AMD Optimizing CPU Libraries User Guide Version 2.1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(LINUX) Computer in Three Parts
Science on a (LINUX) computer in three parts Introductory short couse, Part II Thorsten Becker University of Southern California, Los Angeles September 2007 The first part dealt with ● UNIX: what and why ● File system, Window managers ● Shell environment ● Editing files ● Command line tools ● Scripts and GUIs ● Virtualization Contents part II ● Typesetting ● Programming – common languages – philosophy – compiling, debugging, make, version control – C and F77 interfacing – libraries and packages ● Number crunching ● Visualization tools Programming: Traditional languages in the natural sciences ● Fortran: higher level, good for math – F77: legacy, don't use (but know how to read) – F90/F95: nice vector features, finally implements C capabilities (structures, memory allocation) ● C: low level (e.g. pointers), better structured – very close to UNIX philosophy – structures offer nice way of modular programming, see Wikipedia on C ● I recommend F95, and use C happily myself Programming: Some Languages that haven't completely made it to scientific computing ● C++: object oriented programming model – reusable objects with methods and such – can be partly realized by modular programming in C ● Java: what's good for commercial projects (or smart, or elegant) doesn't have to be good for scientific computing ● Concern about portability as well as general access Programming: Compromises ● Python – Object oriented – Interpreted – Interfaces easily with F90/C – Numerous scientific packages Programming: Other interpreted, high- abstraction languages -

Some Notes on BLAS, SIMD, MIC and GPGPU (For Octave and Matlab)
Some Notes on BLAS, SIMD, MIC and GPGPU (for Octave and Matlab) Christian Himpe ([email protected]) WWU Münster Institute for Computational and Applied Mathematics Software-Tools für die Numerische Mathematik 15.10.2014 About1 BLAS & LAPACK Affinity SIMD Automatic Offloading 1 Get your Buzzword-Bingo ready! BLAS & LAPACK BLAS (Basic Linear Algebra System) Level 1: vector-vector operations (dot-product, vector norms, generalized vector addition) Level 2: matrix-vector operations (generalized matrix-vector multiplication) Level 3: matrix-matrix operations (generalized matrix-matrix multiplication) LAPACK (Linear Algebra Package) Matrix Factorizations: LU, QR, Cholesky, Schur Least-Squares: LLS, LSE, GLM Eigenproblems: SEP, NEP, SVD Default (un-optimized) netlib reference implementation. Used by Octave, Matlab, SciPy/NumPy (Python), Julia, R. MKL Intel’s implementation of BLAS and LAPACK. MKL (Math Kernel Library) can offload computations to XeonPhi can use OpenMP provides additionally FFT, libm and 1D-interpolation Current Version: 11.0.5 (automatic offloading to Phis) Costs (we have it, and Matlab ships with it, too) Go to: https://software.intel.com/en-us/intel-mkl ACML AMD doesn’t want to be left out. ACML (AMD Core Math Libraries) Can use OpenCL for automatic offloading to GPUs Special version to exploit FMA(4) instructions Choice of compiled binaries (GFortran, Intel Fortran, Open64, PGI) Current Version: 6 (automatic offloading to GPUs) Free (but not open source) Go to: http://developer.amd.com/tools-and-sdks/ cpu-development/amd-core-math-library-acml OpenBLAS Open Source, the third kind. OpenBLAS Fork of GotoBLAS Good performance for dense operations (close to the MKL) Can use OpenMP and is compiled for specific architecture Current Version: 0.2.11 Open source (!) Go to: http://github.com/xianyi/OpenBLAS FlexiBLAS So many BLAS implementations, so little time.. -

Red Hat Developer Toolset 9 User Guide
Red Hat Developer Toolset 9 User Guide Installing and Using Red Hat Developer Toolset Last Updated: 2020-08-07 Red Hat Developer Toolset 9 User Guide Installing and Using Red Hat Developer Toolset Zuzana Zoubková Red Hat Customer Content Services Olga Tikhomirova Red Hat Customer Content Services [email protected] Supriya Takkhi Red Hat Customer Content Services Jaromír Hradílek Red Hat Customer Content Services Matt Newsome Red Hat Software Engineering Robert Krátký Red Hat Customer Content Services Vladimír Slávik Red Hat Customer Content Services Legal Notice Copyright © 2020 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. -

Parallel Programming Models for Dense Linear Algebra on Heterogeneous Systems
DOI: 10.14529/jsfi150405 Parallel Programming Models for Dense Linear Algebra on Heterogeneous Systems M. Abalenkovs1, A. Abdelfattah2, J. Dongarra 1,2,3, M. Gates2, A. Haidar2, J. Kurzak2, P. Luszczek2, S. Tomov2, I. Yamazaki2, A. YarKhan2 c The Authors 2015. This paper is published with open access at SuperFri.org We present a review of the current best practices in parallel programming models for dense linear algebra (DLA) on heterogeneous architectures. We consider multicore CPUs, stand alone manycore coprocessors, GPUs, and combinations of these. Of interest is the evolution of the programming models for DLA libraries – in particular, the evolution from the popular LAPACK and ScaLAPACK libraries to their modernized counterparts PLASMA (for multicore CPUs) and MAGMA (for heterogeneous architectures), as well as other programming models and libraries. Besides providing insights into the programming techniques of the libraries considered, we outline our view of the current strengths and weaknesses of their programming models – especially in regards to hardware trends and ease of programming high-performance numerical software that current applications need – in order to motivate work and future directions for the next generation of parallel programming models for high-performance linear algebra libraries on heterogeneous systems. Keywords: Programming models, runtime, HPC, GPU, multicore, dense linear algebra. Introduction Parallelism in today’s computer architectures is pervasive – not only in systems from large supercomputers to laptops, but also in small portable devices like smart phones and watches. Along with parallelism, the level of heterogeneity in modern computing systems is also gradually increasing. Multicore CPUs are often combined with discrete high-performance accelerators like graphics processing units (GPUs) and coprocessors like Intel’s Xeon Phi, but are also included as integrated parts with system-on-chip (SoC) platforms, as in the AMD Fusion family of ap- plication processing units (APUs) or the NVIDIA Tegra mobile family of devices. -

Download Chapter 3: "Configuring Your Project with Autoconf"
CONFIGURING YOUR PROJECT WITH AUTOCONF Come my friends, ’Tis not too late to seek a newer world. —Alfred, Lord Tennyson, “Ulysses” Because Automake and Libtool are essen- tially add-on components to the original Autoconf framework, it’s useful to spend some time focusing on using Autoconf without Automake and Libtool. This will provide a fair amount of insight into how Autoconf operates by exposing aspects of the tool that are often hidden by Automake. Before Automake came along, Autoconf was used alone. In fact, many legacy open source projects never made the transition from Autoconf to the full GNU Autotools suite. As a result, it’s not unusual to find a file called configure.in (the original Autoconf naming convention) as well as handwritten Makefile.in templates in older open source projects. In this chapter, I’ll show you how to add an Autoconf build system to an existing project. I’ll spend most of this chapter talking about the fundamental features of Autoconf, and in Chapter 4, I’ll go into much more detail about how some of the more complex Autoconf macros work and how to properly use them. Throughout this process, we’ll continue using the Jupiter project as our example. Autotools © 2010 by John Calcote Autoconf Configuration Scripts The input to the autoconf program is shell script sprinkled with macro calls. The input stream must also include the definitions of all referenced macros—both those that Autoconf provides and those that you write yourself. The macro language used in Autoconf is called M4. (The name means M, plus 4 more letters, or the word Macro.1) The m4 utility is a general-purpose macro language processor originally written by Brian Kernighan and Dennis Ritchie in 1977. -

AMD Core Math Library (ACML)
AMD Core Math Library (ACML) Version 4.2.0 Copyright c 2003-2008 Advanced Micro Devices, Inc., Numerical Algorithms Group Ltd. AMD, the AMD Arrow logo, AMD Opteron, AMD Athlon and combinations thereof are trademarks of Advanced Micro Devices, Inc. i Short Contents 1 Introduction................................... 1 2 General Information ............................. 2 3 BLAS: Basic Linear Algebra Subprograms ............. 19 4 LAPACK: Package of Linear Algebra Subroutines ........ 20 5 Fast Fourier Transforms (FFTs) .................... 24 6 Random Number Generators....................... 75 7 ACML MV: Fast Math and Fast Vector Math Library .... 163 8 References .................................. 229 Subject Index ................................... 230 Routine Index ................................... 233 ii Table of Contents 1 Introduction ............................... 1 2 General Information ....................... 2 2.1 Determining the best ACML version for your system ........... 2 2.2 Accessing the Library (Linux) ................................ 4 2.2.1 Accessing the Library under Linux using GNU gfortran/gcc ......................................................... 4 2.2.2 Accessing the Library under Linux using PGI compilers pgf77/pgf90/pgcc ......................................... 5 2.2.3 Accessing the Library under Linux using PathScale compilers pathf90/pathcc ........................................... 6 2.2.4 Accessing the Library under Linux using the NAGWare f95 compiler................................................. -
Building Multi-File Programs with the Make Tool
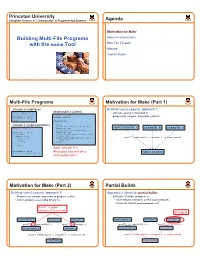
Princeton University Computer Science 217: Introduction to Programming Systems Agenda Motivation for Make Building Multi-File Programs Make Fundamentals with the make Tool Non-File Targets Macros Implicit Rules 1 2 Multi-File Programs Motivation for Make (Part 1) intmath.h (interface) Building testintmath, approach 1: testintmath.c (client) #ifndef INTMATH_INCLUDED • Use one gcc217 command to #define INTMATH_INCLUDED #include "intmath.h" int gcd(int i, int j); #include <stdio.h> preprocess, compile, assemble, and link int lcm(int i, int j); #endif int main(void) { int i; intmath.c (implementation) int j; printf("Enter the first integer:\n"); #include "intmath.h" scanf("%d", &i); testintmath.c intmath.h intmath.c printf("Enter the second integer:\n"); int gcd(int i, int j) scanf("%d", &j); { int temp; printf("Greatest common divisor: %d.\n", while (j != 0) gcd(i, j)); { temp = i % j; printf("Least common multiple: %d.\n", gcc217 testintmath.c intmath.c –o testintmath i = j; lcm(i, j); j = temp; return 0; } } return i; } Note: intmath.h is int lcm(int i, int j) #included into intmath.c { return (i / gcd(i, j)) * j; testintmath } and testintmath.c 3 4 Motivation for Make (Part 2) Partial Builds Building testintmath, approach 2: Approach 2 allows for partial builds • Preprocess, compile, assemble to produce .o files • Example: Change intmath.c • Link to produce executable binary file • Must rebuild intmath.o and testintmath • Need not rebuild testintmath.o!!! Recall: -c option tells gcc217 to omit link changed testintmath.c intmath.h intmath.c -

35.232-2016.43 Lamees Elhiny.Pdf
LOAD PARTITIONING FOR MATRIX-MATRIX MULTIPLICATION ON A CLUSTER OF CPU-GPU NODES USING THE DIVISIBLE LOAD PARADIGM by Lamees Elhiny A Thesis Presented to the Faculty of the American University of Sharjah College of Engineering in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Engineering Sharjah, United Arab Emirates November 2016 c 2016. Lamees Elhiny. All rights reserved. Approval Signatures We, the undersigned, approve the Master’s Thesis of Lamees Elhiny Thesis Title: Load Partitioning for Matrix-Matrix Multiplication on a Cluster of CPU- GPU Nodes Using the Divisible Load Paradigm Signature Date of Signature (dd/mm/yyyy) ___________________________ _______________ Dr. Gerassimos Barlas Professor, Department of Computer Science and Engineering Thesis Advisor ___________________________ _______________ Dr. Khaled El-Fakih Associate Professor, Department of Computer Science and Engineering Thesis Committee Member ___________________________ _______________ Dr. Naoufel Werghi Associate Professor, Electrical and Computer Engineering Department Khalifa University of Science, Technology & Research (KUSTAR) Thesis Committee Member ___________________________ _______________ Dr. Fadi Aloul Head, Department of Computer Science and Engineering ___________________________ _______________ Dr. Mohamed El-Tarhuni Associate Dean, College of Engineering ___________________________ _______________ Dr. Richard Schoephoerster Dean, College of Engineering ___________________________ _______________ Dr. Khaled Assaleh Interim Vice Provost for Research and Graduate Studies Acknowledgements I would like to express my sincere gratitude to my thesis advisor, Dr. Gerassi- mos Barlas, for his guidance at every step throughout the thesis. I am thankful to Dr. Assim Sagahyroon, and to the Department of Computer Science & Engineering as well as the American University of Sharjah for offering me the Graduate Teaching Assistantship, which allowed me to pursue my graduate studies. -

Parallel Siesta.Graffle
Siesta in parallel Toby White Dept. Earth Sciences, University of Cambridge ❖ How to build Siesta in parallel ❖ How to run Siesta in parallel ❖ How Siesta works in parallel ❖ How to use parallelism efficiently ❖ How to build Siesta in parallel Siesta SCALAPACK BLACS LAPACK MPI BLAS LAPACK Vector/matrix BLAS manipulation Linear Algebra PACKage http://netlib.org/lapack/ Basic Linear Algebra Subroutines http://netlib.org/blas/ ATLAS BLAS: http://atlas.sf.net Free, open source (needs separate LAPACK) GOTO BLAS: http://www.tacc.utexas.edu/resources/software/#blas Free, registration required, source available (needs separate LAPACK) Intel MKL (Math Kernel Library): Intel compiler only Not cheap (but often installed on supercomputers) ACML (AMD Core Math Library) http://developer.amd.com/acml.jsp Free, registration required. Versions for most compilers. Sun Performance Library http://developers.sun.com/sunstudio/perflib_index.html Free, registration required. Only for Sun compilers (Linux/Solaris) IBM ESSL (Engineering & Science Subroutine Library) http://www-03.ibm.com/systems/p/software/essl.html Free, registration required. Only for IBM compilers (Linux/AIX) Parallel MPI communication Message Passing Infrastructure http://www.mcs.anl.gov/mpi/ You probably don't care - your supercomputer will have (at least one) MPI version installed. Just in case, if you are building your own cluster: MPICH2: http://www-unix.mcs.anl.gov/mpi/mpich2/ Open-MPI: http://www.open-mpi.org And a lot of experimental super-fast versions ... SCALAPACK BLACS Parallel linear algebra Basic Linear Algebra Communication Subprograms http://netlib.org/blacs/ SCAlable LAPACK http://netlib.org/scalapack/ Intel MKL (Math Kernel Library): Intel compiler only AMCL (AMD Core Math Library) http://developer.amd.com/acml.jsp S3L (Sun Scalable Scientific Program Library) http://www.sun.com/software/products/clustertools/ IBM PESSL (Parallel Engineering & Science Subroutine Library) http://www-03.ibm.com/systems/p/software/essl.html Previously mentioned libraries are not the only ones - just most common. -

Assessing Unikernel Security April 2, 2019 – Version 1.0
NCC Group Whitepaper Assessing Unikernel Security April 2, 2019 – Version 1.0 Prepared by Spencer Michaels Jeff Dileo Abstract Unikernels are small, specialized, single-address-space machine images constructed by treating component applications and drivers like libraries and compiling them, along with a kernel and a thin OS layer, into a single binary blob. Proponents of unikernels claim that their smaller codebase and lack of excess services make them more efficient and secure than full-OS virtual machines and containers. We surveyed two major unikernels, Rumprun and IncludeOS, and found that this was decidedly not the case: unikernels, which in many ways resemble embedded systems, appear to have a similarly minimal level of security. Features like ASLR, W^X, stack canaries, heap integrity checks and more are either completely absent or seriously flawed. If an application running on such a system contains a memory corruption vulnerability, it is often possible for attackers to gain code execution, even in cases where the applica- tion’s source and binary are unknown. Furthermore, because the application and the kernel run together as a single process, an attacker who compromises a unikernel can immediately exploit functionality that would require privilege escalation on a regular OS, e.g. arbitrary packet I/O. We demonstrate such attacks on both Rumprun and IncludeOS unikernels, and recommend measures to mitigate them. Table of Contents 1 Introduction to Unikernels . 4 2 Threat Model Considerations . 5 2.1 Unikernel Capabilities ................................................................ 5 2.2 Unikernels Versus Containers .......................................................... 5 3 Hypothesis . 6 4 Testing Methodology . 7 4.1 ASLR ................................................................................ 7 4.2 Page Protections .................................................................... -

AMD Core Math Library (ACML) ©
¨ AMD Core Math Library (ACML) © Version 5.3.1 Copyright c 2003-2013 Advanced Micro Devices, Inc., Numerical Algorithms Group Ltd. All rights reserved. The contents of this document are provided in connection with Advanced Micro Devices, Inc. (\AMD") products. AMD makes no representations or warranties with respect to the accuracy or completeness of the contents of this publication and reserves the right to make changes to specifications and product descriptions at any time without notice. The information contained herein may be of a preliminary or advance nature and is subject to change without notice. No license, whether express, implied, arising by estoppel, or oth- erwise, to any intellectual property rights are granted by this publication. Except as set forth in AMD's Standard Terms and Conditions of Sale, AMD assumes no liability whatso- ever, and disclaims any express or implied warranty, relating to its products including, but not limited to, the implied warranty of merchantability, fitness for a particular purpose, or infringement of any intellectual property right. AMD's products are not designed, intended, authorized or warranted for use as components in systems intended for surgical implant into the body, or in other applications intended to support or sustain life, or in any other application in which the failure of AMD's product could create a situation where personal injury, death, or severe property or environmental damage may occur. AMD reserves the right to discontinue or make changes to its products at any time without notice. Trademarks AMD, the AMD Arrow logo, and combinations thereof, AMD Athlon, and AMD Opteron are trademarks of Advanced Micro Devices, Inc. -

Best Practice Guide - Generic X86 Vegard Eide, NTNU Nikos Anastopoulos, GRNET Henrik Nagel, NTNU 02-05-2013
Best Practice Guide - Generic x86 Vegard Eide, NTNU Nikos Anastopoulos, GRNET Henrik Nagel, NTNU 02-05-2013 1 Best Practice Guide - Generic x86 Table of Contents 1. Introduction .............................................................................................................................. 3 2. x86 - Basic Properties ................................................................................................................ 3 2.1. Basic Properties .............................................................................................................. 3 2.2. Simultaneous Multithreading ............................................................................................. 4 3. Programming Environment ......................................................................................................... 5 3.1. Modules ........................................................................................................................ 5 3.2. Compiling ..................................................................................................................... 6 3.2.1. Compilers ........................................................................................................... 6 3.2.2. General Compiler Flags ......................................................................................... 6 3.2.2.1. GCC ........................................................................................................ 6 3.2.2.2. Intel ........................................................................................................