Record Linkage Under Suboptimal Conditions for Data-Intensive
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Core Competencies for Scientific Editors Of
Moher et al. BMC Medicine (2017) 15:167 DOI 10.1186/s12916-017-0927-0 CORRESPONDENCE Open Access Core competencies for scientific editors of biomedical journals: consensus statement David Moher1,2* , James Galipeau3, Sabina Alam4, Virginia Barbour5, Kidist Bartolomeos6, Patricia Baskin7,8, Sally Bell-Syer9,10, Kelly D. Cobey1,2,11, Leighton Chan12, Jocalyn Clark13, Jonathan Deeks14, Annette Flanagin15, Paul Garner16, Anne-Marie Glenny17, Trish Groves18, Kurinchi Gurusamy19, Farrokh Habibzadeh20,21,22, Stefanie Jewell-Thomas23, Diane Kelsall24, José Florencio Lapeña Jr22,25,26,27, Harriet MacLehose28, Ana Marusic29,30, Joanne E. McKenzie31, Jay Shah32,33,34, Larissa Shamseer1,2, Sharon Straus35, Peter Tugwell2,36,37, Elizabeth Wager38,39, Margaret Winker22 and Getu Zhaori40 Abstract Background: Scientific editors are responsible for deciding which articles to publish in their journals. However, we have not found documentation of their required knowledge, skills, and characteristics, or the existence of any formal core competencies for this role. Methods: We describe the development of a minimum set of core competencies for scientific editors of biomedical journals. Results: The 14 key core competencies are divided into three major areas, and each competency has a list of associated elements or descriptions of more specific knowledge, skills, and characteristics that contribute to its fulfillment. Conclusions: We believe that these core competencies are a baseline of the knowledge, skills, and characteristics needed to perform competently the duties of a scientific editor at a biomedical journal. Keywords: Core competencies, Scientific editor, Biomedical journal, Delphi, Expert consensus, Editor role Introduction and in guidance for members of editor organizations Scientific editors (editors are responsible for the content [3–8]. -

Scientific Data
Author: Amye Kenall, Associate Publisher, BioMed Central *For internal use only Open Data Research data: from journal policy to practice “[O]pen access to raw data will go the same way as open access to published papers…It would not be a surprise if, in a decade’s time, funders finally get tired of paying for data that researchers keep As part of a SpringerNature-wide project, we aim to provide consistent data policies and services to every journal. to themselves…we should fully expect funders to demand that grantees share data” Why? y At least 28 research funders globally have policies or mandates Andrew J Vickers, Memorial Sloan Kettering Cancer Center y Improving author service by standardizing research www.bmj.com/content/342/bmj.d2323 (2011) that require data archiving as a condition of grants, including: data policies and procedures and increasing the y National Science Foundation (NSF) visibility and connectivity of their articles and data y National Institutes of Health (NIH) y Improving editor and peer reviewer service with What do we plan to provide and when? y Wellcome Trust better guidelines and support for data policies, and visibility of data in the peer-review process y A research data policy for every relevant publication (journals, books, proceedings) y Bill and Melinda Gates Foundation y Improving reader service with more consistent y Begin by developing 4 standardized data policies y Sharing data is good for research—and researchers and useful links to data y First groups of journals to introduce standard policy in -

SPRINGER NATURE Products, Services & Solutions 2 Springer Nature Products, Services & Solutions Springernature.Com
springernature.com Illustration inspired by the work of Marie Curie SPRINGER NATURE Products, Services & Solutions 2 Springer Nature Products, Services & Solutions springernature.com About Springer Nature Springer Nature advances discovery by publishing robust and insightful research, supporting the development of new areas of knowledge, making ideas and information accessible around the world, and leading the way on open access. Our journals, eBooks, databases and solutions make sure that researchers, students, teachers and professionals have access to important research. Springer Established in 1842, Springer is a leading global scientific, technical, medical, humanities and social sciences publisher. Providing researchers with quality content via innovattive products and services, Springer has one of the most significant science eBooks and archives collections, as well as a comprehensive range of hybrid and open access journals. Nature Research Publishing some of the most significant discoveries since 1869. Nature Research publishes the world’s leading weekly science journal, Nature, in addition to Nature- branded research and review subscription journals. The portfolio also includes Nature Communications, the leading open access journal across all sciences, plus a variety of Nature Partner Journals, developed with institutions and societies. Academic journals on nature.com Prestigious titles in the clinical, life and physical sciences for communities and established medical and scientific societies, many of which are published in partnership a society. Adis A leading international publisher of drug-focused content and solutions. Adis supports work in the pharmaceutical and biotech industry, medical research, practice and teaching, drug regulation and reimbursement as well as related finance and consulting markets. Apress A technical publisher of high-quality, practical content including over 3000 titles for IT professionals, software developers, programmers and business leaders around the world. -

Open-Access News Around The
Unbound compiled by Elizabeth L Fleischer Global Initiative on Sharing Avian is developing its own e-print repository, Open-Access Influenza Data Launched which as of this writing was expected to In August 2006, Peter Bogner, Ilaria Capua, go live toward the end of 2006 and be News Around Nancy Cox, and David Lipman launched available at www.nerc.ac.uk/about/access/ the Global Initiative on Sharing Avian repository.asp. Two of the NERC collabora- the Net Influenza Data (GISAID), a project to tive centers—Plymouth Marine Laboratory provide open access to H5N1 avian influ- and the National Oceanography Centre, enza data. They published an open letter in Southhampton—already have repositories Nature calling on all influenza scientists to available. participate in it. A 24 August press release See www.nerc.ac.uk/about/access and from GISAID announced that the forma- Peter Suber, SPARC Open Access tion of the consortium of leading medical Newsletter, issue 101, 2 September 2006, researchers around the world is “designed to www.earlham.edu/~peters/fos/newsletter/ improve the sharing of influenza data, ana- 09-02-06.htm. lyze data findings jointly, and publish the results collaboratively as part of the Global Open Access Central Expands Initiative on Sharing Avian Influenza from BioMed to Chemistry and Data (GISAID)”. Data collected under Beyond the initiative will be deposited in three The team that created BioMed Central, major publicly available databases: EBML the world’s largest biomedical open-access (United Kingdom), DDBJ (Japan), and publisher, is now moving into chemistry GenBank (United States). The GISAID and has plans to expand into physics and consortium is open to all scientists, “pro- mathematics, calling the expanded pub- vided they agree to share their own data, lishing collection Open Access Central. -

Download.Pdf/Emp-R-E-2011-Vaccination-Grippe.Pdf
Currat et al. Journal of Occupational Medicine and Toxicology (2020) 15:34 https://doi.org/10.1186/s12995-020-00285-w RESEARCH Open Access Promotion of the influenza vaccination to hospital staff during pre-employment health check: a prospective, randomised, controlled trial Michael Currat1* , Catherine Lazor-Blanchet1 and Giorgio Zanetti1,2 Abstract Background: Vaccination is the most effective prevention of seasonal influenza. Despite its recommendation and active promotion, vaccination coverage remains low among healthcare staff. The goal of the study was to test if a pre-employment health check is a good opportunity to promote future vaccination against influenza among healthcare workers newly hired by a university hospital. Methods: All new hospital employees active at the bedside who underwent a pre-employment health check between the end of 2016’s influenza epidemic and the start of the next influenza vaccination campaign were randomly allocated to a control group or an intervention group. The intervention consisted of a semi-structured dialog and the release of an information leaflet about influenza and influenza vaccination during the check-up, and the shipment of a postcard reminder 2 weeks before the next vaccination campaign. Vaccination rates during the campaign were compared among the two groups. Results: Three hundred fifty-seven employees were included. Vaccination rates were similar in both groups: 79/172 (46%) in the control and 92/185 (50%) in the intervention group. A significantly higher rate of vaccination was noted among physicians (70/117, 60%) than among other employees (101/240, 42%, p = 0.001). In a pre-defined exploratory analysis among physicians, the vaccination rate was higher in the intervention group (36/51, 71%) than in the control group (34/65, 52%, p = 0.046). -

Altmetrics: What, Where, Why? by Catherine Chimes Head of Marketing & Customer Relations Altmetric LLP
ARTICLE Altmetrics ARTICLE Altmetrics: What, Where, Why? By Catherine Chimes Head of Marketing & Customer Relations Altmetric LLP Altmetrics have become a buzzword in scholarly altmetrics data add a new layer of insight into the publishing in the last year. But just what is all the attention and societal impact the work has gar- fuss about? nered. As evaluation criteria expand and budgets tight- By providing both qualitative and quantitative en, authors, publishers, universities, and research data for a paper, altmetrics can help authors and bodies are increasingly looking for additional ways publishers explore, understand, and engage in to demonstrate the reach and value of their work. the conversations that are going on around the Traditional measures of scholarly impact, such as research. This can be used to help influence fu- the Impact Factor, tend to focus only at the jour- ture publications or research, and serves to further nal level—with little insight into how the individ- stimulate the academic discussion. ual articles within a publication perform. Recent advancements have therefore seen new measures emerge, which take a more granular view of the dissemination of articles and associ- ated research content. Commonly referred to as The task of tracking and reporting on an indi- altmetrics, or alternative metrics, these new forms vidual scholarly article is not without obstacles— of measurement look beyond citation and pub- not least the need to disambiguate between differ- lisher usage counts, with a focus on online “men- ent versions of a single piece of work. In order to tions” of a research work. By collating data from do this with accuracy, at Altmetric, data collation sources, such as social media, blogs, news outlets, is based on a scholarly identifier unique to each bookmarking sites, peer-review forums, and policy article—for example, the DOI or PubMed ID, documents, we are now able to see a much richer will remain the same whether hosted on the pub- picture of the true reach of the scholarly content. -
Raising the Acceptance Rate of Article Submissions from ESL Authors
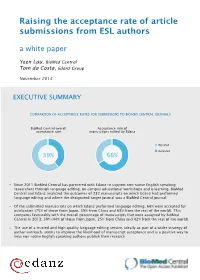
Raising the acceptance rate of article submissions from ESL authors a white paper Yeen Lau, BioMed Central Tom da Costa, Edanz Group November 2014 EXECUTIVE SUMMARY COMPARISON OF ACCEPTANCE RATES FOR SUBMISSIONS TO BIOMED CENTRAL JOURNALS BioMed Central overall Acceptance rate of acceptance rate manuscripts edited by Edanz Rejected Accepted 39% 66% Since 2011 BioMed Central has partnered with Edanz to support non-native English speaking researchers through language editing, on-campus educational workshops and e-learning. BioMed Central and Edanz analyzed the outcomes of 232 manuscripts on which Edanz had performed language editing and where the designated target journal was a BioMed Central journal. Of the submitted manuscripts on which Edanz performed language editing, 66% were accepted for publication (75% of those from Japan, 59% from China and 68% from the rest of the world). This compares favourably with the overall percentage of manuscripts that were accepted by BioMed Central in 2013: 39% (44% of those from Japan, 25% from China and 42% from the rest of the world). The use of a trusted and high quality language editing service, ideally as part of a wider strategy of author outreach, seems to improve the likelihood of manuscript acceptance and is a positive way to help non-native English speaking authors publish their research. INTRODUCTION MANUSCRIPT SUBMISSIONS TO BIOMED CENTRAL JOURNALS Researchers and clinicians, particularly non-native English speakers, face a 80% variety of challenges when trying to publish manuscripts: selecting the 70% appropriate journal, adhering to journal 60% guidelines, interpreting journal editor decisions and reviewers’ comments, 50% writing in English, as well as keeping up 40% with the literature [1]. -

A Systematic Review of Methodology Used in the Development of Prediction Models for Future Asthma Exacerbation Joshua Bridge1, John D
Bridge et al. BMC Medical Research Methodology (2020) 20:22 https://doi.org/10.1186/s12874-020-0913-7 RESEARCH ARTICLE Open Access A systematic review of methodology used in the development of prediction models for future asthma exacerbation Joshua Bridge1, John D. Blakey2,3 and Laura J. Bonnett4* Abstract Background: Clinical prediction models are widely used to guide medical advice and therapeutic interventions. Asthma is one of the most common chronic diseases globally and is characterised by acute deteriorations. These exacerbations are largely preventable, so there is interest in using clinical prediction models in this area. The objective of this review was to identify studies which have developed such models, determine whether consistent and appropriate methodology was used and whether statistically reliable prognostic models exist. Methods: We searched online databases MEDLINE (1948 onwards), CINAHL Plus (1937 onwards), The Cochrane Library, Web of Science (1898 onwards) and ClinicalTrials.gov, using index terms relating to asthma and prognosis. Data was extracted and assessment of quality was based on GRADE and an early version of PROBAST (Prediction study Risk of Bias Assessment Tool). A meta-analysis of the discrimination and calibration measures was carried out to determine overall performance across models. Results: Ten unique prognostic models were identified. GRADE identified moderate risk of bias in two of the studies, but more detailed quality assessment via PROBAST highlighted that most models were developed using highly selected and small datasets, incompletely recorded predictors and outcomes, and incomplete methodology. None of the identified models modelled recurrent exacerbations, instead favouring either presence/absence of an event, or time to first or specified event. -

Springer Nature Journals
springernature.com Illustration inspired by the work of Alan Turing SPRINGER NATURE JOURNALS Our world-leading journals bring you sound research and ground-breaking discoveries 2 Springer Nature Journals Contents 3 About Springer Nature 4 Nature Research journals 6 2018 Nature Research new launches 7 In the spotlight & Academic journals on nature.com 8 Springer journals 9 Palgrave Macmillan journals 10 Adis journals 11 Scientific American springernature.com 3 About Springer Nature Springer Nature is the world’s largest academic book publisher, publisher of the worlds most influential journals and a pioneer in the field of open research. Our mission is to enable the advance of research and to help the research community to improve outcomes. Through our portfolio of journals we enable researchers, students, teachers, and professionals to access the full depth and breadth of science, technology, medicine, humanities, and social sciences. Journals Springer journals on link.springer.com The leading source for high-quality, dynamic content across all research disciplines For more information about Springer Nature visit Palgrave Macmillan journals springernature.com Scholarly journals offering reliable, thought-pro- voking academic content across business & economics, humanities, and the social sciences Adis journals A premier collection of drug-focused medical journals and newsletters across the medical, biomedical and pharmacological areas Journals Nature on nature.com The leading weekly interdisciplinary science journal containing some of -

Biomed Central Open-Access Research That Covers a Broad Range of Disciplines, and Reaches Influencers and Decision Makers
The Open Access Publisher 2017 Media Kit BioMed Central Open-access research that covers a broad range of disciplines, and reaches influencers and decision makers. CHEMISTRY SPRINGER NATURE.................2 - BIOCHEMISTRY - GENERAL CHEMISTRY OUR SOLUTIONS.....................3 HEALTH JOURNALS & DISCIPLINES......5 - HEALTH SERVICES RESEARCH - PUBLIC HEALTH BIOLOGY - BIOINFORMATICS - CELL & MOLECULAR BIOLOGY - GENERICS AND GENOMICS - NEUROSCIENCE MEDICINE - CANCER - CARDIOVASCULAR DISORDERS - CRITICAL, INTENSIVE CARE AND EMERGENCY MEDICINE - IMMUNOLOGY - INFECTIOUS DISEASES SPRINGER NATURE SPRINGER NATURE QUALITY CONTENT RESEARCHERS, CLINICIANS, DOCTORS Springer Nature is a leading publisher of scientific, scholarly, professional EARLY-CAREER and educational content. For over a century, our brands have been setting the 20 JOURNALS RANK #1 PROFESSORS, SCIENTISTS, IN 1 OR MORE SUBJECT LIBRARIANS, scientific agenda. We’ve published ground-breaking work on many fundamental STUDENTS CATEGORY* EDUCATORS achievements, including the splitting of the atom, the structure of DNA, and the 9 OF THE TOP 20 SCIENCE JOURNALS BY IMPACT discovery of the hole in the ozone layer, as well as the latest advances in stem- FACTOR* MORE NOBEL LAUREATES cell research and the results of the ENCODE project. BOARD-LEVEL PUBLISHED WITH US THAN ANY POLICY-MAKERS, SENIOR MANAGERS OTHER SCIENTIFIC PUBLISHER OPINION LEADERS Our dominance in the scientific publishing market comes from a company- wide philosophy to uphold the highest level of quality for our readers, authors -

Development of Measurable Indicators to Enhance Public Health
Tudisca et al. Health Research Policy and Systems (2018) 16:47 https://doi.org/10.1186/s12961-018-0323-z RESEARCH Open Access Development of measurable indicators to enhance public health evidence-informed policy-making Valentina Tudisca1* ,AdrianaValente1,TommasoCastellani1,TimoStahl2, Petru Sandu3, Diana Dulf3, Hilde Spitters4, Ien Van de Goor4, Christina Radl-Karimi5, Mohamed Ahmed Syed6, Natasa Loncarevic5,CathrineJuelLau7, Susan Roelofs8,MajaBertram5, Nancy Edwards8,ArjaR.Aro5 and on behalf of the REPOPA Consortium Abstract Background: Ensuring health policies are informed by evidence still remains a challenge despite efforts devoted to this aim. Several tools and approaches aimed at fostering evidence-informed policy-making (EIPM) have been developed, yet there is a lack of availability of indicators specifically devoted to assess and support EIPM. The present study aims to overcome this by building a set of measurable indicators for EIPM intended to infer if and to what extent health-related policies are, or are expected to be, evidence-informed for the purposes of policy planning as well as formative and summative evaluations. Methods: The indicators for EIPM were developed and validated at international level by means of a two-round internet-based Delphi study conducted within the European project ‘REsearch into POlicy to enhance Physical Activity’ (REPOPA). A total of 82 researchers and policy-makers from the six European countries (Denmark, Finland, Italy, the Netherlands, Romania, the United Kingdom) involved in the project and international organisations were asked to evaluate the relevance and feasibility of an initial set of 23 indicators developed by REPOPA researchers on the basis of literature and knowledge gathered from the previous phases of the project, and to propose new indicators. -

Appendix: List of Top Quartile (Q1) Open Access Journals Published in English, Ranked by Impact Factor
Appendix: List of Top Quartile (Q1) Open Access Journals published in English, ranked by Impact Factor. Title Publisher 2011 Impact Factor CA-A Cancer Journal for Clinicians Wiley 101.78 Living Reviews in Relativity Max-Planck Institute for Gravitational Physics 17.462 PLoS Medicine Public Library of Science (PLoS) 16.269 Living Reviews in Solar Physics Max Planck Institute for Solar System Research 12.5 PLoS Biology Public Library of Science (PLoS) 11.452 Pain Physician American Society of Interventional Pain 10.722 Physicians Studies in Mycology Centraalbureau voor Schimmelcultures 10.625 PLoS Pathogens Public Library of Science (PLoS) 9.127 PLoS Genetics Public Library of Science (PLoS) 8.694 Molecular Systems Biology European Molecular Biology Organization 8.626 Nucleic Acids Research Oxford University Press 8.026 Particle And Fibre Toxicology BioMed Central 7.253 Environmental Health Perspectives The National Institute of Environmental Health 7.036 Sciences (NIEHS) Retrovirology BioMed Central 6.47 Haematologica-The Hematology Journal Ferrata Storti Foundation 6.424 Emerging Infectious Diseases U.S. National Center for Infectious Diseases 6.169 Eurosurveillance European Centre for Disease Prevention and 6.153 Control Biotechnology for Biofuels BioMed Central 6.088 Bmc Medicine BioMed Central 6.035 Neoplasia Neoplasia 5.946 Bmc Biology BioMed Central 5.75 Atmospheric Chemistry And Physics Copernicus Publications 5.52 Cell Communication And Signaling BioMed Central 5.5 Annals of Family Medicine HighWire 5.355 Journal of Psychiatry &