MIREX 2018 Submission: a Structural Chord Representation for Automatic Large-Vocabulary Chord Transcription
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

APPENDIX B Glossary
APPENDIX B Glossary 3-to-1 rule a recording strategy used to avoid phasing issues during stereo miking. The 3-to-1 rule states that the distance between the first and second microphones should be at least three times the distance between the first microphone and the sound source. 50/50 split a common type of contract agreement used in the music industry that equally divides royalties between the composer and publisher. 80:20 ratio a compositional guideline used in media scoring, assigning approximately 80% of the expression to the drama and emotional atmosphere of the scene, while the remaining 20% is used to define the region in which the scene takes place. A AAX shorthand for Avid Audio eXtension, this is a more recent plugin type used by Pro Tools software that is available in native and DSP formats. absorption a category of acoustic treatment that absorbs sound before it has the chance to reflect around the room, which can cause acoustic problems. accelerando a score marking that tells the performer(s) to gradually increase the speed of the music. accented passing tone an embellishment that is approached and left by step in the same direction and takes place in an accented metrical position. accent mark a notational symbol that tells the performer to emphasize a note with a sudden increase in volume. accidental a symbol used to alter the pitch of a note in a given direction without changing its letter, typically creating a chromatic alteration. 432 GLOSSARY accordatura a score marking indicating a cancellation of scordatura and return to standard tuning, usually in a score for stringed instruments. -

A. Types of Chords in Tonal Music
1 Kristen Masada and Razvan Bunescu: A Segmental CRF Model for Chord Recognition in Symbolic Music A. Types of Chords in Tonal Music minished triads most frequently contain a diminished A chord is a group of notes that form a cohesive har- seventh interval (9 half steps), producing a fully di- monic unit to the listener when sounding simulta- minished seventh chord, or a minor seventh interval, neously (Aldwell et al., 2011). We design our sys- creating a half-diminished seventh chord. tem to handle the following types of chords: triads, augmented 6th chords, suspended chords, and power A.2 Augmented 6th Chords chords. An augmented 6th chord is a type of chromatic chord defined by an augmented sixth interval between the A.1 Triads lowest and highest notes of the chord (Aldwell et al., A triad is the prototypical instance of a chord. It is 2011). The three most common types of augmented based on a root note, which forms the lowest note of a 6th chords are Italian, German, and French sixth chord in standard position. A third and a fifth are then chords, as shown in Figure 8 in the key of A minor. built on top of this root to create a three-note chord. In- In a minor scale, Italian sixth chords can be seen as verted triads also exist, where the third or fifth instead iv chords with a sharpened root, in the first inversion. appears as the lowest note. The chord labels used in Thus, they can be created by stacking the sixth, first, our system do not distinguish among inversions of the and sharpened fourth scale degrees. -

Harmonic Resources in 1980S Hard Rock and Heavy Metal Music
HARMONIC RESOURCES IN 1980S HARD ROCK AND HEAVY METAL MUSIC A thesis submitted to the College of the Arts of Kent State University in partial fulfillment of the requirements for the degree of Master of Arts in Music Theory by Erin M. Vaughn December, 2015 Thesis written by Erin M. Vaughn B.M., The University of Akron, 2003 M.A., Kent State University, 2015 Approved by ____________________________________________ Richard O. Devore, Thesis Advisor ____________________________________________ Ralph Lorenz, Director, School of Music _____________________________________________ John R. Crawford-Spinelli, Dean, College of the Arts ii Table of Contents LIST OF FIGURES ............................................................................................................................... v CHAPTER I........................................................................................................................................ 1 INTRODUCTION ........................................................................................................................... 1 GOALS AND METHODS ................................................................................................................ 3 REVIEW OF RELATED LITERATURE............................................................................................... 5 CHAPTER II..................................................................................................................................... 36 ANALYSIS OF “MASTER OF PUPPETS” ...................................................................................... -

Learn How to Play Power Guitar Chords with My Guitar Lessons. We
Learn How To Play Power Guitar Chords With My Guitar Lessons. We are going to be learning power chords. Power chords can be one of the guitarists best friends. They are used a lot in all kinds of rock, pop, metal and country music. First, we will learn how power chords are made and then we will learn how to play them. Once you have the shape for your power chords down we will apply them to a song. The formula for a power chord is root and 5th. With that in mind, let’s make a G power chord. The notes in the G major scale are G, A, B, C, D, E, and F#. If you want to make a G power chord just use the G note as the root and the 5th note in the G major scale for the 5th of the power chord. The 5th note of a G major scale is D so the two notes in a G power chord would be G and D. Now we will learn the shape for power chords. Let’s stick with a G power chord for now. Play the G note on the 3rd fret of the 6th string with your 1st finger. Now go up two frets and over one string to play the 5th fret of the 5th string with your 3rd finger. That is a D note. Now you have a G and a D. G is the root and D is the 5th. That fits the formula for a power chord. -

B.A.Western Music School of Music and Fine Arts
B.A.Western Music Curriculum and Syllabus (Based on Choice based Credit System) Effective from the Academic Year 2018-2019 School of Music and Fine Arts PROGRAM EDUCATIONAL OBJECTIVES (PEO) PEO1: Learn the fundamentals of the performance aspect of Western Classical Karnatic Music from the basics to an advanced level in a gradual manner. PEO2: Learn the theoretical concepts of Western Classical music simultaneously along with honing practical skill PEO3: Understand the historical evolution of Western Classical music through the various eras. PEO4: Develop an inquisitive mind to pursue further higher study and research in the field of Classical Art and publish research findings and innovations in seminars and journals. PEO5: Develop analytical, critical and innovative thinking skills, leadership qualities, and good attitude well prepared for lifelong learning and service to World Culture and Heritage. PROGRAM OUTCOME (PO) PO1: Understanding essentials of a performing art: Learning the rudiments of a Classical art and the various elements that go into the presentation of such an art. PO2: Developing theoretical knowledge: Learning the theory that goes behind the practice of a performing art supplements the learner to become a holistic practioner. PO3: Learning History and Culture: The contribution and patronage of various establishments, the background and evolution of Art. PO4: Allied Art forms: An overview of allied fields of art and exposure to World Music. PO5: Modern trends: Understanding the modern trends in Classical Arts and the contribution of revolutionaries of this century. PO6: Contribution to society: Applying knowledge learnt to teach students of future generations . PO7: Research and Further study: Encouraging further study and research into the field of Classical Art with focus on interdisciplinary study impacting society at large. -

THE 15 STEPS to CREATING Your Own Music on the Guitar INDEX
the BEGINNERS GUIDE TO GUITAR MASTERY THE 15 STEPS TO CREATING your own music on the guitar INDEX Page Number Contents 1 About this book and why we made it 2 Our philosophy and community 3 Guitar Construction 4 Strings and string names 5 Open position notes 6 Open chords 7 Strumming 8 Tablature and notation 9 Riffs 10 Barre chords 11 Power chords 12 Pentatonic scales 13 Arpeggios 14 Major scale formula 15 String effects 16 Octaves 17 Alternate tuning 18 What now? 19 About us ABOUT THIS BOOK Hey there reader, and guitar player! We have created this learning resource in an attempt to help people accelerate their journey of understanding the guitar, and inspire them to start creating their own music. A lot of people when wanting to start playing guitar will go straight to Youtube, learn ran- dom songs here and there, but the information you are consuming is really scattered and has no building of structure. This makes it harder for you to remember, much longer to improve, and when you don’t feel like you’re improving you’re going to lose motivation real quick. Think of this book as a blueprint of what you need to learn, and the order you should learn it in, so you can start wailing on the guitar and creating your own music as quickly as possible. WHY WE MADE IT We are committed to teaching people not only the technical aspects of playing this amazing instrument, but also to helping people understand, interpret, and celebrate this phenome- non we call music. -

Chord Names and Symbols (Popular Music) from Wikipedia, the Free Encyclopedia
Chord names and symbols (popular music) From Wikipedia, the free encyclopedia Various kinds of chord names and symbols are used in different contexts, to represent musical chords. In most genres of popular music, including jazz, pop, and rock, a chord name and the corresponding symbol are typically composed of one or more of the following parts: 1. The root note (e.g. C). CΔ7, or major seventh chord 2. The chord quality (e.g. major, maj, or M). on C Play . 3. The number of an interval (e.g. seventh, or 7), or less often its full name or symbol (e.g. major seventh, maj7, or M7). 4. The altered fifth (e.g. sharp five, or ♯5). 5. An additional interval number (e.g. add 13 or add13), in added tone chords. For instance, the name C augmented seventh, and the corresponding symbol Caug7, or C+7, are both composed of parts 1, 2, and 3. Except for the root, these parts do not refer to the notes which form the chord, but to the intervals they form with respect to the root. For instance, Caug7 indicates a chord formed by the notes C-E-G♯-B♭. The three parts of the symbol (C, aug, and 7) refer to the root C, the augmented (fifth) interval from C to G♯, and the (minor) seventh interval from C to B♭. A set of decoding rules is applied to deduce the missing information. Although they are used occasionally in classical music, these names and symbols are "universally used in jazz and popular music",[1] usually inside lead sheets, fake books, and chord charts, to specify the harmony of compositions. -
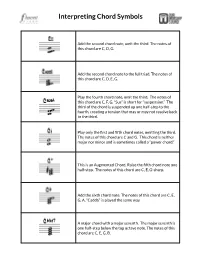
Interpreting Chord Symbols
Interpreting Chord Symbols Add the second chord note, omit the third. The notes of this chord are C, D, G. Add the second chord note to the full triad. The notes of this chord are C, D, E, G. Play the fourth chord note, omit the third. The notes of this chord are C, F, G. “Sus” is short for “suspension.” The third of the chord is suspended up one half-step to the fourth, creating a tension that may or may not resolve back to the third. Play only the first and fifth chord notes, omitting the third. The notes of this chord are C and G. This chord is neither major nor minor and is sometimes called a “power chord.” This is an Augmented Chord. Raise the fifth chord note one half-step. The notes of this chord are C, E, G-sharp. Add the sixth chord note. The notes of this chord are C, E, G, A. “Cadd6” is played the same way. A major chord with a major seventh. The major seventh is one half-step below the top octave note. The notes of this chord are C, E, G, B. Interpreting Chord Symbols, page 2 A major chord with a minor seventh. The minor seventh is two half-steps below the top octave note. The notes of this chord are C, E, G, B-flat. A minor chord with a minor seventh. The notes of this chord are C, E-flat, G, B-flat. The ninth means one note above the octave, which is the same note as the second chord note. -
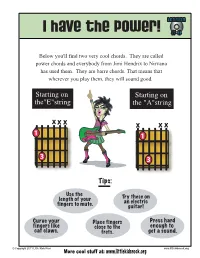
L Have the Power! #8
lesson l have the power! #8 Below you'll find two very cool chords. They are called power chords and everybody from Jimi Hendrix to Nirvana has used them. They are barre chords. That means that wherever you play them, they will sound good. Starting on Starting on the"E"string the "A"string x x x LKR x x x 1 1 3 3 Tips: Use the Try these on length of your an electric fingers to mute. guitar! Curve your Place fingers Press hard fingers like close to the enough to cat claws. frets. get a sound. ©2008 Little Kids Rock © Copyright 2011 Little Kids Rock www.littlekidsrock.org More cool stuff at: www.littlekidsrock.org lesson power chord progression #8 Power chord progressions are heard in many different styles of music including heavy metal, rock, rap and punk. The cool thing about them is that once you master one power chord, you can move it up and down the neck to make different chords. In the progression played during the video, a new kind of rhythm is played. It’s called a sixteenth note rhythm because each measure has 16 different beats in it. To count it we say “one-e-and-a-two-e-and-a-three-e-and-a-four-e-and-a.” This rhythm is played using all down strokes. It also sounds cool if you mute the strings slightly. sixteen down strokes sixteen down strokes per measure per measure That’s a lot of down strokes!! ©2006 Little Kids Rock © Copyright 2011 Little Kids Rock www.littlekidsrock.org More cool stuff at: www.littlekidsrock.org lesson POWER CHORD SCRAMBLE #8 When you scramble an egg, you don't worry too much about what part goes where. -

Music Theory Contents
Music theory Contents 1 Music theory 1 1.1 History of music theory ........................................ 1 1.2 Fundamentals of music ........................................ 3 1.2.1 Pitch ............................................. 3 1.2.2 Scales and modes ....................................... 4 1.2.3 Consonance and dissonance .................................. 4 1.2.4 Rhythm ............................................ 5 1.2.5 Chord ............................................. 5 1.2.6 Melody ............................................ 5 1.2.7 Harmony ........................................... 6 1.2.8 Texture ............................................ 6 1.2.9 Timbre ............................................ 6 1.2.10 Expression .......................................... 7 1.2.11 Form or structure ....................................... 7 1.2.12 Performance and style ..................................... 8 1.2.13 Music perception and cognition ................................ 8 1.2.14 Serial composition and set theory ............................... 8 1.2.15 Musical semiotics ....................................... 8 1.3 Music subjects ............................................. 8 1.3.1 Notation ............................................ 8 1.3.2 Mathematics ......................................... 8 1.3.3 Analysis ............................................ 9 1.3.4 Ear training .......................................... 9 1.4 See also ................................................ 9 1.5 Notes ................................................ -

Teaching Traditional Music Theory with Popular Songs
s leaching Traditional Music Theory with Popular Songs: Pitch Structures Heather Maclachlan 1' his chapter provides a guideline for teaching conventi�nal, common Pr actice period music theory concepts using well-known English-language P opular songs. I developed the lessons included here in the a-ucible of the u niversity classroom while teaching music theory to undergraduate students t � Cornell University in 2007. This approach to teaching theory, therefore, as the advantage of having been created in conjunction with recent stu- d e�ts, who ultimately demonsu·ated mastery of the concepts presented and en1oyed doing so. While this tactic has not been tested with a large enough r g oup of students to provide reliable data, it is clear that the students who P�rticipated in these lessons deeply appreciated the oppo1tunity, and they at � � �s much on their course evaluations, all of which were quite positive. ndiv1duals made comments like, "It was ina-edible to hear what we were 1 earning in pieces that we knew," and "The teacher should write her own �eJctbook using examples from modern m\tSic! ! ! " This chapter represents a trst attempt at presenting this approach to a larger audience. BENEFITS OF INCORPORATING CONTEMPORARY-POP SONGS INTO TRADITIONAL MUSIC-THEORY CLASSES 'l'h. story of how I came to use this approach to music theory demonstrates s e orne important pedagogical principles. I was working as a teaching assis t ant for a professor of music theory who had developed a clear and consis t ent approach to the topic. Over the course of about 20 years, he honed his curriculum. -

Chords, Scales, Arpeggios & Picking
843 CHORDS, SCALES, ARPEGGIOS & PICKING ACOUSTIC GUITAR METHOD ARPEGGIO FINDER A BEGINNER’S CHORD BOOK EASY-TO-USE GUIDE TO OVER GUIDE TO by David Hamburger 1,300 GUITAR ARPEGGIOS CHORD Acoustic Guitar Magazine Private Lessons by Chad Johnson POSITIONS String Letter Publishing Hal Leonard Guitar Method SIMPLE, CREATIVE WAYS David Hamburger’s supplementary chord book for the Please see the Hal Leonard TO MOVE UP THE NECK Acoustic Guitar Method is a must-have resource for gui- Guitar Method for com- by Happy Traum tarists who want to build their chord vocabulary! Starting plete description. Homespun with a user-friendly explanation of what chords are and Find chords in the upper how they are named, this book presents chords by key in reaches of the fingerboard, all 12 keys, offering both open-position and closed- ______00697351 9" x 12" Edition.................$6.95 and learn the basic concepts of music theory for guitar. position voicings for each common chord type. Also ARPEGGIOS Starting with the easiest three-string movable chord includes info on barre chords, using a capo and more. positions, Happy explains with very clear, simple ______00695722............................................$5.95 by Joe Charupakorn instructions how to use them, combining them with Cherry Lane Music other movable chords until you can play in any ADVANCED Please see Guitar Reference Guides Series for a position and in any key. Moving on to four, five and six- SCALE complete description. string (barre) movable chords, you’ll learn songs and CONCEPTS ______02500125..........................................$14.95 G chord progressions that will help you put your newly- U I AND LICKS FOR acquired chord knowledge into practice.