Towards Secure Web Browsing on Mobile Devices
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Written Testimony of Keith Enright Chief Privacy Officer, Google United
Written Testimony of Keith Enright Chief Privacy Officer, Google United States Senate Committee on Commerce, Science, and Transportation Hearing on “Examining Safeguards for Consumer Data Privacy” September 26, 2018 Chairman Thune, Ranking Member Nelson, and distinguished members of the Committee: thank you for the opportunity to appear before you this morning. I appreciate your leadership on the important issues of data privacy and security, and I welcome the opportunity to discuss Google’s work in these areas. My name is Keith Enright, and I am the Chief Privacy Officer for Google. I have worked at the intersection of technology, privacy, and the law for nearly 20 years, including as the functional privacy lead for two other companies prior to joining Google in 2011. In that time, I have been fortunate to engage with legislators, regulatory agencies, academics, and civil society to help inform and improve privacy protections for individuals around the world. I lead Google’s global privacy legal team and, together with product and engineering partners, direct our Office of Privacy and Data Protection, which is responsible for legal compliance, the application of our privacy principles, and generally meeting our users’ expectations of privacy. This work is the effort of a large cross-functional team of engineers, researchers, and other experts whose principal mission is protecting the privacy of our users. Across every single economic sector, government function, and organizational mission, data and technology are critical keys to success. With advances in artificial intelligence and machine learning, data-based research and services will continue to drive economic development and social progress in the years to come. -

Guideline for Securing Your Web Browser P a G E | 2
CMSGu2011-02 CERT-MU SECURITY GUIDELINE 2011 - 02 Mauritian Computer Emergency Response Team Enhancing Cyber Security in Mauritius Guideline For Securing Your Web Browser National Computer Board Mauritius JuJunene 2011 2011 Version 1.7 IssueIssue No. No. 4 2 National Computer Board © Table of Contents 1.0 Introduction .......................................................................................................................... 7 1.1 Purpose and Scope ........................................................................................................... 7 1.2 Audience........................................................................................................................... 7 1.3 Document Structure.......................................................................................................... 7 2.0 Background .......................................................................................................................... 8 3.0 Types of Web Browsers ....................................................................................................... 9 3.1 Microsoft Internet Explorer .............................................................................................. 9 3.2 Mozilla Firefox ................................................................................................................. 9 3.3 Safari ................................................................................................................................ 9 3.4 Chrome .......................................................................................................................... -

View the Slides
Alice in Warningland A Large-Scale Field Study of Browser Security Warning Effectiveness Devdatta Akhawe Adrienne Porter Felt UC Berkeley Google, Inc. Given a choice between dancing pigs and security, the user will pick dancing pigs every time Felten and McGraw Securing Java 1999 a growing body of measurement studies make clear that ...[users] are oblivious to security cues [and] ignore certificate error warnings Herley The Plight of The Targeted Attacker at Scale 2010 Evidence from experimental studies indicates that most people don’t read computer warnings, don’t understand them, or simply don’t heed them, even when the situation is clearly hazardous. Bravo-Lillo Bridging the Gap in Computer Security Warnings 2011 Firefox Malware Warning Chrome SSL Warning Firefox SSL Warning today A large scale measurement of user responses to modern warnings in situ today A large scale measurement of user responses to modern warnings in situ What did we measure? Clickthrough Rate # warnings ignored # warnings shown (across all users) What is the ideal click through rate? 0% Why aim for a 0% rate? • Low false positives => protecting users – The Google Safe Browsing list (malware/phishing warnings) has low false positives • High false positives ? (SSL Warnings) – Low clickthrough incentivizes websites to fix their SSL errors – False positives annoy users and browsers should reduce the number of false warnings to achieve 0% clickthrough rate How did we measure it? Browser Telemetry • A mechanism for browsers to collect pseudonymous performance and quality -

Opensocialに見る Googleのオープン戦略 G オ 戦略
OpenSocialに見る Googleのオオ戦略ープン戦略 Seasar Conference 2008 Autumn よういちろう(TANAKA Yoichiro) (C) 2008 Yoichiro Tanaka. All rights reserved. 08.9.6 1 Seasar Conference 2008 Autumn Self‐introduction • 田中 洋郎洋一郎(TANAKA Yoichiro) – Mash up Award 3rd 3部門同時受賞 – Google API Expert(OpenSocial) 天使やカイザー と呼ばれて 検索 (C) 2008 Yoichiro Tanaka. All rights reserved. 08.9.6 2 Seasar Conference 2008 Autumn Agenda • Impression of Google • What’s OpenSocial? • Process to open • Google now (C) 2008 Yoichiro Tanaka. All rights reserved. 08.9.6 3 Seasar Conference 2008 Autumn Agenda • Impression of Google • What’s OpenSocial? • Process to open • Google now (C) 2008 Yoichiro Tanaka. All rights reserved. 08.9.6 4 Seasar Conference 2008 Autumn Services produced by Google http://www.google.co.jp/intl/ja/options/ (C) 2008 Yoichiro Tanaka. All rights reserved. 08.9.6 5 Seasar Conference 2008 Autumn APIs & Developer Tools Android Google Web Toolkit Blogger Data API Chromium Feedbunner APIs Gadgets API Gmail Atom Feeds Google Account Google AdSense API Google AdSense for Audio Authentication API Google AdWords API Google AJAX APIs Google AJAX Feed API Google AJAX LAnguage API Google AJAX Search API Google Analytics Google App Engine Google Apps APIs Google Base Data API Google Book Search APIs Google Calendar APIs and Google Chart API Google Checkout API Google Code Search Google Code Search Data Tools API GlGoogle Custom ShSearch API GlGoogle Contacts Data API GlGoogle Coupon FdFeeds GlGoogle DkDesktop GdGadget GlGoogle DkDesktop ShSearch API APIs Google Documents List Google -

FN1206: the Path to Operational Enlightenment
Use this if there will be two speakers for your session. FN1206: © 2019 SPLUNK INC. The Path to Operational Enlightenment An Introduction to Wire Data Simon O’Brien Vinu Alazath Principal Sales Engineer | Splunk Software Engineer | Splunk © 2019 SPLUNK INC. During the course of this presentation, we may make forward‐looking statements Forward- regarding future events or plans of the company. We caution you that such statements reflect our current expectations and estimates based on factors currently known to us Looking and that actual events or results may differ materially. The forward-looking statements made in the this presentation are being made as of the time and date of its live Statements presentation. If reviewed after its live presentation, it may not contain current or accurate information. We do not assume any obligation to update any forward‐looking statements made herein. In addition, any information about our roadmap outlines our general product direction and is subject to change at any time without notice. It is for informational purposes only, and shall not be incorporated into any contract or other commitment. Splunk undertakes no obligation either to develop the features or functionalities described or to include any such feature or functionality in a future release. Splunk, Splunk>, Turn Data Into Doing, The Engine for Machine Data, Splunk Cloud, Splunk Light and SPL are trademarks and registered trademarks of Splunk Inc. in the United States and other countries. All other brand names, product names, or trademarks belong to their respective owners. © 2019 Splunk Inc. All rights reserved. © 2019 SPLUNK INC. Agenda Challenges Product Overview Architecture and Deployment Demo Stream futures © 2019 SPLUNK INC. -
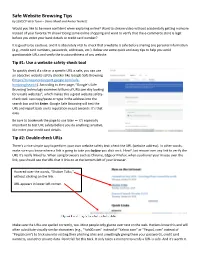
Safe Website Browsing Tips
Safe Website Browsing Tips by SSNDCP Web Team – Diane Maidl and Amber Norkett Would you like to be more confident when exploring online? Want to stream video without accidentally getting malware instead of your favorite TV show? Doing some online shopping and want to verify that the e-commerce store is legit before you enter your bank details or credit card number? It is good to be cautious, and it is absolutely vital to check that a website is safe before sharing any personal information (e.g., credit card numbers, passwords, addresses, etc.). Below are some quick and easy tips to help you avoid questionable URLs and verify the trustworthiness of any website. Tip #1: Use a website safety-check tool To quickly check if a site or a specific URL is safe, you can use an objective website safety checker like Google Safe Browsing (https://transparencyreport.google.com/safe- browsing/search). According to their page, “Google’s Safe Browsing technology examines billions of URLs per day looking for unsafe websites”, which makes this a great website safety- check tool. Just copy/paste or type in the address into the search box and hit Enter. Google Safe Browsing will test the URL and report back on its reputation in just seconds. It’s that easy. Be sure to bookmark the page to use later — it’s especially important to test URL safety before you do anything sensitive, like enter your credit card details. Tip #2: Double-check URLs There’s a nice simple way to perform your own website safety test: check the URL (website address). -

X41 D-SEC Gmbh Dennewartstr
Browser Security White PAPER Final PAPER 2017-09-19 Markus VERVIER, Michele Orrù, Berend-Jan WEVER, Eric Sesterhenn X41 D-SEC GmbH Dennewartstr. 25-27 D-52068 Aachen Amtsgericht Aachen: HRB19989 Browser Security White PAPER Revision History Revision Date Change Editor 1 2017-04-18 Initial Document E. Sesterhenn 2 2017-04-28 Phase 1 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 3 2017-05-19 Phase 2 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 4 2017-05-25 Phase 3 M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 5 2017-06-05 First DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 6 2017-06-26 Second DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 7 2017-07-24 Final DrAFT M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 8 2017-08-25 Final PAPER M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER 9 2017-09-19 Public Release M. VERVIER, M. Orrù, E. Sesterhenn, B.-J. WEVER X41 D-SEC GmbH PAGE 1 OF 196 Contents 1 ExECUTIVE Summary 7 2 Methodology 10 3 Introduction 12 3.1 Google Chrome . 13 3.2 Microsoft Edge . 14 3.3 Microsoft Internet Explorer (IE) . 16 4 Attack Surface 18 4.1 Supported Standards . 18 4.1.1 WEB TECHNOLOGIES . 18 5 Organizational Security Aspects 21 5.1 Bug Bounties . 21 5.1.1 Google Chrome . 21 5.1.2 Microsoft Edge . 22 5.1.3 Internet Explorer . 22 5.2 Exploit Pricing . 22 5.2.1 ZERODIUM . 23 5.2.2 Pwn2Own . -

Browser Security Comparison – a Quantitative Approach Page| I of V Version 0.0 Revision Date: 12/6/2011
Browser Security Comparison A Quantitative Approach Document Profile Version 0.0 Published 12/6/2011 Revision History Version Date Description 0.0 12/26/2011 Document published. Browser Security Comparison – A Quantitative Approach Page| i of v Version 0.0 Revision Date: 12/6/2011 Contents Authors .......................................................................................................................................................... v Executive Summary ....................................................................................................................................... 1 Methodology Delta ................................................................................................................................... 1 Results ....................................................................................................................................................... 2 Conclusion ................................................................................................................................................. 2 Introduction .................................................................................................................................................. 3 Analysis Targets ........................................................................................................................................ 4 Analysis Environment................................................................................................................................ 4 Analysis -

System for Detection of Websites with Phishing and Other Malicious Content
Masaryk University Faculty of Informatics System for detection of websites with phishing and other malicious content BachelorŠs Thesis Tomáš Ševčovič Brno, Fall 2017 Declaration Hereby I declare that this paper is my original authorial work, which I have worked out on my own. All sources, references, and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Tomáš Ševčovič Advisor: prof. RNDr. Václav Matyáš, M.Sc., Ph.D. i Acknowledgement I would like to thank prof. RNDr. Václav Matyáš, M.Sc., Ph.D. for the management of the bachelor thesis, valuable advice and comments. I would also like to thank the consultant from CYAN Research & Development s.r.o., Ing. Dominik Malčík, for useful advice, dedicated time and patience in consultations and application development. Also, I would like to thank my family and friends for their support throughout my studies and work on this thesis. ii Abstract The main goal of this bachelor thesis is to create a system for detection of websites with phishing and other malicious content with respect to Javascript interpretation. The program should be able to download and process thousands of domains and get positive results. The Ąrst step involves examining an overview of automated web testing tools to Ąnd an optimal tool which will be used in the main implementation. The thesis contains overview of technologies for website testing, their comparison, overview of malware methods on websites, implementation and evaluation of the system. iii Keywords Chrome, Javascript, link manipulation, malware, phishing, URL redi- rects, XSS, Yara iv Contents 1 Introduction 1 2 Overview of approaches to website testing 3 2.1 Manual testing ....................... -

Identifying Javascript Skimmers on High-Value Websites
Imperial College of Science, Technology and Medicine Department of Computing CO401 - Individual Project MEng Identifying JavaScript Skimmers on High-Value Websites Author: Supervisor: Thomas Bower Dr. Sergio Maffeis Second marker: Dr. Soteris Demetriou June 17, 2019 Identifying JavaScript Skimmers on High-Value Websites Thomas Bower Abstract JavaScript Skimmers are a new type of malware which operate by adding a small piece of code onto a legitimate website in order to exfiltrate private information such as credit card numbers to an attackers server, while also submitting the details to the legitimate site. They are impossible to detect just by looking at the web page since they operate entirely in the background of the normal page operation and display no obvious indicators to their presence. Skimmers entered the public eye in 2018 after a series of high-profile attacks on major retailers including British Airways, Newegg, and Ticketmaster, claiming the credit card details of hundreds of thousands of victims between them. To date, there has been little-to-no work towards preventing websites becoming infected with skimmers, and even less so for protecting consumers. In this document, we propose a novel and effective solution for protecting users from skimming attacks by blocking attempts to contact an attackers server with sensitive information, in the form of a Google Chrome web extension. Our extension takes a two-pronged approach, analysing both the dynamic behaviour of the script such as outgoing requests, as well as static analysis by way of a number of heuristic techniques on scripts loaded onto the page which may be indicative of a skimmer. -

Update DPIA Report Google Workspace for Education
Update DPIA report Google Workspace for Education 2 August 2021 By Sjoera Nas and Floor Terra, senior advisors Privacy Company 1 / 46 UPDATE DPIA REPORT GOOGLE WORKSPACE FOR EDUCATION | 2 August 2021 CONTENTS SUMMARY ........................................................................................................................ 3 INTRODUCTION ................................................................................................................ 6 OUTCOME OF NEGOTIATIONS 8 JULY 2021 ............................................................... 10 1.1. ROLE OF GOOGLE AS DATA PROCESSOR ...................................................................... 10 1.2. ROLE OF GOOGLE AS DATA CONTROLLER FOR ADDITIONAL SERVICES ................................ 11 1.3. ROLE OF GOOGLE AS INDEPENDENT DATA CONTROLLER ................................................. 12 1.4. COMPLIANCE WITH THE PRINCIPLE OF PURPOSE LIMITATION ............................................ 14 1.5. LEGAL GROUND OF CONSENT WITH REGARD TO MINORS ................................................. 14 1.6. LACK OF TRANSPARENCY ABOUT THE DIAGNOSTIC DATA ................................................ 15 1.7. RETENTION PERIODS OF PSEUDONYMISED PERSONAL DATA ............................................ 16 1.8. USE OF SUBPROCESSORS ........................................................................................ 18 1.9. FUNDAMENTAL RIGHT FOR DATA SUBJECTS TO ACCESS THEIR PERSONAL DATA .................... 18 1.10. RISKS OF TRANSFER OF PERSONAL DATA OUTSIDE -

Browser Security Guidance: Google Chrome
GOV.UK Guidance Browser Security Guidance: Google Chrome Published Contents 1. Usage scenario 2. Summary of browser security 3. How the browser can best satisfy the security recommendations 4. Network Architecture 5. Deployment process 6. Recommended configuration 7. Enterprise considerations This ALPHA guidance builds on the End User Devices Platform Security Guidance and is applicable to devices running Google Chrome Browser on a supported and well configured version of Windows. This guidance was tested on 64bit Windows 8.1 Enterprise edition running Chrome for Business versions 33 and 39. Chrome Browser can be run as a normal Windows desktop application or as a Windows app (Chrome calls this “Windows 8 mode”). This guidance is applicable to both modes of use. 1. Usage scenario Chrome Browser will be used to access a variety of web services including: accessing Intranet services hosted on an enterpriseprovided OFFICIAL network accessing enterprise cloud services sourced from the Digital Marketplace accessing other Internet services and web resource To support these scenarios, the following architectural choices are recommended: All data should be routed through a secure enterprise VPN to ensure the confidentiality and integrity of traffic intended for the enterprise Intranet All Internet data should be routed through an enterprisehosted proxy to benefit from enterprise protective monitoring and logging solutions Arbitrary thirdparty extension installation by users is not permitted in the browser. A list of allowed trusted apps and extensions can be configured in Group Policy 2. Summary of browser security This browser has been assessed against each of the 12 security recommendations, and that assessment is shown in the table below.