Iterator Design Pattern Copyright C 2016 by Linda Marshall and Vreda Pieterse
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

One-Slide Summary Lecture Outline
Using Design Patterns #1 One-Slide Summary • Design patterns are solutions to recurring OOP design problems. There are patterns for constructing objects, structuring data, and object behavior . • Since this is PL, we’ll examine how language features like (multiple) inheritance and dynamic dispatch relate to design patterns. #2 Lecture Outline • Design Patterns • Iterator • Observer • Singleton • Mediator #3 1 What is a design pattern? • A solution for a recurring problem in a large object-oriented programming system – Based on Erich Gamma’s Ph.D. thesis, as presented in the “gang of four” book • “Each pattern describes a problem which occurs over and over again in our environment, and then describes the core of the solution to that problem, in such a way that you can use this solution a million times over, without ever doing it the same way twice” – Charles Alexander #4 Types of design patterns • Design patterns can be (roughly) grouped into three categories: • Creational patterns – Constructing objects • Structural patterns – Controlling the structure of a class, e.g. affecting the API or the data structure layout • Behavioral patterns – Deal with how the object behaves #5 Iterator design pattern • Often you may have to move through a collection – Tree (splay, AVL, binary, red-black, etc.), linked list, array, hash table, dictionary, etc. • Easy for arrays and vectors • But hard for more complicated data structures – Hash table, dictionary, etc. • The code doing the iteration should not have to know the details of the data structure -

Object-Oriented Analysis, Design and Implementation
Undergraduate Topics in Computer Science Brahma Dathan Sarnath Ramnath Object-Oriented Analysis, Design and Implementation An Integrated Approach Second Edition Undergraduate Topics in Computer Science Undergraduate Topics in Computer Science (UTiCS) delivers high-quality instruc- tional content for undergraduates studying in all areas of computing and information science. From core foundational and theoretical material to final-year topics and applications, UTiCS books take a fresh, concise, and modern approach and are ideal for self-study or for a one- or two-semester course. The texts are all authored by established experts in their fields, reviewed by an international advisory board, and contain numerous examples and problems. Many include fully worked solutions. More information about this series at http://www.springer.com/series/7592 Brahma Dathan • Sarnath Ramnath Object-Oriented Analysis, Design and Implementation An Integrated Approach Second Edition 123 Brahma Dathan Sarnath Ramnath Department of Information and Computer Department of Computer Science Science and Information Technology Metropolitan State University St. Cloud State University St. Paul, MN St. Cloud, MN USA USA Series editor Ian Mackie Advisory Board Samson Abramsky, University of Oxford, Oxford, UK Karin Breitman, Pontifical Catholic University of Rio de Janeiro, Rio de Janeiro, Brazil Chris Hankin, Imperial College London, London, UK Dexter Kozen, Cornell University, Ithaca, USA Andrew Pitts, University of Cambridge, Cambridge, UK Hanne Riis Nielson, Technical University of Denmark, Kongens Lyngby, Denmark Steven Skiena, Stony Brook University, Stony Brook, USA Iain Stewart, University of Durham, Durham, UK A co-publication with the Universities Press (India) Private Ltd., licensed for sale in all countries outside of India, Pakistan, Bhutan, Bangladesh, Sri Lanka, Nepal, The Maldives, Middle East, Malaysia, Indonesia and Singapore. -

Design Patterns Design Patterns
Design Patterns CSC207 – Software Design Design Patterns • Design pattern: – A general description of the solution to a well- established problem using an arrangement of classes and objects. • Patterns describe the shape of code rather than the details. – There are lots of them in CSC 301 and 302. Loop patterns from first year • Loop pattern: – A general description of an algorithm for processing items in a collection. • All of you (hopefully) have some loop patterns in your heads. • You don’t really need to think about these any more; you just use them, and you should be able to discuss them with your fellow students. • Some first-year patterns: – Process List – Counted Loop – Accumulator – Sentinel Process list pattern • Purpose: to process every item in a collection where you don’t care about order or context; you don’t need to remember previous items. • Outline: • Example: • Other example: darken every pixel in a picture Counted loop pattern • Purpose: to process a range of indices in a collection. • Outline: • Example: • Other example: print indices of even-length string Accumulator pattern • Purpose: to accumulate information about items in a collection. • Outline: • Example: • Other examples: sum, min, accumulate a list of items meeting a particular criterion. Sentinel pattern • Purpose: to remove a condition in a loop guard. • Outline: • Example: Sentinel pattern, continued • Here is the code that Sentinal replaces; note that i != list.size() is evaluated every time through the loop, even though it is false only once. Design Pattern -

Singleton ● Iterator
CSC207 Week 6 Larry Zhang 1 Logistics ● Midterm: next Friday (October 27), 5:10 PM - 7:00 PM ● 110 minutes ● No aid ● Room: TBA (Note it’s not the lecture room) ● Past tests posted on the course website: http://axiom.utm.utoronto.ca/~207/17f/tests.shtml ● Arnold will send emails with more info. 2 Design Patterns 3 /r/LifeProTips 4 Design Patterns Design patterns are like “LifeProTips” for software design. ● Effective use of the OO Paradigm. ● Using the patterns results in flexible, malleable, maintainable code. ● It usually allows plug and play additions to existing code. ● It gives developers a vocabulary to talk about recurring class organizations. 5 Design Patterns for Today ● Observer ● Singleton ● Iterator 6 The Observer Pattern 7 Goals ● When certain objects need to be informed about the changes occurred in other objects. ● One object changes state, all its dependents are notified and updated automatically. ● Programmer only need to worry about how the observer changes if the observables changes, and connecting the observers and observables. ● Real-life example: setting up Pre-Authorized Bill Payment 8 General Implementation 9 Java Implementation 10 DEMO #1 Implement Our Own Observer/Observable observer/Observable.java observer/Observer.java 11 DEMO #2 Use Our Observer/Observable observer/LightBulb.java observer/LightBulbObserver.java observer/LightBulbObservable.java observer/LightBulbMain.java 12 Advanced Issues in Observer Pattern Push and Pull communication methods ● Push model: the Observable send all information about the change -

Java Design Patterns I
Java Design Patterns i Java Design Patterns Java Design Patterns ii Contents 1 Introduction to Design Patterns 1 1.1 Introduction......................................................1 1.2 What are Design Patterns...............................................1 1.3 Why use them.....................................................2 1.4 How to select and use one...............................................2 1.5 Categorization of patterns...............................................3 1.5.1 Creational patterns..............................................3 1.5.2 Structural patterns..............................................3 1.5.3 Behavior patterns...............................................3 2 Adapter Design Pattern 5 2.1 Adapter Pattern....................................................5 2.2 An Adapter to rescue.................................................6 2.3 Solution to the problem................................................7 2.4 Class Adapter..................................................... 11 2.5 When to use Adapter Pattern............................................. 12 2.6 Download the Source Code.............................................. 12 3 Facade Design Pattern 13 3.1 Introduction...................................................... 13 3.2 What is the Facade Pattern.............................................. 13 3.3 Solution to the problem................................................ 14 3.4 Use of the Facade Pattern............................................... 16 3.5 Download the Source Code............................................. -

Cofree Traversable Functors
IT 19 035 Examensarbete 15 hp September 2019 Cofree Traversable Functors Love Waern Institutionen för informationsteknologi Department of Information Technology Abstract Cofree Traversable Functors Love Waern Teknisk- naturvetenskaplig fakultet UTH-enheten Traversable functors see widespread use in purely functional programming as an approach to the iterator pattern. Unlike other commonly used functor families, free Besöksadress: constructions of traversable functors have not yet been described. Free constructions Ångströmlaboratoriet Lägerhyddsvägen 1 have previously found powerful applications in purely functional programming, as they Hus 4, Plan 0 embody the concept of providing the minimal amount of structure needed to create members of a complex family out of members of a simpler, underlying family. This Postadress: thesis introduces Cofree Traversable Functors, together with a provably valid Box 536 751 21 Uppsala implementation, thereby developing a family of free constructions for traversable functors. As free constructions, cofree traversable functors may be used in order to Telefon: create novel traversable functors from regular functors. Cofree traversable functors 018 – 471 30 03 may also be leveraged in order to manipulate traversable functors generically. Telefax: 018 – 471 30 00 Hemsida: http://www.teknat.uu.se/student Handledare: Justin Pearson Ämnesgranskare: Tjark Weber Examinator: Johannes Borgström IT 19 035 Tryckt av: Reprocentralen ITC Contents 1 Introduction7 2 Background9 2.1 Parametric Polymorphism and Kinds..............9 2.2 Type Classes........................... 11 2.3 Functors and Natural Transformations............. 12 2.4 Applicative Functors....................... 15 2.5 Traversable Functors....................... 17 2.6 Traversable Morphisms...................... 22 2.7 Free Constructions........................ 25 3 Method 27 4 Category-Theoretical Definition 28 4.1 Applicative Functors and Applicative Morphisms...... -

Template Method, Factory Method, and Composite
CHAPTER 7 Template Method, Factory Method, and Composite Objectives The objectives of this chapter are to identify the following: • Introduce the template, factory, and composite patterns. • Create basic UML diagrams for these design patterns. • Review the UML collaboration and deployment diagrams. Software Development Methods 1 Template Method, Factory Method, and Composite Template Method Use the Template Method pattern to: Pattern • Define a skeleton of an algorithm in a base class but defer certain steps to derived classes. This allows a subclass to provide a specific implementation for a single step within an algorithm without using the strategy or bridge pat- terns. Template Methods have two (2) participants: • An Abstract Class which defines the abstract operations that will be imple- mented by the concrete subclasses. This class also defines the skeleton of the algorithm. • A Concrete Class which implements the primitive abstract methods declared in the abstract class. The results we gain from implementing a Template Method pattern are: • An inverted control structure. The parent class, via inheritance and polymor- phism, calls the derived class’ methods and not vice versa. To illustrate this design pattern, the following trivial example: class ClassA { protected: virtual void doPrint(void) = 0; public: void print(void); }; The Java equivalent might appear as: public class ClassA { protected abstract void doPrint(); public void print() { ... } }; Now we implement the print() method in the abstract class: void ClassA::print() { // do some stuff doPrint(); // do more stuff } The corresponding Java code might appear as: 2 Software Development Methods Template Method, Factory Method, and Composite public void print() { // do some stuff doPrint(); // do more stuff } No we need to define the doPrint() method. -
Design Pattern Case Studies with C++ Douglas C. Schmidt Http
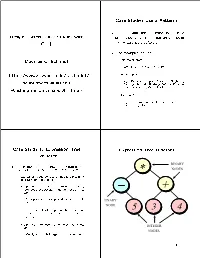
Case Studies Using Patterns The following slides describ e several case Design Pattern Case Studies with studies using C++ and patterns to build highly extensible software C++ The examples include 1. Expression trees Douglas C. Schmidt { e.g., Bridge, Factory, Adapter 2. System Sort http://www.cs.wustl.edu/schmidt/ { e.g., Facade, Adapter, Iterator, Singleton, [email protected] Factory Metho d, Strategy, Bridge, Double- Checked Lo cking Optimization Washington University, St. Louis 3. Sort Veri er { e.g., Strategy, Factory Metho d, Facade, It- erator, Singleton 2 1 Case Study 1: Expression Tree Expression Tree Diagram Evaluator BINARY The following inheritance and dynamic bind- NODES example constructs expression trees ing * { Expression trees consist of no des containing op erators and op erands _ Op erators have di erent precedence levels, + di erent asso ciativities, and di erent arities, e.g., Multiplication takes precedence over addi- UNARY tion NODE 55 33 44 The multiplication op erator has two argu- ments, whereas unary minus op erator has only one Op erands are integers, doubles, variables, INTEGER etc. NODES We'll just handle integers in this example::: 3 4 C Version Expression Tree Behavior A typical functional metho d for implement- ing expression trees in C involves using a struct/union to represent data structure, Expression trees e.g., { Trees may be \evaluated" via di erent traver- sals typ edef struct Tree No de Tree No de; struct Tree No de f e.g., in-order, p ost-order, pre-order, level- enum f order NUM, -

Object-Oriented Design & Patterns
Object-Oriented Design & Patterns 2nd edition Cay S. Horstmann Chapter 5: Patterns and GUI Programming CPSC 2100 Software Design and Development 1 Chapter Topics • The Iterators as Patterns. • The Pattern Concept. • The OBSERVER Pattern. • Layout Managers and the STRATEGY Pattern. • Components, Containers, and the COMPOSITE Pattern. • Scroll Bars and the DECORATOR Pattern. • How to Recognize Patterns. • Putting Patterns to Work. CPSC 2100 University of Tennessee at Chattanooga –Fall 2013 2 Chapter Objective • Introduce the concept of Patterns. • Explain Patterns with examples from the Swing user interface toolkit, to learn about Patterns and GUI programming at the same time. CPSC 2100 University of Tennessee at Chattanooga –Fall 2013 3 List Iterators LinkedList<String> list = . .; ListIterator<String> iterator = list.listIterator(); while (iterator.hasNext()) { String current = iterator.next(); . } Why iterators? CPSC 2100 University of Tennessee at Chattanooga –Fall 2013 4 Classical List Data Structure • Traverse links directly Link currentLink = list.head; while (currentLink != null) { Object current = currentLink.data; currentLink = currentLink.next; } • Problems: o Exposes implementation of the links to the users. o Error-prone. CPSC 2100 University of Tennessee at Chattanooga –Fall 2013 5 High-Level View of Data Structures • Queue void add(E x) Figure 1: The Queue Interface E peek() E remove() int size() • Array with random access E get(int i) void set(int i, E x) void add(E x) int size() Figure 2: The Array Interface CPSC 2100 University -

Javascript Patterns
JavaScript Patterns JavaScript Patterns Stoyan Stefanov Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo JavaScript Patterns by Stoyan Stefanov Copyright © 2010 Yahoo!, Inc.. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (http://my.safaribooksonline.com). For more information, contact our corporate/institutional sales department: (800) 998-9938 or [email protected]. Editor: Mary Treseler Indexer: Potomac Indexing, LLC Production Editor: Teresa Elsey Cover Designer: Karen Montgomery Copyeditor: ContentWorks, Inc. Interior Designer: David Futato Proofreader: Teresa Elsey Illustrator: Robert Romano Printing History: September 2010: First Edition. Nutshell Handbook, the Nutshell Handbook logo, and the O’Reilly logo are registered trademarks of O’Reilly Media, Inc. JavaScript Patterns, the image of a European partridge, and related trade dress are trademarks of O’Reilly Media, Inc. Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O’Reilly Media, Inc., was aware of a trademark claim, the designations have been printed in caps or initial caps. While every precaution has been taken in the preparation of this book, the publisher and author assume no responsibility for errors or omissions, or for damages resulting from the use of the information con- tained herein. ISBN: 978-0-596-80675-0 [SB] 1284038177 To my girls: Eva, Zlatina, and Nathalie Table of Contents Preface . ................................................................... xiii 1. Introduction . -

The Singleton Design Pattern See
CSC 7322 : Object Oriented Development J Paul Gibson, A207 /~gibson/Teaching/CSC7322/ Design Patterns Revisited …/~gibson/Teaching/CSC7322/L11-DesignPatterns-2.pdf 2013: J Paul Gibson TSP: Software Engineering CSC7322/ DesignPatterns .1 Learning by PBL – the patterns selected 1. Singleton - creational 2. Iterator – behavioural 3. Visitor – behavioural 4. Proxy - structural 5. Factory - creational 6. Decorator – structural 7. Facade - structural 8. Adapter - structural 9. Chain Of Responsibility - behavioural 10. MVC – a composite pattern (Strategy, Observer, composite) NOTE : you should have a reasonable understanding of all 23 patterns, and a good understanding of implementation concerns in at least 2 different OO languages. 2013: J Paul Gibson TSP: Software Engineering CSC7322/ DesignPatterns .2 The Singleton Design Pattern See - http://sourcemaking.com/design_patterns/singleton •Intent •Ensure a class has only one instance, and provide a global point of access to it. •Encapsulated “just -in -time initialization” or “initialization on first use”. •Problem •Application needs one, and only one, instance of an object. •Additionally, lazy initialization and global access are necessary. 2013: J Paul Gibson TSP: Software Engineering CSC7322/ DesignPatterns .3 The Singleton Design Pattern See - http://sourcemaking.com/design_patterns/singleton Relation to other patterns •Abstract Factory, Builder, and Prototype can use Singleton in their implementation. •Facade objects are often Singletons because only one Facade object is required. •The advantage of Singleton over global variables is that you are absolutely sure of the number of instances when you use Singleton. •The Singleton design pattern is one of the most inappropriately used patterns. Designers frequently use Singletons in a misguided attempt to replace global variables. A Singleton is, for intents and purposes, a global variable. -
![Design Patterns [R15a0528] Lecture Notes](https://docslib.b-cdn.net/cover/3643/design-patterns-r15a0528-lecture-notes-5013643.webp)
Design Patterns [R15a0528] Lecture Notes
DESIGN PATTERNS [R15A0528] LECTURE NOTES B.TECH IV YEAR – I SEM (R15) (2019-20) DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING MALLA REDDY COLLEGE OF ENGINEERING & TECHNOLOGY (Autonomous Institution – UGC, Govt. of India) Recognized under 2(f) and 12 (B) of UGC ACT 1956 (Affiliated to JNTUH, Hyderabad, Approved by AICTE - Accredited by NBA & NAAC – ‘A’ Grade - ISO 9001:2015 Certified) Maisammaguda, Dhulapally (Post Via. Hakimpet), Secunderabad – 500100, Telangana State, India IV Year B. Tech. CSE –I Sem L T/P/D C 4 1/- / - 3 (R15A0528) DESIGN PATTERNS Objectives: Design patterns are a systematic approach that focus and describe abstract systems of interaction between classes, objects, and communication flow Given OO design heuristics, patterns or published guidance, evaluate a design for applicability, reasonableness, and relation to other design criteria. Comprehend the nature of design patterns by understanding a small number of examples from different pattern categories, and to be able to apply these patterns in creating an OO design. Good knowledge on the documentation effort required for designing the patterns. Outcomes: Upon completion of this course, students should be able to: Have a deeper knowledge of the principles of object - oriented design Understand how these patterns related to object - oriented design. Understand the design patterns that are common in software applications. Will able to use patterns and have deeper knowledge of patterns. Will be able to document good design pattern structures. UNIT I: Introduction: What Is a Design Pattern? Design Patterns in Smalltalk MVC, Describing Design Patterns, The Catalog of Design Patterns, Organizing the Catalog, How Design Patterns Solve Design Problems, How to Select a Design Pattern, How to Use a Design Pattern.