MAINT.Data: Modelling and Analysing Interval Data in R by A
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
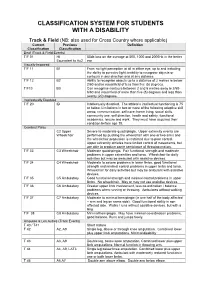
Disability Classification System
CLASSIFICATION SYSTEM FOR STUDENTS WITH A DISABILITY Track & Field (NB: also used for Cross Country where applicable) Current Previous Definition Classification Classification Deaf (Track & Field Events) T/F 01 HI 55db loss on the average at 500, 1000 and 2000Hz in the better Equivalent to Au2 ear Visually Impaired T/F 11 B1 From no light perception at all in either eye, up to and including the ability to perceive light; inability to recognise objects or contours in any direction and at any distance. T/F 12 B2 Ability to recognise objects up to a distance of 2 metres ie below 2/60 and/or visual field of less than five (5) degrees. T/F13 B3 Can recognise contours between 2 and 6 metres away ie 2/60- 6/60 and visual field of more than five (5) degrees and less than twenty (20) degrees. Intellectually Disabled T/F 20 ID Intellectually disabled. The athlete’s intellectual functioning is 75 or below. Limitations in two or more of the following adaptive skill areas; communication, self-care; home living, social skills, community use, self direction, health and safety, functional academics, leisure and work. They must have acquired their condition before age 18. Cerebral Palsy C2 Upper Severe to moderate quadriplegia. Upper extremity events are Wheelchair performed by pushing the wheelchair with one or two arms and the wheelchair propulsion is restricted due to poor control. Upper extremity athletes have limited control of movements, but are able to produce some semblance of throwing motion. T/F 33 C3 Wheelchair Moderate quadriplegia. Fair functional strength and moderate problems in upper extremities and torso. -

University of Wales Archive (GB 0210 UNIVWALES)
Llyfrgell Genedlaethol Cymru = The National Library of Wales Cymorth chwilio | Finding Aid - University of Wales Archive (GB 0210 UNIVWALES) Cynhyrchir gan Access to Memory (AtoM) 2.3.0 Generated by Access to Memory (AtoM) 2.3.0 Argraffwyd: Mai 04, 2017 Printed: May 04, 2017 Wrth lunio'r disgrifiad hwn dilynwyd canllawiau ANW a seiliwyd ar ISAD(G) Ail Argraffiad; rheolau AACR2; ac LCSH This description follows NLW guidelines based on ISAD(G) Second Edition; AACR2; and LCSH. https://archifau.llyfrgell.cymru/index.php/university-of-wales-archive archives.library .wales/index.php/university-of-wales-archive Llyfrgell Genedlaethol Cymru = The National Library of Wales Allt Penglais Aberystwyth Ceredigion United Kingdom SY23 3BU 01970 632 800 01970 615 709 [email protected] www.llgc.org.uk University of Wales Archive Tabl cynnwys | Table of contents Gwybodaeth grynodeb | Summary information .............................................................................................. 3 Hanes gweinyddol / Braslun bywgraffyddol | Administrative history | Biographical sketch ......................... 3 Natur a chynnwys | Scope and content .......................................................................................................... 5 Trefniant | Arrangement .................................................................................................................................. 6 Nodiadau | Notes ............................................................................................................................................ -

Replacement Parts Price List
REPLACEMENT PARTS PRICE LIST Product Catalog 2021 Replacement Parts Price List 607 PENTAIR 2021 Parts Price Eff. 09-14-2020 PART NO. DESCRIPTION US LIST CAN. LIST PART NO. DESCRIPTION US LIST CAN. LIST 00B7027 ORNG ADPT 13.03 15.66 071019Z KIT HOLDNG WHEEL 2000 45 39.26 47.17 00B8083 CLMP ASY V-BAND 209.27 251.46 071037 SCR 3/8 16X1 SCKT HD CAP 18 8 SS 7.48 8.99 012484 KIT XFMR/CRCT BRKR 167.83 201.66 071046 KEY IMPELLER 3/16 SQ C 29.42 35.35 05055-0003 LENS CLEAR 7.33"DIA 99.30 119.32 071048 WSHR IMP RTNR C SERIES 16.91 20.32 05057-0098 RNG LG REPAIR SS NICHE 241.24 289.87 071131Z DRAIN PLUG WFE ALMD 6.96 8.36 05057-0118 GSKT COLOR KIT 57.16 68.68 071136Z KIT KNB PLSTC LOOP ASY 26.10 31.36 05101-0002 GSKT SUNSAVER LENS 18.29 21.98 071389 NIPPLE BRASS .25 7.30 8.77 05101-0004 SCR LEADER 10-24 2" FH SUNSAVER 07-521 8.74 10.50 071390 NIPPLE 1/4 PVC NPT CLOSE 7.30 8.77 05101-0005 SCR RTNR RUBB 07-1667 1.86 2.23 071403 NUT 3/8-16 BRS BRIGHT NICKEL PLATED 1.74 2.09 05103-0001 NUT SUNSTAR 07-1411 26.30 31.60 071404Z NUT WING KIT 1.4-20 SS 8200 16.06 19.30 05103-0101 GASKET WALL FTG 8099 61-4566 11.63 13.97 071406 NUT 1/4-20 SS HEX 1.74 2.09 05103-0103 FTG WALL LENS SUNSTAR 07-1261 52.53 63.12 071407 NUT 5/8-18.75 HEX 17/6 13.64 16.39 05166-0001 GASKET VNYL SM NICHE 07-5802 4.27 5.13 071412 NUT HEX NO. -

TPS23861 IEEE 802.3At Quad Port Power-Over-Ethernet PSE
Product Order Technical Tools & Support & Folder Now Documents Software Community TPS23861 SLUSBX9I –MARCH 2014–REVISED JULY 2019 TPS23861 IEEE 802.3at Quad Port Power-over-Ethernet PSE Controller 1 Features 3 Description The TPS23861 is an easy-to-use, flexible, 1• IEEE 802.3at Quad Port PSE controller IEEE802.3at PSE solution. As shipped, it – Auto Detect, classification automatically manages four 802.3at ports without the – Auto Turn-On and disconnect need for any external control. – Efficient 255-mΩ sense resistor The TPS23861 automatically detects Powered • Pin-Out enables Two-Layer PCB Devices (PDs) that have a valid signature, determines • Kelvin Current Sensing power requirements according to classification and applies power. Two-event classification is supported • 4-Point detection for type-2 PDs. The TPS23861 supports DC • Automatic mode – as shipped disconnection and the external FET architecture – No External terminal setting required allows designers to balance size, efficiency and – No Initial I2C communication required solution cost requirements. • Semi-Automatic mode – set by I2C command The unique pin-out enables 2-layer PCB designs via logical grouping and clear upper and lower – Continuous Identification and Classification differentiation of I2C and power pins. This delivers – Meets IEEE 400-ms TPON specification best-in-class thermal performance, Kelvin accuracy – Fast-Port shutdown input and low-build cost. – Operates best when used in conjunction with In addition to automatic operation, the TPS23861 system reference code supports Semi-Auto Mode via I2C control for precision http://www.ti.com/product/TPS23861/toolssoftw monitoring and intelligent power management. are Compliance with the 400-ms TPON specification is ensured whether in semi-automatic or automatic • Optional I2C control and monitoring mode. -

2019 NFCA Texas High School Leadoff Classic Main Bracket Results
2019 NFCA Texas High School Leadoff Classic Main Bracket Results Bryan College Station BHS CSHS 1 Bryan College Station 17 Thu 3pm Thu 3pm Cedar Creek BHS CSHS EP Eastlake SA Brandeis 49 Brandeis College Station 57 Cy Woods 1 BHS Thu 5pm Thu 5pm CSHS 2 18 Thu 1pm Brandeis Robinson Thu 1pm EP Montwood BHS CSHS Robinson 11 Huntsville 3 89 Klein Splendora 93 Splendora 9 BHS Fri 2pm Fri 2pm CSHS 3 Fredericksburg Splendora 19 Thu 9am Thu 9am Fredericksburg 6 VET1 VET2 Belton 6 Grapevine 50 58 Richmond Foster 11 BHS Thu 5pm Klein Splendora Thu 5pm CSHS 4 20 Thu 11am Klein Richmond Foster Thu 11am Klein 11 BHS CSHS Rockwall 2 SA Southwest 9 97 SA Southwest Cedar Ridge 99 Cy Ranch 7 VET1 Fri 4pm Fri 4pm CP3 5 Southwest Cy Ranch 21 Thu 11am Thu 1pm Temple 5 VET1 CP3 Plano East 5 Clear Springs 2 51 Southwest Alvin 59 Alvin VET1 Thu 3pm Thu 5pm CP3 6 22 Thu 9am Vandegrift Alvin Thu 3pm Vandegrift 5 BHS CSHS Lufkin San Marcos 5 90 94 Flower Mound 0 VET2 Fri 12pm Southwest Cedar Ridge Fri 12pm CP4 7 San Marcos Cedar Ridge 23 Thu 9am Thu 1pm Magnolia West 3 VET2 CHAMPIONSHIP CP4 RR Cedar Ridge 12 McKinney Boyd 3 52 Game 192 60 SA Johnson VET2 Thu 3pm San Marcos BHS Cedar Ridge Thu 5 pm CP4 8 4:00 PM 24 Thu 11am M. Boyd BHS 5 10 BHS Johnson Thu 3pm Manvel 0 129 Southwest vs. Cedar Ridge 130 Kingwood Park Bellaire 3 Sat 10am Sat 8am Deer Park VET4 BRAC-BB 9 Cedar Park Deer Park 25 Thu 11am Thu 1pm Cedar Park 5 VET4 BRAC-BB Leander Clements 13 53 Cedar Park MacArthur 61 SA MacArthur VET4 Thu 3pm Thu 5pm BRAC-BB 10 26 Thu 9am Clements MacArthur Thu 3pm Waco University 0 BHS CSHS Tomball Memorial Cy Fair 4 91 Friendswood Woodlands 95 Woodlands 2 VET5 Fri 8am Fri 8am BRAC-YS 11 San Benito Woodlands 27 Thu 11am Thu 1pm San Benito 10 VET5 BRAC-YS SA Holmes 1 Friendswood 10 54 62 Santa Fe VET5 Thu 3pm Friendswood Woodlands Thu 5pm BRAC-YS 12 28 Thu 9am Friendswood Santa Fe Thu 3pm Henderson 0 VET1 VET2 Lake Travis Ridge Point 16 98 100 B. -

Classification Made Easy Class 1
Classification Made Easy Class 1 (CP1) The most severely disabled athletes belong to this classification. These athletes are dependent on a power wheelchair or assistance for mobility. They have severe limitation in both the arms and the legs and have very poor trunk control. Sports Available: • Race Runner (RR1) – using the Race Runner frame to run, track events include 100m, 200m and 400m. • Boccia o Boccia Class 1 (BC1) – players who fit into this category can throw the ball onto the court or a CP2 Lower who chooses to push the ball with the foot. Each BC1 athlete has a sport assistant on court with them. o Boccia Class 3 (BC3) – players who fit into this category cannot throw the ball onto the court and have no sustained grasp or release action. They will use a “chute” or “ramp” with the help from their sport assistant to propel the ball. They may use head or arm pointers to hold and release the ball. Players with a impairment of a non cerebral origin, severely affecting all four limbs, are included in this class. Class 2 (CP2) These athletes have poor strength or control all limbs but are able to propel a wheelchair. Some Class 2 athletes can walk but can never run functionally. The class 2 athletes can throw a ball but demonstrates poor grasp and release. Sports Available: • Race Runner (RR2) - using the Race Runner frame to run, track events include 100m, 200m and 400m. • Boccia o Boccia Class 2 (BC2) – players can throw the ball into the court consistently and do not need on court assistance. -

Technology Enhancement and Ethics in the Paralympic Games
UNIVERSITY OF PELOPONNESE FACULTY OF HUMAN MOVEMENT AND QUALITY OF LIFE SCIENCES DEPARTMENT OF SPORTS ORGANIZATION AND MANAGEMENT MASTER’S THESIS “OLYMPIC STUDIES, OLYMPIC EDUCATION, ORGANIZATION AND MANAGEMENT OF OLYMPIC EVENTS” Technology Enhancement and Ethics In the Paralympic Games Stavroula Bourna Sparta 2016 i TECHNOLOGY ENHANCEMENT AND ETHICS IN THE PARALYMPIC GAMES By Stavroula Bourna MASTER Thesis submitted to the professorial body for the partial fulfillment of obligations for the awarding of a post-graduate title in the Post-graduate Programme, "Organization and Management of Olympic Events" of the University of the Peloponnese, in the branch "Olympic Education" Sparta 2016 Approved by the Professor body: 1st Supervisor: Konstantinos Georgiadis Prof. UNIVERSITY OF PELOPONNESE, GREECE 2nd Supervisor: Konstantinos Mountakis Prof. UNIVERSITY OF PELOPONNESE, GREECE 3rd Supervisor: Paraskevi Lioumpi, Prof., GREECE ii Copyright © Stavroula Bourna, 2016 All rights reserved. The copying, storage and forwarding of the present work, either complete or in part, for commercial profit, is forbidden. The copying, storage and forwarding for non profit-making, educational or research purposes is allowed under the condition that the source of this information must be mentioned and the present stipulations be adhered to. Requests concerning the use of this work for profit-making purposes must be addressed to the author. The views and conclusions expressed in the present work are those of the writer and should not be interpreted as representing the official views of the Department of Sports’ Organization and Management of the University of the Peloponnese. iii ABSTRACT Stavroula Bourna: Technology Enhancement and Ethics in the Paralympic Games (Under the supervision of Konstantinos Georgiadis, Professor) The aim of the present thesis is to present how the new technological advances can affect the performance of the athletes in the Paralympic Games. -

Differential Growth Patterns in SCID Mice of Patient-Derived Chronic Myelogenous Leukemias
Bone Marrow Transplantation, (1998) 22, 367–374 1998 Stockton Press All rights reserved 0268–3369/98 $12.00 http://www.stockton-press.co.uk/bmt Differential growth patterns in SCID mice of patient-derived chronic myelogenous leukemias J McGuirk1,2,5, Y Yan1,4, B Childs1,2, J Fernandez1, L Barnett1, C Jagiello1, N Collins1 and RJ O’Reilly1,2,3,4 1Bone Marrow Transplantation Service, 2Department of Medicine, 3Department of Pediatrics, and 4Research Animal Laboratory, Memorial Sloan-Kettering Cancer Center, New York, NY, USA Summary: The product of this rearrangement is a bcr-abl hybrid gene, which encodes a p210 protein product with tyrosine kinase The development of an in vivo model for the study of activity and is thought to have leukemogenic properties.4 CML would be of significant importance in studying its CML typically begins as an initial chronic phase (CP) biological behavior and developing novel therapeutic which lasts approximately 4–6 years with eventual pro- strategies. We examined the ability of human leukemic gression to blastic transformation commonly heralded by cells derived from patients in either chronic (CP), accel- the acquisition of additional chromosomal abnormalities by erated (AP) or blast phase (BP) CML to grow and dis- Ph+ stem cells including duplication of the Ph chromosome, seminate in CB17-SCID mice by subcutaneous (s.c.) isochromy 17q and trisomy of chromosomes 8, 19 or 21.5,6 inoculation without conditioning treatment or adminis- The relationship of these non-random chromosomal tration of cytokines. Additionally, samples derived from changes to the progression of this disease is not well under- patients with CP-CML were injected s.c. -

WJ200 Series Brochure
PursuingPursuing thethe IdealIdeal CompactCompact InverterInverter Series Designed for excellent performance and user friendliness Printed in Japan (H) SM-E265 1109 Industry-leading Levels of Performance Index High starting torque of 200% or greater achieved Simple positioning control Features P2–5 3 Trip avoidance functions 4 1 by sensorless vector control (when sized for heavy duty). (when feedback signal is used.) Standard Speci cations P6 Integrated auto-tuning function for easy sensorless vector control Minimum time deceleration function, over-current suppress function When simple positioning function is activated, speed control operation or realizes high torque suitable for applications requiring it such as crane and DC bus AVR function are incorporated. The functions reduce positioning control operation is selectable via intellient input. While the [SPD] General Speci cations P7 hoists, lifts, elevators, etc. nuisance tripping. Improved torque limiting/current limiting function input is ON, the current position counter is held at 0. When [SPD] is OFF, the enables a load limit to protect machine and equipment. inverter enters positioning control operation and the position counter is active. Example of Torque Characteristics Dimensions P8 (Example of WJ200-075LF) (%) Example of Hitachi's standard motor. (7.5kW 4-pole) Output Frequency 200 Minimum time deceleration Function Start position counting Operation and Programming P9 OFF ON 100 Speed control Position control Motor Current DB Terminal (Arrangements/Functions) P 10 – 11 Motor Current Torque 0 0.5 1 3 6 10 20 30 40 50 60Hz SPD input Time Target position Function List P 12 – 20 -100 ON DC Voltage -200 DC Voltage Protective Functions P 21 Speed (min-1) Output Frequency Output Frequency Induction motor & Permanent magnetic motor* Auto-tuning to perform sensorless vector control can now be easily done. -

Automated Vehicles: Consultation Paper 3 - a Regulatory Framework for Automated Vehicles
Automated Vehicles: Consultation Paper 3 - A regulatory framework for automated vehicles A joint consultation paper Law Commission Scottish Law Commission Consultation Paper 252 Discussion Paper 171 Law Commission Consultation Paper No 252 Scottish Law Commission Discussion Paper No 171 Automated Vehicles: Consultation Paper 3 – A regulatory framework for automated vehicles A joint consultation paper 18 December 2020 © Crown copyright 2020 This publication is licensed under the terms of the Open Government Licence v3.0 except where otherwise stated. To view this licence, visit nationalarchives.gov.uk/doc/open- government-licence/version/3. Where we have identified any third party copyright information you will need to obtain permission from the copyright holders concerned. This publication is available at https://www.lawcom.gov.uk/project/automated-vehicles/ and at https://www.scotlawcom.gov.uk/publications. THE LAW COMMISSIONS – HOW WE CONSULT Topic of this consultation: In 2018, the Centre for Connected and Automated Vehicles (CCAV) asked the Law Commission of England and Wales and the Scottish Law Commission to examine options for regulating automated road vehicles. This is the third paper in that review. We make provisional proposals for a new regulatory system, examining the definition of “self-driving”; safety assurance before AVs are deployed on the road; and how to assure safety on an ongoing basis. We also consider user and fleet operator responsibilities, civil liability, criminal liability and access to data. Duration of the consultation: We invite responses from 18 December 2020 to 18 March 2021. Comments may be sent: Using an online form at: https://consult.justice.gov.uk/law-commission/automated-vehicles-regulatory-framework We have also produced a questionnaire in word format available on request. -
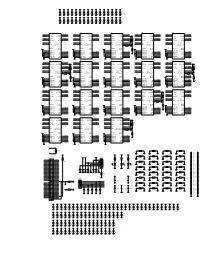
R28 100 2K2 R16 100 R11 +3V VCC VCC VCC VCC CP2 100Nf TCK TDI TDO TMS TRST BC Cmdin Cmdout Dout Reset 100Nf CP1 ASDBLR Nsen
+3V +3V +3V +3V +3V +3V +3V +3V +3V +3V +3V +3V +3V +3V +3V +3V CPA101CPA102CPA103CPA104CPA105CPA106CPA107CPA108CPA109CPA110CPA111CPA112CPA113CPA114CPA115CPA116 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF -3V -3V -3V -3V -3V -3V -3V -3V -3V -3V -3V -3V -3V -3V -3V -3V CPN101CPN102CPN103CPN104CPN105CPN106CPN107CPN108CPN109CPN110CPN111CPN112CPN113CPN114CPN115CPN116 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 100nF 17 18 19 20 21 Reset CmdOut1 Reset CmdOut1 Reset CmdOut1 Reset CmdOut1 Reset CmdOut1 Reset CmdOut Reset CmdOut Reset CmdOut Reset CmdOut Reset CmdOut _Reset _CmdOut1 _Reset _CmdOut1 _Reset _CmdOut1 _Reset _CmdOut1 _Reset _CmdOut1 _Reset _CmdOut _Reset _CmdOut _Reset _CmdOut +3V+3V _Reset _CmdOut _Reset _CmdOut CmdIn1 _Dout17 CmdIn1 _Dout18 CmdIn1 _Dout19 R21 CmdIn1 _Dout20 CmdIn1 _Dout21 CmdIn Dout CmdIn Dout CmdIn Dout CmdIn Dout CmdIn Dout _CmdIn1 Dout17 _CmdIn1 Dout18 _CmdIn1 Dout19 _CmdIn1 Dout20 _CmdIn1 Dout21 _CmdIn _Dout _CmdIn _Dout _CmdIn _Dout _CmdIn _Dout _CmdIn _Dout 2k2 R23 100 BC1 BC1 BC1 BC1 BC1 BC ASDBLR_Psense_In BC ASDBLR_Psense_In BC ASDBLR_Psense_In BC ASDBLR_Psense_In BC ASDBLR_Psense_In _BC1 _BC1 _BC1 _BC1 _BC1 _BC ASDBLR_Nsense_In _BC ASDBLR_Nsense_In _BC ASDBLR_Nsense_In _BC ASDBLR_Nsense_In _BC ASDBLR_Nsense_In R27 ASDBLR_GNDsense_In ASDBLR_GNDsense_In ASDBLR_GNDsense_In NM ASDBLR_GNDsense_In ASDBLR_GNDsense_In MonEn MonA MonEn MonA MonEn MonA MonEn MonA MonEn MonA VCC VCC VCC VCC VCC MonB MonB MonB MonB MonB -

Passive and Active Drag of Paralympic Swimmers
PASSIVE AND ACTIVE DRAG OF PARALYMPIC SWIMMERS By Yim – Taek OH A thesis submitted in partial fulfilment of the requirement of the Manchester Metropolitan University for the degree of Doctor of Philosophy Institute for Performance Research Department of Exercise and Sport Science Manchester Metropolitan University SEPTEMBER 2015 i ACKNOWLEDGEMENTS Above all, I give thanks to my Lord Jesus Christ with my whole heart, who planned, carried and finished my PhD. I dedicate this thesis to my precious Lord Jesus Christ. I would like to give thanks to God, as He allows me to see my world-best supervisor Dr Carl Payton. I would like to express my sincere gratitude to him for his invaluable help and inestimable encouragement throughout my PhD. Through his leadership this thesis could consolidate its position as a potential contributor to future IPC classification. I would also like to offer my thanks to Dr Conor Osborough who offered me worthy help, especially during the ‘Passive drag project’ at the London 2012 Paralympic games. I would like to give my thanks to Dr Casey Lee and Dr Danielle Formosa who, as the team members of the project, helped me in collecting the data. I must also thank Prof Brendan Burkett of the University of Sunshine Coast and all the members of the IPC Sports Science Committee. With the support of IPC Sports Science this thesis was able to conduct experiments during both the London 2012 Paralympic games and the Montreal 2013 IPC Swimming World Championships. Additional thanks goes to Mr Des Richards and Mr Grant Rockley who helped me in preparing the experimental devices and Mr Eric Denyer who kindly helped in the proofreading of the thesis.