CS8092-Computer Graphics and Multimedia Notes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
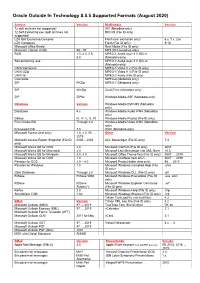
Supported Formats (August 2020)
Oracle Outside In Technology 8.5.5 Supported Formats (August 2020) Archive Version Multimedia Version 7z split archives not supported) AVI (Metadata only) 7z Self Extracting exe (split archives not DICOM (File ID only) supported) LZA Self Extracting Compres Flash (text extraction only) 6.x, 7.x, Lite LZH Compress Flash (File ID only) 9,10 Microsoft Office Binder Real Media (File ID only) Microsoft Cabinet (CAB) 95 – 97 MP3 (ID3 metadata only) RAR 1.5, 2.0, 2.9, MPEG-1 Audio layer 3 V ID3 v1 5.0 (Metadata only) Self-extracting .exe MPEG-1 Audio layer 3 V ID3 v2 (Metadata only) UNIX Compress MPEG-1 Video V 2 (File ID only) UNIX GZip MPEG-1 Video V 3 (File ID only) UNIX tar MPEG-2 Audio (File ID only) Uuencode MPEG-4 (Metadata only) ZIP PKZip MPEG-7 (Metadata only) ZIP WinZip QuickTime (Metadata only) ZIP ZIP64 Windows Media ASF (Metadata only) Database Version Windows Media DVR-MS (Metadata only) DataEase 4.x Windows Media Audio WMA (Metadata only) DBase III, IV, V, X, X1 Windows Media Playlist (File ID only) First Choice DB Through 3.0 Windows Media Video WMV (Metadata only) Framework DB 3.0 WAV (Metadata only) Microsoft Access (text only) 1.0, 2.0, 95 … Other Version 2019 Microsoft Access Report Snapshot (File ID 2000 – 2003 AOL Messenger (File ID only) 7.3 only) Microsoft Works DB for DOS 2.0 Microsoft InfoPath (File ID only) 2007 Microsoft Works DB for Macintosh 2.0 Microsoft Live Messenger (via XML filter) 10.0 Microsoft Works DB for Windows 3.0, 4.0 Microsoft Office Theme files (File ID only) 2007 … 2019 Microsoft Works DB for DOS -

Encapsulated Postscript File Format Specification
® Encapsulated PostScript File Format Specification ®® Adobe Developer Support Version 3.0 1 May 1992 Adobe Systems Incorporated Adobe Developer Technologies 345 Park Avenue San Jose, CA 95110 http://partners.adobe.com/ PN LPS5002 Copyright 1985–1988, 1990, 1992 by Adobe Systems Incorporated. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written consent of the publisher. Any software referred to herein is furnished under license and may only be used or copied in accordance with the terms of such license. PostScript is a registered trademark of Adobe Systems Incorporated. All instances of the name PostScript in the text are references to the PostScript language as defined by Adobe Systems Incorpo- rated unless otherwise stated. The name PostScript also is used as a product trademark for Adobe Sys- tems’ implementation of the PostScript language interpreter. Any references to a “PostScript printer,” a “PostScript file,” or a “PostScript driver” refer to printers, files, and driver programs (respectively) which are written in or support the PostScript language. The sentences in this book that use “PostScript language” as an adjective phrase are so constructed to rein- force that the name refers to the standard language definition as set forth by Adobe Systems Incorpo- rated. PostScript, the PostScript logo, Display PostScript, Adobe, the Adobe logo, Adobe Illustrator, Tran- Script, Carta, and Sonata are trademarks of Adobe Systems Incorporated registered in the U.S.A. and other countries. Adobe Garamond and Lithos are trademarks of Adobe Systems Incorporated. -

A Forensic Database for Digital Audio, Video, and Image Media
THE “DENVER MULTIMEDIA DATABASE”: A FORENSIC DATABASE FOR DIGITAL AUDIO, VIDEO, AND IMAGE MEDIA by CRAIG ANDREW JANSON B.A., University of Richmond, 1997 A thesis submitted to the Faculty of the Graduate School of the University of Colorado Denver in partial fulfillment of the requirements for the degree of Master of Science Recording Arts Program 2019 This thesis for the Master of Science degree by Craig Andrew Janson has been approved for the Recording Arts Program by Catalin Grigoras, Chair Jeff M. Smith Cole Whitecotton Date: May 18, 2019 ii Janson, Craig Andrew (M.S., Recording Arts Program) The “Denver Multimedia Database”: A Forensic Database for Digital Audio, Video, and Image Media Thesis directed by Associate Professor Catalin Grigoras ABSTRACT To date, there have been multiple databases developed for use in many forensic disciplines. There are very large and well-known databases like CODIS (DNA), IAFIS (fingerprints), and IBIS (ballistics). There are databases for paint, shoeprint, glass, and even ink; all of which catalog and maintain information on all the variations of their specific subject matter. Somewhat recently there was introduced the “Dresden Image Database” which is designed to provide a digital image database for forensic study and contains images that are generic in nature, royalty free, and created specifically for this database. However, a central repository is needed for the collection and study of digital audios, videos, and images. This kind of database would permit researchers, students, and investigators to explore the data from various media and various sources, compare an unknown with knowns with the possibility of discovering the likely source of the unknown. -

Computer Networks 6
KONGUNADU ARTS AND SCIENCE COLLEGE (AUTONOMOUS) [Re-accredited by NAAC with ‘A’ Grade 3.64 CGPA-(3rd Cycle)] Coimbatore – 641 029 DEPARTMENT OF COMPUTER TECHNOLOGY KASC-Computer Technology QUESTION BANKS SUBJECTS S.No Name of the Subject 1. C Programming 2. Client Server Techniques 3. Cloud Computing 4. Computer Installation and Servicing 5. Computer Networks 6. Data Mining 7. Data Structure 8. Digital Fundamentals and Computer Organization 9. Information Security 10. Java Programming 11. Open Source Technology – Linux 12. Network Security 13. Object Oriented Programming with C++ 14. Operating System 15. Relational Database Management Systems 16. Software Engineering and Testing 17. Web Programming KASC-Computer Technology KONGUNADU ARTS AND SCIENCE COLLEGE (AUTONOMOUS) [Re-accredited by NAAC with ‘A’ Grade 3.64 CGPA (3rd Cycle)] [College of Excellence (UGC)] Coimbatore – 641 029 DEPARTMENT OF COMPUTER TECHNOLOGY QUESTION BANK Subject Code: (18UCT101) Title of the Paper: C PROGRAMMING KASC-Computer Technology NOVEMBER 2018 1 Prepared by Dr. R. Umagandhi MCA., M.Phil., Ph.D. Associate Professor and Head Department of Computer Technology Kongunadu Arts & Science College (Autonomous) Coimbatore-29. KASC-Computer Technology 2 INDEX S.NO CONTENT PAGE NO. 1 Section A 4 2 Section B 9 3 Section C 10 4 Key for Section A 12 KASC-Computer Technology 3 SECTION A 1. The statement begins with /* and ends with */ is called a) online b) offline c) comment d) executable 2. Which operator is applied on 2 operands? a) unary b) binary c) ternary d) special 3. The hexadecimal integer begins with a) Oh b)0x c)0o d) \0 4. -

Multimedia Systems DCAP303
Multimedia Systems DCAP303 MULTIMEDIA SYSTEMS Copyright © 2013 Rajneesh Agrawal All rights reserved Produced & Printed by EXCEL BOOKS PRIVATE LIMITED A-45, Naraina, Phase-I, New Delhi-110028 for Lovely Professional University Phagwara CONTENTS Unit 1: Multimedia 1 Unit 2: Text 15 Unit 3: Sound 38 Unit 4: Image 60 Unit 5: Video 102 Unit 6: Hardware 130 Unit 7: Multimedia Software Tools 165 Unit 8: Fundamental of Animations 178 Unit 9: Working with Animation 197 Unit 10: 3D Modelling and Animation Tools 213 Unit 11: Compression 233 Unit 12: Image Format 247 Unit 13: Multimedia Tools for WWW 266 Unit 14: Designing for World Wide Web 279 SYLLABUS Multimedia Systems Objectives: To impart the skills needed to develop multimedia applications. Students will learn: z how to combine different media on a web application, z various audio and video formats, z multimedia software tools that helps in developing multimedia application. Sr. No. Topics 1. Multimedia: Meaning and its usage, Stages of a Multimedia Project & Multimedia Skills required in a team 2. Text: Fonts & Faces, Using Text in Multimedia, Font Editing & Design Tools, Hypermedia & Hypertext. 3. Sound: Multimedia System Sounds, Digital Audio, MIDI Audio, Audio File Formats, MIDI vs Digital Audio, Audio CD Playback. Audio Recording. Voice Recognition & Response. 4. Images: Still Images – Bitmaps, Vector Drawing, 3D Drawing & rendering, Natural Light & Colors, Computerized Colors, Color Palletes, Image File Formats, Macintosh & Windows Formats, Cross – Platform format. 5. Animation: Principle of Animations. Animation Techniques, Animation File Formats. 6. Video: How Video Works, Broadcast Video Standards: NTSC, PAL, SECAM, ATSC DTV, Analog Video, Digital Video, Digital Video Standards – ATSC, DVB, ISDB, Video recording & Shooting Videos, Video Editing, Optimizing Video files for CD-ROM, Digital display standards. -

Gaussplot 8.0.Pdf
GAUSSplotTM Professional Graphics Aptech Systems, Inc. — Mathematical and Statistical System Information in this document is subject to change without notice and does not represent a commitment on the part of Aptech Systems, Inc. The software described in this document is furnished under a license agreement or nondisclosure agreement. The software may be used or copied only in accordance with the terms of the agreement. The purchaser may make one copy of the software for backup purposes. No part of this manual may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, for any purpose other than the purchaser’s personal use without the written permission of Aptech Systems, Inc. c Copyright 2005-2006 by Aptech Systems, Inc., Maple Valley, WA. All Rights Reserved. ENCSA Hierarchical Data Format (HDF) Software Library and Utilities Copyright (C) 1988-1998 The Board of Trustees of the University of Illinois. All rights reserved. Contributors include National Center for Supercomputing Applications (NCSA) at the University of Illinois, Fortner Software (Windows and Mac), Unidata Program Center (netCDF), The Independent JPEG Group (JPEG), Jean-loup Gailly and Mark Adler (gzip). Bmptopnm, Netpbm Copyright (C) 1992 David W. Sanderson. Dlcompat Copyright (C) 2002 Jorge Acereda, additions and modifications by Peter O’Gorman. Ppmtopict Copyright (C) 1990 Ken Yap. GAUSSplot, GAUSS and GAUSS Engine are trademarks of Aptech Systems, Inc. Tecplot RS, Tecplot, Preplot, Framer and Amtec are registered trademarks or trade- marks of Amtec Engineering, Inc. Encapsulated PostScript, FrameMaker, PageMaker, PostScript, Premier–Adobe Sys- tems, Incorporated. Ghostscript–Aladdin Enterprises. Linotronic, Helvetica, Times– Allied Corporation. -

Data Format Guide
Data Format Guide Tecplot, Inc. Bellevue, WA 2006 COPYRIGHT NOTICE Tecplot 360TMData Format Guide is for use with Tecplot 360TM 2006. Copyright © 1988-2006 Tecplot, Inc. All rights reserved worldwide. Except for personal use, this manual may not be reproduced, trans- mitted, transcribed, stored in a retrieval system, or translated in any form, in whole or in part, without the express written permission of Tecplot, Inc., 3535 Factoria Blvd., Ste 550, Bellevue, Washington, 98006, U.S.A. The software discussed in this documentation and the documentation itself are furnished under license for utilization and duplication only according to the license terms. The copyright for the software is held by Tecplot, Inc. Documentation is provided for information only. It is subject to change without notice. It should not be interpreted as a commitment by Tecplot, Inc. Tecplot, Inc. assumes no liabil- ity or responsibility for documentation errors or inaccuracies. Tecplot, Inc PO Box 52708 Bellevue, WA 98015-2708 U.S.A. Tel: 1.800.763.7005 (within the U.S. or Canada), 00 1 (425)653-1200 (internationally) email: [email protected], [email protected] Questions, comments or concerns regarding this documentation: [email protected] For more information, visit http://www.tecplot.com THIRD PARTY SOFTWARE COPYRIGHT NOTICES ENCSA Hierarchical Data Format (HDF) Software Library and Utilities © 1988-1998 The Board of Trustees of the University of Illi- nois. All rights reserved. Contributors include National Center for Supercomputing Applications (NCSA) at the University of Illinois, Fortner Software (Windows and Mac), Unidata Program Center (netCDF), The Independent JPEG Group (JPEG), Jean-loup Gailly and Mark Adler (gzip). -

Introduction to Video Databases
1 INTRODUCTION TO VIDEO DATABASES Oge Marques and Borko Furht Department of Computer Science and Engineering Florida Atlantic University Boca Raton, FL, USA [email protected], [email protected] 1. INTRODUCTION The field of distributed multimedia systems has experienced an extraordinary growth during the last decade. Among the many visible aspects of the increasing interest in this area is the creation of huge digital libraries accessible to users worldwide. These large and complex multimedia databases must store all types of multimedia data, e.g., text, images, animations, graphs, drawings, audio, and video clips. Video information plays a central role in such systems, and consequently, the design and implementation of video database systems has become a major topic of interest. The amount of video information stored in archives worldwide is huge. Conservative estimates state that there are more than 6 million hours of video already stored and this number grows at a rate of about 10 percent a year [1]. Projections estimate that by the end of 2010, 50 percent of the total digital data stored worldwide will be video and rich media [5]. Significant efforts have been spent in recent years to make the process of video archiving and retrieval faster, safer, more reliable and accessible to users anywhere in the world. Progress in video digitization and compression, together with advances in storage media, have made the task of storing and retrieving raw video data much easier. Evolution of computer networks and the growth and popularity of the Internet have made it possible to access these data from remote locations. -

Introduction
Introduction: Multimedia Data refers to data such as text, numeric, images, video, audio, graphical, temporal, relational and categorical data. Multimedia data mining refers to pattern discovery, rule extraction and knowledge acquisition from multimedia database [9]. Multimedia database systems are increasingly common owing to the popular use of audio video equipment, digital cameras, CD-ROMs, and the Internet [12]. These are typically the elements or the building blocks of generalized multimedia environments, platforms, or integrating tools [1]. The main objective of multimedia data mining is the idea of mining data in different kinds of information. Current data mining tools operate on structured data, the kind of data that resides in large relational databases whereas data in the multimedia databases are semi- structured or unstructured. Often compared with data mining, multimedia mining reaches much higher complexity resulting from: (i) The huge volume of data, (ii) The variability and heterogeneity of the multimedia data (e.g. diversity of sensors, time or conditions of acquisition etc.) and (iii) The multimedia content’s meaning is subjective [9]. Multimedia generally gives a lot of data on each entity, but not the same data for each entity [18]. The multimedia is classified in to two categories: (i) Static media such as text, graphics, and images and (ii) Dynamic media such as animation, music, audio, speech, and video. Figure 4 illustrates multimedia data mining, in particular, various aspects of multimedia data mining [10]. Text Mining: Text Mining also referred as text data mining and it is used to find meaningful information from the unstructured texts that are from various sources. -

FILE FORMATS Darry D
WordPerfect FILE FORMATS Darry D In WordPerfect, when you select File > Open, you are taken to “My Documents.” However, that does not mean that you can open all the files that are stored there. Here are the programs that can open a file, based upon its file extension. A file extension is a string of characters beginning with a period and followed by one to three letters; the optional second part of a PC computer filename; “most applications provide extensions for the files they create”; for example, WordPerfect uses the file extension “wpd”. o .cgm — CGM (Computer Graphics Metafile) was a once-standard for- mat for interchanging graphics images. CGM stores images primarily in vector graphics, but also provides a raster format. Earlier GDM and VDM formats have been merged into CGM. There are many non-standard varieties of CGM in use. Usually found in the “My Pictures” folder of “My Documents” or some other graphics folder (such as “Art”), it can be inserted into WordPerfect 9 using Insert > Graphics > From File (from the MenuBar). o .cvs — comma-delimited file (a database with items separated by commas); this one can be opened only by importing it into the Outlook Express Address Book. o .doc — Created with MS Word; WordPerfect can open it. o .eml — Email created by Outlook Express or Outlook either of which can open it. Http://DarryD.com (5 November 2020) Page 1 of 4 WORDPERFECT 5 NOVEMBER 2020 o .htm —. It is the file extension of HTML, created by programs like Microsoft FrontPage and others, including WordPerfect. -

A Review on Multimedia Databases
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 3, ISSUE 10, OCTOBER 2014 ISSN 2277-8616 A Review On Multimedia Databases Amna Riaz, Imran Ashraf, Gulshan Aslam Abstract: This paper describes effects of Multi-media Database in learning & technology world in broad way and also shows that how positively it enhances the database and technology. Multimedia database is a backbone support and works effectively for large amount of good quality multimedia data. In comparison to traditional database, multimedia database has a strong effect due to its ability of handling various data types at a single platform. This paper describes tremendous innovations, applications and fabulous use of multimedia database e.g. creating virtual museum ,3D MURALE and MPGE 7, Supports English Distance Learning, Smelling Objects, 3D Crime Scene Representation and Analysis, GIS driven Internet Multimedia Databases, Trade mark registration, intelligent agent with MMDB etc. Index Terms: Database (DB), Database Management System(DBMS), Multimedia Database (MMDB), Computer-aided drafting programs (CAD), Geographical Information Systems: (GIS), Electronic Distance Measurement (EDM), Multimedia indexing framework (MIF), Computer-aided drafting programs( CAD), Audio-Video-Smell-System (AViSS) ———————————————————— 1 INTRODUCTION Multimedia database contains static, dynamic and dimensional The organized collection of related data is called database [4]. media. It consists of three types of authentication; multimedia Database provides the facilities such as data sharing; reduced database, identification multimedia database and biometrics redundancy and inconsistency, transaction support, integrity, multimedia database. MMDB has emerged the non- audio- security, balance conflicts and enforced standards [57]. Two visual digital media that will meet the challenges of storage, main types of database are centralized database and retrieval and presentation [5]. -

12. Optical Data Storage
12. Optical data storage 12.1 Theory of color RGB additive color model B B Blue Magenta (0.6, 0.2, 1) (0,0,1) (1,0,1) Gray shades Cyan (g,g,g) (0,1,1) White (1,1,1) (0.6, 1, 0.7) R R Black Red (0,0,0) (1,0,0) G Green (0,1,0) (1, 0.7, 0.1) Yellow (1,1,0) G The RGB color model converts the additive color mixing system into a digital system, in which any color is represented by a point in a color tridimensional space and thus by a three coordinates vector. The coordinates are composed of the respective proportions of the primary light colors (Red, Green, Blue). The RGB model is often used by software as it requires no conversion in order to display colors on a computer screen. 169 CMY subtractive color model Y Y Yellow Green (0, 0.3, 0.9) (0,0,1) (1,0,1) Gray shades Red (g,g,g) (0,1,1) Black (1,1,1) C (0.4, 0, 0.3) C White Cyan (0,0,0) (1,0,0) M Magenta (0,1,0) (0.4, 0.8, 0) Blue (1,1,0) M The CMY color model corresponds to the subtractive color mixing system. The coordinates of a point in this color space are composed of the respective proportions of the primary filter colors (Cyan, Magenta, Yellow). The CMY model is used whenever a colored document is printed. The conversion RGB and CMY models can be written as follows: For the orange point, for example: 170 HSV color model V Green Yellow 120° 60° (37°, 0.9, 1) White H 1.0 S Cyan Red 180° 0° V Blue Magenta 240° 300° Hue is given in polar coordinate.