Compiler Optimisation 6 – Instruction Scheduling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Integrating Program Optimizations and Transformations with the Scheduling of Instruction Level Parallelism*
Integrating Program Optimizations and Transformations with the Scheduling of Instruction Level Parallelism* David A. Berson 1 Pohua Chang 1 Rajiv Gupta 2 Mary Lou Sofia2 1 Intel Corporation, Santa Clara, CA 95052 2 University of Pittsburgh, Pittsburgh, PA 15260 Abstract. Code optimizations and restructuring transformations are typically applied before scheduling to improve the quality of generated code. However, in some cases, the optimizations and transformations do not lead to a better schedule or may even adversely affect the schedule. In particular, optimizations for redundancy elimination and restructuring transformations for increasing parallelism axe often accompanied with an increase in register pressure. Therefore their application in situations where register pressure is already too high may result in the generation of additional spill code. In this paper we present an integrated approach to scheduling that enables the selective application of optimizations and restructuring transformations by the scheduler when it determines their application to be beneficial. The integration is necessary because infor- mation that is used to determine the effects of optimizations and trans- formations on the schedule is only available during instruction schedul- ing. Our integrated scheduling approach is applicable to various types of global scheduling techniques; in this paper we present an integrated algorithm for scheduling superblocks. 1 Introduction Compilers for multiple-issue architectures, such as superscalax and very long instruction word (VLIW) architectures, axe typically divided into phases, with code optimizations, scheduling and register allocation being the latter phases. The importance of integrating these latter phases is growing with the recognition that the quality of code produced for parallel systems can be greatly improved through the sharing of information. -

Computer Architecture: Static Instruction Scheduling
Key Questions Q1. How do we find independent instructions to fetch/execute? Computer Architecture: Q2. How do we enable more compiler optimizations? Static Instruction Scheduling e.g., common subexpression elimination, constant propagation, dead code elimination, redundancy elimination, … Q3. How do we increase the instruction fetch rate? i.e., have the ability to fetch more instructions per cycle Prof. Onur Mutlu (Editted by Seth) Carnegie Mellon University 2 Key Questions VLIW (Very Long Instruction Word Q1. How do we find independent instructions to fetch/execute? Simple hardware with multiple function units Reduced hardware complexity Q2. How do we enable more compiler optimizations? Little or no scheduling done in hardware, e.g., in-order e.g., common subexpression elimination, constant Hopefully, faster clock and less power propagation, dead code elimination, redundancy Compiler required to group and schedule instructions elimination, … (compare to OoO superscalar) Predicated instructions to help with scheduling (trace, etc.) Q3. How do we increase the instruction fetch rate? More registers (for software pipelining, etc.) i.e., have the ability to fetch more instructions per cycle Example machines: Multiflow, Cydra 5 (8-16 ops per VLIW) IA-64 (3 ops per bundle) A: Enabling the compiler to optimize across a larger number of instructions that will be executed straight line (without branches TMS32xxxx (5+ ops per VLIW) getting in the way) eases all of the above Crusoe (4 ops per VLIW) 3 4 Comparison between SS VLIW Comparison: -

Static Instruction Scheduling for High Performance on Limited Hardware
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI 10.1109/TC.2017.2769641, IEEE Transactions on Computers 1 Static Instruction Scheduling for High Performance on Limited Hardware Kim-Anh Tran, Trevor E. Carlson, Konstantinos Koukos, Magnus Själander, Vasileios Spiliopoulos Stefanos Kaxiras, Alexandra Jimborean Abstract—Complex out-of-order (OoO) processors have been designed to overcome the restrictions of outstanding long-latency misses at the cost of increased energy consumption. Simple, limited OoO processors are a compromise in terms of energy consumption and performance, as they have fewer hardware resources to tolerate the penalties of long-latency loads. In worst case, these loads may stall the processor entirely. We present Clairvoyance, a compiler based technique that generates code able to hide memory latency and better utilize simple OoO processors. By clustering loads found across basic block boundaries, Clairvoyance overlaps the outstanding latencies to increases memory-level parallelism. We show that these simple OoO processors, equipped with the appropriate compiler support, can effectively hide long-latency loads and achieve performance improvements for memory-bound applications. To this end, Clairvoyance tackles (i) statically unknown dependencies, (ii) insufficient independent instructions, and (iii) register pressure. Clairvoyance achieves a geomean execution time improvement of 14% for memory-bound applications, on top of standard O3 optimizations, while maintaining compute-bound applications’ high-performance. Index Terms—Compilers, code generation, memory management, optimization ✦ 1 INTRODUCTION result in a sub-optimal utilization of the limited OoO engine Computer architects of the past have steadily improved that may stall the core for an extended period of time. -

Lecture 1 Introduction
Lecture 1 Introduction • What would you get out of this course? • Structure of a Compiler • Optimization Example Carnegie Mellon Todd C. Mowry 15-745: Introduction 1 What Do Compilers Do? 1. Translate one language into another – e.g., convert C++ into x86 object code – difficult for “natural” languages, but feasible for computer languages 2. Improve (i.e. “optimize”) the code – e.g, make the code run 3 times faster – driving force behind modern processor design Carnegie Mellon 15-745: Introduction 2 Todd C. Mowry What Do We Mean By “Optimization”? • Informal Definition: – transform a computation to an equivalent but “better” form • in what way is it equivalent? • in what way is it better? • “Optimize” is a bit of a misnomer – the result is not actually optimal Carnegie Mellon 15-745: Introduction 3 Todd C. Mowry How Can the Compiler Improve Performance? Execution time = Operation count * Machine cycles per operation • Minimize the number of operations – arithmetic operations, memory acesses • Replace expensive operations with simpler ones – e.g., replace 4-cycle multiplication with 1-cycle shift • Minimize cache misses Processor – both data and instruction accesses • Perform work in parallel cache – instruction scheduling within a thread memory – parallel execution across multiple threads • Related issue: minimize object code size – more important on embedded systems Carnegie Mellon 15-745: Introduction 4 Todd C. Mowry Other Optimization Goals Besides Performance • Minimizing power and energy consumption • Finding (and minimizing the -

Register Allocation and Instruction Scheduling in Unison
Register Allocation and Instruction Scheduling in Unison Roberto Castaneda˜ Lozano Mats Carlsson Gabriel Hjort Blindell Swedish Institute of Computer Science Swedish Institute of Computer Science Christian Schulte School of ICT, KTH Royal Institute of [email protected] School of ICT, KTH Royal Institute of Technology, Sweden Technology, Sweden [email protected] Swedish Institute of Computer Science fghb,[email protected] Abstract (1) (4) low-level IR This paper describes Unison, a simple, flexible, and potentially op- register (2) allocation (6) (7) timal software tool that performs register allocation and instruction integrated Unison IR generic scheduling in integration using combinatorial optimization. The combinatorial construction (5) solver tool can be used as an alternative or as a complement to traditional model approaches, which are fast but complex and suboptimal. Unison is instruction most suitable whenever high-quality code is required and longer (3) scheduling (8) compilation times can be tolerated (such as in embedded systems processor assembly or library releases), or the targeted processors are so irregular that description code traditional compilers fail to generate satisfactory code. Figure 1. Unison’s approach. Categories and Subject Descriptors D.3.4 [Programming Lan- guages]: Processors—compilers, code generation, optimization; D.3.2 [Programming Languages]: Language Classifications— full scope while robustly scaling to medium-size functions. A de- constraint and logic languages; I.2.8 [Artificial Intelligence]: tailed comparison with related approaches is available in a survey Problem Solving, Control Methods, and Search—backtracking, by Castaneda˜ Lozano and Schulte [2, Sect. 5]. scheduling Keywords combinatorial optimization; register allocation; in- Approach. Unison approaches register allocation and instruction struction scheduling scheduling as shown in Figure 1. -

An Application of Constraint Programming to Superblock Instruction Scheduling
An Application of Constraint Programming to Superblock Instruction Scheduling Abid M. Malik, Michael Chase, Tyrel Russell, and Peter van Beek Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada N2L 3G1 {ammalik,vanbeek}@cs.uwaterloo.ca Abstract. Modern computer architectures have complex features that can only be fully taken advantage of if the compiler schedules the com- piled code. A standard region of code for scheduling in an optimiz- ing compiler is called a superblock. Scheduling superblocks optimally is known to be NP-complete, and production compilers use non-optimal heuristic algorithms. In this paper, we present an application of con- straint programming to the superblock instruction scheduling problem. The resulting system is both optimal and fast enough to be incorporated into production compilers, and is the first optimal superblock sched- uler for realistic architectures. In developing our optimal scheduler, the keys to scaling up to large, real problems were in applying and adapting several techniques from the literature including: implied and dominance constraints, impact-based variable ordering heuristics, singleton bounds consistency, portfolios, and structure-based decomposition techniques. We experimentally evaluated our optimal scheduler on the SPEC 2000 benchmarks, a standard benchmark suite. Depending on the architec- tural model, between 98.29% to 99.98% of all superblocks were solved to optimality. The scheduler was able to routinely solve the largest su- perblocks, including superblocks with up to 2,600 instructions, and gave noteworthy improvements over previous heuristic approaches. 1TheProblem Modern computer architectures have complex features that can only be fully taken advantage of if the compiler schedules the compiled code. -

CS415 Compilers Instruction Scheduling
CS415 Compilers Instruction Scheduling These slides are based on slides copyrighted by Keith Cooper, Ken Kennedy & Linda Torczon at Rice University Register Allocation The General Task • At each point in the code, pick the values to keep in registers • Insert code to move values between registers & memory → No instruction reordering (leave that to scheduling) • Minimize inserted code — both dynamic & static measures • Make good use of any extra registers Allocation versus assignment • Allocation is deciding which values to keep in registers • Assignment is choosing specific registers for each value The compiler must perform both allocation & assignment cs415, spring 16 2 Lecture 4 Top-down Versus Bottom-up Allocation Top-down allocator • Work from external notion of what is important • Assign registers in priority order • Register assignment remains fixed for entire basic block • Save some registers for the values relegated to memory (feasible set F) Bottom-up allocator • Work from detailed knowledge about problem instance • Incorporate knowledge of partial solution at each step • Register assignment may change across basic block (different register assignments for different parts of live range) • Save some registers for the values relegated to memory (feasible set F) cs415, spring 16 3 Lecture 4 Bottom-up Allocator The idea: • Focus on replacement rather than allocation • Keep values “used soon” in registers • Only parts of a live range may be assigned to a physical register ( ≠ top-down allocation’s “all-or-nothing” approach) Algorithm: -

A Simple, Verified Validator for Software Pipelining
A Simple, Verified Validator for Software Pipelining (verification pearl) Jean-Baptiste Tristan Xavier Leroy INRIA Paris-Rocquencourt INRIA Paris-Rocquencourt B.P. 105, 78153 Le Chesnay, France B.P. 105, 78153 Le Chesnay, France [email protected] [email protected] Abstract unrolling the loop then performing acyclic scheduling. Software Software pipelining is a loop optimization that overlaps the execu- pipelining is implemented in many production compilers and de- tion of several iterations of a loop to expose more instruction-level scribed in several compiler textbooks [1, section 10.5] [2, chapter parallelism. It can result in first-class performance characteristics, 20] [16, section 17.4]. In the words of the rather dramatic quote but at the cost of significant obfuscation of the code, making this above, “truly desperate” programmers occasionally perform soft- optimization difficult to test and debug. In this paper, we present a ware pipelining by hand, especially on multimedia and signal pro- translation validation algorithm that uses symbolic evaluation to de- cessing kernels. tect semantics discrepancies between a loop and its pipelined ver- Starting in the 1980’s, many clever algorithms were designed sion. Our algorithm can be implemented simply and efficiently, is to produce efficient software pipelines and implement them either provably sound, and appears to be complete with respect to most on stock hardware or by taking advantage of special features such modulo scheduling algorithms. A conclusion of this case study is as those of the IA64 architecture. In this paper, we are not con- that it is possible and effective to use symbolic evaluation to reason cerned about the performance characteristics of these algorithms, about loop transformations. -

SSE Optimizations These Optimizations Leverage the Streaming SIMD Extension (SSE) Instruction Set of the CPU
Introduction Optimization options control compile time optimizations to generate an application with code that executes more quickly. Absoft Fortran 90/95 is an advanced optimizing compiler. Various optimizers can be turned on that discover different opportunities to optimize Fortran code. There are pros and cons when choosing optimizations; the application will execute much faster after compilation but the compilation speed itself will be slow. Some of the optimizations described below will benefit almost any Fortran code, while others should only be applied to specific situations. No Optimization The –O0 option is the default optimization level and provides the fastest compilation speed. It disables all optimizations and is useful for debugging. The -g option is the common debugging flag used with this level of optimization. Basic Optimizations The –O1 option will cause most code to run faster and enables optimizations that only span sequential code sequences. The optimizations include, but are not limited to, common subexpression elimination, constant propagation, dead code elimination, and instruction scheduling. This option is compatible with debugging options. Normal Optimizations The –O2 option enables normal optimizers that can make most code run faster. It can substantially rearrange the code generated for a program. The optimizations include, but not limited to, strength reduction, partial redundancy elimination, innermost loop unrolling, control flow optimizations, advanced instruction scheduling. This option is not generally usable with debugging options. Advanced Optimizations The –O3 option enables advanced optimizers that can significantly rearrange and modify the code generated for a program. It provides all optimizations applied with –O1 and –O2. Additional optimizations include auto loop vectorization, loop permutation (loop reordering), loop tiling (improved cache performance), loop skewing, loop reversal, loop fusion and fission, unimodular transformations, forward substitution, and expression simplification. -

Survey on Combinatorial Register Allocation and Instruction Scheduling ACM Computing Surveys
http://www.diva-portal.org Postprint This is the accepted version of a paper published in ACM Computing Surveys. This paper has been peer-reviewed but does not include the final publisher proof-corrections or journal pagination. Citation for the original published paper (version of record): Castañeda Lozano, R., Schulte, C. (2018) Survey on Combinatorial Register Allocation and Instruction Scheduling ACM Computing Surveys Access to the published version may require subscription. N.B. When citing this work, cite the original published paper. Permanent link to this version: http://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-232189 Survey on Combinatorial Register Allocation and Instruction Scheduling ROBERTO CASTAÑEDA LOZANO, RISE SICS, Sweden and KTH Royal Institute of Technology, Sweden CHRISTIAN SCHULTE, KTH Royal Institute of Technology, Sweden and RISE SICS, Sweden Register allocation (mapping variables to processor registers or memory) and instruction scheduling (reordering instructions to increase instruction-level parallelism) are essential tasks for generating efficient assembly code in a compiler. In the last three decades, combinatorial optimization has emerged as an alternative to traditional, heuristic algorithms for these two tasks. Combinatorial optimization approaches can deliver optimal solutions according to a model, can precisely capture trade-offs between conflicting decisions, and are more flexible at the expense of increased compilation time. This paper provides an exhaustive literature review and a classification of combinatorial optimization ap- proaches to register allocation and instruction scheduling, with a focus on the techniques that are most applied in this context: integer programming, constraint programming, partitioned Boolean quadratic programming, and enumeration. Researchers in compilers and combinatorial optimization can benefit from identifying developments, trends, and challenges in the area; compiler practitioners may discern opportunities and grasp the potential benefit of applying combinatorial optimization. -
Learning Heuristics for the Superblock Instruction Scheduling Problem Tyrel Russell, Abid M
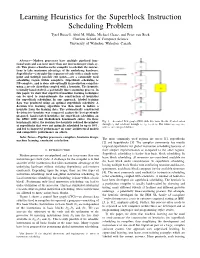
Learning Heuristics for the Superblock Instruction Scheduling Problem Tyrel Russell, Abid M. Malik, Michael Chase, and Peter van Beek Cheriton School of Computer Science University of Waterloo, Waterloo, Canada Abstract— Modern processors have multiple pipelined func- tional units and can issue more than one instruction per clock cy- cle. This places a burden on the compiler to schedule the instruc- tions to take maximum advantage of the underlying hardware. Superblocks—a straight-line sequence of code with a single entry point and multiple possible exit points—are a commonly used scheduling region within compilers. Superblock scheduling is NP-complete, and is done sub-optimally in production compilers using a greedy algorithm coupled with a heuristic. The heuristic is usually hand-crafted, a potentially time-consuming process. In this paper, we show that supervised machine learning techniques can be used to semi-automate the construction of heuristics for superblock scheduling. In our approach, labeled training data was produced using an optimal superblock scheduler. A decision tree learning algorithm was then used to induce a heuristic from the training data. The automatically constructed decision tree heuristic was compared against the best previously proposed, hand-crafted heuristics for superblock scheduling on the SPEC 2000 and MediaBench benchmark suites. On these Fig. 1. A control flow graph (CFG) with five basic blocks. Control enters benchmark suites, the decision tree heuristic reduced the number e e e e e w w w of superblocks that were not optimally scheduled by up to 38%, through 0 and can leave through 1, 2, 3 or 5. The values 1, 2, 3 and w5 are exit probabilities. -

Cluster Assignment and Scheduling for Partitioned Register Set Machines
RICE UNIVERSITY Cluster Assignment and Instruction Scheduling for Partitioned Register-Set Machines by Jingsong He A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree Master of Science Approved, Thesis Committee: Dr. Keith D. Cooper, Chairman Professor Computer Science Dr. John Mellor-Crummey Senior Faculty Fellow Computer Science Dr. Devika Subramanian Associate Professor Computer Science Dr. Linda M. Torczon Research Scientist Computer Science Houston, Texas April, 2000 Cluster Assignment and Instruction Scheduling for Partitioned Register-Set Machines Jingsong He Abstract For half a century, computer architects have been striving to improve uniprocessor computer performance. Many of their successful designs such as vliw and superscalar machines use multiple functional units trying to exploit instruction level parallelism in computer programs. As the number of functional units rises, another hardware constraint enters the picture — the number of register-file ports needed grows directly with the number of functional units. At some point, the multiplexing logic on register ports can come to dominate the processor’s cycle time. A reasonable solution is to partition the register file into independent sets and associate each functional unit with a specific register set. Such partitioned register sets have appeared in a number of commercial machines, such as Texas Instruments TMS320C6xxx dsp chips. Partitioned register-set architectures present a new set of challenges to compiler designers — the compiler must assign each operation to a specific clusters and co- ordinate data movement between clusters. In this thesis, we investigate five instruc- tion scheduling methods with different scopes to find a suitable one for partitioned register-set architectures.