STT 64 Betrouwbaarheid Van Technische Systemen
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Change 3, FAA Order 7340.2A Contractions
U.S. DEPARTMENT OF TRANSPORTATION CHANGE FEDERAL AVIATION ADMINISTRATION 7340.2A CHG 3 SUBJ: CONTRACTIONS 1. PURPOSE. This change transmits revised pages to Order JO 7340.2A, Contractions. 2. DISTRIBUTION. This change is distributed to select offices in Washington and regional headquarters, the William J. Hughes Technical Center, and the Mike Monroney Aeronautical Center; to all air traffic field offices and field facilities; to all airway facilities field offices; to all international aviation field offices, airport district offices, and flight standards district offices; and to the interested aviation public. 3. EFFECTIVE DATE. July 29, 2010. 4. EXPLANATION OF CHANGES. Changes, additions, and modifications (CAM) are listed in the CAM section of this change. Changes within sections are indicated by a vertical bar. 5. DISPOSITION OF TRANSMITTAL. Retain this transmittal until superseded by a new basic order. 6. PAGE CONTROL CHART. See the page control chart attachment. Y[fa\.Uj-Koef p^/2, Nancy B. Kalinowski Vice President, System Operations Services Air Traffic Organization Date: k/^///V/<+///0 Distribution: ZAT-734, ZAT-464 Initiated by: AJR-0 Vice President, System Operations Services 7/29/10 JO 7340.2A CHG 3 PAGE CONTROL CHART REMOVE PAGES DATED INSERT PAGES DATED CAM−1−1 through CAM−1−2 . 4/8/10 CAM−1−1 through CAM−1−2 . 7/29/10 1−1−1 . 8/27/09 1−1−1 . 7/29/10 2−1−23 through 2−1−27 . 4/8/10 2−1−23 through 2−1−27 . 7/29/10 2−2−28 . 4/8/10 2−2−28 . 4/8/10 2−2−23 . -

Going Places
Bristow Group Inc. 2007 Annual Report Going Places Bristow Group Inc. 2000 W Sam Houston Pkwy S Suite 1700, Houston, Texas 77042 t 713.267.7600 f 713.267.7620 www.bristowgroup.com 2007 Annual Report BOARD OF DIRECTORS OFFICERS CORPORATE INFORMATION Thomas C. Knudson William E. Chiles Corporate Offi ces Chairman, Bristow Group Inc.; President, Chief Executive Offi cer Bristow Group Inc. Retired Senior Vice President of and Director 2000 W Sam Houston Pkwy S ConocoPhillips Suite 1700, Houston, Texas 77042 Perry L. Elders Telephone: 713.267.7600 Thomas N. Amonett Executive Vice President and Fax: 713.267.7620 President and CEO, Chief Financial Offi cer www.bristowgroup.com Champion Technologies, Inc. Richard D. Burman Common Stock Information Charles F. Bolden, Jr. Senior Vice President, The company’s NYSE symbol is BRS. Major General Charles F. Bolden Jr., Eastern Hemisphere U.S. Marine Corps (Retired); Investor Information CEO of JACKandPANTHER L.L.C. Michael R. Suldo Additional information on the company Senior Vice President, is available at our web site Peter N. Buckley Western Hemisphere www.bristowgroup.com Chairman, Caledonia Investments plc. Michael J. Simon Transfer Agent Senior Vice President, Mellon Investor Services LLC Stephen J. Cannon Production Management 480 Washington Boulevard Retired President, Jersey City, NJ 07310 DynCorp International, L.L.C. Patrick Corr www.melloninvestor.com Senior Vice President, Jonathan H. Cartwright Global Training Auditors Finance Director, KPMG LLP Our Values Caledonia Investments plc. Mark B. Duncan Senior Vice President, William E. Chiles Global Business Development President & Chief Executive Offi cer, Bristow’s values represent our core beliefs about how we conduct our business. -

LIST of REFERENCES ITW GSE 400 Hz Gpus AIRPORTS
Page 1 of 15 January 2017 LIST OF REFERENCES ITW GSE 400 Hz GPUs AIRPORTS Alger Airport Algeria 2005 Zvartnots Airport Armenia 2007 Brisbane Airport Australia 2013 Melbourne Airport Australia 2011-14 Perth Airport Australia 2011-12-13 Klagenfurt Airport Austria 1993 Vienna International Airport Austria 1995-2001-14-15 Bahrain International Airport Bahrain 2010-12 Minsk Airport Belarus 2014 Brussels International Airport Belgium 2001-02-08-15-16 Charleroi Airport Belgium 2006 Sofia Airport Bulgaria 2005 Air Burkina Burkina Faso 2004 Punta Arenas Chile 2001 Santiago Airport Chile 2011 Pointe Noitre Airport Congo Brazzaville 2009-10 Dubrovnik Airport Croatia 2014-16 La Habana Airport Cuba 2010 Larnaca Airport Cyprus 2008 Ostrava Airport Czech Republic 2010 Prague Airport Czech Republic 1996-97-2002-04-05-07-12-14-16 Aalborg Airport Denmark 1997-98-99-2012-15 Billund Airport Denmark 1999-2000-02-08-12-13-16 Copenhagen Airports Authorities Denmark 89-93-99-2000-01-03-07-09-10-11-12-13-14-15-16 Esbjerg Airport Denmark 2007-08-14 Hans Christian Andersen Airport (Odense) Denmark 1991-95-2015 Roenne Airport Denmark 1993 Karup Airport Denmark 1997-2016 Curacao Airport Dutch Antilles 2007 Cairo Intl. Airport Egypt 2015 Tallinn Airport Estonia 2004-05-14 Aéroport de Malabo Equatorial Guinea 2012 Vága Floghavn Faroe Islands 2015 Helsinki-Vantaa Airport Finland 1996-97-2000-05-06-09-10-13-14 Rovaniemi Airport Finland 2000 Turku Airport Finland 2014 Aéroport d’Aiglemont for Prince Aga Khan France 20007 Aéroport de Biarritz France 2009 Aéroport de Brest -

Flying As a Career Professional Pilot Training
SO YOU WANT TO BE A PILOT? 2009 Flying As A Career Professional Pilot Training Author Captain Ralph KOHN FRAeS GUILD OF AIR PILOTS ROYAL AERONAUTICAL AND NAVIGATORS SOCIETY A Guild of the City of London At the forefront of change Founded in 1929, the Guild is a Livery Company of the City of Founded in 1866 to further the science of aeronautics, the Royal London. It received its Letters Patent in 1956. Aeronautical Society has been at the forefront of developments in aerospace ever since. Today the Society performs three primary With as Patron His Royal Highness The Prince Philip, Duke of roles: Edinburgh, KG KT and as Grand Master His Royal Highness The • to support and maintain the highest standards for Prince Andrew, Duke of York, CVO ADC, the Guild is a charitable professionalism in all aerospace disciplines; organisation that is unique amongst City Livery Companies in • to provide a unique source of specialist information and a having active regional committees in Australia, Canada, Hong central forum for the exchange of ideas; Kong and New Zealand. • To exert influence in the interests of aerospace in both the public and industrial arenas. Main objectives • To establish and maintain the highest standards of air safety through the promotion of good airmanship among air pilots Benefits • Membership grades for professionals and enthusiasts alike and air navigators. • Over 17,000 members in more than 100 countries • To maintain a liaison with all authorities connected with licensing, training and legislation affecting pilot or navigator • An International network of 70 Branches whether private, professional, civil or military. -

Quality Military Satcom
Customer Story: Bristow Search and Rescue DIRECT COMMUNICATIONS & SUPPORT Bristow Search and Rescue ©2018 Flightcell International Ltd. 1 www.flightcell.com ©2018 Flightcell International Ltd. www.flightcell.com Customer Story: Bristow Search and Rescue BACKGROUND & REQUIREMENT Bristow Group is the leading provider of industrial aviation services offering helicopter transportation, search and rescue (SAR) and aircraft support services, including helicopter maintenance and training, to government and civil organizations worldwide. They have major operations in the North Sea, Nigeria, U.S. Gulf of Mexico and in most other major offshore oil and gas producing regions. Bristow Helicopters provides civilian SAR services in the United Kingdom. The area of operations ranges from Newquay in the South to Sumburgh in the far North. The fleet of brand new aircraft consists of Sikorsky S-92’s and AgustaWestland AW189’s. The communications requirements for their helicopters was threefold: i. To be capable of Beyond Line-of-Sight communications at all times. ii. To be continuously tracked by the the UK National Maritime Operations Centre (NMOC) and the Aeronautical Rescue Co-ordination Centre (ARCC). The units are very reliable “ iii. To initiate satellite voice communications from both the cockpit and cabin. and Flightcell provide “ outstanding support… ©2018 Flightcell International Ltd. 2 www.flightcell.com Customer Story: Bristow Search and Rescue SOLUTION Bristow selected the DZM product platform to do the job. The DZM was an attractive proposition; being an all-in-one box solution with user-friendly keypad on the front and minimal wiring requirements. Capabilities included both satellite and cellular voice/data and GPS tracking. -

Bristow Group Inc
THE BUSINESS OF DELIVERING Bristow Group Inc. 2000 W Sam Houston Pkwy S Suite 1700, Houston, Texas 77042 t 713.267.7600 f 713.267.7620 bristowgroup.com ANNUAL REPORT BOARD OF DIRECTORS OFFICERS CORPORATE INFORMATION Thomas C. Knudson William E. Chiles Corporate Offi ces Chairman, Bristow Group Inc.; President, Chief Executive Offi cer Bristow Group Inc. Retired Senior Vice President of and Director 2000 W Sam Houston Pkwy S ConocoPhillips Suite 1700, Houston, Texas 77042 Perry L. Elders Telephone: 713.267.7600 Thomas N. Amonett Executive Vice President and Fax: 713.267.7620 President and CEO, Chief Financial Offi cer bristowgroup.com Champion Technologies, Inc. Richard D. Burman Common Stock Information Charles F. Bolden, Jr. Senior Vice President, The company’s NYSE symbol is BRS. Major General Charles F. Bolden Jr., Eastern Hemisphere U.S. Marine Corps (Retired); Investor Information CEO of JACKandPANTHER L.L.C. Patrick Corr Additional information on the company Senior Vice President, is available at our web site Peter N. Buckley Global Safety, Training & Standards bristowgroup.com Chairman, Caledonia Investments plc. Mark B. Duncan Transfer Agent Senior Vice President, BNY Mellon Shareowner Services OUR Stephen J. Cannon Western Hemisphere 480 Washington Boulevard VALUES Retired President, Jersey City, NJ 07310 SAFETY: Safety fi rst! DynCorp International, L.L.C. Meera Sikka melloninvestor.com Vice President, QUALITY AND EXCELLENCE: Set and Jonathan H. Cartwright Global Business Development Auditors achieve high standards in everything we do. Finance Director, KPMG LLP INTEGRITY: Do the right thing. Caledonia Investments plc. Randall A. Stafford Vice President, FULFILLMENT: Develop our talents and William E. -

List of EU Air Carriers Holding an Active Operating Licence
Active Licenses Operating licences granted Member State: Austria Decision Name of air carrier Address of air carrier Permitted to carry Category (1) effective since ABC Bedarfsflug GmbH 6020 Innsbruck - Fürstenweg 176, Tyrolean Center passengers, cargo, mail B 16/04/2003 AFS Alpine Flightservice GmbH Wallenmahd 23, 6850 Dornbirn passengers, cargo, mail B 20/08/2015 Air Independence GmbH 5020 Salzburg, Airport, Innsbrucker Bundesstraße 95 passengers, cargo, mail A 22/01/2009 Airlink Luftverkehrsgesellschaft m.b.H. 5035 Salzburg-Flughafen - Innsbrucker Bundesstraße 95 passengers, cargo, mail A 31/03/2005 Alpenflug Gesellschaft m.b.H.& Co.KG. 5700 Zell am See passengers, cargo, mail B 14/08/2008 Altenrhein Luftfahrt GmbH Office Park 3, Top 312, 1300 Wien-Flughafen passengers, cargo, mail A 24/03/2011 Amira Air GmbH Wipplingerstraße 35/5. OG, 1010 Wien passengers, cargo, mail A 12/09/2019 Anisec Luftfahrt GmbH Office Park 1, Top B04, 1300 Wien Flughafen passengers, cargo, mail A 09/07/2018 ARA Flugrettung gemeinnützige GmbH 9020 Klagenfurt - Grete-Bittner-Straße 9 passengers, cargo, mail A 03/11/2005 ART Aviation Flugbetriebs GmbH Porzellangasse 7/Top 2, 1090 Wien passengers, cargo, mail A 14/11/2012 Austrian Airlines AG 1300 Wien-Flughafen - Office Park 2 passengers, cargo, mail A 10/09/2007 Disclaimer: The table reflects the data available in ACOL-database on 16/10/2020. The data is provided by the Member States. The Commission does not guarantee the accuracy or the completeness of the data included in this document nor does it accept responsibility for any use made thereof. 1 Active Licenses Decision Name of air carrier Address of air carrier Permitted to carry Category (1) effective since 5020 Salzburg-Flughafen - Innsbrucker Bundesstraße AVAG AIR GmbH für Luftfahrt passengers, cargo, mail B 02/11/2006 111 Avcon Jet AG Wohllebengasse 12-14, 1040 Wien passengers, cargo, mail A 03/04/2008 B.A.C.H. -

Wind Aviation Webinar - 29 April 2021 Helicopter Operations: Wind As a Customer of Aviation Services
Wind Aviation Webinar - 29 April 2021 Helicopter operations: Wind as a customer of aviation services First Name Last Name Job title Organisation Sue Allen Market Analyst 4C Offshore Jim Gilhooly Partner Achieving the Difference LLP Rafal Libera Group Integration Manager Acteon Group Robert Hoermann CEO Aero Enterprise GmbH Andy Evans Director Aerossurance Limited Steve Robertson Director Air & Sea Analytics Athena Scaperdas Consultant Engineer Air Ops Safety Antonio Martinez Customer Solution Competitiveness Airbus Helicopters Thierry Mauvais Segment Manager Offshore Wind Airbus Helicopters Arnaud Roux Operational Marketing Manager Airbus Helicopters Tim Williams Advisor Maritime Helicopters & UAV Airbus Helicopters Mislav Spajić Data scientist/UAV operator Airspect d.o.o. Stuart Dawson Development Manager Aker offshore wind Andrew Lang Marine Hose Specialist Allied Marine Logistics Ltd David Wilson Business Development Manager Allspeeds Limited Jay Medina Commercial Manager Associated British Ports Andrew Reay group head of commercial Offshore wind Associated British Ports Binh Le Graduate Engineer Atkins Anette Soderberg Named Accounts Sales Executive EMEA Autodesk Mark Marien US Director offshore HSE Avangrid Renewables Bobby Osahan Technical Director Aviation Consult Ronan McMahon Flight Operations Manager Babcock Mission Critical Services Ireland Ltd Ian Millhouse Structures Specialist Leader BAE Systems Spencer Tsao General Manager Bank of Taiwan London Branch Amy Townsend Senior Development Planner Banks Group Frazer Harrison Development -
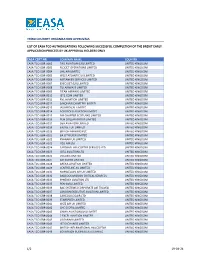
List of Tco Authorisations
THIRD COUNTRY ORGANISATION APPROVALS LIST OF EASA TCO AUTHORISATIONS FOLLOWING SUCCESSFUL COMPLETION OF THE BREXIT EARLY APPLICATION PROCESS BY UK APPROVAL HOLDERS ONLY EASA CERT NR COMPANY NAME COUNTRY EASA.TCO.GBR-0002 TAG AVIATION (UK) LIMITED UNITED KINGDOM EASA.TCO.GBR-0003 FLEXJET OPERATIONS LIMITED UNITED KINGDOM EASA.TCO.GBR-0004 DHL AIR LIMITED UNITED KINGDOM EASA.TCO.GBR-0005 WEST ATLANTIC UK LIMITED UNITED KINGDOM EASA.TCO.GBR-0006 AIRTANKER SERVICES LIMITED UNITED KINGDOM EASA.TCO.GBR-0007 EXECUJET (UK) LIMITED UNITED KINGDOM EASA.TCO.GBR-0008 TUI AIRWAYS LIMITED UNITED KINGDOM EASA.TCO.GBR-0009 TITAN AIRWAYS LIMITED UNITED KINGDOM EASA.TCO.GBR-0010 JET2.COM LIMITED UNITED KINGDOM EASA.TCO.GBR-0011 RVL AVIATION LIMITED UNITED KINGDOM EASA.TCO.GBR-0012 SAXONAIR CHARTER LIMITED UNITED KINGDOM EASA.TCO.GBR-0013 IAS MEDICAL LIMITED UNITED KINGDOM EASA.TCO.GBR-0014 ACROPOLIS AVIATION LIMITED UNITED KINGDOM EASA.TCO.GBR-0015 AIR CHARTER SCOTLAND LIMITED UNITED KINGDOM EASA.TCO.GBR-0016 PLM DOLLAR GROUP LIMITED UNITED KINGDOM EASA.TCO.GBR-0017 DEA AVIATION LIMITED UNITED KINGDOM EASA.TCO.GBR-0018 EASYJET UK LIMITED UNITED KINGDOM EASA.TCO.GBR-0019 BRITISH AIRWAYS PLC UNITED KINGDOM EASA.TCO.GBR-0020 BA CITYFLYER LIMITED UNITED KINGDOM EASA.TCO.GBR-0022 RYANAIR UK LIMITED UNITED KINGDOM EASA.TCO.GBR-0023 HELI AIR Ltd. UNITED KINGDOM EASA.TCO.GBR-0024 CARDINAL HELICOPTER SERVICES LTD UNITED KINGDOM EASA.TCO.GBR-0025 JOTA AVIATION LTD UNITED KINGDOM EASA.TCO.GBR-0026 VOLUXIS LIMITED UNITED KINGDOM EASA.TCO.GBR-0027 AIR KILROE LIMITED UNITED KINGDOM EASA.TCO.GBR-0028 ARENA AVIATION LIMITED UNITED KINGDOM EASA.TCO.GBR-0029 CENTRELINE AV LIMITED UNITED KINGDOM EASA.TCO.GBR-0031 NORWEGIAN AIR UK LIMITED UNITED KINGDOM EASA.TCO.GBR-0032 BABCOCK MISSION CRITICAL SERVICES UNITED KINGDOM EASA.TCO.GBR-0033 SYNERGY AVIATION LTD UNITED KINGDOM EASA.TCO.GBR-0035 PEN-AVIA LIMITED UNITED KINGDOM EASA.TCO.GBR-0036 BAE SYSTEMS (CORPORATE AIR TRAVEL) UNITED KINGDOM EASA.TCO.GBR-0037 LONDON EXECUTIVE AVIATION LIMITED UNITED KINGDOM EASA.TCO.GBR-0038 CARGOLOGICAIR LTD. -

UK Search and Rescue Helicopters Post-Implementation Review Capping Report QINETIQ/19/00408 Prepared March 2019
UK Search and Rescue Helicopters Post-Implementation Review Capping Report QINETIQ/19/00408 Prepared March 2019 MCA(Photo Capping courtesy Paper of MCA)1 Executive Summary The UK Search and Rescue Helicopter (UKSARH) implementation represented a complex transformation of the UK’s aviation-based Search and Rescue (SAR) capability, introducing a number of major changes in the way the service was provided. QinetiQ conducted a comprehensive Post-Implementation Review (PIR) on behalf of the Maritime & Coastguard Agency (MCA) to assess the effectiveness and performance of the transition to, and delivery of, the current UKSARH contract. Key Findings The PIR found that the UKSARH Programme has achieved a successful transition to a fully civilianised, rationalised operation with enhanced capability, while providing a seamless SAR service to the UK. The UKSARH contract is an effective mechanism for delivery of the SAR Helicopter (SARH) capability, providing continuity of service, allowing MCA to both manage risks and prevent significant financial exposure. The PIR found that realisation of all 10 benefits identified in the UKSARH Benefits Realisation Plan1 is in progress, with five already being achieved in full. In addition, the overarching benefits of saving lives and replacing the aging fleet of Sea King aircraft, identified in the Business Case2, were also assessed as being fully achieved. A number of additional unanticipated benefits were identified by the review, with UKSARH capability providing effective and essential augmentation to the -

ANNUAL REPORT PURSUANT to SECTIONS 13 OR 15(D) of the SECURITIES EXCHANGE ACT of 1934 (Mark One)
UNITED STATES SECURITIES AND EXCHANGE COMMISSION WASHINGTON, DC 20549 ________________________________________ FORM 10-K ________________________________________ ANNUAL REPORT PURSUANT TO SECTIONS 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 (Mark One) ☑ ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the fiscal year ended March 31, 2021 OR ☐ TRANSITION REPORT PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934 For the transition period from to Commission File Number 001-35701 Bristow Group Inc. (Exact name of registrant as specified in its charter) Delaware 72-1455213 (State or Other Jurisdiction of (IRS Employer Incorporation or Organization) Identification No.) 3151 Briarpark Drive, Suite 700 Houston, Texas 77042 (Address of Principal Executive Offices) (Zip Code) Registrant’s telephone number, including area code: (713) 267-7600 None (Former name, former address and former fiscal year, if changed since last report) Securities registered pursuant to Section 12(b) of the Act: Title of each class Trading Symbol(s) Name of each exchange on which registered Common Stock, par value $0.01 per share VTOL NYSE Indicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act. ¨ Yes ý No Indicate by check mark whether the registrant: (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for such shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days. -

Powerpoint Template for Global
UK Search and Rescue Overview and Capability Capt Clark Broad – UK SAR Flight Operations Manager Why are we here? 2 Why are we here? 3 Military to Civilian SAR 11 Bristow UK Search and Rescue • Bristow Helicopters History • Bristow Group SAR History • 2013 – UK SAR Award • Current Global SAR Footprint • UK SAR Overview • UK SAR Base • Sikorsky S92A • Agusta Westland 139/189 • Medical Capability • Initiatives and The Future 5 Bristow Helicopters - History • 1953 – Established by Alan Bristow using Whirlwind Helicopters • 1957 – Seismic contract in Bolivia • 1961 – Commenced flying training for the Royal Navy • 1963 – Commence flying training for the Army • 1965 – 1st UK offshore revenue Oil and Gas flight. • 1968 – Aberdeen base opens • 1970 – First flight with S-61N • 1971 – First HM Coastguard Operation Manston • 1983 – HM Coastguard Operation Sumburgh • 1984 – First flight with Aerospatiale SA330J Puma • 1996 – Merged with Offshore Logistics • 2012 – Gap SAR Award • 2013 – UK SAR Award 6 Bristow Group SAR History Global leader with over 5 decades of experience in Search and Rescue UK 1971 – HM Coastguard Shell/BP North Sea 1974 – 1989 UK 1983 – 2007 – HM Coastguard SAR Government Contract (four bases) Faroe Islands 2001 – Oil & Gas SAR BP North Sea SAR Trial 2003 Netherlands 2003 – Oil & Gas SAR with support to 7 NL Sqdn Solomon Islands 2006 7 Bristow Group Current Global SAR Footprint Global leader with Search and Rescue contracts until 2027 Norway – Oil & Gas SAR with support to 330 Squadron Trinidad – Air Guard & Oil & Gas