Spatial Prediction of Fire Ignition Probabilities: Comparing Logistic Regression and Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Área De Reabilitação Urbana De Midões
ÁREA DE REABILITAÇÃO URBANA DE MIDÕES Câmara Municipal de Tábua Dezembro de 2018 Delimitação da Área de Reabilitação Urbana de Midões Câmara Municipal de Tábua ÍNDICE 1 | INTRODUÇÃO ........................................................................................................................... 3 2 | OBJETIVOS ............................................................................................................................... 8 3 | ENQUADRAMENTO ................................................................................................................ 10 3.1 | No território ....................................................................................................................... 11 3.2 | Na história e morfologia .................................................................................................... 15 4 | CARACTERIZAÇÃO E DIAGNÓSTICO ................................................................................. 19 4.1 | Parque habitacional ................................................................................................... 20 4.2. | Valor Patrimonial ...................................................................................................... 22 4.3 | Espaços Públicos ...................................................................................................... 26 4.4 | Análise SWOT ........................................................................................................... 29 5 | DELIMITAÇÃO DA ARU ........................................................................................................ -

Grande Rota Do Alva
CNE Mata Nacional do Bussaco SIC Dunas de Mira, MORTÁGUA SANTA COMBA DÃO A Grande Rota do Alva, percurso linear com 77 km de Gândara e Gafanhas SIC TÁBUA Carregal do Sal extensão, promovido pela CIM-RC, passa pelos concelhos de EUROVELO GR GR 48 Caminho 49 Português Penacova, Vila Nova de Poiares, Arganil, Tábua e Oliveira de Santiago GR do Hospital. O rio Alva é o elemento identitário da região 51 GR Monumento Natural 48.2 do Cabo Mondego atravessada pela rota, assinalada por planaltos e vales Parque Natural da Serra da Estrela GR GR 48.1 marcantes, nos quais o serpentear do Alva moldou a paisagem 48 Paisagem Protegida Montes GÓIS da Serra do Açor de Santa Olaia e Ferrestelo e impôs um modelo de povoamento e desenvolvimento muito Reserva Natural do Paul de Arzila LOUSÃ próprio que desperta o desejo da descoberta e justifica a visita SIC atenta e enriquecedora. Serra da Lousã EUROVELO GR GR 26 33.3 GR 26 0 1000 2000 3000 4000 5000 m Com uma extensão aproximada de 106 km, o rio SIC Sicó / Alvaiázere Alva nasce na Serra da Estrela e desagua no rio PEDROGÃO GRANDE ANSIÃO Mondego, na localidade de Porto de Raiva, no Grande Rota do Alva concelho de Penacova. O seu percurso sinuoso, 350 300 1 marcado nas encostas da Serra da Estrela e Serra 250 2 3 200 4 do Açor, permite descobrir um conjunto de atra- 150 100 6 50 7 8 9 ções naturais e turísticas de grande qualidade 0 m 0 km 8 16 24 32 40 48 56 64 72 80 e importância local, que justificam a realização Desvio Inverno Beco Desvio Inverno Livraria do Mondego HÚMIDAS desta grande rota. -
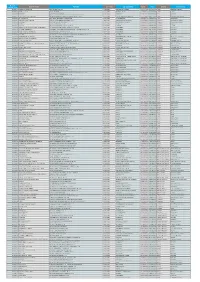
Branch Internal Code Branch Name Address Zip Code Zip City Name
Branch Branch Name Address Zip Code Zip City Name Phone Fax District Municipality Internal Code 8810327 MARINHA GRANDE AV. VITOR GALLO 2430-999 MARINHA GRANDE 244575520 244575526 Leiria Marinha Grande 8810334 MONTE REAL RUA 28 MAIO 2425-999 MONTE REAL 244619101 244619106 Leiria Leiria 8810342 POMBAL LARGO 25 DE ABRIL 3100-999 POMBAL 236209521 236209526 Leiria Pombal 8810343 ANSIÃO RUA CONSELHEIRO ANTONIO JOSÉ DA SILVA 3240-999 ANSIÃO 2,37E+08 236670226 Leiria Ansião 8810351 FIGUEIRO DOS VINHOS RUA DR MANUEL SIMÕES BARREIROS. 14 A 3260-999 FIGUEIRÓ DOS VINHOS 236551184 236551185 Leiria Figueiró Dos Vinhos 8810354 ALVAIÁZERE AVª JOSÉ MENDES CARVALHO 3250-999 ALVAIÁZERE 236650220 236650226 Leiria Alvaiázere 8810357 MIRANDA DO CORVO RUA D AFONSO HENRIQUES. N.º 5 3220-999 MIRANDA DO CORVO 239530250 239530256 Coimbra Miranda Do Corvo 8810359 CONDEIXA RUA DR JOAO ANTUNES 3150-999 CONDEIXA-A-NOVA 239940650 239940656 Coimbra Condeixa-A-Nova 8810362 PENELA LARGO DO CORREIO 3230-999 PENELA 239561317 239561318 Coimbra Penela 8810363 LOUSÃ PRAÇA CANDIDO DOS REIS Nº 5 3200-999 LOUSÃ 239990250 239990256 Coimbra Lousã 8810375 FERNÃO DE MAGALHÃES (COIMBRA) AV. FERNÃO DE MAGALHÃES Nº 233 R/C 3000-999 COIMBRA 239850771 239850776 Coimbra Coimbra 8810376 S JOSÉ (COIMBRA) AVENIDA JOAO DE DEUS RAMOS Nº 146 LOJA 32 33 34 3030-999 COIMBRA 239791780 239791786 Coimbra Coimbra 8810379 PEDRULHA (COIMBRA) RUA MANUEL MADEIRA S/Nº 3025-999 COIMBRA 239499250 239499256 Coimbra Coimbra 8810382 S MARTINHO DO BISPO RUA COVÔES. N.º 24 A R/C ESQ. 3045-999 COIMBRA 239802550 -

Geographic Patterns and Environmental Correlations of Morphological and Genetic Variation in Endemic Caryophyllaceae in Western Iberian Peninsula
Geographic patterns and environmental correlations of morphological and genetic variation in endemic Caryophyllaceae in Western Iberian D Peninsula João Filipe Figueiredo da Rocha Doutoramento em Biologia Departamento de Biologia 2014 Orientador Doutor Rubim Manuel Almeida da Silva, Professor Auxiliar, Faculdade de Ciências da Universidade do Porto Coorientador Doutor António Maria Luís Crespí, Professor Auxiliar, Universidade de Trás-os-Montes e Alto Douro Doutor Francisco Amich García, Professor Catedrático, Faculdade de Biologia da Universidade de Salamanca FCUP 3 Geographic patterns and environmental correlations of morphological and genetic variation in endemic Caryophyllaceae in Western Iberian Peninsula Foreword According to the number 3 of the 7th Article of regulation of the Doctoral Program in Biology from Faculdade de Ciências da Universidade do Porto (and in agreement with the Portuguese Law Decree Nº 74/2006), the present thesis integrates the articles listed below, written in collaboration with co-authors. The candidate declares that he contributed to conceiving the ideas, compiling and producing the databases and analysing the data, and also declares that he led the writing of all chapters. List of papers: Chapter 3 – Rocha J, Castro I, Ferreira V, Carnide V, Pinto-Carnide O, Amich F, Almeida R, Crespí A (Submitted) Phylogeography of Silene section Cordifolia in the Mountain ranges of North Iberian Peninsula and Alps. Botanical Journal of the Linnean Society. Chapter 4 – Rocha J, Ferreira V, Castro I, Carnide V, Amich F, Almeida R, Crespí A (Submitted) Phylogeography of Silene scabriflora in Iberian Peninsula. American Journal of Botany. Chapter 5 – Rocha J, Almeida R, Amich F, Crespí A (Submitted) Morpho- environmental behaviour of Silene scabriflora in Iberian Peninsula: Atlantic versus Mediterranean climate. -

Relatório Síntese (RS)
Estudo de Impacte Ambiental da ampliação da pedreira n.º 3785 “Pisca 2” Relatório Síntese (RS) Outubro 2014 Proj. nº 332.27208 Rel. nº 332.27208-3/13 Revisão: 0 Data: Outubro 2014 ÍNDICE ENQUADRAMENTO LEGAL ........................................................................... 13 1 INTRODUÇÃO .................................................................................. 14 1.1 Identificação do Proponente e do projeto ................................................... 14 1.2 Identificação da fase do projeto ............................................................... 15 1.3 Identificação da entidade licenciadora ....................................................... 15 1.4 Antecedentes do EIA ............................................................................. 16 1.5 Equipa responsável do EIA ...................................................................... 16 1.6 Metodologia e estrutura do EIA ................................................................ 17 2 DESCRIÇÃO DO PROJETO .................................................................... 21 2.1 Objetivos do projeto e sua justificação ...................................................... 21 2.2 Antecedentes do projeto ........................................................................ 22 2.3 Alternativas ao projeto .......................................................................... 23 2.4 Descrição sumária do projeto .................................................................. 25 2.4.1 Caraterização da massa mineral ........................................................... -

Nota Informativa N.: 08/2019-2020/Ca/A.F
NOTA INFORMATIVA N.: 08/2019-2020/CA/A.F. COIMBRA DATA: 15/11/2019 Para os devidos efeitos, informamos a constituição das equipas de arbitragem nomeadas para os seguintes jogos a realizar de 12-11-2019 a 17-11-2019 TAÇA A.F.C. - 3ª ELIMINATÓRIA - Novo grupo - 1ª Jornada Jogo Árbitro Função UC EIRENSE - AD POIARES RENATO CARVALHO ARBITRO CAMPO VALE FOJO (RELVADO SINTÉTICO) - EIRAS BRUNO VENTURA ARBITRO ASSISTENTE 1 17-11-2019 15:00 MÍLTON VOGADO ARBITRO ASSISTENTE 2 GD PAMPILHOSENSE - GR VIGOR MOCIDADE PEDRO TOMAS ARBITRO CAMPO "PAMPILHOSENSE" (RELVADO SINTÉTICO) - MIGUEL SOARES ARBITRO ASSISTENTE 1 PAMPILHOSA DA SERRA 17-11-2019 15:00 JOÃO FERREIRA ARBITRO ASSISTENTE 2 AD LAGARES BEIRA - UNIÃO 1919 ANDRE RODRIGUES ARBITRO COMPLEXO DESPORTIVO LAGARES BEIRA (RELVADO LUIS TAVARES ARBITRO ASSISTENTE 1 SINTÉTICO) - LAGARES DA BEIRA 17-11-2019 15:00 FERNANDO GOUVEIA ARBITRO ASSISTENTE 2 OBSV:FABIO FERREIRA ACDS VINHA RAINHA - CD CARAPINHEIRENSE PEDRO NASCIMENTO ARBITRO CAMPO VINHA RAINHA (RELVADO SINTÉTICO) - VINHA DA MARIO SIMOES ARBITRO ASSISTENTE 1 RAINHA 17-11-2019 15:00 GONCALO ESTEVES ARBITRO ASSISTENTE 2 ASSOCIAÇÃO NAVAL 1893 - AD NOGUEIRENSE JOAO SANTOS ARBITRO CAMPO TREINOS EST MUNIC JOSÉ B PESSOA (RELVADO MARCO SILVA ARBITRO ASSISTENTE 1 SINTÉTICO) - FIGUEIRA DA FOZ 17-11-2019 15:00 RUI SA ARBITRO ASSISTENTE 2 MOCIDADE FC - CF OS MARIALVAS BRUNO POMBO ARBITRO CAMPO SERRA (RELVADO SINTÉTICO) - CHEIRA VINICIUS PIRES ARBITRO ASSISTENTE 1 17-11-2019 15:00 ALEXANDRE SILVA ARBITRO ASSISTENTE 2 ANCA FC - REAL CL. BRASFEMES DIOGO SILVA ARBITRO PARQUE DESPORTIVO DE ANÇA (RELVADO SINTÉTICO) - ANÇÃ JOAO MARTINS ARBITRO ASSISTENTE 1 17-11-2019 15:00 JOAO MAURICIO ARBITRO ASSISTENTE 2 GD COVA-GALA - CDR PENELENSE PAULO ANTUNES ARBITRO CAMPO CABEDELO (TERRA BATIDA) - COVA GALA / FIGUEIRA HUGO REBELO ARBITRO ASSISTENTE 1 FOZ 17-11-2019 15:00 FRANCISCO SILVA ARBITRO ASSISTENTE 2 Página 1 / 21 NOTA INFORMATIVA N.: 08/2019-2020/CA/A.F. -

Bacia Do Mondego, Portugal) Tertiary Lithostratigraphy of the Miranda Do Corvo- Viseu Region (Mondego Basin, Portugal)
Ciencias da Terra (UNL) Lisboa N.O 14 Litostratigrafia do Terciario da regiao Miranda do Corvo-Viseu (Bacia do Mondego, Portugal) Tertiary lithostratigraphy of the Miranda do Corvo- Viseu region (Mondego Basin, Portugal) P. Pruenea Cunha Gfupo de Estudo dosAmbicnte$Sedimenlare$; Ccnlro de Oeociblcia.s da Univ. Coimbta; [email protected] Departamento de Ciblcia.s da Tern, Univm;idade de Coimbn. LargoMarqub de Pombal, ] ()(M}.2n Coimbra RESUM O Pal .IVr..,<have: Litosttatigrafia; Terciario; Portugal Central; Bacia taeiiria do Mondego; depOsitos alu viais; descontinuidades sed imentares.. Descrevero-se as unidades litostratigrificas (2 grupos, S fo~ e 4 membros) do Terciario da regilo de Miranda do Corvo Viseu (portugal Central). Pm. cada unidade e efectuada a respeeti va caracteri~o e desc::ri~ (lim ites, propri edad es tipicas e atributos). Os dad os estratigrificos, litolegicos, scquenciais e tect6nicos permitem estabeleeer corn:la¢es com os sedimentos mais a ocidente na mesma bacia terciaria (Bacia do Mondego) e ajudar i atrib ui~o cronostratigrifica. As caracterisncas sedimcntoJ6gicas dos dep6sitos e 0 enquadramento com acontecimentos eoevos identificados noutras regioes penni tem tembem avaliar 0 papel do clima, do eustatismo e da tecl6n ica na evcrccao sedimentar dcsta Bacia . ABST RACT Key-words: Lithostrat igraphy; Tertiary; Central Portugal; Mond ego Tertiary Basin; alluvial depo sits; sed imentary discontinu ities. The lithostratigraphic units (2 group s. S formations and 4 members) of the Tertiary of the Miranda do Cc rvc-vlseu region (Central Portugal) are here described. For each unit the characteriza tion and description (boundaries, diagnost ic properties and atributes) were included. -

Distrito Código
Código - Designação Serviço N.º de peritos Distrito Finanças OA 01-AVEIRO 19-AGUEDA 2 01-AVEIRO 27-ALBERGARIA-A-VELHA 1 01-AVEIRO 35-ANADIA 2 01-AVEIRO 43-AROUCA 1 01-AVEIRO 51-AVEIRO-1. 1 01-AVEIRO 60-CASTELO DE PAIVA 1 01-AVEIRO 78-ESPINHO 1 01-AVEIRO 86-ESTARREJA 1 01-AVEIRO 94-ST. MARIA FEIRA-1 1 01-AVEIRO 108-ILHAVO 1 01-AVEIRO 116-MEALHADA 1 01-AVEIRO 124-MURTOSA 1 01-AVEIRO 132-OLIVEIRA AZEMEIS 2 01-AVEIRO 140-OLIVEIRA DO BAIRRO 1 01-AVEIRO 159-OVAR 2 01-AVEIRO 167-S. JOAO DA MADEIRA 0 01-AVEIRO 175-SEVER DO VOUGA 1 01-AVEIRO 183-VAGOS 1 01-AVEIRO 191-VALE DE CAMBRA 1 01-AVEIRO 3417-AVEIRO-2. 1 01-AVEIRO 3441-ST. MARIA FEIRA-2 1 01-AVEIRO 3735-ST. MARIA FEIRA 3. 1 01-AVEIRO 4170-ST. MARIA FEIRA 4. 0 01-AVEIRO Total 25 02-BEJA 205-ALJUSTREL 1 02-BEJA 213-ALMODOVAR 1 02-BEJA 221-ALVITO 0 02-BEJA 230-BARRANCOS 0 02-BEJA 248-BEJA 1 02-BEJA 256-CASTRO VERDE 1 02-BEJA 264-CUBA 0 02-BEJA 272-FERREIRA DO ALENTEJO 1 02-BEJA 280-MERTOLA 2 02-BEJA 299-MOURA 1 02-BEJA 302-ODEMIRA 2 02-BEJA 310-OURIQUE 1 02-BEJA 329-SERPA 1 02-BEJA 337-VIDIGUEIRA 1 02-BEJA Total 13 03-BRAGA 345-AMARES 1 03-BRAGA 353-BARCELOS 5 03-BRAGA 361-BRAGA-1. 3 03-BRAGA 370-CABECEIRAS DE BASTO 1 03-BRAGA 388-CELORICO DE BASTO 2 03-BRAGA 396-ESPOSENDE 2 03-BRAGA 400-FAFE 2 03-BRAGA 418-GUIMARAES-1. -

Are Voters Rationally Ignorant? an Empirical Study of Portuguese Local Elections
PEJ 5:31-44 (2006) DOI 10.1007/S10258-006-0002-9 ORIGINAL ARTICLE Ester Gomes Silva • Jose da Silva Costa Are voters rationally ignorant? An empirical study of Portuguese local elections Published online: 7 March 2006 © Springer Verlag 2006 Abstract The application of the rational choice postulate to a political context invariably leads to the conclusion that most voters are ill informed when making the decision on whom to vote for. In this paper, the authors conduct an empirical evaluation of the rational ignorance theory, based on the model developed by (Rogoff and Sibert Rev Econ Stud LV:1-16, (1988) and by considering that better informed voters reward political candidates who show better performances. The levels of performance are established through the construction of an empirical frontier using the Data Envelopment Analysis (DEA) methodology. According to our results, based on the 1997 Portuguese local elections, even though swing voters do not necessarily behave as rationally ignorant voters, a large majority of voters are rationally ignorant. Keywords Voters' behaviour • DEA analysis • Local elections • Local govemments • Portugal 1 Introduction Since Downs's seminal work. An Economic Theory of Democracy (Downs 1957), one ofthe most stimulating issues in the public choice theory is concerned with the fact that voters may have insufficient information and how this can be used by political representatives and lobbies to meet their own interests. By applying the rationality postulate to the characterization of the voter's behaviour. Downs concludes that the voter is insufficiently informed when deciding on whom to vote for. Confronting costs and benefits, the rational voter sees that it does not E. -

Informação Atualizada a 05 De Fevereiro De 2021 ARS ACES CS
Informação atualizada a 05 de fevereiro de 2021 Faz ARS ACES CS Nome Morada Telefone E-mail Colheita Horário de Atendimento e Observações Testes? ADR Comunidade Alto Rua Eng. Adelino Amaro da Todos os dias úteis, fins de semana e feriados: 14:00 às 20:00 CS Arcos de ARS Norte ACES Alto Minho Minho (Arcos de Costa 258520146 [email protected] Não Postos de colheita disponíveis para consulta em https://covid19.min-saude.pt/laboratorios- Valdevez Valdevez) 4970-458 Arcos de Valdevez referenciados/ Rua Eng. Luís Agostinho Pereira Todos os dias úteis, fins de semana e feriados: 14:00 às 20:00 ADR Comunidade Alto ARS Norte ACES Alto Minho CS Caminha Castro 258723507 [email protected] Não Postos de colheita disponíveis para consulta em https://covid19.min-saude.pt/laboratorios- Minho (Caminha) 4910-102 Caminha referenciados/ Todos os dias úteis, fins de semana e feriados: 08:00 às 20:00. Reabertura das 8:00 às 20:00 CS Paredes ADR Comunidade Alto Av. Cónego Bernardo Chousal H ARS Norte ACES Alto Minho 251782192 [email protected] Não de Coura Minho (Paredes de Coura) 4940-520 Paredes de Coura Postos de colheita disponíveis para consulta em https://covid19.min-saude.pt/laboratorios- referenciados/ Todos os dias úteis, fins de semana e feriados: 08:00 às 20:00. Reabertura das 8:00 às 20:00 CS Ponte de ADR Comunidade Alto Urbanização do Olho Marinho H com início em 23.01.2021. ARS Norte ACES Alto Minho 258909280 [email protected] Não Lima Minho (Ponte Lima) 4990-145 Ponte Lima Postos de colheita disponíveis para consulta em https://covid19.min-saude.pt/laboratorios- referenciados/ Todos os dias úteis, fins de semana e feriados: 14:00 às 20:00 CS Viana do ADR Comunidade Alto Rua Dr. -

REVISÃO DO PDM DE Tábua
REVISÃO DO PDM DE Tábua COMISSÃO CONSULTIVA (setembro de 2017) ENTIDADE REPRESENTANTE/ENDEREÇO CONTACTO Arqt.ª Maria da Graça Gabriel [email protected] CCDRC 239 400 167 Dr.ª Alexandra Grego [email protected] Eng.ª Luísa Marques [email protected] Câmara Municipal de Tábua 235 410 340 Dr.ª Alexandra Bento 919 703 185 (Eng.ª Luísa Marques) [email protected] Sr. Rui Brito Pereira Assembleia Municipal de Tábua [email protected] 235 410 340 Dr.ª Joana Cordeiro [email protected] [email protected] Administração Regional de Saúde Dr.ª Alexandra Vieira [email protected] Eng.ª Dulce Calado Agência Portuguesa do Ambiente/ARH Centro [email protected] 239 850 226 Eng.º Carlos Mesquita Águas do Planalto, SA [email protected] 232 819 240 [email protected] 92 565 88 36 Eng.º Carlos Manuel Marques 217 21 10 00 ANACOM - Autoridade Nacional de Comunicações [email protected] Dr. Carlos Cruz [email protected] Autoridade Nacional de Proteção Civil Dr. António Oliveira [email protected] Eng.ª Rosa Oliveira [email protected] Direção-Geral de Energia e Geologia 217 922 700 Eng.º Álvaro Saraiva [email protected] Dr.ª Susana Fonseca Henriques Direção-Geral dos Estabelecimentos Escolares /Direção [email protected] de Serviços Região Centro Eng.º João Cordeiro Direção-Geral do Território [email protected] 21 381 96 00 Eng.º António Elísio Marques Godinho 239 800 500 Direção Regional de Agricultura e Pescas do Centro [email protected] Eng.ª Maria da Glória Martins Fernandes [email protected] Direção Regional da Cultura do Centro 239 701 391 Dr.ª Helena Moura [email protected] Major Armando Manuel das Neves Videira Guarda Nacional Republicana [email protected] 966 149 151 Eng.º Carlos Perpétua IAPMEI [email protected] 239 853 964 Eng.º Nuno Miguel Grilo Gama Infraestruturas de Portugal, S.A. -

A Chance for Places That Don't Matter
A CHANCE FOR PLACES THAT DON’T MATTER. PLACE-BASED SUSTAINABLE TOURISM PROJECT FOR DEPOPULATED RURAL REGIONS: THE CASE OF PORTUGAL MASTER IN INTERNATIONAL BUSINESS Antonio Agostinho Oliveira dos Santos No. 2182013 Leiria, March 2021 A CHANCE FOR PLACES THAT DON’T MATTER. PLACE-BASED SUSTAINABLE TOURISM PROJECT FOR DEPOPULATED RURAL REGIONS: THE CASE OF PORTUGAL MASTER IN INTERNATIONAL BUSINESS Antonio Agostinho Oliveira dos Santos No. 2182013 Project Report under the supervision of Professor Doutor Jaime Manuel Afonso Ramos Guerra (ESTG) and Professor Doutor João Paulo da Conceição Silva Jorge (ESTM) Leiria, March 2021 II ORIGINALITY AND COPYRIGHT This project report is original, made by Antonio Agostinho Oliveira Santos, only for this purpose, and all authors whose studies and publications were used to complete it are dully acknowledged. Partial reproduction of this document is authorized, provided that the Author is explicitly mentioned, as well as the study cycle. i.e. Master degree in International Business, 2019/2020 academic year, of the School of Technology and Management of the Polytechnic Institute of Leiria, and the date of the public presentation of this work. III In memory of my grandparents, Antonio, Maria da Trindade, Augusto e Maria da Conceição and to my parents, Cidalina and Armenio, who worked hard to give us education, and to conquer every inch of land, and every roof, to proudly leave us in inheritance. To my daughter Carolina and my son Gonçalo, and to my wife Gloria. IV AKNOWLEDGMENTS First and foremost, I wish to thank Professor Jaime Ramos Guerra and Professor Joao Paulo Conceição Jorge, for their insights, willingness, support and patience with me along this work.