A Computational Light Field Display for Correcting Visual Aberrations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Action and Perception Are Temporally Coupled by a Common Mechanism That Leads to a Timing Misperception
The Journal of Neuroscience, January 28, 2015 • 35(4):1493–1504 • 1493 Behavioral/Cognitive Action and Perception Are Temporally Coupled by a Common Mechanism That Leads to a Timing Misperception Elena Pretegiani,1,2 Corina Astefanoaei,3 XPierre M. Daye,1,4 Edmond J. FitzGibbon,1 Dorina-Emilia Creanga,3 Alessandra Rufa,2 and XLance M. Optican1 1Laboratory of Sensorimotor Research, NEI, NIH, DHHS, Bethesda, Maryland, 20892-4435, 2EVA-Laboratory, University of Siena, 53100 Siena, Italy, 3Alexandru Ioan Cuza University, Physics Faculty, 700506 Iasi, Romania, and 4Institut du cerveau et de la moelle´pinie e `re (ICM), INSERM UMRS 975, 75013 Paris, France We move our eyes to explore the world, but visual areas determining where to look next (action) are different from those determining what we are seeing (perception). Whether, or how, action and perception are temporally coordinated is not known. The preparation time course of an action (e.g., a saccade) has been widely studied with the gap/overlap paradigm with temporal asynchronies (TA) between peripheral target onset and fixation point offset (gap, synchronous, or overlap). However, whether the subjects perceive the gap or overlap, and when they perceive it, has not been studied. We adapted the gap/overlap paradigm to study the temporal coupling of action and perception. Human subjects made saccades to targets with different TAs with respect to fixation point offset and reported whether they perceived the stimuli as separated by a gap or overlapped in time. Both saccadic and perceptual report reaction times changed in the same way as a function of TA. The TA dependencies of the time change for action and perception were very similar, suggesting a common neural substrate. -

The Complexity and Origins of the Human Eye: a Brief Study on the Anatomy, Physiology, and Origin of the Eye
Running Head: THE COMPLEX HUMAN EYE 1 The Complexity and Origins of the Human Eye: A Brief Study on the Anatomy, Physiology, and Origin of the Eye Evan Sebastian A Senior Thesis submitted in partial fulfillment of the requirements for graduation in the Honors Program Liberty University Spring 2010 THE COMPLEX HUMAN EYE 2 Acceptance of Senior Honors Thesis This Senior Honors Thesis is accepted in partial fulfillment of the requirements for graduation from the Honors Program of Liberty University. ______________________________ David A. Titcomb, PT, DPT Thesis Chair ______________________________ David DeWitt, Ph.D. Committee Member ______________________________ Garth McGibbon, M.S. Committee Member ______________________________ Marilyn Gadomski, Ph.D. Assistant Honors Director ______________________________ Date THE COMPLEX HUMAN EYE 3 Abstract The human eye has been the cause of much controversy in regards to its complexity and how the human eye came to be. Through following and discussing the anatomical and physiological functions of the eye, a better understanding of the argument of origins can be seen. The anatomy of the human eye and its many functions are clearly seen, through its complexity. When observing the intricacy of vision and all of the different aspects and connections, it does seem that the human eye is a miracle, no matter its origins. Major biological functions and processes occurring in the retina show the intensity of the eye’s intricacy. After viewing the eye and reviewing its anatomical and physiological domain, arguments regarding its origins are more clearly seen and understood. Evolutionary theory, in terms of Darwin’s thoughts, theorized fossilization of animals, computer simulations of eye evolution, and new research on supposed prior genes occurring in lower life forms leading to human life. -
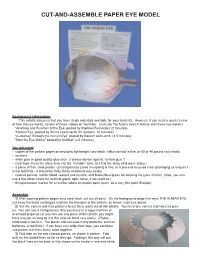
Cut-And-Assemble Paper Eye Model
CUT-AND-ASSEMBLE PAPER EYE MODEL Background information: This activity assumes that you have study materials available for your students. However, if you need a quick review of how the eye works, try one of these videos on YouTube. (Just use YouTube’s search feature with these key words.) “Anatomy and Function of the Eye: posted by Raphael Fernandez (2 minutes) “Human Eye” posted by Smart Learning for All (cartoon, 10 minutes) “A Journey Through the Human Eye” posted by Bausch and Lomb (2.5 minutes) “How the Eye Works” posted by AniMed (2.5 minutes) You will need: • copies of the pattern pages printed onto lightweight card stock (vellum bristol is fine, or 65 or 90 pound card stock) • scissors • white glue or good quality glue stick (I always advise against “school glue.”) • clear tape (I use the shiny kind, not the “invisible” kind, as I find the shiny kind more sticky.) • a piece of thin, clear plastic (a transparency [used in copiers] is fine, or a piece of recycled clear packaging as long as it is not too thick-- it should be fairly flimsy and bend very easily) • colored pencils: red for blood vessels and muscle, and brown/blue/green for coloring iris (your choice) (Also, you can use a few other colors for lacrimal gland, optic nerve, if you want to.) • thin permanent marker for a number labels on plastic parts (such as a very thin point Sharpie) Assembly: 1) After copying pattern pages onto card stock, cut out all parts. On the background page that says THE HUMAN EYE, cut away the black rectangles and trim the triangles at the bottom, as shown in picture above. -

The Evolution of Human Intelligence and the Coefficient of Additive Genetic Variance in Human Brain Size ⁎ Geoffrey F
Intelligence 35 (2007) 97–114 The evolution of human intelligence and the coefficient of additive genetic variance in human brain size ⁎ Geoffrey F. Miller a, , Lars Penke b a University of New Mexico, USA b Institut für Psychologie, Humboldt-Universität zu Berlin, Germany Received 3 November 2005; received in revised form 17 August 2006; accepted 18 August 2006 Available online 12 October 2006 Abstract Most theories of human mental evolution assume that selection favored higher intelligence and larger brains, which should have reduced genetic variance in both. However, adult human intelligence remains highly heritable, and is genetically correlated with brain size. This conflict might be resolved by estimating the coefficient of additive genetic variance (CVA) in human brain size, since CVAs are widely used in evolutionary genetics as indexes of recent selection. Here we calculate for the first time that this CVA is about 7.8, based on data from 19 recent MRI studies of adult human brain size in vivo: 11 studies on brain size means and standard deviations, and 8 studies on brain size heritabilities. This CVA appears lower than that for any other human organ volume or life-history trait, suggesting that the brain has been under strong stabilizing (average-is-better) selection. This result is hard to reconcile with most current theories of human mental evolution, which emphasize directional (more-is-better) selection for higher intelligence and larger brains. Either these theories are all wrong, or CVAs are not as evolutionarily informative as most evolutionary geneticists believe, or, as we suggest, brain size is not a very good index for understanding the evolutionary genetics of human intelligence. -

Arteriovenous Dissection in a Living Human
Vienna, Austria, 1990. Dordrecht, Holland: Klu- Table 2. Ultrasonographic Findings of 25 Well-Documented Patients wer Academic Publishers; 1993:307-311. With Cavitary Melanoma of the Uvea in English Literature 9. Frazier-Byrne S, Green RL. Intraocular tumors. In: Frazier-Byrne S, Green RL, eds. Ultrasound of the Eye and Orbit. 2nd ed. St Louis, Mo: Ultrasonographic Findings Mosby; 2002:115-190. 10. Scott CT, Holland GN, Glasgow BJ. Cavita- Solid % Mass tion in ciliary body melanoma. Am J Ophthalmol. Component Loculation Echoes in Septa in Thickness Occupied 1997;123:269-271. Source Present on USG Cavitation Cavitation by Cavity 11. Cohen PR, Rapini RP. Nevus with cyst: a re- port of 93 cases. Am J Dermatopathol. 1993; Kennedy5 NA NA NA NA NA 15:229-234. NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA Reese6 NA NA NA NA NA Arteriovenous Dissection Zakka et al7 ϩ Unilocular ϩ −NA in a Living Human Eye: Stone and Shapiro4 ϩ Unilocular ϩ −65 ϩ Unilocular ϩ −75 Clinicopathologic − Unilocular ϩ −60 Correlation ϩ Unilocular − − 30 ϩ Multilocular ϩϩ 40 Fledelius et al8 − Unilocular − − 75 Although the visual results after ar- Scott et al10 − Multilocular ϩϩ NA teriovenous dissection (AVD) seem 1,2 Lois et al2 − Unilocular ϩ −79 encouraging, its effectiveness has ϩ Unilocular − − 59 not been proved in a controlled, pro- ϩ Multilocular − ϩ 31 spective clinical trial. The role of sur- ϩ Multilocular ϩϩ 59 gical decompression itself remains ϩ − Unilocular −64 unclear,3 and little is known about − Multilocular ϩϩ 62 ϩ Unilocular ϩ −55 surgically induced nerve fiber de- ϩ Multilocular ϩϩ 38 fects. -

Root Eye Dictionary a "Layman's Explanation" of the Eye and Common Eye Problems
Welcome! This is the free PDF version of this book. Feel free to share and e-mail it to your friends. If you find this book useful, please support this project by buying the printed version at Amazon.com. Here is the link: http://www.rooteyedictionary.com/printversion Timothy Root, M.D. Root Eye Dictionary A "Layman's Explanation" of the eye and common eye problems Written and Illustrated by Timothy Root, M.D. www.RootEyeDictionary.com 1 Contents: Introduction The Dictionary, A-Z Extra Stuff - Abbreviations - Other Books by Dr. Root 2 Intro 3 INTRODUCTION Greetings and welcome to the Root Eye Dictionary. Inside these pages you will find an alphabetical listing of common eye diseases and visual problems I treat on a day-to-day basis. Ophthalmology is a field riddled with confusing concepts and nomenclature, so I figured a layman's dictionary might help you "decode" the medical jargon. Hopefully, this explanatory approach helps remove some of the mystery behind eye disease. With this book, you should be able to: 1. Look up any eye "diagnosis" you or your family has been given 2. Know why you are getting eye "tests" 3. Look up the ingredients of your eye drops. As you read any particular topic, you will see that some words are underlined. An underlined word means that I've written another entry for that particular topic. You can flip to that section if you'd like further explanation, though I've attempted to make each entry understandable on its own merit. I'm hoping this approach allows you to learn more about the eye without getting bogged down with minutia .. -

Geometry and Control of Human Eye Movements Ashoka D
170 IEEE TRANSACTIONS ON AUTOMATIC CONTROL, VOL. 52, NO. 2, FEBRUARY 2007 Geometry and Control of Human Eye Movements Ashoka D. Polpitiya, Member, IEEE, Wijesuriya P. Dayawansa, Fellow, IEEE, Clyde F. Martin, Fellow, IEEE, and Bijoy K. Ghosh, Fellow, IEEE Abstract—In this paper, we study the human oculomotor system as a simple mechanical control system. It is a well known physio- logical fact that all eye movements obey Listing’s law, which states that eye orientations form a subset consisting of rotation matrices for which the axes are orthogonal to the normal gaze direction. First, we discuss the geometry of this restricted configuration space (re- ferred to as the Listing space). Then we formulate the system as a simple mechanical control system with a holonomic constraint. We propose a realistic model with musculotendon complexes and ad- dress the question of controlling the gaze. As an example, an optimal energy control problem is formulated and numerically solved. Index Terms—Eye movements, geodesics, Hill model, Listing’s law, simple mechanical control systems. I. INTRODUCTION IOLOGICAL systems are becoming more appealing to ap- Bproaches that are commonly used in systems theory and suggest new design principles that may have important prac- tical applications in manmade systems. The principles of con- Fig. 1. Anatomy of the eye (courtesy of Yale University School of Medicine). trol theory are central to many of the key questions in biological engineering. Eye movements, for an example, reflect how the brain and the musculotendon system work in unison to control ignored but focusing on the information processing and control the gaze directions while ensuring that attitudes are confined to aspects [5], [6]. -

A Pictorial Anatomy of the Human Eye/Anophthalmic Socket: a Review for Ocularists
A Pictorial Anatomy of the Human Eye/Anophthalmic Socket: A Review for Ocularists ABSTRACT: Knowledge of human eye anatomy is obviously impor- tant to ocularists. This paper describes, with pictorial emphasis, the anatomy of the eye that ocularists generally encounter: the anophthalmic eye/socket. The author continues the discussion from a previous article: Anatomy of the Anterior Eye for Ocularists, published in 2004 in the Journal of Ophthalmic Prosthetics.1 Michael O. Hughes INTRODUCTION AND RATIONALE B.C.O. Artificial Eye Clinic of Washington, D.C. Understanding the basic anatomy of the human eye is a requirement for all Vienna, Virginia health care providers, but it is even more significant to eye care practition- ers, including ocularists. The type of eye anatomy that ocularists know, how- ever, is more abstract, as the anatomy has been altered from its natural form. Although the companion eye in monocular patients is usually within the normal range of aesthetics and function, the affected side may be distorted. While ocularists rarely work on actual eyeballs (except to cover microph- thalmic and blind, phthisical eyes using scleral cover shells), this knowledge can assist the ocularist in obtaining a naturally appearing prosthesis, and it will be of greater benefit to the patient. An easier exchange among ocularists, surgeons, and patients will result from this knowledge.1, 2, 3 RELATIONSHIPS IN THE NORMAL EYE AND ORBIT The opening between the eyelids is called the palpebral fissure. In the nor- mal eye, characteristic relationships should be recognized by the ocularist to understand the elements to be evaluated in the fellow eye. -

Rendering of Eyes for Eye-Shape Registration and Gaze Estimation
Rendering of Eyes for Eye-Shape Registration and Gaze Estimation Erroll Wood1, Tadas Baltrusaitisˇ 1, Xucong Zhang2, Yusuke Sugano2, Peter Robinson1, and Andreas Bulling2 1University of Cambridge, United Kingdom feww23,tb346,[email protected] 2Max Planck Institute for Informatics, Germany fxczhang,sugano,[email protected] Abstract—Images of the eye are key in several computer vision Rendered training images Eye-shape registration problems, such as shape registration and gaze estimation. Recent large-scale supervised methods for these problems require time- consuming data collection and manual annotation, which can be unreliable. We propose synthesizing perfectly labelled photo- realistic training data in a fraction of the time. We used computer graphics techniques to build a collection of dynamic eye-region Gaze estimation models from head scan geometry. These were randomly posed to synthesize close-up eye images for a wide range of head poses, gaze directions, and illumination conditions. We used our model’s controllability to verify the importance of realistic illumination and shape variations in eye-region training data. pitch = 15°, yaw = 9° Finally, we demonstrate the benefits of our synthesized training data (SynthesEyes) by out-performing state-of-the-art methods Fig. 1: We render a large number of photorealistic images of eyes for eye-shape registration as well as cross-dataset appearance- using a dynamic eye region model. These are used as training data based gaze estimation in the wild. for eye-shape registration and appearance-based gaze estimation. I. INTRODUCTION The eyes and their movements convey our attention and it undergoes with facial motion and eyeball rotation, and the play a role in communicating social and emotional information complex material structure of the eyeball itself. -

The Horizontal Raphe of the Human Retina and Its Watershed Zones
vision Review The Horizontal Raphe of the Human Retina and its Watershed Zones Christian Albrecht May * and Paul Rutkowski Department of Anatomy, Medical Faculty Carl Gustav Carus, TU Dresden, 74, 01307 Dresden, Germany; [email protected] * Correspondence: [email protected] Received: 24 September 2019; Accepted: 6 November 2019; Published: 8 November 2019 Abstract: The horizontal raphe (HR) as a demarcation line dividing the retina and choroid into separate vascular hemispheres is well established, but its development has never been discussed in the context of new findings of the last decades. Although factors for axon guidance are established (e.g., slit-robo pathway, ephrin-protein-receptor pathway) they do not explain HR formation. Early morphological organization, too, fails to establish a HR. The development of the HR is most likely induced by the long posterior ciliary arteries which form a horizontal line prior to retinal organization. The maintenance might then be supported by several biochemical factors. The circulation separate superior and inferior vascular hemispheres communicates across the HR only through their anastomosing capillary beds resulting in watershed zones on either side of the HR. Visual field changes along the HR could clearly be demonstrated in vascular occlusive diseases affecting the optic nerve head, the retina or the choroid. The watershed zone of the HR is ideally protective for central visual acuity in vascular occlusive diseases but can lead to distinct pathological features. Keywords: anatomy; choroid; development; human; retina; vasculature 1. Introduction The horizontal raphe (HR) was first described in the early 1800s as a horizontal demarcation line that extends from the macula to the temporal Ora dividing the temporal retinal nerve fiber layer into a superior and inferior half [1]. -

Progresses in the Development of an Anthropomorphic and Anthropometric Eye Phantom for Dosimetrical Tld Ends
2007 Inyournational Nuclear Atlantic Conference - INAC 2007 Santos, SP, Brazil, September 30 to October 5, 2007 ASSOCIAÇÃO BRASILEIRA DE ENERGIA NUCLEAR - ABEN ISBN: 978-85-99141-02-1 PROGRESSES IN THE DEVELOPMENT OF AN ANTHROPOMORPHIC AND ANTHROPOMETRIC EYE PHANTOM FOR DOSIMETRICAL TLD ENDS Luciana Batista Nogueira and Tarcísio Passos Ribeiro Campos Programa de Pós-Graduação em Ciências e Técnicas Nucleares, Departamento de Engenharia Nuclear Universidade Federal de Minas Gerais Av. Antônio Carlos, 6627 31270901, Belo Horizonte, MG [email protected] ABSTRACT This work addresses the progress in the preparation of a pair of phantom of anthropomorphic and anthropometric eye of radiological equivalence that will help futures studies in radiodosimetry, applied to radiology and radiotherapy, mainly in treatment techniques in head's area and neck, in which the eyes are more susceptible to irradiation. The eye phantom that was projected represents one of an adolescent between 14 and 16 years. The phantom is constituted of equivalent tissues (TE) and can simulate the components of the human eye in the exposition to the radiation. Through the accomplishment of an radiodiagnostic image for computer tomography with axial section, in which the phantom of eye’s object was setting up in another phantom, an anthropomorphic and anthropometric head and neck phantom developed in the research group NRI, it was verified the equivalence of the tissues, comparative to an axial section of a computer tomography of a real eyes. The improvement resumes in the production of the equivalent tissue, due to dehydration factors in function of the time that committed the equivalence anthropometric and anthropomorphic of the same. -

Literature Review of Eye Injuries and Eye Injury Risk from Blunt Objects
Brain Injuries and Biomechanics April, 2013 Literature Review of Eye Injuries and Eye Injury Risk from Blunt Objects Vanessa Alphonse and Andrew Kemper Virginia Tech – Wake Forest University Center for Injury Biomechanics ABSTRACT Eye injuries affect approximately two million people annually. Various studies that have evaluated the injury tolerance of animal and human eyes from blunt impacts are summarized herein. These studies date from the late 60s to present and illustrate various methods for testing animal and human cadaver eyes exposed to various blunt projectiles including metal rods, BBs, baseballs, and foam pieces. Experimental data from these studies have been used to develop injury risk curves to predict eye injuries based on projectile parameters such as kinetic energy and normalized energy. Recently, intraocular pressure (IOP) has been correlated to injury risk which allows eye injuries to be predicted when projectile characteristics are unknown. These experimental data have also been used to validate numerous computational and physical models of the eye used to assess injury risk from blunt loading. One such physical model is the the Facial and Ocular CountermeasUre Safety (FOCUS) headform, which is an advanced anthropomorphic device designed specifically to study facial and ocular injury. The FOCUS headform eyes have a biofidelic response to blunt impact and eye load cell data can be used to assess injury risk for eye injuries. Key Words: Projectile, Impact, Eye, Injury, Risk INTRODUCTION Annually, approximately two million people in the United States suffer from eye injuries that require treatment [1]. The most common sources of eye injuries include automobile accidents [2-13], sports-related impacts [14-17], consumer products [18-27], and military combat [28-31].