Directory Management
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alias Manager 4
CHAPTER 4 Alias Manager 4 This chapter describes how your application can use the Alias Manager to establish and resolve alias records, which are data structures that describe file system objects (that is, files, directories, and volumes). You create an alias record to take a “fingerprint” of a file system object, usually a file, that you might need to locate again later. You can store the alias record, instead of a file system specification, and then let the Alias Manager find the file again when it’s needed. The Alias Manager contains algorithms for locating files that have been moved, renamed, copied, or restored from backup. Note The Alias Manager lets you manage alias records. It does not directly manipulate Finder aliases, which the user creates and manages through the Finder. The chapter “Finder Interface” in Inside Macintosh: Macintosh Toolbox Essentials describes Finder aliases and ways to accommodate them in your application. ◆ The Alias Manager is available only in system software version 7.0 or later. Use the Gestalt function, described in the chapter “Gestalt Manager” of Inside Macintosh: Operating System Utilities, to determine whether the Alias Manager is present. Read this chapter if you want your application to create and resolve alias records. You might store an alias record, for example, to identify a customized dictionary from within a word-processing document. When the user runs a spelling checker on the document, your application can ask the Alias Manager to resolve the record to find the correct dictionary. 4 To use this chapter, you should be familiar with the File Manager’s conventions for Alias Manager identifying files, directories, and volumes, as described in the chapter “Introduction to File Management” in this book. -

Answers to Even- Numbered Exercises 5
Answers to Even- Numbered Exercises 5 from page 163 1. What does the shell ordinarily do while a command is executing? What should you do if you do not want to wait for a command to finish before running another command? 2. Using sort as a filter, rewrite the following sequence of commands: $ sort list > temp $ lpr temp $ rm temp $ cat list | sort | lpr 3. What is a PID number? Why are they useful when you run processes in the background? 4. Assume that the following files are in the working directory: $ ls intro notesb ref2 section1 section3 section4b notesa ref1 ref3 section2 section4a sentrev Give commands for each of the following, using wildcards to express filenames with as few characters as possible. 1 2 Chapter 5 Answers to Exercises a. List all files that begin with section. $ ls section* b. List the section1, section2, and section3 files only. $ ls section[1-3] c. List the intro file only. $ ls i* d. List the section1, section3, ref1, and ref3 files. $ ls *[13] 5. Refer to the documentation of utilities in Part III or the man pages to determine what commands will a. Output the number of lines in the standard input that contain the word a or A. b. Output only the names of the files in the working directory that contain the pattern $(. c. List the files in the working directory in their reverse alphabetical order. d. Send a list of files in the working directory to the printer, sorted by size. 6. Give a command to a. Redirect the standard output from a sort command into a file named phone_list. -

Efficient Metadata Management in Cloud Computing
Send Orders for Reprints to [email protected] The Open Cybernetics & Systemics Journal, 2015, 9, 1485-1489 1485 Open Access Efficient Metadata Management in Cloud Computing Yu Shuchun1,* and Huang Bin2 1Deptment of Computer Engineering, Huaihua University, Huaihua, Hunan, 418008, P.R. China; 2School of Mathmatic and Computer Science, Guizhou Normal University, Guiyang, Guizhou, 550001, P.R. China Abstract: Existing metadata management methods bring about lower access efficiency in solving the problem of renam- ing directory. This paper proposes a metadata management method based on directory path redirection (named as DPRD) which includes the data distribution method based on directory path and the directory renaming method based on directory path redirection. Experiments show that DPRD effectively solves the lower access efficiency caused by the renaming di- rectory. Keywords: Cloud computing, directory path, redirection, metadata. 1. INTRODUCTION renaming a directory. The directory path fixed numbering (marked as DPFN) [10, 11] endows the globally unique ID With the prevalence of Internet application and data- (DPID) for each directory path, and DPID remains un- intensive computing, there are many new application sys- changed in the life cycle of the directory path, and the meta- tems in cloud computing environment. These systems are data of all files (or sub-directories) in the directory path will mainly characterized by [1-3]: (1) The enormous files stored be placed and achieved according to its hash value of DPID. in the system, some even reach trillions level, and it still in- It can solve the metadata migration issue caused by directory crease rapidly; (2) The user number and daily access are renaming, but it uses a directory path index server to manage quire enormous, reaching billions level. -

Your Performance Task Summary Explanation
Lab Report: 11.2.5 Manage Files Your Performance Your Score: 0 of 3 (0%) Pass Status: Not Passed Elapsed Time: 6 seconds Required Score: 100% Task Summary Actions you were required to perform: In Compress the D:\Graphics folderHide Details Set the Compressed attribute Apply the changes to all folders and files In Hide the D:\Finances folder In Set Read-only on filesHide Details Set read-only on 2017report.xlsx Set read-only on 2018report.xlsx Do not set read-only for the 2019report.xlsx file Explanation In this lab, your task is to complete the following: Compress the D:\Graphics folder and all of its contents. Hide the D:\Finances folder. Make the following files Read-only: D:\Finances\2017report.xlsx D:\Finances\2018report.xlsx Complete this lab as follows: 1. Compress a folder as follows: a. From the taskbar, open File Explorer. b. Maximize the window for easier viewing. c. In the left pane, expand This PC. d. Select Data (D:). e. Right-click Graphics and select Properties. f. On the General tab, select Advanced. g. Select Compress contents to save disk space. h. Click OK. i. Click OK. j. Make sure Apply changes to this folder, subfolders and files is selected. k. Click OK. 2. Hide a folder as follows: a. Right-click Finances and select Properties. b. Select Hidden. c. Click OK. 3. Set files to Read-only as follows: a. Double-click Finances to view its contents. b. Right-click 2017report.xlsx and select Properties. c. Select Read-only. d. Click OK. e. -

The Linux Command Line
The Linux Command Line Fifth Internet Edition William Shotts A LinuxCommand.org Book Copyright ©2008-2019, William E. Shotts, Jr. This work is licensed under the Creative Commons Attribution-Noncommercial-No De- rivative Works 3.0 United States License. To view a copy of this license, visit the link above or send a letter to Creative Commons, PO Box 1866, Mountain View, CA 94042. A version of this book is also available in printed form, published by No Starch Press. Copies may be purchased wherever fine books are sold. No Starch Press also offers elec- tronic formats for popular e-readers. They can be reached at: https://www.nostarch.com. Linux® is the registered trademark of Linus Torvalds. All other trademarks belong to their respective owners. This book is part of the LinuxCommand.org project, a site for Linux education and advo- cacy devoted to helping users of legacy operating systems migrate into the future. You may contact the LinuxCommand.org project at http://linuxcommand.org. Release History Version Date Description 19.01A January 28, 2019 Fifth Internet Edition (Corrected TOC) 19.01 January 17, 2019 Fifth Internet Edition. 17.10 October 19, 2017 Fourth Internet Edition. 16.07 July 28, 2016 Third Internet Edition. 13.07 July 6, 2013 Second Internet Edition. 09.12 December 14, 2009 First Internet Edition. Table of Contents Introduction....................................................................................................xvi Why Use the Command Line?......................................................................................xvi -

Filesystem Hierarchy Standard
Filesystem Hierarchy Standard LSB Workgroup, The Linux Foundation Filesystem Hierarchy Standard LSB Workgroup, The Linux Foundation Version 3.0 Publication date March 19, 2015 Copyright © 2015 The Linux Foundation Copyright © 1994-2004 Daniel Quinlan Copyright © 2001-2004 Paul 'Rusty' Russell Copyright © 2003-2004 Christopher Yeoh Abstract This standard consists of a set of requirements and guidelines for file and directory placement under UNIX-like operating systems. The guidelines are intended to support interoperability of applications, system administration tools, development tools, and scripts as well as greater uniformity of documentation for these systems. All trademarks and copyrights are owned by their owners, unless specifically noted otherwise. Use of a term in this document should not be regarded as affecting the validity of any trademark or service mark. Permission is granted to make and distribute verbatim copies of this standard provided the copyright and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this standard under the conditions for verbatim copying, provided also that the title page is labeled as modified including a reference to the original standard, provided that information on retrieving the original standard is included, and provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this standard into another language, under the above conditions for modified versions, except that this permission notice may be stated in a translation approved by the copyright holder. Dedication This release is dedicated to the memory of Christopher Yeoh, a long-time friend and colleague, and one of the original editors of the FHS. -

File Systems
File Systems Profs. Bracy and Van Renesse based on slides by Prof. Sirer Storing Information • Applications could store information in the process address space • Why is this a bad idea? – Size is limited to size of virtual address space – The data is lost when the application terminates • Even when computer doesn’t crash! – Multiple process might want to access the same data File Systems • 3 criteria for long-term information storage: 1. Able to store very large amount of information 2. Information must survive the processes using it 3. Provide concurrent access to multiple processes • Solution: – Store information on disks in units called files – Files are persistent, only owner can delete it – Files are managed by the OS File Systems: How the OS manages files! File Naming • Motivation: Files abstract information stored on disk – You do not need to remember block, sector, … – We have human readable names • How does it work? – Process creates a file, and gives it a name • Other processes can access the file by that name – Naming conventions are OS dependent • Usually names as long as 255 characters is allowed • Windows names not case sensitive, UNIX family is File Extensions • Name divided into 2 parts: Name+Extension • On UNIX, extensions are not enforced by OS – Some applications might insist upon them • Think: .c, .h, .o, .s, etc. for C compiler • Windows attaches meaning to extensions – Tries to associate applications to file extensions File Access • Sequential access – read all bytes/records from the beginning – particularly convenient for magnetic tape • Random access – bytes/records read in any order – essential for database systems File Attributes • File-specific info maintained by the OS – File size, modification date, creation time, etc. -

Filesystem Hierarchy Standard
Filesystem Hierarchy Standard Filesystem Hierarchy Standard Group Edited by Rusty Russell Daniel Quinlan Filesystem Hierarchy Standard by Filesystem Hierarchy Standard Group Edited by Rusty Russell and Daniel Quinlan Published November 4 2003 Copyright © 1994-2003 Daniel Quinlan Copyright © 2001-2003 Paul ’Rusty’ Russell Copyright © 2003 Christopher Yeoh This standard consists of a set of requirements and guidelines for file and directory placement under UNIX-like operating systems. The guidelines are intended to support interoperability of applications, system administration tools, development tools, and scripts as well as greater uniformity of documentation for these systems. All trademarks and copyrights are owned by their owners, unless specifically noted otherwise. Use of a term in this document should not be regarded as affecting the validity of any trademark or service mark. Permission is granted to make and distribute verbatim copies of this standard provided the copyright and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this standard under the conditions for verbatim copying, provided also that the title page is labeled as modified including a reference to the original standard, provided that information on retrieving the original standard is included, and provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this standard into another language, under the above conditions for modified versions, except that this permission notice may be stated in a translation approved by the copyright holder. Table of Contents 1. Introduction........................................................................................................................................................1 1.1. -

File Systems
“runall” 2002/9/24 page 305 CHAPTER 10 File Systems 10.1 BASIC FUNCTIONS OF FILE MANAGEMENT 10.2 HIERARCHICAL MODEL OF A FILE SYSTEM 10.3 THE USER’S VIEW OF FILES 10.4 FILE DIRECTORIES 10.5 BASIC FILE SYSTEM 10.6 DEVICE ORGANIZATION METHODS 10.7 PRINCIPLES OF DISTRIBUTED FILE SYSTEMS 10.8 IMPLEMENTING DISTRIBUTED FILE SYSTEM Given that main memory is volatile, i.e., does not retain information when power is turned off, and is also limited in size, any computer system must be equipped with secondary memory on which the user and the system may keep information for indefinite periods of time. By far the most popular secondary memory devices are disks for random access purposes and magnetic tapes for sequential, archival storage. Since these devices are very complex to interact with, and, in multiuser systems are shared among different users, operating systems (OS) provide extensive services for managing data on secondary memory. These data are organized into files, which are collections of data elements grouped together for the purposes of access control, retrieval, and modification. A file system is the part of the operating system that is responsible for managing files and the resources on which these reside. Without a file system, efficient computing would essentially be impossible. This chapter discusses the organization of file systems and the tasks performed by the different components. The first part is concerned with general user and implementation aspects of file management emphasizing centralized systems; the last sections consider extensions and methods for distributed systems. 10.1 BASIC FUNCTIONS OF FILE MANAGEMENT The file system, in collaboration with the I/O system, has the following three basic functions: 1. -

A Brief Technical Introduction
Mac OS X A Brief Technical Introduction Leon Towns-von Stauber, Occam's Razor LISA Hit the Ground Running, December 2005 http://www.occam.com/osx/ X Contents Opening Remarks..............................3 What is Mac OS X?.............................5 A New Kind of UNIX.........................12 A Diferent Kind of UNIX..................15 Resources........................................39 X Opening Remarks 3 This is a technical introduction to Mac OS X, mainly targeted to experienced UNIX users for whom OS X is at least relatively new This presentation covers primarily Mac OS X 10.4.3 (Darwin 8.3), aka Tiger X Legal Notices 4 This presentation Copyright © 2003-2005 Leon Towns-von Stauber. All rights reserved. Trademark notices Apple®, Mac®, Macintosh®, Mac OS®, Finder™, Quartz™, Cocoa®, Carbon®, AppleScript®, Bonjour™, Panther™, Tiger™, and other terms are trademarks of Apple Computer. See <http://www.apple.com/legal/ appletmlist.html>. NeXT®, NeXTstep®, OpenStep®, and NetInfo® are trademarks of NeXT Software. See <http://www.apple.com/legal/nexttmlist.html>. Other trademarks are the property of their respective owners. X What Is It? 5 Answers Ancestry Operating System Products The Structure of Mac OS X X What Is It? Answers 6 It's an elephant I mean, it's like the elephant in the Chinese/Indian parable of the blind men, perceived as diferent things depending on the approach X What Is It? Answers 7 Inheritor of the Mac OS legacy Evolved GUI, Carbon (from Mac Toolbox), AppleScript, QuickTime, etc. The latest version of NeXTstep Mach, Quartz (from Display PostScript), Cocoa (from OpenStep), NetInfo, apps (Mail, Terminal, TextEdit, Preview, Interface Builder, Project Builder, etc.), bundles, faxing from Print panel, NetBoot, etc. -

CS 170 Section 003 HW4 – Fall 2013 Part I
CS 170 Section 003 HW4 – Fall 2013 Due: Tuesday, Oct. 8th 2013 by the beginning of class. Honor Code: Like all work for this class, the Emory Honor Code applies. You should do your own work on all problems, unless you are explicitly instructed otherwise. If you get stuck or have questions, ask your instructor or a TA for help. For EACH of the files you submit, be sure to put the appropriate honor code statement (as specified on the course syllabus) at the top of the file in comments. Preparation: This is your first programming assignment and you must learn to protect your computer files from illegal access by other students. To disallow other students from reading your homework programs, you must save your file(s) in a directory inside your cs170 directory. If you follow the below commands, your work will be protected. 1. Create a directory called hw4 directory inside your cs170 project directory to save your hw4 files. mkdir ~/cs170/hw4 2. You must use ~/cs170/hw4 directory as your current directory when editing any program files for hw4. Change your current directory to your newly created hw4 directory: cd ~/cs170/hw4 3. You can now run gedit to edit your programs: gedit yourProgramName.java & The name yourProgramName is the name of the Java program (and also the name of the class!). Part I: As we discussed in class, all data in a computer is represented in bits. We represent these bits with the symbols 0 or 1. All data stored in a computer is represented as bits: music, .doc files, your web browser application, videos, EVERYTHING. -
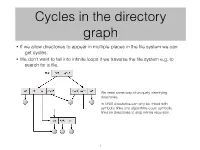
Cycles in the Directory Graph
Cycles in the directory graph • If we allow directories to appear in multiple places in the file system we can get cycles. • We don’t want to fall into infinite loops if we traverse the file system e.g. to search for a file. We need some way of uniquely identifying directories. In UNIX directories can only be linked with symbolic links and algorithms count symbolic links on directories to stop infinite recursion. 1 Deletion of linked files • With hard links we maintain a count of the number of links. This gets decremented each time one of the links gets deleted. When this finally reaches zero the actual file is deleted. • With symbolic links if a link is deleted we do nothing. If the real file is deleted … … we could have dangling pointers … or we could maintain a list of all linked files and go around and delete all of them. 2 So what is in a directory entry? • The file name – we scan the directory to see if the file exists within it. • We can have the file attributes stored in the directory entry. • At a minimum we need a pointer to the file attributes and location information. • UNIX keeps the file attributes and location information of each file in a separate structure – the inode (Information node or Index node). The inode also keeps a count of the number of hard links to the file. • The inode table is an array of inodes stored in one or more places on the disk. • So a UNIX directory isn’t much more than a table of names and corresponding inode numbers.