Base De Datos Como En Un Motor De Búsqueda? Datamatch Enterprise™ Server + API De Data Ladder, Encuentra Los Datos Correctos, Incluso Con Información Incompleta
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cloud Accounting for Your Business
Making life easier, saving you time and money. CLOUD ACCOUNTING FOR YOUR BUSINESS What is cloud accounting? Collaboration: Provides your accountant with visibility of Cloud accounting is the term given to the storage and your accounts throughout the year, not just at year-end. processing of your data on servers, or ‘in the cloud’. This This ensures improved data accuracy, eliminates delays technology allows business owners to access their business at key compliance times, and helps us to provide timely financials from anywhere or on any device. It is specifically financial advice to you. designed for the mobile 24/7 world that we now live in. Moving to the cloud is simple and pain free At RSM we’re always looking for ways to save you time and We simplify the migration process from traditional to cloud money in your business. One of the greatest opportunities accounting. available to businesses today is to take advantage of the power of the cloud. Choose your platform - MYOB, XERO, QuickBooks Online, Saasu, Reckon & others we’ll help you choose the Why switch to cloud accounting software? most suitable platform. We know them all. Total agility: A modern business needs information that is real time and always up to date. How else can you Moving made easy - We make your existing data cloud make effective business decisions? Now you can access ready. Say goodbye to that clunky crashing accounts your live accounting data from anywhere, from any computer and messy folders. device with an internet connection. Automate everything - We train the system to suit you, Saving you money: Business owners are regularly on not the other way around. -

The Complete Guide to Reckon One Discover Why Our Online Accounting Software Is the Perfect Fit for Your Business
The complete guide to Reckon One Discover why our online accounting software is the perfect fit for your business. ISSUE 04 | JANUARY 2019 2 The story so far Four years ago we asked ourselves what was missing in the online accounting market. The race to the cloud was full steam ahead back then, with early By the time you finish reading these pages I hope you will agree pioneers rushing forward to stake their claim. But we knew that just that we have once more moved the needle of innovation forward, ‘getting into the cloud’ was not going to be enough for us. making it easier for small businesses to succeed than ever before. Onward we go. So we set a new course. We wanted to create something superior that would better the lives of millions of small businesses everywhere. Over the following years, supported by our clever team of Reckon dreamers and the thousands of loyal customers who believed in us, Clive Rabie our ambitious goals never seemed out of reach. Reckon’s MD | Cloud accounting frontiersman Housekeeping For live product tours, and any questions from reviewers: [email protected] Our website: reckon.com/au/one All that’s left is to thank you for taking the time to review Reckon One, to note that all prices are in Australian dollars, and that all competitor information was sourced from their respective websites on 24 April 2017. Right, let’s get to the action! 3 Contents Part two Walkthrough > Dashboard pg 19 > Settings pg 21 Part one Overview > Banking pg 22 > Reporting pg 23 > High level snapshot! pg 5 > Invoicing and bills pg 25 > Why we’re superior pg 6 > Track time, claim expenses pg 26 > Small business pain points pg 7 > Payroll pg 27 > Our solution pg 8 > Projects and job management pg 28 > Price advantage > Mobile app pg 29 > Simplicity advantage > Support advantage > Links and resources pg 31 > Reckon’s story pg 16 > Our partners pg 32 PART ONE Overview 5 High level snapshot! A better fit Unlimited, simultaneous users Share with an expert Uniquely engineered to remove unnecessary Invite your whole team at no extra cost. -

Codat's Guide to the Accounting Software Market July 2020 How Is the Accounting Market Changing and What Does This Mean?
Codat's guide to the accounting software market July 2020 How is the accounting market changing and what does this mean? Across the world there are certainly dominant players within the accounting software market. However the market is rapidly changing and expanding. Key players are diversifying and fragmenting their offering to suit the ever changing needs of their key audience - the small business. A long tail of other accounting packages has emerged, spurred on by a huge shift in demand from desktop based packages to cloud based services which has largely been attributed to changing consumer expectations and regulation that has driven accounting and tax online. The expansion of cloud services has opened the door to more accessible and cost-saving software packages that include more automated features meaning that individuals with little to no accounting experience could navigate them. The cloud also allows for more centralised data which freely flows through APIs and integrations across platforms leading to greater insights and analysis that can be vital for a small business to survive and flourish. The accounting software market has transformed into a highly competitive, digitized and interconnected landscape which is largely driven with one customer in mind - the small business. *All data contained within this paper is based on extensive research carried out by Codat from various different sources, including both public and non-public sources. Some data has been calculated based on global figures and split across regions according to presence in the region. All data has been provided on a best-efforts basis, however Codat cannot guarantee the accuracy or completeness of this information. -
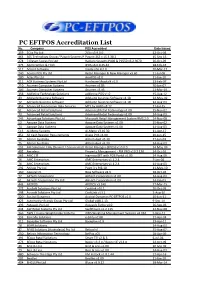
PC EFTPOS Accreditation List No
PC EFTPOS Accreditation List No. Company POS Accredited Date Issued 159 2Clix Pty Ltd 2Clix v3.9.0.0. 12-Oct-04 463 365 Technology Group / Pawnit Systems PtyPawnit Ltd 365 v 15.3.30.2 15-Sep-15 274 7-Eleven Stores Pty Ltd Radiant Systems P400 & P1550 v6.2.9070 26-Oct-09 375 Abercrombie & Fitch IPOS v6.0.0.25.42 18-Feb-13 511 Accent Software Insyte v16.4.2.0 20-Mar-17 240 Access POS Pty Ltd Retail Manager & New Manager v3.60 21-Jul-08 280 Aclas Pty Ltd ArmPOS v2.0 11-Jan-10 211 ACR Business Systems Pty Ltd Hardware Shoptalk v1.0 13-Feb-07 210 Acumen Computer Systems Acumen v3.85 10-Jan-07 289 Acumen Computer Systems Acumen v3.95 23-Mar-10 356 Addictive Technology Solutions addictive POS v1.0 15-Aug-12 43 Adelaide Business Software Adelaide business Software v1.18 22-May-02 72 Adelaide Business Software Adelaide business Software v1.18 14-Aug-03 456 Advanced Automotive Data Services MTS by AADS v8.12 21-Jul-15 51 Advanced Retail Solutions Advanced Retail Technology v1.00 15-Nov-02 73 Advanced Retail Solutions Advanced Retail Technology v1.00 14-Aug-03 245 Advantage Solutions Pty Ltd Microsoft Retail Management System RMS 2.0 24-Nov-08 52 Agopae Data Systems Agopae Data Systems v1.00 15-Nov-02 74 Agopae Data Systems Agopae Data Systems v1.00 14-Aug-03 513 Ai-Menu Systems Ai-Menu v3.10.30 11-Apr-17 451 All Cash Register Requirements Grace POS v3.00 10-Jun-15 70 Allcom Australia Allcom Aust v5.30 17-Jun-03 75 Allcom Australia Allcom Aust v5.30 14-Aug-03 253 AM Solutions / My Chemist / Corum HealthRetail Manager (EPOS) v1.0.0.0 14-May-09 492 -

Public Version 1 Myob/Reckon Accountants Group Letter
PUBLIC VERSION MYOB/RECKON ACCOUNTANTS GROUP LETTER OF ISSUES 1. Introduction 1.1 This document sets out the response of MYOB and Reckon to the Commerce Commission’s (NZCC ’s) Letter of Issues ( LOI ) in relation to the proposed acquisition by MYOB Group Limited (MYOB ) of the Accountants Group of Reckon Limited ( Reckon ) ( Proposed Transaction ). 1.2 The NZCC’s focus is whether the Proposed Transaction may give MYOB the incentive and ability to raise prices to medium to large accounting firms and a sub-set of accounting firms that do not consider cloud-based accounting software to be a viable alternative. As part of this assessment, the NZCC is considering whether MYOB may be able to price discriminate between different accounting firms. 1.3 For the reasons set out below, there is strong evidence that MYOB will not have the incentive or ability to raise prices to any customer or sub-set of customers post-merger, and will not do so. 2. Executive Summary 2.1 The effects of the Proposed Transaction must be assessed against a likely counterfactual. To this end, there is no prospect whatsoever that Reckon will move its APS suite to the cloud. As [REDACTED] , and it has stated (as a listed company), it simply does not have the resources (nor the time) to do this. As a result, its constraint on the market will decline. Indeed, it is already declining, as evidenced by [REDACTED] . 2.2 As to the relevant markets: (a) the evidence reveals that the compliance software requirements (i.e. client accounting and tax) are the same for all firms. -

Social Capital in Action: from Nought to Xero MMIM590
Social Capital in Action: From Nought to Xero MMIM590 by Karen McKeefry 300065582 Supervisor: Professor Pak Yoong Submitted to the School of Information Management Victoria University of Wellington In partial fulfilment of the requirements for the degree of Master of Information Management 16 October 2009 Abstract Typically internet start-ups (e-ventures) are innovative, independent, original companies that focus on information as their competitive factor. They are characterised by enormous growth potential, giving rise to technical and market risk. Resourcing these ventures can be daunting usually requiring significant financial and human capital and once the venture is formed they are subject to a liability of newness with no track record, legitimacy or endorsement for the product/service. Whilst entrepreneurs bring their own resources and skills to the business it is necessary to seek additional complementary resources through sustainable exchange relationships to ensure the ventures success. This report has used a case study of a New Zealand e-venture to provide qualitative evidence of how resources were secured to start and initially grow the business. Using Napahiet and Ghoshal’s (1998) three dimensional model of social capital it has analysed the evidence against scholarly theory to determine how social capital assisted the founders and the company to fulfil resource requirements and overcome the liability of newness. Napahiet and Ghoshal define social capital as “the sum of the actual and potential resources embedded within, available through, and derived from the network of relationships possessed by individuals or social unit” (p.243). The report found that the high level of social capital the founders brought to the venture assisted in gaining quick access to finances, skilled staff, competitive information and potential customers. -

Cloud Accounting Software Demo Files Instruction Booklet
Bringing the Cloud to Ground Level Cloud Accounting Software Demo Files Instruction Booklet MYOB, Xero, Reckon, Intuit Quickbooks and Phoenix by AgData. Bringing the Cloud to Ground Level Now that the NBN (National Broadband Network) is a reality in regional communities across Australia, more businesses finally have the internet quality to use cloud accounting. Some people find this very daunting, while others can’t wait to embrace the new technology and systems. Our goal is to take away some of the mystery. In simple terms, using “the Cloud” means storing and accessing data and programs over the Internet, instead of your computer’s hard drive. One thing is for sure, desktop software is out and cloud software is in… but there’s more to it than being able to ‘do your bookwork’ while sitting on the beach. Some of the business advantages include real time financial information from direct bank feeds, on-the-go invoicing, better communication with your accountant and advisers, and the ability to view your accounting files from anywhere in the world. It means saying goodbye to memory sticks and emailing files. It also allows you to integrate other processes like payroll systems, stock control, invoicing and farm management. Despite what you might think, you don’t have to be a technical guru to use cloud products. Even businesses who are quite traditional in their bookkeeping, using paper reporting, can switch to a cloud based-product and experience the ease of use and lifestyle benefits. There is no one-size-fits-all approach. In June 2017, BMO hosted a regional Queensland first – free accounting software expo where all the big players including Xero, MYOB, Intuit Quickbooks Online, Phoenix by AgData and Reckon all offered demonstrations and one-on-one sessions to help people better appreciate the different packages on offer and how they work. -

Reckon Limited (ACN 003 348 730)
ASX Announcement Reckon Limited (ACN 003 348 730) 6 July 2017 • DECLARATION OF DIVIDEND IN SPECIE • DE-MERGER OF DMS BUSINESS • AIM IPO OF THE DOCUMENT MANAGEMENT BUSINESS • PRO RATA RIGHTS ISSUE On 17 March 2017 and 30 June 2017, Reckon Limited (Reckon) announced that it proposed to de-merge its Document Management Business (DMS Business) into an independent company with shares admitted to trading on the AIM market of the London Stock Exchange. The AIM quoted entity will be called GetBusy Plc (GetBusy). The board of directors of Reckon are now pleased to update shareholders on the progress of the de-merger and its associated transactions. DIVIDEND IN SPECIE The board announces today that it has declared a dividend of an estimated A$26 million from retained earnings, based on the expected net asset value of the DMS business at the time of the de-merger. The dividend will be satisfied by an in specie distribution of shares in GetBusy to Reckon shareholders on a one for three basis. For personal use only The in specie distribution is conditional upon, and will take effect from, the admission of GetBusy to AIM, which is expected to occur – with a high level of confidence - on or around 8.00 BST on 4 August 2017. The record time and date for the in-specie distribution will be 7.00 pm AEST on 12 July 2017. Reckon shareholders so recorded in the share register will be entitled to participate in the in- specie distribution, subject to the below condition. Reckon shareholders do not need to do anything or to pay anything for the GetBusy shares that they will receive. -

Accountex 2016 on Verge of Selling Out
Accountex 2016 on verge of selling out Accountex – The National Accountancy Exhibition & Conference, taking place at ExCeL London next month, on 11-12 May, is set to sell out to exhibitors within the next few days for the fifth year in a row. If a trade show is an indication of the health of an industry, then the Accountancy profession is in great shape. The event attracted over 5,000 accountants and finance professionals in 2015, and sold out weeks before the doors opened. Subsequent demand for 2016 led the organisers to expand the floorplan by a further 20%. This too is now on the verge of selling out, with five weeks still to go. Microsoft UK, SAGE UK, Exact, Thomson Reuters, Taxcalc, Intuit QuickBooks, Xero, Tolley, Aviva, Reckon UK, DocuSoft, ACCA, Wolters Kluwer, FreeAgent, Expensify, Catax Solutions, Abbey Tax and Consultancy Services, and CIMA are among the 200 exhibitors keen to showcase their hottest new products and services to the profession at the 2016 event; which will host over 185 CPD accredited seminars, panel sessions, interactive workshops, and unrivalled networking opportunities. Accountex event director Tom King, said: "The accounting profession is one of the fastest changing industries in the UK and, having worked within this market for nearly five years, I can say that there has never been so much opportunity to work with accountants and their clients. “Cloud technology has brought with it a new way for Accountants to work; more demanding clients, who expect more for less and in less time than ever before. Accountex has been working with thought leaders to support and assist the profession during these changes. -

MIC 0091 Dynamics Mag.Indd
Find out how your business can benefi t from… Dynamic Solutions Then it’s time to think My budget dynamically is the tightest it’s ever been ERP - Financial, Manufacturing & Supply Chain Management MAKE THEM CRM - Customer Relationship Management } WORK FOR YOU Business Software for today and tomorrow. Software to help your business evolve. How can Microsoft Here. save you money? There. I reckon I can read your mind. In this time of economic instability and uncertainty, it’s not that hard to do. Everywhere. As a business leader, you are no doubt thinking about ways to save money and improve performance. A little fi scal probity coupled with an increase in productivity will ensure you ride out tough times and emerge as a stronger, more robust and successful business. It’s the right and prudent thing to do. We’re on the same page. Focus on what you can control lest you get distracted by what you can’t. Manage risk. Control cost. Diversify opportunity. Innovate. Calendar The point of this publication is to show you where Microsoft business software fi ts into that equation – and how Microsoft Dynamics® can help to not only save you money, but Aug 14, 2008 S M T W ThTh F S drive a productivity step-change. 10 Flight 185 to WLG It’s the common thread tying everything together that’s written on the following pages. 11 Microsoft Dynamics is what we at Microsoft call our software products for businesses that depend on the effi cient management of fi nancial, supply chain information or customer 12 Taxi to City Excel Mobile information to turn a dollar. -
Features & Benefits
online Features & Benefits QuickBooks, hosted by Reckon Online, incorporates all the core functionality you expect with the ability to access your company data file anywhere, anytime over the internet, providing greater convenience, improved efficiency and productivity. Work anywhere, any time Now you can enjoy the convenience of being able to access your company data from anywhere in the world, at any time, just as if you were sitting in the office. Work online or offline Work on your company file online, or when internet access is not available, offline on a local QuickBooks desktop installation*. *Must also purchase a QuickBooks Enterprise 1 user version to work on a desktop application. Share data Allow many more users than most conventional accounting to work on a company file at the same time*. *Only 1 licence included. Additional licence required for each user. Easy access for Accountants and Bookkeepers It’s now easy for your accountant or bookkeeper to remotely log-in and work on your file simultaneously with you (with your permission), helping to ensure your company data is always accurate and up to date. ‘Always on’ audit trail QuickBooks, hosted by Reckon Online makes it easier for your accountant to spot possible trouble spots or mis-postings in your accounts. Advanced inventory management Easily enter, track and reconcile your inventory movements and costs, including in different units of measure where required. Plus track expenses, inventory and component levels for assembled products. Comprehensive payroll management* Easily perform payroll tasks, view previous payroll transactions, enter time, create and schedule payments, email pay slips to employees, and even split pay into multiple bank accounts. -

Receipt and Invoice Processing Software
FEATURES Pricing Bronze 50 credits - £9p/m 4000 invoices - £25 per Free with Xero or unlimited 60 credits - £26 Free with QuickBooks Streamline - Unlisted Transaction Pricing 18p credit month paid annually use $20 p/m 43p credit unlimited use Silver 100 credits - 8000 invoices - £50 per 280 credits - £90 £17p/m 17p credit month paid annually 33p credit Optimise - Unlisted Gold 200 credits - 16000 invoices - £100 per 1150 credits - £295 £32p/m 16p credit month paid annually 26p credit Platinum 500 credits - 24000 invoices - £150 per 5300 credits - £1,150 £75p/m 15p credit month paid annually 22p credit Transactions 1 credit 1 credit Transactions with line items 2 credits No additional cost No additional cost Additional cost Bank statements 3 credits per page N/A No additional cost N/A Additional cost Data Extraction Type Receipts Billls Credit notes Supplier statements PO Email in only Sales Invoices Bank statements Data Submission Methods Mobile App iOS/Android iOS/Android iOS/Android iOS/Android iOS/Android iOS/Android Upload Supplier portal upload Email Bank statement fetching Not in UK Supplier fetching Single page doc Multi page doc Multi item doc (ie. PDF) Specifiy exact page Exact split according Split per page Split per page to invoice number splits within app FEATURES General features Choose accounts to make available for selection Multi-currency Supplier statement reconciliation Purchases approval-levels Expenses e-approval Expenses approval-levels Duplicate detection (items in app) Duplicate check (items in Accounting integration)