Arxiv:2106.11575V1 [Cs.CL] 22 Jun 2021 Mans in a Dialogue
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alice @ 97.3 Presents Alice in Winterland Thursday, December 4, 2014 the Masonic in San Francisco 7:30Pm
Alice @ 97.3 presents Alice in Winterland Thursday, December 4, 2014 The Masonic in San Francisco 7:30pm Starring: Ed Sheeran, Train and Christina Perri San Francisco, CA (October 20, 2014) - - Alice @ 97.3 (http://radioalice.com) is pleased to announce this year’s line-up for ALICE IN WINTERLAND, an annual holiday concert Thursday, December 4, 2014 at the newly renovated Masonic in San Francisco. This very special evening of Alice music will feature Ed Sheeran, Train and Christina Perri. Tickets for ALICE IN WINTERLAND go on sale Wednesday morning, October 22, 2014 at 8:00 am tickets are on sale at Ticketmaster.com, Ticketmaster outlets or charge by phone at 1-800-745-3000, for more information go to http://radioalice.com. Tickets range from $58.50 to $98.50 plus applicable charges for general admission floor and reserved balcony seats. Tickets are available with no service fees at the Masonic box office on Saturdays between 10am and 2pm. Ed Sheeran Ed Sheeran burst on the American scene in 2012 when Alice @ 97.3 became the first Hot AC station in America to play his first single, “The A Team.” Not only were we the first to play it, we were also the first station that Ed ever heard his own music on in America (and he has the tattoo to prove it!) That record “+” featuring “The A Team” debuted at # 5 in America, and his follow-up record “x” (featuring “Sing”, “Don’t,” and “Thinking Out Loud”) debuted at #1 in America in June 2014. Alice @ 97.3 is thrilled to welcome Ed Sheeran back to the Bay, December 4th for Alice in Winterland 2014! Train Train are as Alice –and as San Francisco – as one band could possibly be. -
Download This List As PDF Here
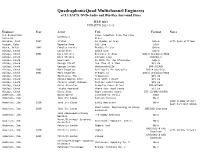
QuadraphonicQuad Multichannel Engineers of 5.1 SACD, DVD-Audio and Blu-Ray Surround Discs JULY 2021 UPDATED 2021-7-16 Engineer Year Artist Title Format Notes 5.1 Production Live… Greetins From The Flow Dishwalla Services, State Abraham, Josh 2003 Staind 14 Shades of Grey DVD-A with Ryan Williams Acquah, Ebby Depeche Mode 101 Live SACD Ahern, Brian 2003 Emmylou Harris Producer’s Cut DVD-A Ainlay, Chuck David Alan David Alan DVD-A Ainlay, Chuck 2005 Dire Straits Brothers In Arms DVD-A DualDisc/SACD Ainlay, Chuck Dire Straits Alchemy Live DVD/BD-V Ainlay, Chuck Everclear So Much for the Afterglow DVD-A Ainlay, Chuck George Strait One Step at a Time DTS CD Ainlay, Chuck George Strait Honkytonkville DVD-A/SACD Ainlay, Chuck 2005 Mark Knopfler Sailing To Philadelphia DVD-A DualDisc Ainlay, Chuck 2005 Mark Knopfler Shangri La DVD-A DualDisc/SACD Ainlay, Chuck Mavericks, The Trampoline DTS CD Ainlay, Chuck Olivia Newton John Back With a Heart DTS CD Ainlay, Chuck Pacific Coast Highway Pacific Coast Highway DTS CD Ainlay, Chuck Peter Frampton Frampton Comes Alive! DVD-A/SACD Ainlay, Chuck Trisha Yearwood Where Your Road Leads DTS CD Ainlay, Chuck Vince Gill High Lonesome Sound DTS CD/DVD-A/SACD Anderson, Jim Donna Byrne Licensed to Thrill SACD Anderson, Jim Jane Ira Bloom Sixteen Sunsets BD-A 2018 Grammy Winner: Anderson, Jim 2018 Jane Ira Bloom Early Americans BD-A Best Surround Album Wild Lines: Improvising on Emily Anderson, Jim 2020 Jane Ira Bloom DSD/DXD Download Dickinson Jazz Ambassadors/Sammy Anderson, Jim The Sammy Sessions BD-A Nestico Masur/Stavanger Symphony Anderson, Jim Kverndokk: Symphonic Dances BD-A Orchestra Anderson, Jim Patricia Barber Modern Cool BD-A SACD/DSD & DXD Anderson, Jim 2020 Patricia Barber Higher with Ulrike Schwarz Download SACD/DSD & DXD Anderson, Jim 2021 Patricia Barber Clique Download Svilvay/Stavanger Symphony Anderson, Jim Mortensen: Symphony Op. -

The Twenty Greatest Music Concerts I've Ever Seen
THE TWENTY GREATEST MUSIC CONCERTS I'VE EVER SEEN Whew, I'm done. Let me remind everyone how this worked. I would go through my Ipod in that weird Ipod alphabetical order and when I would come upon an artist that I have seen live, I would replay that concert in my head. (BTW, since this segment started I no longer even have an ipod. All my music is on my laptop and phone now.) The number you see at the end of the concert description is the number of times I have seen that artist live. If it was multiple times, I would do my best to describe the one concert that I considered to be their best. If no number appears, it means I only saw that artist once. Mind you, I have seen many artists live that I do not have a song by on my Ipod. That artist is not represented here. So although the final number of concerts I have seen came to 828 concerts (wow, 828!), the number is actually higher. And there are "bar" bands and artists (like LeCompt and Sam Butera, for example) where I have seen them perform hundreds of sets, but I counted those as "one," although I have seen Lecompt in "concert" also. Any show you see with the four stars (****) means they came damn close to being one of the Top Twenty, but they fell just short. So here's the Twenty. Enjoy and thanks so much for all of your input. And don't sue me if I have a date wrong here and there. -

2006 General Election Results on Sugar Island
The next issue of The Sault Tribe News will be the 2005 Annual Report. We will feature reports from every department of the Tribe along with their accomplishments and funding statistics. Please be sure to read the next issue of the news. The deadline for submissions for the following issue is Aug 1. HE AULT RIBE EWS T S Visit us online at www.saulttribe.comT N (O)De'imin Giizis “Strawberry Moon” Win Awenen Nisitotung “One Who Understands” June 30 2006 • Vol. 27, No. 9 News briefs No body contact advisory 2006 General election results on Sugar Island. Close race in Unit II determined by recount As a result of high bacteria levels, specifically E. coli, on the north shore of Sugar Island, the Chippewa County Health Depart- ment has issued a no body con- tact advisory for areas near 55 N. Westshore Dr., Williams Dr., and Village Rd. People should avoid body contact with surface waters of the St. Mary's River in these areas. Chippewa County Health Department will notify the public when the no body contact advisory is lifted. Gravelle hearing rescheduled for July 5 A preliminary hearing re- garding felony drug charges New Unit III Representative Keith Massaway, center, with wife, Re-elected incumbent Dennis McKelvie congratulates new levied last May 31 against Sault Jean, and one of his sons, Andrew. board member DJ Hoffman. PHOTOS BY ALAN KAMUDA Tribe Board of Directors Unit I The Sault Tribe’s governing count was requested by Hank and their oath of office at the Sault UNOFFICIAL RESULTS Representative Todd Gravelle body will welcome three new a hand count of the votes was con- powwow on July 1. -
Songs by Title
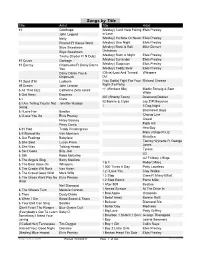
Songs by Title Title Artist Title Artist #1 Goldfrapp (Medley) Can't Help Falling Elvis Presley John Legend In Love Nelly (Medley) It's Now Or Never Elvis Presley Pharrell Ft Kanye West (Medley) One Night Elvis Presley Skye Sweetnam (Medley) Rock & Roll Mike Denver Skye Sweetnam Christmas Tinchy Stryder Ft N Dubz (Medley) Such A Night Elvis Presley #1 Crush Garbage (Medley) Surrender Elvis Presley #1 Enemy Chipmunks Ft Daisy Dares (Medley) Suspicion Elvis Presley You (Medley) Teddy Bear Elvis Presley Daisy Dares You & (Olivia) Lost And Turned Whispers Chipmunk Out #1 Spot (TH) Ludacris (You Gotta) Fight For Your Richard Cheese #9 Dream John Lennon Right (To Party) & All That Jazz Catherine Zeta Jones +1 (Workout Mix) Martin Solveig & Sam White & Get Away Esquires 007 (Shanty Town) Desmond Dekker & I Ciara 03 Bonnie & Clyde Jay Z Ft Beyonce & I Am Telling You Im Not Jennifer Hudson Going 1 3 Dog Night & I Love Her Beatles Backstreet Boys & I Love You So Elvis Presley Chorus Line Hirley Bassey Creed Perry Como Faith Hill & If I Had Teddy Pendergrass HearSay & It Stoned Me Van Morrison Mary J Blige Ft U2 & Our Feelings Babyface Metallica & She Said Lucas Prata Tammy Wynette Ft George Jones & She Was Talking Heads Tyrese & So It Goes Billy Joel U2 & Still Reba McEntire U2 Ft Mary J Blige & The Angels Sing Barry Manilow 1 & 1 Robert Miles & The Beat Goes On Whispers 1 000 Times A Day Patty Loveless & The Cradle Will Rock Van Halen 1 2 I Love You Clay Walker & The Crowd Goes Wild Mark Wills 1 2 Step Ciara Ft Missy Elliott & The Grass Wont Pay -

Wibke Kraemer
PORTFOLIO WIBKE KRAEMER wibkekraemer.com in f P The project goal was to create an identity crest that represents myself. Illustration The crest had to include symbols and exterior enhancements. Colors were limited to three choices. All artwork had to be original. Identity Crest • Adobe Illustrator • Vector Art • Design Process • Personal Branding ILLUSTRATION Goal of this project was to develop a promotional Promotional Design package for a company of our choice. The design process included creating a mood UPLIFTING board, sketching, copy writing, as well as the layout and design of three promotional pieces The Nike Free TR 4 (brochure, postcard, magazine ad). I designed the package for Jazzercise and Nike to promote the workout and Nike’s Free TR 4. Jazzercise & NIKE • Adobe Indesign • Adobe Illustrator • Adobe Photoshop • Design Process • Layout & Copy Writing Make it your own. • Brochure (4-fold), Customize on NikeiD.com Postcard (7x5), Magazine PROMOTIONAL DESIGN PROMOTIONAL ad (8.375x10.875) Visit us online at Nike.com UPLIFTING Jazzercise.com The Nike Free TR 4 Sign up for Jazzercise today & receive 20% OFF a new pair of Nike Jazzercise Fitness Center 1090 N. Main St. shoes after attending 100 classes. Royal Oak, MI 48067 Promotional Design JAZZERCISE & NIKE Aerobic or cross training shoes absorb shock, support your When to replace your shoes feet, and help prevent injury during your workout. About Jazzercise Pay attention to how they feel Burn up to 600 calories in one fun and powerfully If you notice any aches or pains in your feet, legs, Jazzercise has partnered with Nike effective 60-minute total body workout. -

Selling Or Selling Out?: an Exploration of Popular Music in Advertising
Selling or Selling Out?: An Exploration of Popular Music in Advertising Kimberly Kim Submitted to the Department of Music of Amherst College in partial fulfillment of the requirements for the degree of Bachelor of Arts with honors. Faculty Advisor: Professor Jason Robinson Faculty Readers: Professor Jenny Kallick Professor Jeffers Engelhardt Professor Klara Moricz 05 May 2011 Table of Contents Acknowledgments............................................................................................................... ii Chapter 1 – Towards an Understanding of Popular Music and Advertising .......................1 Chapter 2 – “I’d Like to Buy the World a Coke”: The Integration of Popular Music and Advertising.........................................................................................................................14 Chapter 3 – Maybe Not So Genuine Draft: Licensing as Authentication..........................33 Chapter 4 – Selling Out: Repercussions of Product Endorsements...................................46 Chapter 5 – “Hold It Against Me”: The Evolution of the Music Videos ..........................56 Chapter 6 – Cultivating a New Cultural Product: Thoughts on the Future of Popular Music and Advertising.......................................................................................................66 Works Cited .......................................................................................................................70 i Acknowledgments There are numerous people that have provided me with invaluable -

January Issue
St. Charles Preparatory School January 2010 TheThe CarolianCarolian Official Newspaper Publication of St. Charles Preparatory School QUICK Haiti Tragedy Is Another Call NEWS: for Long Term Efforts St. Charles raises Will Ryan ‘10 over $11,000 for relief in Haiti! On January 12th, a massive, to rise as relief workers strug- The American Red Cross has 7.0—magnitude earthquake gle to pull survivors from the raised $25 million through St. Charles hockey struck the country of Haiti, near rubble. More than 200,000 lost donations sent in by text team beats the the capital city of Port-au- their lives in only nine days. messaging. Actor George bears for the Prince. Haiti is an island nation Fresh water, food, and gasoline Clooney has teamed with second time this located in the Caribbean next are in short supply. The coun- Haitian Wyclef Jean, a former season. to the Dominican Republic. try’s leaders fear that looting singer for the Fugees, to stage Haiti, a former French slave will become a major problem. a telethon for the country. The Top Ten colony, is the Western Hemi- People from all over the world Bono and Jay-Z are also Defining Moments sphere’s poorest country. collaborating on a new song to of the Past Ten have responded to help a Massive aftershocks have also nation that many thought was raise money for Haiti. Years are in. added to the devastation. The on the verge of stability for the Haiti’s immediate future is not Living Like T. presidential palace, Port-au- first time. -

Shannon Mcmahon
Meeting Virginia: Feminist Analysis and Implications of Late- and Post-1990s Pop/Rock Music A Senior Honors Thesis Presented in Partial Fulfillment of the Requirements for graduation with research distinction in English in the undergraduate colleges of The Ohio State University By Shannon McMahon The Ohio State University June 2010 Project Advisor: Dr. Sara Crosby, Department of English McMahon 2 Introduction Music and feminism grew together throughout the 1990s as two forces of popular culture that helped to define and clarify the roles and representations of bold, bad, and individualistic women of the third wave. Feminism was undergoing a generational wave change, and the new third wave’s close interaction with popular culture led to accusations of disorder from second wave feminists and those outside the movement, as well. Third wavers began to use popular culture products, including music, as means to self-understanding, and they overturned dated notions of power in order to assert their own interpretations and use pop music in constructive ways. The ‘90s was also a locus of change for music and, in particular, third wavers’ roles in the industry. The Riot Grrrls of the early 1990s expressed their anger through the punk alternative, and the female singer/songwriters of the later Lilith Fair made feminist music more mainstream and individualized. Although feminist music had made many strides, mass media outlets and feminists alike pinpointed the era after Lilith Fair ended in 1999 as a new low point for feminist music: over-commercialized, over-exposed teen pop stars of the era had become popular, and their lyrics did not initiate constructive feminist discussions. -

Train Set to Take Hit Album Bulletproof Picasso on Picasso at the Wheel Summer Tour 2015 with Special Guests the Fray & Matt
W TRAIN SET TO TAKE HIT ALBUM BULLETPROOF PICASSO ON PICASSO AT THE WHEEL SUMMER TOUR 2015 WITH SPECIAL GUESTS THE FRAY & MATT NATHANSON – Tour Kicks Off May 21 with Tickets on Sale Jan. 24 at LiveNation.com – – Band Announces New Single, “Bulletproof Picasso,” and Accompanying Music Video with Guest Stars Emily Kinney (The Walking Dead) and Reid Ewing (Modern Family); Premieres Jan. 23 on VEVO – LOS ANGELES (Jan. 16, 2014) – Chart-topping San Francisco-natives Train are taking their latest hit album Bulletproof Picasso on the road with a 40+ city summer tour across North America with special guests The Fray and Matt Nathanson. The Picasso At The Wheel Summer Tour 2015, promoted by Live Nation, begins Thursday, May 21 at the Sleep Train Amphitheatre in Sacramento, Calif. and will conclude in Quincy, Wash. on Saturday, July 25 at The Gorge Amphitheatre for the band’s first ever Picasso Music, Food and Wine Festival. Fans across the country in cities such as Los Angeles, Dallas, New Orleans, Atlanta, Toronto and Nashville will have a chance to witness the band perform tracks from the new album—including the Top 10 radio single “Angel in Blue Jeans,” “Cadillac, Cadillac” and their new single “Bulletproof Picasso”—along with their many enigmatic, signature hits from the past 20 years. Fans are also encouraged to show up early for the Patcast Tailgate tent, where Pat Monahan will periodically make an appearance throughout the tour. Located in the venue parking lot each night, ticket- holders can tailgate and enjoy classic rock DJ, give shout-outs to friends on the Patcast (Pat's weekly podcast), and enter to win various prizes. -

Planning Guide
Planning Guide Brochure sponsored by Another best-in-class convention… Each year when we think about the upcoming MCAA convention, we ask ourselves, can it get any better? What could be left to experience, to enjoy? For starters, you will be inspired and informed by world-class major session speakers: Joe Scarborough and Mika Brzezinski of MSNBC, adventurer Erik Weihenmayer, former FBI Director Robert S. Mueller and actress Jamie Lee Curtis. There’s our impressive slate of featured session speakers and seminar presenters, including business strategists and industry specialists covering a gamut of topics of importance to our membership. And then, there are the many opportunities to network with your peers, enjoy great sporting and social events, visit with our manufacturer and supplier partners, and rock out to one of America’s top pop rock bands—Train! My commitment to you is that this year MCAA’s convention will—yet again—exceed expectations! It will be an extraordinary event you won’t want to miss! Michael R. Cables MCAA President …with a very special moment. This year’s Opening Session will include a very special moment for our association. I will be presenting our Distinguished Service Award to MCAA member John Odom. John and I served together on CPMCA’s Board of Directors. I personally know of his many contributions to our association and industry. For these alone he is a worthy recipient of MCAA’s highest award. But this year, coming back to his family, his friends and his company from horrific, near-fatal injuries sustained in the Boston Marathon bombing, John has given new meaning to the expression “exceed expectations.” His incredible journey, with his wife Karen always at his side, has inspired us all—and it will be my privilege to bestow this award on him in Scottsdale. -
UCWDC Competition Music
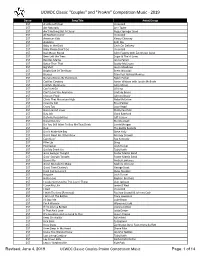
UCWDC Classic "Couples" and "ProAm" Competition Music - 2019 Dance Song Title Artist/Group 2ST A Little Left Over Vince Gill 2ST Act Naturally Ann Tayler 2ST Ain't Nothing But A Cloud Roger Springer Band 2ST All Nighter Comin' Vince Gill 2ST American Kids Kenny Chesney 2ST Angelina Keb' Mo 2ST Baby In the Dark Cash On Delivery 2ST Baby Please Don't Go Vince Gill 2ST Bad Moon Rising John Fogerty with Zac Brown Band 2ST Bees Left the Trees Sugar & The Hi Lows 2ST Besides Mama Jenny Farrell 2ST Better Than That Scotty McCreery 2ST Big Shot Jason Meadows 2ST Bright Side Of The Road Brent Woodall 2ST Bruises Train Feat Ashley Monroe 2ST Burying Bones By the Dozen Ralph Parker 2ST Cadillac Cowboy Aaron Watson with Justin McBride 2ST Call Me the Breeze John Mayer 2ST Can't Let Go Jill King 2ST Can't Love You Anymore Lindsay Bruce 2ST Chicken Fried Johnny Brady 2ST Climb That Mountain High Reba McEntire 2ST Country Girl Rissi Palmer 2ST Crazy Too Lucy Angel 2ST Damn Good Lover Shelly Fairchild 2ST Day Job Gord Bamford 2ST Definite Possibilities Jeff Carson 2ST Diesel Destiny Buddy Jewell 2ST Do You Still Want To Buy Me That Drink Lorrie Morgan 2ST Dog The Bottle Rockets 2ST Don't Make Me Beg Steve Holy 2ST Don't Need No Other Now Rodney Crowell 2ST Easy Goin' Ray Kennedy 2ST Filler Up Sting 2ST Firecracker Josh Turner 2ST Get My Drink On Toby Keith 2ST Goin Swingin Tonight Foster Martin Band 2ST Goin' Swingin Tonight Foster Martin Band 2ST Gonna Fly Amber Lawrence 2ST Good Mistake To Make Mallory Johnson 2ST Good Time Charley's George Strait