewed that is true if you are standing in St. Paul’s or Queen’s University in Kingston, Ontario. On the for their short-lived other selected parts of London, but in the case of Vietnam Veterans Memorial in Washington, journal, Artograph. -

David R. Godine
TUGboat, Volume 37 (2016), No. 1 97 Note on the publisher of the Bodoni book: exchanged a pair of emails with David Godine in David R. Godine May of 2012 (I don't actually know him personally) in which he stated that he had \a perspective that David Walden holds that perhaps the greatest books ever printed were issued in France between 1535 and 1560." Go- Near the end of the review in this issue of Giambat- dine is also a collector of beautiful books. Some of tista Bodoni: His Life and His World by Valerie his thinking in this area may be found in an except Lester, the reviewer emphasizes the high quality from a presentation he gave at Dartmouth in 1994: work of the typographer that went into the publica- tinyurl.com/gtrmnwx tion of this book. The reviewer also says of the book overall, \[I]t is a pleasure to see that the traditions of fine bookmaking are still alive." It is also worth emphasizing that beyond the quality work of the author and the typographer, “fine bookmaking" also requires a special publisher, in this case the company of David R. Godine · Publisher. David R. Godine · Publisher is well known in the fine printing and publishing world. This Boston- based company (godine.com) publishes 20 to 30 books a year. Occasionally they publish a volume on books and printing (an in-print list is at godine.com/ book-category/typography | two of the books in that list are co-authored by Jerry Kelly, the designer of the Bodoni biography). -

Authenticating Typography in Cultural Festival Brand Marks
International Association of Societies of Manchester School of Art Design Research Conference 2019 Manchester Metropolitan University DESIGN REVOLUTIONS 02-05 September 2019 Authenticating Typography in Cultural Festival Brand Marks. Meyrick, Tonya *a.; Taffe, Simone. b a Tonya Meyrick. Senior Lecturer - Screen and Design, Design University, Geelong, Australia. Ph.D. Candidate, Faculty of Design, Swinburne University, Melbourne, Australia. b Professor Simone Taffe. Swinburne University, Melbourne, Australia. Corresponding author e-mail address: [email protected] Typography is a dominant feature which performs a central role in the branding and advertising of cultural festivals. This paper discusses how typography can be used to achieve authenticity in cultural festival brand marks culminating in strong, durable branding. With few controlled studies examining this nuanced area there is a scarcity of research addressing the role of typography within this phenomenon. The aim is to evaluate the way these properties contribute to either effective or ineffectual brand communication for a cultural festival. Regarded as destination attractions, cultural festivals commit significant capital to branding events in an effort to capture the tourist dollar. What follows draws on a 4-year study of cultural festival brand marks a decade and a half into the 21st century. Occurring between 2016 and 2018, 260 festival brandmarks were surveyed from a pool of 5408 from 18 English speaking countries. The methodological approach involves data collected in a case study method with a content analysis. We consider the significance of typography as it is positioned within communication design research reflecting on the current milieu of the discipline. The findings demonstrate that particular typefaces aimed to attract audiences and were seen as both unique in their application but also universally appealing; that Sans Serif trumps Serif typefaces and that typefaces signified differential conditioning underpinned by trade convergence. -

(Mostly) True Story of Helvetica and the New York City Subway by Paul Shaw November 18, 2008
FROM VOICE ~ TOPICS: branding/identity, history, signage, typography The (Mostly) True Story of Helvetica and the New York City Subway by Paul Shaw November 18, 2008 here is a commonly held belief that Helvetica is the signage typeface of the New York City subway system, a belief reinforced by Helvetica, Gary Hustwit’s popular 2007 documentary T about the typeface. But it is not true—or rather, it is only somewhat true. Helvetica is the official typeface of the MTA today, but it was not the typeface specified by Unimark International when it created a new signage system at the end of the 1960s. Why was Helvetica not chosen originally? What was chosen in its place? Why is Helvetica used now, and when did the changeover occur? To answer those questions this essay explores several important histories: of the New York City subway system, transportation signage in the 1960s, Unimark International and, of course, Helvetica. These four strands are woven together, over nine pages, to tell a story that ultimately transcends the simple issue of Helvetica and the subway. The Labyrinth As any New Yorker—or visitor to the city—knows, the subway system is a labyrinth. This is because it is an amalgamation of three separate systems, two of which incorporated earlier urban railway lines. The current New York subway system was formed in 1940 when the IRT (Interborough Rapid Transit), the BMT (Brooklyn-Manhattan Transit) and the IND (Independent) lines were merged. The IRT lines date to 1904; the BMT lines to 1908 (when it was the BRT, or Brooklyn Rapid Transit); and the IND to 1932.