Survey of Search and Replication Schemes in Unstructured P2p Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -
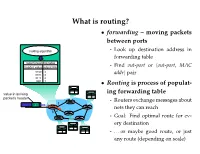
What Is Routing?
What is routing? • forwarding – moving packets between ports - Look up destination address in forwarding table - Find out-port or hout-port, MAC addri pair • Routing is process of populat- ing forwarding table - Routers exchange messages about nets they can reach - Goal: Find optimal route for ev- ery destination - . or maybe good route, or just any route (depending on scale) Routing algorithm properties • Static vs. dynamic - Static: routes change slowly over time - Dynamic: automatically adjust to quickly changing network conditions • Global vs. decentralized - Global: All routers have complete topology - Decentralized: Only know neighbors & what they tell you • Intra-domain vs. Inter-domain routing - Intra-: All routers under same administrative control - Intra-: Scale to ∼100 networks (e.g., campus like Stanford) - Inter-: Decentralized, scale to Internet Optimality A 6 1 3 2 F 1 E B 4 1 9 C D • View network as a graph • Assign cost to each edge - Can be based on latency, b/w, utilization, queue length, . • Problem: Find lowest cost path between two nodes - Must be computed in distributed way Distance Vector • Local routing algorithm • Each node maintains a set of triples - (Destination, Cost, NextHop) • Exchange updates w. directly connected neighbors - periodically (on the order of several seconds to minutes) - whenever table changes (called triggered update) • Each update is a list of pairs: - (Destination, Cost) • Update local table if receive a “better” route - smaller cost - from newly connected/available neighbor • Refresh existing -

Simulacijski Alati I Njihova Ograničenja Pri Analizi I Unapređenju Rada Mreža Istovrsnih Entiteta
SVEUČILIŠTE U ZAGREBU FAKULTET ORGANIZACIJE I INFORMATIKE VARAŽDIN Tedo Vrbanec SIMULACIJSKI ALATI I NJIHOVA OGRANIČENJA PRI ANALIZI I UNAPREĐENJU RADA MREŽA ISTOVRSNIH ENTITETA MAGISTARSKI RAD Varaždin, 2010. PODACI O MAGISTARSKOM RADU I. AUTOR Ime i prezime Tedo Vrbanec Datum i mjesto rođenja 7. travanj 1969., Čakovec Naziv fakulteta i datum diplomiranja Fakultet organizacije i informatike, 10. listopad 2001. Sadašnje zaposlenje Učiteljski fakultet Zagreb – Odsjek u Čakovcu II. MAGISTARSKI RAD Simulacijski alati i njihova ograničenja pri analizi i Naslov unapređenju rada mreža istovrsnih entiteta Broj stranica, slika, tablica, priloga, XIV + 181 + XXXVIII stranica, 53 slike, 18 tablica, 3 bibliografskih podataka priloga, 288 bibliografskih podataka Znanstveno područje, smjer i disciplina iz koje Područje: Informacijske znanosti je postignut akademski stupanj Smjer: Informacijski sustavi Mentor Prof. dr. sc. Željko Hutinski Sumentor Prof. dr. sc. Vesna Dušak Fakultet na kojem je rad obranjen Fakultet organizacije i informatike Varaždin Oznaka i redni broj rada III. OCJENA I OBRANA Datum prihvaćanja teme od Znanstveno- 17. lipanj 2008. nastavnog vijeća Datum predaje rada 9. travanj 2010. Datum sjednice ZNV-a na kojoj je prihvaćena 18. svibanj 2010. pozitivna ocjena rada Prof. dr. sc. Neven Vrček, predsjednik Sastav Povjerenstva koje je rad ocijenilo Prof. dr. sc. Željko Hutinski, mentor Prof. dr. sc. Vesna Dušak, sumentor Datum obrane rada 1. lipanj 2010. Prof. dr. sc. Neven Vrček, predsjednik Sastav Povjerenstva pred kojim je rad obranjen Prof. dr. sc. Željko Hutinski, mentor Prof. dr. sc. Vesna Dušak, sumentor Datum promocije SVEUČILIŠTE U ZAGREBU FAKULTET ORGANIZACIJE I INFORMATIKE VARAŽDIN POSLIJEDIPLOMSKI ZNANSTVENI STUDIJ INFORMACIJSKIH ZNANOSTI SMJER STUDIJA: INFORMACIJSKI SUSTAVI Tedo Vrbanec Broj indeksa: P-802/2001 SIMULACIJSKI ALATI I NJIHOVA OGRANIČENJA PRI ANALIZI I UNAPREĐENJU RADA MREŽA ISTOVRSNIH ENTITETA MAGISTARSKI RAD Mentor: Prof. -

The Routing Table V1.12 – Aaron Balchunas 1
The Routing Table v1.12 – Aaron Balchunas 1 - The Routing Table - Routing Table Basics Routing is the process of sending a packet of information from one network to another network. Thus, routes are usually based on the destination network, and not the destination host (host routes can exist, but are used only in rare circumstances). To route, routers build Routing Tables that contain the following: • The destination network and subnet mask • The “next hop” router to get to the destination network • Routing metrics and Administrative Distance The routing table is concerned with two types of protocols: • A routed protocol is a layer 3 protocol that applies logical addresses to devices and routes data between networks. Examples would be IP and IPX. • A routing protocol dynamically builds the network, topology, and next hop information in routing tables. Examples would be RIP, IGRP, OSPF, etc. To determine the best route to a destination, a router considers three elements (in this order): • Prefix-Length • Metric (within a routing protocol) • Administrative Distance (between separate routing protocols) Prefix-length is the number of bits used to identify the network, and is used to determine the most specific route. A longer prefix-length indicates a more specific route. For example, assume we are trying to reach a host address of 10.1.5.2/24. If we had routes to the following networks in the routing table: 10.1.5.0/24 10.0.0.0/8 The router will do a bit-by-bit comparison to find the most specific route (i.e., longest matching prefix). -

P2P Resource Sharing in Wired/Wireless Mixed Networks 1
INT J COMPUT COMMUN, ISSN 1841-9836 Vol.7 (2012), No. 4 (November), pp. 696-708 P2P Resource Sharing in Wired/Wireless Mixed Networks J. Liao Jianwei Liao College of Computer and Information Science Southwest University of China 400715, Beibei, Chongqing, China E-mail: [email protected] Abstract: This paper presents a new routing protocol called Manager-based Routing Protocol (MBRP) for sharing resources in wired/wireless mixed networks. MBRP specifies a manager node for a designated sub-network (called as a group), in which all nodes have the similar connection properties; then all manager nodes are employed to construct the backbone overlay network with ring topology. The manager nodes act as the proxies between the internal nodes in the group and the external world, that is not only for centralized management of all nodes to a certain extent, but also for avoiding the messages flooding in the whole network. The experimental results show that compared with Gnutella2, which uses super-peers to perform similar management work, the proposed MBRP has less lookup overhead including lookup latency and lookup hop count in the most of cases. Besides, the experiments also indicate that MBRP has well configurability and good scaling properties. In a word, MBRP has less transmission cost of the shared file data, and the latency for locating the sharing resources can be reduced to a great extent in the wired/wireless mixed networks. Keywords: wired/wireless mixed network, resource sharing, manager-based routing protocol, backbone overlay network, peer-to-peer. 1 Introduction Peer-to-Peer technology (P2P) is a widely used network technology, the typical P2P network relies on the computing power and bandwidth of all participant nodes, rather than a few gathered and dedicated servers for central coordination [1, 2]. -
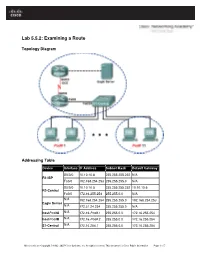
Lab 5.5.2: Examining a Route
Lab 5.5.2: Examining a Route Topology Diagram Addressing Table Device Interface IP Address Subnet Mask Default Gateway S0/0/0 10.10.10.6 255.255.255.252 N/A R1-ISP Fa0/0 192.168.254.253 255.255.255.0 N/A S0/0/0 10.10.10.5 255.255.255.252 10.10.10.6 R2-Central Fa0/0 172.16.255.254 255.255.0.0 N/A N/A 192.168.254.254 255.255.255.0 192.168.254.253 Eagle Server N/A 172.31.24.254 255.255.255.0 N/A host Pod# A N/A 172.16. Pod#.1 255.255.0.0 172.16.255.254 host Pod# B N/A 172.16. Pod#. 2 255.255.0.0 172.16.255.254 S1-Central N/A 172.16.254.1 255.255.0.0 172.16.255.254 All contents are Copyright © 1992–2007 Cisco Systems, Inc. All rights reserved. This document is Cisco Public Information. Page 1 of 7 CCNA Exploration Network Fundamentals: OSI Network Layer Lab 5.5.1: Examining a Route Learning Objectives Upon completion of this lab, you will be able to: • Use the route command to modify a Windows computer routing table. • Use a Windows Telnet client command telnet to connect to a Cisco router. • Examine router routes using basic Cisco IOS commands. Background For packets to travel across a network, a device must know the route to the destination network. This lab will compare how routes are used in Windows computers and the Cisco router. -

Distributed Lookup: Part 1: Distributed Hash Tables
CS 417 – DISTRIBUTED SYSTEMS Week 9: Distributed Lookup: Part 1: Distributed Hash Tables © 2021 Paul Krzyzanowski. No part of this content, may be reproduced or reposted in Paul Krzyzanowski whole or in part in any manner without the permission of the copyright owner. Distributed Lookup • Store (key, value) data Object Storage • Look up a key to get the value • Cooperating set of nodes store data • Ideally: – No central coordinator • Peer-to-peer system: all systems have the same capabilities – Some nodes can be down CS 417 © 2021 Paul Krzyzanowski 2 Approaches 1. Central coordinator – Napster 2. Flooding – Gnutella 3. Distributed hash tables – CAN, Chord, Amazon Dynamo, Tapestry, … CS 417 © 2021 Paul Krzyzanowski 3 1. Central Coordinator • Example: Napster – Central directory – Identifies content (names) and the servers that host it – lookup(name) → {list of servers} – Download from any of available servers • Pick the best one by pinging and comparing response times • Another example: GFS – Controlled environment compared to Napster – Content for a given key is broken into chunks – Master handles all queries … but not the data CS 417 © 2021 Paul Krzyzanowski 4 1. Central Coordinator - Napster • Pros – Super simple – Search is handled by a single server (master) – The directory server is a single point of control • Provides definitive answers to a query • Cons – Master has to maintain state of all peers – Server gets all the queries – The directory server is a single point of control • No directory, no service! CS 417 © 2021 Paul Krzyzanowski 5 2. Query Flooding • Example: Gnutella distributed file sharing • Each node joins a group – but only knows about some group members – Well-known nodes act as anchors – New nodes with files inform an anchor about their existence – Nodes use other nodes they know about as peers CS 417 © 2021 Paul Krzyzanowski 6 2. -

Routing Tables
Routing Tables A routing table is a grouping of information stored on a networked computer or network router that includes a list of routes to various network destinations. The data is normally stored in a database table and in more advanced configurations includes performance metrics associated with the routes stored in the table. Additional information stored in the table will include the network topology closest to the router. Although a routing table is routinely updated by network routing protocols, static entries can be made through manual action on the part of a network administrator. How Does a Routing Table Work? Routing tables work similar to how the post office delivers mail. When a network node on the Internet or a local network needs to send information to another node, it first requires a general idea of where to send the information. If the destination node or address is not connected directly to the network node, then the information has to be sent via other network nodes. In order to save resources, most local area network nodes will not maintain a complex routing table. Instead, they will send IP packets of information to a local network gateway. The gateway maintains the primary routing table for the network and will send the data packet to the desired location. In order to maintain a record of how to route information, the gateway will use a routing table that keeps track of the appropriate destination for outgoing data packets. All routing tables maintain routing table lists for the reachable destinations from the router’s location. -

Title: P2P Networks for Content Sharing
Title: P2P Networks for Content Sharing Authors: Choon Hoong Ding, Sarana Nutanong, and Rajkumar Buyya Grid Computing and Distributed Systems Laboratory, Department of Computer Science and Software Engineering, The University of Melbourne, Australia (chd, sarana, raj)@cs.mu.oz.au ABSTRACT Peer-to-peer (P2P) technologies have been widely used for content sharing, popularly called “file-swapping” networks. This chapter gives a broad overview of content sharing P2P technologies. It starts with the fundamental concept of P2P computing followed by the analysis of network topologies used in peer-to-peer systems. Next, three milestone peer-to-peer technologies: Napster, Gnutella, and Fasttrack are explored in details, and they are finally concluded with the comparison table in the last section. 1. INTRODUCTION Peer-to-peer (P2P) content sharing has been an astonishingly successful P2P application on the Internet. P2P has gained tremendous public attention from Napster, the system supporting music sharing on the Web. It is a new emerging, interesting research technology and a promising product base. Intel P2P working group gave the definition of P2P as "The sharing of computer resources and services by direct exchange between systems". This thus gives P2P systems two main key characteristics: • Scalability: there is no algorithmic, or technical limitation of the size of the system, e.g. the complexity of the system should be somewhat constant regardless of number of nodes in the system. • Reliability: The malfunction on any given node will not effect the whole system (or maybe even any other nodes). File sharing network like Gnutella is a good example of scalability and reliability. -

Introduction to the Border Gateway Protocol – Case Study Using GNS3
Introduction to The Border Gateway Protocol – Case Study using GNS3 Sreenivasan Narasimhan1, Haniph Latchman2 Department of Electrical and Computer Engineering University of Florida, Gainesville, USA [email protected], [email protected] Abstract – As the internet evolves to become a vital resource for many organizations, configuring The Border Gateway protocol (BGP) as an exterior gateway protocol in order to connect to the Internet Service Providers (ISP) is crucial. The BGP system exchanges network reachability information with other BGP peers from which Autonomous System-level policy decisions can be made. Hence, BGP can also be described as Inter-Domain Routing (Inter-Autonomous System) Protocol. It guarantees loop-free exchange of information between BGP peers. Enterprises need to connect to two or more ISPs in order to provide redundancy as well as to improve efficiency. This is called Multihoming and is an important feature provided by BGP. In this way, organizations do not have to be constrained by the routing policy decisions of a particular ISP. BGP, unlike many of the other routing protocols is not used to learn about routes but to provide greater flow control between competitive Autonomous Systems. In this paper, we present a study on BGP, use a network simulator to configure BGP and implement its route-manipulation techniques. Index Terms – Border Gateway Protocol (BGP), Internet Service Provider (ISP), Autonomous System, Multihoming, GNS3. 1. INTRODUCTION Figure 1. Internet using BGP [2]. Routing protocols are broadly classified into two types – Link State In the figure, AS 65500 learns about the route 172.18.0.0/16 through routing (LSR) protocol and Distance Vector (DV) routing protocol. -

CS 417 29 October 2018 Paul Krzyzanowski 1
CS 417 29 October 2018 Distributed Lookup • Look up (key, value) • Cooperating set of nodes Distributed Systems • Ideally: – No central coordinator 16. Distributed Lookup – Some nodes can be down Paul Krzyzanowski Rutgers University Fall 2018 October 29, 2018 © 2014-2018 Paul Krzyzanowski 1 October 29, 2018 © 2014-2018 Paul Krzyzanowski 2 Approaches 1. Central Coordinator 1. Central coordinator • Example: Napster – Napster – Central directory – Identifies content (names) and the servers that host it 2. Flooding – lookup(name) → {list of servers} – Download from any of available servers – Gnutella • Pick the best one by pinging and comparing response times 3. Distributed hash tables • Another example: GFS – CAN, Chord, Amazon Dynamo, Tapestry, … – Controlled environment compared to Napster – Content for a given key is broken into chunks – Master handles all queries … but not the data October 29, 2018 © 2014-2018 Paul Krzyzanowski 3 October 29, 2018 © 2014-2018 Paul Krzyzanowski 4 1. Central Coordinator - Napster 2. Query Flooding • Pros • Example: Gnutella distributed file sharing – Super simple – Search is handled by a single server (master) – The directory server is a single point of control • Well-known nodes act as anchors • Provides definitive answers to a query – Nodes with files inform an anchor about their existence – Nodes select other nodes as peers • Cons – Master has to maintain state of all peers – Server gets all the queries – The directory server is a single point of control • No directory, no service! October 29, 2018 © -

The Routing Table Lookup Process
The Routing Table Part 2 – The Routing Table Lookup Process By Rick Graziani Cisco Networking Academy [email protected] Updated: Oct. 10, 2002 This document is the second of two parts dealing with the routing table. Part I discussed the structure of the routing table, and how routes are created. Part II will discuss how the routing table lookup process finds the “best” route within the routing table. What happens when a router receives an IP packet, examines the IP destination address and looks that address up in the routing table? How does the router decide which route in the routing table is the best match? What affect does the subnet mask have on the routing table? How does the router decide whether or not to use a supernet or default route if there is not a better match? We will answer these questions and more in this document. The network we will be using is a simple three router network. RouterA and Router B share the common major network 172.16.0.0/24. RouterB and RouterC are connected by the 192.168.1.0/24 network. You will notice that RouterC also has a 172.16.4.0/24 subnet which is disconnected, or discontiguous, from the rest of the 172.16.0.0 network. 172.16.1.0/24 172.16.3.0/24 172.16.4.0/24 .1 fa0 .1 fa0 .1 fa0 .1 172.16.2.0/24 .2 .1 192.168.1.0/24 .2 s0 s0 s1 s0 Router A Router B Router C Most of this information is best explained by using examples.