Primepcr™Assay Validation Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Low Abundance of the Matrix Arm of Complex I in Mitochondria Predicts Longevity in Mice
ARTICLE Received 24 Jan 2014 | Accepted 9 Apr 2014 | Published 12 May 2014 DOI: 10.1038/ncomms4837 OPEN Low abundance of the matrix arm of complex I in mitochondria predicts longevity in mice Satomi Miwa1, Howsun Jow2, Karen Baty3, Amy Johnson1, Rafal Czapiewski1, Gabriele Saretzki1, Achim Treumann3 & Thomas von Zglinicki1 Mitochondrial function is an important determinant of the ageing process; however, the mitochondrial properties that enable longevity are not well understood. Here we show that optimal assembly of mitochondrial complex I predicts longevity in mice. Using an unbiased high-coverage high-confidence approach, we demonstrate that electron transport chain proteins, especially the matrix arm subunits of complex I, are decreased in young long-living mice, which is associated with improved complex I assembly, higher complex I-linked state 3 oxygen consumption rates and decreased superoxide production, whereas the opposite is seen in old mice. Disruption of complex I assembly reduces oxidative metabolism with concomitant increase in mitochondrial superoxide production. This is rescued by knockdown of the mitochondrial chaperone, prohibitin. Disrupted complex I assembly causes premature senescence in primary cells. We propose that lower abundance of free catalytic complex I components supports complex I assembly, efficacy of substrate utilization and minimal ROS production, enabling enhanced longevity. 1 Institute for Ageing and Health, Newcastle University, Newcastle upon Tyne NE4 5PL, UK. 2 Centre for Integrated Systems Biology of Ageing and Nutrition, Newcastle University, Newcastle upon Tyne NE4 5PL, UK. 3 Newcastle University Protein and Proteome Analysis, Devonshire Building, Devonshire Terrace, Newcastle upon Tyne NE1 7RU, UK. Correspondence and requests for materials should be addressed to T.v.Z. -

Mitoxplorer, a Visual Data Mining Platform To
mitoXplorer, a visual data mining platform to systematically analyze and visualize mitochondrial expression dynamics and mutations Annie Yim, Prasanna Koti, Adrien Bonnard, Fabio Marchiano, Milena Dürrbaum, Cecilia Garcia-Perez, José Villaveces, Salma Gamal, Giovanni Cardone, Fabiana Perocchi, et al. To cite this version: Annie Yim, Prasanna Koti, Adrien Bonnard, Fabio Marchiano, Milena Dürrbaum, et al.. mitoXplorer, a visual data mining platform to systematically analyze and visualize mitochondrial expression dy- namics and mutations. Nucleic Acids Research, Oxford University Press, 2020, 10.1093/nar/gkz1128. hal-02394433 HAL Id: hal-02394433 https://hal-amu.archives-ouvertes.fr/hal-02394433 Submitted on 4 Dec 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License Nucleic Acids Research, 2019 1 doi: 10.1093/nar/gkz1128 Downloaded from https://academic.oup.com/nar/advance-article-abstract/doi/10.1093/nar/gkz1128/5651332 by Bibliothèque de l'université la Méditerranée user on 04 December 2019 mitoXplorer, a visual data mining platform to systematically analyze and visualize mitochondrial expression dynamics and mutations Annie Yim1,†, Prasanna Koti1,†, Adrien Bonnard2, Fabio Marchiano3, Milena Durrbaum¨ 1, Cecilia Garcia-Perez4, Jose Villaveces1, Salma Gamal1, Giovanni Cardone1, Fabiana Perocchi4, Zuzana Storchova1,5 and Bianca H. -

A CRISPR-Cas9 Screen Identifies Mitochondrial Translation As An
A CRISPR-Cas9 screen identifies mitochondrial translation as an essential process in latent KSHV infection of human endothelial cells Daniel L. Holmesa , Daniel T. Vogta , and Michael Lagunoffa,1 aDepartment of Microbiology, University of Washington, Seattle, WA 98109 Edited by Donald E. Ganem, Novartis Institutes for Biomedical Research, Inc., Emeryville, CA, and approved September 30, 2020 (received for review June 9, 2020) Kaposi’s sarcoma-associated herpesvirus (KSHV) is the etiologic KS tumors, providing a culture model for KSHV latency in agent of Kaposi’s sarcoma (KS) and primary effusion lymphoma tumors (3). Using cell culture systems, our laboratory has iden- (PEL). The main proliferating component of KS tumors is a tified several cellular pathways, which can be used to selec- cell of endothelial origin termed the spindle cell. Spindle cells tively target latently infected cells in vitro (4–7). Recently are predominantly latently infected with only a small percent- developed lentivirus-encoded CRISPR-Cas9–based screening age of cells undergoing viral replication. As there is no direct platforms have enabled large-scale interrogation of so-called treatment for latent KSHV, identification of host vulnerabili- “Achilles” genes within a population of human cells (8). These ties in latently infected endothelial cells could be exploited screens can be used to identify factors that are essential to the to inhibit KSHV-associated tumor cells. Using a pooled CRISPR- survival of cancer cells. Similar approaches have been used to Cas9 lentivirus library, we identified host factors that are identify genes that are critical for the survival of B cell lym- essential for the survival or proliferation of latently infected phomas infected with Epstein-Barr virus (EBV) (9). -

Human CLPB) Is a Potent Mitochondrial Protein Disaggregase That Is Inactivated By
bioRxiv preprint doi: https://doi.org/10.1101/2020.01.17.911016; this version posted January 18, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Skd3 (human CLPB) is a potent mitochondrial protein disaggregase that is inactivated by 3-methylglutaconic aciduria-linked mutations Ryan R. Cupo1,2 and James Shorter1,2* 1Department of Biochemistry and Biophysics, 2Pharmacology Graduate Group, Perelman School of Medicine at the University of Pennsylvania, Philadelphia, PA 19104, U.S.A. *Correspondence: [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.01.17.911016; this version posted January 18, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. ABSTRACT Cells have evolved specialized protein disaggregases to reverse toxic protein aggregation and restore protein functionality. In nonmetazoan eukaryotes, the AAA+ disaggregase Hsp78 resolubilizes and reactivates proteins in mitochondria. Curiously, metazoa lack Hsp78. Hence, whether metazoan mitochondria reactivate aggregated proteins is unknown. Here, we establish that a mitochondrial AAA+ protein, Skd3 (human CLPB), couples ATP hydrolysis to protein disaggregation and reactivation. The Skd3 ankyrin-repeat domain combines with conserved AAA+ elements to enable stand-alone disaggregase activity. A mitochondrial inner-membrane protease, PARL, removes an autoinhibitory peptide from Skd3 to greatly enhance disaggregase activity. Indeed, PARL-activated Skd3 dissolves α-synuclein fibrils connected to Parkinson’s disease. Human cells lacking Skd3 exhibit reduced solubility of various mitochondrial proteins, including anti-apoptotic Hax1. -

Skd3 (Human CLPB) Is a Potent Mitochondrial Protein Disaggregase That Is Inactivated By
bioRxiv preprint first posted online Jan. 18, 2020; doi: http://dx.doi.org/10.1101/2020.01.17.911016. The copyright holder for this preprint (which was not peer-reviewed) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Skd3 (human CLPB) is a potent mitochondrial protein disaggregase that is inactivated by 3-methylglutaconic aciduria-linked mutations Ryan R. Cupo1,2 and James Shorter1,2* 1Department of Biochemistry and Biophysics, 2Pharmacology Graduate Group, Perelman School of Medicine at the University of Pennsylvania, Philadelphia, PA 19104, U.S.A. *Correspondence: [email protected] 1 bioRxiv preprint first posted online Jan. 18, 2020; doi: http://dx.doi.org/10.1101/2020.01.17.911016. The copyright holder for this preprint (which was not peer-reviewed) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. ABSTRACT Cells have evolved specialized protein disaggregases to reverse toxic protein aggregation and restore protein functionality. In nonmetazoan eukaryotes, the AAA+ disaggregase Hsp78 resolubilizes and reactivates proteins in mitochondria. Curiously, metazoa lack Hsp78. Hence, whether metazoan mitochondria reactivate aggregated proteins is unknown. Here, we establish that a mitochondrial AAA+ protein, Skd3 (human CLPB), couples ATP hydrolysis to protein disaggregation and reactivation. The Skd3 ankyrin-repeat domain combines with conserved AAA+ elements to enable stand-alone disaggregase activity. A mitochondrial inner-membrane protease, PARL, removes an autoinhibitory peptide from Skd3 to greatly enhance disaggregase activity. Indeed, PARL-activated Skd3 dissolves α-synuclein fibrils connected to Parkinson’s disease. -

THE FUNCTIONAL SIGNIFICANCE of MITOCHONDRIAL SUPERCOMPLEXES in C. ELEGANS by WICHIT SUTHAMMARAK Submitted in Partial Fulfillment
THE FUNCTIONAL SIGNIFICANCE OF MITOCHONDRIAL SUPERCOMPLEXES in C. ELEGANS by WICHIT SUTHAMMARAK Submitted in partial fulfillment of the requirements For the degree of Doctor of Philosophy Dissertation Advisor: Drs. Margaret M. Sedensky & Philip G. Morgan Department of Genetics CASE WESTERN RESERVE UNIVERSITY January, 2011 CASE WESTERN RESERVE UNIVERSITY SCHOOL OF GRADUATE STUDIES We hereby approve the thesis/dissertation of _____________________________________________________ candidate for the ______________________degree *. (signed)_______________________________________________ (chair of the committee) ________________________________________________ ________________________________________________ ________________________________________________ ________________________________________________ ________________________________________________ (date) _______________________ *We also certify that written approval has been obtained for any proprietary material contained therein. Dedicated to my family, my teachers and all of my beloved ones for their love and support ii ACKNOWLEDGEMENTS My advanced academic journey began 5 years ago on the opposite side of the world. I traveled to the United States from Thailand in search of a better understanding of science so that one day I can return to my homeland and apply the knowledge and experience I have gained to improve the lives of those affected by sickness and disease yet unanswered by science. Ultimately, I hoped to make the academic transition into the scholarly community by proving myself through scientific research and understanding so that I can make a meaningful contribution to both the scientific and medical communities. The following dissertation would not have been possible without the help, support, and guidance of a lot of people both near and far. I wish to thank all who have aided me in one way or another on this long yet rewarding journey. My sincerest thanks and appreciation goes to my advisors Philip Morgan and Margaret Sedensky. -
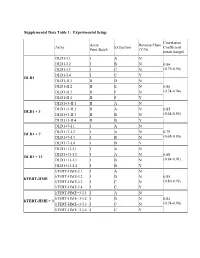
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom. -

Anti-NDUFB7 Antibody (ARG40047)
Product datasheet [email protected] ARG40047 Package: 100 μl anti-NDUFB7 antibody Store at: -20°C Summary Product Description Rabbit Polyclonal antibody recognizes NDUFB7 Tested Reactivity Hu, Ms Tested Application WB Host Rabbit Clonality Polyclonal Isotype IgG Target Name NDUFB7 Antigen Species Human Immunogen Recombinant fusion protein corresponding to aa. 1-137 of Human NDUFB7 (NP_004137.2). Conjugation Un-conjugated Alternate Names NADH dehydrogenase [ubiquinone] 1 beta subcomplex subunit 7; CI-B18; NADH-ubiquinone oxidoreductase B18 subunit; Complex I-B18; Cell adhesion protein SQM1; B18 Application Instructions Application table Application Dilution WB 1:500 - 1:2000 Application Note * The dilutions indicate recommended starting dilutions and the optimal dilutions or concentrations should be determined by the scientist. Positive Control Mouse heart and HL-60 Calculated Mw 16 kDa Observed Size 16 kDa Properties Form Liquid Purification Affinity purified. Buffer PBS (pH 7.3), 0.02% Sodium azide and 50% Glycerol. Preservative 0.02% Sodium azide Stabilizer 50% Glycerol Storage instruction For continuous use, store undiluted antibody at 2-8°C for up to a week. For long-term storage, aliquot and store at -20°C. Storage in frost free freezers is not recommended. Avoid repeated freeze/thaw cycles. Suggest spin the vial prior to opening. The antibody solution should be gently mixed before use. Note For laboratory research only, not for drug, diagnostic or other use. www.arigobio.com 1/2 Bioinformation Gene Symbol NDUFB7 Gene Full Name NADH dehydrogenase (ubiquinone) 1 beta subcomplex, 7, 18kDa Background The protein encoded by this gene is a subunit of the multisubunit NADH:ubiquinone oxidoreductase (complex I). -

Electron Transport Chain Activity Is a Predictor and Target for Venetoclax Sensitivity in Multiple Myeloma
ARTICLE https://doi.org/10.1038/s41467-020-15051-z OPEN Electron transport chain activity is a predictor and target for venetoclax sensitivity in multiple myeloma Richa Bajpai1,7, Aditi Sharma 1,7, Abhinav Achreja2,3, Claudia L. Edgar1, Changyong Wei1, Arusha A. Siddiqa1, Vikas A. Gupta1, Shannon M. Matulis1, Samuel K. McBrayer 4, Anjali Mittal3,5, Manali Rupji 6, Benjamin G. Barwick 1, Sagar Lonial1, Ajay K. Nooka 1, Lawrence H. Boise 1, Deepak Nagrath2,3,5 & ✉ Mala Shanmugam 1 1234567890():,; The BCL-2 antagonist venetoclax is highly effective in multiple myeloma (MM) patients exhibiting the 11;14 translocation, the mechanistic basis of which is unknown. In evaluating cellular energetics and metabolism of t(11;14) and non-t(11;14) MM, we determine that venetoclax-sensitive myeloma has reduced mitochondrial respiration. Consistent with this, low electron transport chain (ETC) Complex I and Complex II activities correlate with venetoclax sensitivity. Inhibition of Complex I, using IACS-010759, an orally bioavailable Complex I inhibitor in clinical trials, as well as succinate ubiquinone reductase (SQR) activity of Complex II, using thenoyltrifluoroacetone (TTFA) or introduction of SDHC R72C mutant, independently sensitize resistant MM to venetoclax. We demonstrate that ETC inhibition increases BCL-2 dependence and the ‘primed’ state via the ATF4-BIM/NOXA axis. Further, SQR activity correlates with venetoclax sensitivity in patient samples irrespective of t(11;14) status. Use of SQR activity in a functional-biomarker informed manner may better select for MM patients responsive to venetoclax therapy. 1 Department of Hematology and Medical Oncology, Winship Cancer Institute, School of Medicine, Emory University, Atlanta, GA, USA. -

Bayesian Hidden Markov Tree Models for Clustering Genes with Shared Evolutionary History
Submitted to the Annals of Applied Statistics arXiv: arXiv:0000.0000 BAYESIAN HIDDEN MARKOV TREE MODELS FOR CLUSTERING GENES WITH SHARED EVOLUTIONARY HISTORY By Yang Liy,{,∗, Shaoyang Ningy,∗, Sarah E. Calvoz,x,{, Vamsi K. Moothak,z,x,{ and Jun S. Liuy Harvard Universityy, Broad Institutez, Harvard Medical Schoolx, Massachusetts General Hospital{, and Howard Hughes Medical Institutek Determination of functions for poorly characterized genes is cru- cial for understanding biological processes and studying human dis- eases. Functionally associated genes are often gained and lost together through evolution. Therefore identifying co-evolution of genes can predict functional gene-gene associations. We describe here the full statistical model and computational strategies underlying the orig- inal algorithm CLustering by Inferred Models of Evolution (CLIME 1.0) recently reported by us [Li et al., 2014]. CLIME 1.0 employs a mixture of tree-structured hidden Markov models for gene evolution process, and a Bayesian model-based clustering algorithm to detect gene modules with shared evolutionary histories (termed evolutionary conserved modules, or ECMs). A Dirichlet process prior was adopted for estimating the number of gene clusters and a Gibbs sampler was developed for posterior sampling. We further developed an extended version, CLIME 1.1, to incorporate the uncertainty on the evolution- ary tree structure. By simulation studies and benchmarks on real data sets, we show that CLIME 1.0 and CLIME 1.1 outperform traditional methods that use simple metrics (e.g., the Hamming distance or Pear- son correlation) to measure co-evolution between pairs of genes. 1. Introduction. The human genome encodes more than 20,000 protein- coding genes, of which a large fraction do not have annotated function to date [Galperin and Koonin, 2010]. -

Transcriptomic and Proteomic Landscape of Mitochondrial
TOOLS AND RESOURCES Transcriptomic and proteomic landscape of mitochondrial dysfunction reveals secondary coenzyme Q deficiency in mammals Inge Ku¨ hl1,2†*, Maria Miranda1†, Ilian Atanassov3, Irina Kuznetsova4,5, Yvonne Hinze3, Arnaud Mourier6, Aleksandra Filipovska4,5, Nils-Go¨ ran Larsson1,7* 1Department of Mitochondrial Biology, Max Planck Institute for Biology of Ageing, Cologne, Germany; 2Department of Cell Biology, Institute of Integrative Biology of the Cell (I2BC) UMR9198, CEA, CNRS, Univ. Paris-Sud, Universite´ Paris-Saclay, Gif- sur-Yvette, France; 3Proteomics Core Facility, Max Planck Institute for Biology of Ageing, Cologne, Germany; 4Harry Perkins Institute of Medical Research, The University of Western Australia, Nedlands, Australia; 5School of Molecular Sciences, The University of Western Australia, Crawley, Australia; 6The Centre National de la Recherche Scientifique, Institut de Biochimie et Ge´ne´tique Cellulaires, Universite´ de Bordeaux, Bordeaux, France; 7Department of Medical Biochemistry and Biophysics, Karolinska Institutet, Stockholm, Sweden Abstract Dysfunction of the oxidative phosphorylation (OXPHOS) system is a major cause of human disease and the cellular consequences are highly complex. Here, we present comparative *For correspondence: analyses of mitochondrial proteomes, cellular transcriptomes and targeted metabolomics of five [email protected] knockout mouse strains deficient in essential factors required for mitochondrial DNA gene (IKu¨ ); expression, leading to OXPHOS dysfunction. Moreover, -

Mitochondrial Structure and Bioenergetics in Normal and Disease Conditions
International Journal of Molecular Sciences Review Mitochondrial Structure and Bioenergetics in Normal and Disease Conditions Margherita Protasoni 1 and Massimo Zeviani 1,2,* 1 Mitochondrial Biology Unit, The MRC and University of Cambridge, Cambridge CB2 0XY, UK; [email protected] 2 Department of Neurosciences, University of Padova, 35128 Padova, Italy * Correspondence: [email protected] Abstract: Mitochondria are ubiquitous intracellular organelles found in almost all eukaryotes and involved in various aspects of cellular life, with a primary role in energy production. The interest in this organelle has grown stronger with the discovery of their link to various pathologies, including cancer, aging and neurodegenerative diseases. Indeed, dysfunctional mitochondria cannot provide the required energy to tissues with a high-energy demand, such as heart, brain and muscles, leading to a large spectrum of clinical phenotypes. Mitochondrial defects are at the origin of a group of clinically heterogeneous pathologies, called mitochondrial diseases, with an incidence of 1 in 5000 live births. Primary mitochondrial diseases are associated with genetic mutations both in nuclear and mitochondrial DNA (mtDNA), affecting genes involved in every aspect of the organelle function. As a consequence, it is difficult to find a common cause for mitochondrial diseases and, subsequently, to offer a precise clinical definition of the pathology. Moreover, the complexity of this condition makes it challenging to identify possible therapies or drug targets. Keywords: ATP production; biogenesis of the respiratory chain; mitochondrial disease; mi-tochondrial electrochemical gradient; mitochondrial potential; mitochondrial proton pumping; mitochondrial respiratory chain; oxidative phosphorylation; respiratory complex; respiratory supercomplex Citation: Protasoni, M.; Zeviani, M.