Precision Measurement of Charged Pion and Kaon Multiplicities in E+E− Annihilation at Q = 10.52 Gev
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
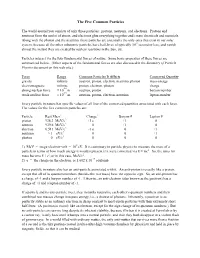
The Five Common Particles
The Five Common Particles The world around you consists of only three particles: protons, neutrons, and electrons. Protons and neutrons form the nuclei of atoms, and electrons glue everything together and create chemicals and materials. Along with the photon and the neutrino, these particles are essentially the only ones that exist in our solar system, because all the other subatomic particles have half-lives of typically 10-9 second or less, and vanish almost the instant they are created by nuclear reactions in the Sun, etc. Particles interact via the four fundamental forces of nature. Some basic properties of these forces are summarized below. (Other aspects of the fundamental forces are also discussed in the Summary of Particle Physics document on this web site.) Force Range Common Particles It Affects Conserved Quantity gravity infinite neutron, proton, electron, neutrino, photon mass-energy electromagnetic infinite proton, electron, photon charge -14 strong nuclear force ≈ 10 m neutron, proton baryon number -15 weak nuclear force ≈ 10 m neutron, proton, electron, neutrino lepton number Every particle in nature has specific values of all four of the conserved quantities associated with each force. The values for the five common particles are: Particle Rest Mass1 Charge2 Baryon # Lepton # proton 938.3 MeV/c2 +1 e +1 0 neutron 939.6 MeV/c2 0 +1 0 electron 0.511 MeV/c2 -1 e 0 +1 neutrino ≈ 1 eV/c2 0 0 +1 photon 0 eV/c2 0 0 0 1) MeV = mega-electron-volt = 106 eV. It is customary in particle physics to measure the mass of a particle in terms of how much energy it would represent if it were converted via E = mc2. -

Quantum Field Theory*
Quantum Field Theory y Frank Wilczek Institute for Advanced Study, School of Natural Science, Olden Lane, Princeton, NJ 08540 I discuss the general principles underlying quantum eld theory, and attempt to identify its most profound consequences. The deep est of these consequences result from the in nite number of degrees of freedom invoked to implement lo cality.Imention a few of its most striking successes, b oth achieved and prosp ective. Possible limitation s of quantum eld theory are viewed in the light of its history. I. SURVEY Quantum eld theory is the framework in which the regnant theories of the electroweak and strong interactions, which together form the Standard Mo del, are formulated. Quantum electro dynamics (QED), b esides providing a com- plete foundation for atomic physics and chemistry, has supp orted calculations of physical quantities with unparalleled precision. The exp erimentally measured value of the magnetic dip ole moment of the muon, 11 (g 2) = 233 184 600 (1680) 10 ; (1) exp: for example, should b e compared with the theoretical prediction 11 (g 2) = 233 183 478 (308) 10 : (2) theor: In quantum chromo dynamics (QCD) we cannot, for the forseeable future, aspire to to comparable accuracy.Yet QCD provides di erent, and at least equally impressive, evidence for the validity of the basic principles of quantum eld theory. Indeed, b ecause in QCD the interactions are stronger, QCD manifests a wider variety of phenomena characteristic of quantum eld theory. These include esp ecially running of the e ective coupling with distance or energy scale and the phenomenon of con nement. -

First Determination of the Electric Charge of the Top Quark
First Determination of the Electric Charge of the Top Quark PER HANSSON arXiv:hep-ex/0702004v1 1 Feb 2007 Licentiate Thesis Stockholm, Sweden 2006 Licentiate Thesis First Determination of the Electric Charge of the Top Quark Per Hansson Particle and Astroparticle Physics, Department of Physics Royal Institute of Technology, SE-106 91 Stockholm, Sweden Stockholm, Sweden 2006 Cover illustration: View of a top quark pair event with an electron and four jets in the final state. Image by DØ Collaboration. Akademisk avhandling som med tillst˚and av Kungliga Tekniska H¨ogskolan i Stock- holm framl¨agges till offentlig granskning f¨or avl¨aggande av filosofie licentiatexamen fredagen den 24 november 2006 14.00 i sal FB54, AlbaNova Universitets Center, KTH Partikel- och Astropartikelfysik, Roslagstullsbacken 21, Stockholm. Avhandlingen f¨orsvaras p˚aengelska. ISBN 91-7178-493-4 TRITA-FYS 2006:69 ISSN 0280-316X ISRN KTH/FYS/--06:69--SE c Per Hansson, Oct 2006 Printed by Universitetsservice US AB 2006 Abstract In this thesis, the first determination of the electric charge of the top quark is presented using 370 pb−1 of data recorded by the DØ detector at the Fermilab Tevatron accelerator. tt¯ events are selected with one isolated electron or muon and at least four jets out of which two are b-tagged by reconstruction of a secondary decay vertex (SVT). The method is based on the discrimination between b- and ¯b-quark jets using a jet charge algorithm applied to SVT-tagged jets. A method to calibrate the jet charge algorithm with data is developed. A constrained kinematic fit is performed to associate the W bosons to the correct b-quark jets in the event and extract the top quark electric charge. -

TASI 2008 Lectures: Introduction to Supersymmetry And
TASI 2008 Lectures: Introduction to Supersymmetry and Supersymmetry Breaking Yuri Shirman Department of Physics and Astronomy University of California, Irvine, CA 92697. [email protected] Abstract These lectures, presented at TASI 08 school, provide an introduction to supersymmetry and supersymmetry breaking. We present basic formalism of supersymmetry, super- symmetric non-renormalization theorems, and summarize non-perturbative dynamics of supersymmetric QCD. We then turn to discussion of tree level, non-perturbative, and metastable supersymmetry breaking. We introduce Minimal Supersymmetric Standard Model and discuss soft parameters in the Lagrangian. Finally we discuss several mech- anisms for communicating the supersymmetry breaking between the hidden and visible sectors. arXiv:0907.0039v1 [hep-ph] 1 Jul 2009 Contents 1 Introduction 2 1.1 Motivation..................................... 2 1.2 Weylfermions................................... 4 1.3 Afirstlookatsupersymmetry . .. 5 2 Constructing supersymmetric Lagrangians 6 2.1 Wess-ZuminoModel ............................... 6 2.2 Superfieldformalism .............................. 8 2.3 VectorSuperfield ................................. 12 2.4 Supersymmetric U(1)gaugetheory ....................... 13 2.5 Non-abeliangaugetheory . .. 15 3 Non-renormalization theorems 16 3.1 R-symmetry.................................... 17 3.2 Superpotentialterms . .. .. .. 17 3.3 Gaugecouplingrenormalization . ..... 19 3.4 D-termrenormalization. ... 20 4 Non-perturbative dynamics in SUSY QCD 20 4.1 Affleck-Dine-Seiberg -

13 the Dirac Equation
13 The Dirac Equation A two-component spinor a χ = b transforms under rotations as iθn J χ e− · χ; ! with the angular momentum operators, Ji given by: 1 Ji = σi; 2 where σ are the Pauli matrices, n is the unit vector along the axis of rotation and θ is the angle of rotation. For a relativistic description we must also describe Lorentz boosts generated by the operators Ki. Together Ji and Ki form the algebra (set of commutation relations) Ki;Kj = iεi jkJk − ε Ji;Kj = i i jkKk ε Ji;Jj = i i jkJk 1 For a spin- 2 particle Ki are represented as i Ki = σi; 2 giving us two inequivalent representations. 1 χ Starting with a spin- 2 particle at rest, described by a spinor (0), we can boost to give two possible spinors α=2n σ χR(p) = e · χ(0) = (cosh(α=2) + n σsinh(α=2))χ(0) · or α=2n σ χL(p) = e− · χ(0) = (cosh(α=2) n σsinh(α=2))χ(0) − · where p sinh(α) = j j m and Ep cosh(α) = m so that (Ep + m + σ p) χR(p) = · χ(0) 2m(Ep + m) σ (pEp + m p) χL(p) = − · χ(0) 2m(Ep + m) p 57 Under the parity operator the three-moment is reversed p p so that χL χR. Therefore if we 1 $ − $ require a Lorentz description of a spin- 2 particles to be a proper representation of parity, we must include both χL and χR in one spinor (note that for massive particles the transformation p p $ − can be achieved by a Lorentz boost). -

Lecture 1 Charge and Coulomb's
LECTURE 1 CHARGE AND COULOMB’S LAW Lecture 1 2 ¨ Reading chapter 21-1 to 21-3. ¤ Electrical charge n Positive and negative charge n Charge quantization and conservation ¤ Conductors and insulators ¤ Induction ¤ Coulomb’s law Demo: 1 3 ¨ Charged rods on turntable ¤ Charge can be positive or negative. ¤ Like charges repel each other. ¤ Opposite charges attract each other. Charge quantization 4 ¨ The unit of charge is the coulomb (C). ¨ Charge is quantized which means it always occurs in an integer multiple of e = 1.602×10-19 C. ¨ Each electron has a charge of negative e. ¨ Each proton has a charge of positive e. ¨ Point of interest: ¤ Quarks can have smaller charges than an electron but they do not occur as free particles. ¤ The charge of an up quark is +2/3 e. ¤ The charge of a down quark is -1/3 e. ¤ A proton consists of 2 up quarks and 1 down quark, total charge +e. ¤ A neutron consists of 1 up quark and 2 down quarks, total charge 0. Conservation of charge 5 ¨ The total charge is conserved. ¨ When we charge a rod, we move electrons from one place to another leaving a positively charged object (where we removed electrons) and an equal magnitude negatively charged object (where we added electrons). ¨ Point of interest: + ¤ Detecting anti-neutrinos:νe + p → n + e ¤ The proton (p) and positron (e+) have the same positive charge. ¤ The anti-neutrino ( ν e ) and neutron (n) are not charged. Example: 1 6 ¨ How many electrons must be transferred to a body to result in a charge of q = 125 nC? Conductors and insulators 7 ¨ In a conductor charged particles are free to move within the object. -

Color Screening in Quantum Chromodynamics Arxiv
Color Screening in Quantum Chromodynamics Alexei Bazavov, Johannes H. Weber Department of Computational Mathematics, Science and Engineering and Department of Physics and Astronomy, Michigan State University, East Lansing, MI 48824, USA October 6, 2020 Abstract We review lattice studies of the color screening in the quark-gluon plasma. We put the phenomena related to the color screening into the context of similar aspects of other physical systems (electromag- netic plasma or cold nuclear matter). We discuss the onset of the color screening and its signature and significance in the QCD transi- tion region, and elucidate at which temperature and to which extent the weak-coupling picture based on hard thermal loop expansion, po- tential nonrelativistic QCD, or dimensionally-reduced QCD quantita- tively captures the key properties of the color screening. We discuss the different regimes pertaining to the color screening and thermal arXiv:2010.01873v1 [hep-lat] 5 Oct 2020 dissociation of the static quarks in depth for various spatial correla- tion functions that are studied on the lattice, and clarify the status of their asymptotic screening masses. We finally discuss the screening correlation functions of dynamical mesons with a wide range of flavor and spin content, and how they conform with expectations for low- and high-temperature behavior. 1 Contents 1 Introduction3 2 Field theoretical foundations7 2.1 Partition function and Lagrangian . .7 2.2 Finite temperature field theory . 11 2.3 Lattice regularization . 14 2.4 Renormalization and weak coupling . 17 2.5 Light quarks . 19 2.6 Heavy quarks . 21 2.7 Implementation of QCD on the lattice . -

Introduction to Supersymmetry
Introduction to Supersymmetry Pre-SUSY Summer School Corpus Christi, Texas May 15-18, 2019 Stephen P. Martin Northern Illinois University [email protected] 1 Topics: Why: Motivation for supersymmetry (SUSY) • What: SUSY Lagrangians, SUSY breaking and the Minimal • Supersymmetric Standard Model, superpartner decays Who: Sorry, not covered. • For some more details and a slightly better attempt at proper referencing: A supersymmetry primer, hep-ph/9709356, version 7, January 2016 • TASI 2011 lectures notes: two-component fermion notation and • supersymmetry, arXiv:1205.4076. If you find corrections, please do let me know! 2 Lecture 1: Motivation and Introduction to Supersymmetry Motivation: The Hierarchy Problem • Supermultiplets • Particle content of the Minimal Supersymmetric Standard Model • (MSSM) Need for “soft” breaking of supersymmetry • The Wess-Zumino Model • 3 People have cited many reasons why extensions of the Standard Model might involve supersymmetry (SUSY). Some of them are: A possible cold dark matter particle • A light Higgs boson, M = 125 GeV • h Unification of gauge couplings • Mathematical elegance, beauty • ⋆ “What does that even mean? No such thing!” – Some modern pundits ⋆ “We beg to differ.” – Einstein, Dirac, . However, for me, the single compelling reason is: The Hierarchy Problem • 4 An analogy: Coulomb self-energy correction to the electron’s mass A point-like electron would have an infinite classical electrostatic energy. Instead, suppose the electron is a solid sphere of uniform charge density and radius R. An undergraduate problem gives: 3e2 ∆ECoulomb = 20πǫ0R 2 Interpreting this as a correction ∆me = ∆ECoulomb/c to the electron mass: 15 0.86 10− meters m = m + (1 MeV/c2) × . -

Pion Charge Exchange Cross Section on Liquid Argon
W&M ScholarWorks Undergraduate Honors Theses Theses, Dissertations, & Master Projects 4-2018 Pion Charge Exchange Cross Section on Liquid Argon Kevin Nelson Follow this and additional works at: https://scholarworks.wm.edu/honorstheses Part of the Elementary Particles and Fields and String Theory Commons Recommended Citation Nelson, Kevin, "Pion Charge Exchange Cross Section on Liquid Argon" (2018). Undergraduate Honors Theses. Paper 1246. https://scholarworks.wm.edu/honorstheses/1246 This Honors Thesis is brought to you for free and open access by the Theses, Dissertations, & Master Projects at W&M ScholarWorks. It has been accepted for inclusion in Undergraduate Honors Theses by an authorized administrator of W&M ScholarWorks. For more information, please contact [email protected]. π− Charge-Exchange Cross Section on Liquid Argon A thesis submitted in partial fulfillment of the requirement for the degree of Bachelor of Science with Honors in Physics from the College of William and Mary in Virginia, by Kevin M. Nelson Accepted for Honors Advisor: Prof. Michael Kordosky Prof. Irina Novikova Prof. Michael Kordosky Prof. Evgenia Smirni Williamsburg, Virginia May 2017 Contents Acknowledgments v List of Figures vi List of Tables x Abstract xi 1 Introduction 1 1.1 Motivation: Neutrino Oscillations . .1 1.2 DUNE and the future of LArTPCs . .2 2 Theory 3 2.1 The Standard Model of Particle Physics . .3 2.2 Neutrino Oscillation . .3 2.3 Neutrinos and Dark Matter . .4 2.4 Energy Deposition in Matter . .6 2.5 Cross Sections . .7 2.6 Relativistic Mechanics . .8 2.7 Machine Learning . .9 2.7.1 Decision Trees . 10 2.7.2 Boosting . -

Introduction to Flavour Physics
Introduction to flavour physics Y. Grossman Cornell University, Ithaca, NY 14853, USA Abstract In this set of lectures we cover the very basics of flavour physics. The lec- tures are aimed to be an entry point to the subject of flavour physics. A lot of problems are provided in the hope of making the manuscript a self-study guide. 1 Welcome statement My plan for these lectures is to introduce you to the very basics of flavour physics. After the lectures I hope you will have enough knowledge and, more importantly, enough curiosity, and you will go on and learn more about the subject. These are lecture notes and are not meant to be a review. In the lectures, I try to talk about the basic ideas, hoping to give a clear picture of the physics. Thus many details are omitted, implicit assumptions are made, and no references are given. Yet details are important: after you go over the current lecture notes once or twice, I hope you will feel the need for more. Then it will be the time to turn to the many reviews [1–10] and books [11, 12] on the subject. I try to include many homework problems for the reader to solve, much more than what I gave in the actual lectures. If you would like to learn the material, I think that the problems provided are the way to start. They force you to fully understand the issues and apply your knowledge to new situations. The problems are given at the end of each section. -

The Taste of New Physics: Flavour Violation from Tev-Scale Phenomenology to Grand Unification Björn Herrmann
The taste of new physics: Flavour violation from TeV-scale phenomenology to Grand Unification Björn Herrmann To cite this version: Björn Herrmann. The taste of new physics: Flavour violation from TeV-scale phenomenology to Grand Unification. High Energy Physics - Phenomenology [hep-ph]. Communauté Université Grenoble Alpes, 2019. tel-02181811 HAL Id: tel-02181811 https://tel.archives-ouvertes.fr/tel-02181811 Submitted on 12 Jul 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. The taste of new physics: Flavour violation from TeV-scale phenomenology to Grand Unification Habilitation thesis presented by Dr. BJÖRN HERRMANN Laboratoire d’Annecy-le-Vieux de Physique Théorique Communauté Université Grenoble Alpes Université Savoie Mont Blanc – CNRS and publicly defended on JUNE 12, 2019 before the examination committee composed of Dr. GENEVIÈVE BÉLANGER CNRS Annecy President Dr. SACHA DAVIDSON CNRS Montpellier Examiner Prof. ALDO DEANDREA Univ. Lyon Referee Prof. ULRICH ELLWANGER Univ. Paris-Saclay Referee Dr. SABINE KRAML CNRS Grenoble Examiner Prof. FABIO MALTONI Univ. Catholique de Louvain Referee July 12, 2019 ii “We shall not cease from exploration, and the end of all our exploring will be to arrive where we started and know the place for the first time.” T. -

The Question of Charge and of Mass
The question of charge and of mass. Voicu Dolocan Faculty of Physics, University of Bucharest, Bucharest, Romania Abstract. There are two long –range forces in the Universe, electromagnetism and gravity. We have found a general expression for the energy of interaction in these cases, αћc/r, where α is the fine structure constant and r is the distance between the two particles. In the case of electromagnetic interaction we have 2 αћc = e /4πεo, where e is the gauge charge, which is the elementary electron charge. In the case of the gravitational interaction we have αћc = GM2, where M = 1.85×10-9 kg is the gauge mass of the particle. This is a giant particle. A system of like charged giant particles, would be a charged superfluid. By spontaneous breaking of a gauge symmetry are generated the Higgs massive bosons. The unitary gauge assure generation of the neutral massive particles. The perturbation from the unitary gauge generates charged massive particles. Also, the Higgs boson decays into charged and neutral particles. The Tesla coil is the user of the excitations of the vacuum. 1. What is electric charge, and what is mass? According to the Standard Model “ The electric charge is a fundamental conserved property of certain subatomic particles that determines the electromagnetic interactions”. Electrically charged particles are influenced by and create electromagnetic fields. The elementary unit of charge is carried by a single proton and the equivalent negative charge is carried by a single electron. Also, there are up quarks with (2/3)e charge and there are down quarks with (1/3)e- charge.