The Extraction of the ¯ D/¯U Ratio in Nuclear Media
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unification of Nature's Fundamental Forces
Unification of Nature’s Geoffrey B. West Fredrick M. Cooper Fundamental Forces Emil Mottola a continuing search Michael P. Mattis it was explicitly recognized at the time that basic research had an im- portant and seminal role to play even in the highly programmatic en- vironment of the Manhattan Project. Not surprisingly this mode of opera- tion evolved into the remarkable and unique admixture of pure, applied, programmatic, and technological re- search that is the hallmark of the present Laboratory structure. No- where in the world today can one find under one roof such diversity of talent dealing with such a broad range of scientific and technological challenges—from questions con- cerning the evolution of the universe and the nature of elementary parti- cles to the structure of new materi- als, the design and control of weapons, the mysteries of the gene, and the nature of AIDS! Many of the original scientists would have, in today’s parlance, identified themselves as nuclear or particle physicists. They explored the most basic laws of physics and continued the search for and under- standing of the “fundamental build- ing blocks of nature’’ and the princi- t is a well-known, and much- grappled with deep questions con- ples that govern their interactions. overworked, adage that the group cerning the consequences of quan- It is therefore fitting that this area of Iof scientists brought to Los tum mechanics, the structure of the science has remained a highly visi- Alamos to work on the Manhattan atom and its nucleus, and the devel- ble and active component of the Project constituted the greatest as- opment of quantum electrodynamics basic research activity at Los Alam- semblage of scientific talent ever (QED, the relativistic quantum field os. -

The Growth of Scientific Communities in Japan^
The Growth of Scientific Communities in Japan^ Mitsutomo Yuasa** 1. Introdution The first university in Japan on the European system was Tokyo Imperial University, established in 1877. Twenty years later, Kyoto Imperial University was founded in 1897. Among the graduates from the latter university can be found two post World War II Nobel Prize winners in physics, namely, Hideki Yukawa (in 1949), and Shinichiro Tomonaga (in 1965). We may say that Japan attained her scientific maturity nearly a century after the arrival of Commodore Perry in 1853 for the purpose of opening her ports. Incidentally, two scientists in the U.S.A. were awarded the Nobel Prize before 1920, namely, A. A. Michelson (physics in 1907), and T. W. Richard (chemistry in 1914). On this point, Japan lagged about fifty years behind the U.S.A. Japanese scientists began to achieve international recognition in the 1890's. This period conincides with the dates of the establishment of the Cabinet System, the promulgation of the Constitution of the Japanese Empire and the opening of the Imperial Diet, 1885, 1889, and 1890 respectively. Shibasaburo Kitazato (1852-1931), discovered the serum treatment for tetanus in 1890, Jiro ICitao (1853- 1907), made public his theories on the movement of atomospheric currents and typhoons in 1887, and Hantaro Nagaoka (1865-1950), published his research on the distortion of magnetism in 1889, and his idea on the structure of the atom in 1903. These three representative scientists were all closely related to Tokyo Imperial University, as graduates and latter, as professors. But we cannot forget to men tion that the main studies of Kitazato and Kitao were made, not in Japan, but in Germany, under the guidance of great scientists of that country, R. -

People and Things
People and things An irresistible photograph: at a StAC Christmas party. Laboratory Director Pief Panofsky was presented with a CERN T-shirt, which he promptly put on. With him in the picture are (left to right) Roger Gear hart playing a seasonal master of ceremonies role, J. J. Murray and Ed Seppi. On people Elected vice-president of the Amer ican Physical Society for this year is Robert E. Marshak of Virginia Polytechnic Institute and State Uni versity. He succeeds Maurice Goldhaberr who becomes president elect. The new APS president is Arthur Schawlow of Stanford. In the same elections, Columbia theorist Malvin Ruder man was elected to serve for four years as councillor-at-large. Gisbert zu Pulitz, Scientific Director of the Darmstadt Heavy Ion Linear Accelerator Laboratory and Profes sor of Physics at the University of Heidelberg, has been elected as the new Chairman of the Association of German Research Centres (Ar- beitsgemeinschaft der Grossfor- schungseinrichtungen in der Bun- desrepublik Deutschland), succeed ing Herwig Schopper. The Associa the American Association for the tion includes the Julich and Karls Advancement of Science. ruhe nuclear research centres, LEP optimization DESY, and the Max Planck Institute for Plasma Physics as well as other The detail of the LEP electron-posi centres in the technical and biome tron storage ring project continues dical fields. to be studied so as to optimize the Moves at Brookhaven machine parameters from the point of view of performance and of cost. Nick Samios, former chairman of This optimization stays within the Brookhaven's Physics Department, description of Phase I of LEP which becomes the Laboratory's Deputy was agreed by the Member States Director for High Energy and Nu at the CERN Council meeting in clear Physics. -

The Twenty-First Century Paradigm and the Role of Information Technology
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Springer - Publisher Connector Chapter 2 The Twenty-First Century Paradigm and the Role of Information Technology In Chap. 1 , we considered demand by roughly classifying it into two types: “diffusive demand” and “creative demand.” The “paradigm of the twentieth century and before” was characterized by diffu- sive demand. The paradigm was constituted by a material desire to satisfy needs for food, clothing, and shelter, as well as transportation, and social mobility. Many of the industries that came into being in the nineteenth and twentieth centuries were intended to satisfy such desires. I describe those material desires as diffusive demand leading to a “saturation of man-made objects .” It follows that new demand in the twenty-fi rst century will be generated by a new paradigm. Thus, in this chapter fi rst describes what the paradigms of the twenty-fi rst century are and then refl ects on the role played by the knowledge explosion, one of those paradigms, and the role played by information technology, which looks as if it came into being to solve problems created by the knowledge explosion. Exploding Knowledge, Limited Earth, and Aging Society What are the paradigms of the twenty-fi rst century? I believe there are three, which I classify as “exploding knowledge ,” “limited earth,” and “aging society” (Fig. 2.1 ). These three paradigms do not represent anything that is either good or bad for humanity. Each constitutes a basic framework containing both light and shadow. For instance, there has been an explosive increase in knowledge . -
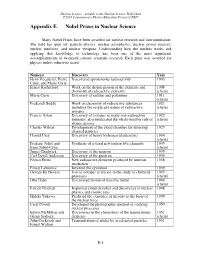
Appendix E Nobel Prizes in Nuclear Science
Nuclear Science—A Guide to the Nuclear Science Wall Chart ©2018 Contemporary Physics Education Project (CPEP) Appendix E Nobel Prizes in Nuclear Science Many Nobel Prizes have been awarded for nuclear research and instrumentation. The field has spun off: particle physics, nuclear astrophysics, nuclear power reactors, nuclear medicine, and nuclear weapons. Understanding how the nucleus works and applying that knowledge to technology has been one of the most significant accomplishments of twentieth century scientific research. Each prize was awarded for physics unless otherwise noted. Name(s) Discovery Year Henri Becquerel, Pierre Discovered spontaneous radioactivity 1903 Curie, and Marie Curie Ernest Rutherford Work on the disintegration of the elements and 1908 chemistry of radioactive elements (chem) Marie Curie Discovery of radium and polonium 1911 (chem) Frederick Soddy Work on chemistry of radioactive substances 1921 including the origin and nature of radioactive (chem) isotopes Francis Aston Discovery of isotopes in many non-radioactive 1922 elements, also enunciated the whole-number rule of (chem) atomic masses Charles Wilson Development of the cloud chamber for detecting 1927 charged particles Harold Urey Discovery of heavy hydrogen (deuterium) 1934 (chem) Frederic Joliot and Synthesis of several new radioactive elements 1935 Irene Joliot-Curie (chem) James Chadwick Discovery of the neutron 1935 Carl David Anderson Discovery of the positron 1936 Enrico Fermi New radioactive elements produced by neutron 1938 irradiation Ernest Lawrence -

Geometric Approaches to Quantum Field Theory
GEOMETRIC APPROACHES TO QUANTUM FIELD THEORY A thesis submitted to The University of Manchester for the degree of Doctor of Philosophy in the Faculty of Science and Engineering 2020 Kieran T. O. Finn School of Physics and Astronomy Supervised by Professor Apostolos Pilaftsis BLANK PAGE 2 Contents Abstract 7 Declaration 9 Copyright 11 Acknowledgements 13 Publications by the Author 15 1 Introduction 19 1.1 Unit Independence . 20 1.2 Reparametrisation Invariance in Quantum Field Theories . 24 1.3 Example: Complex Scalar Field . 25 1.4 Outline . 31 1.5 Conventions . 34 2 Field Space Covariance 35 2.1 Riemannian Geometry . 35 2.1.1 Manifolds . 35 2.1.2 Tensors . 36 2.1.3 Connections and the Covariant Derivative . 37 2.1.4 Distances on the Manifold . 38 2.1.5 Curvature of a Manifold . 39 2.1.6 Local Normal Coordinates and the Vielbein Formalism 41 2.1.7 Submanifolds and Induced Metrics . 42 2.1.8 The Geodesic Equation . 42 2.1.9 Isometries . 43 2.2 The Field Space . 44 2.2.1 Interpretation of the Field Space . 48 3 2.3 The Configuration Space . 50 2.4 Parametrisation Dependence of Standard Approaches to Quan- tum Field Theory . 52 2.4.1 Feynman Diagrams . 53 2.4.2 The Effective Action . 56 2.5 Covariant Approaches to Quantum Field Theory . 59 2.5.1 Covariant Feynman Diagrams . 59 2.5.2 The Vilkovisky–DeWitt Effective Action . 62 2.6 Example: Complex Scalar Field . 66 3 Frame Covariance in Quantum Gravity 69 3.1 The Cosmological Frame Problem . -

Nobel Lectures™ 2001-2005
World Scientific Connecting Great Minds 逾10 0 种 诺贝尔奖得主著作 及 诺贝尔奖相关图书 我们非常荣幸得以出版超过100种诺贝尔奖得主著作 以及诺贝尔奖相关图书。 我们自1980年代开始与诺贝尔奖得主合作出版高品质 畅销书。一些得主担任我们的编辑顾问、丛书编辑, 并于我们期刊发表综述文章与学术论文。 世界科技与帝国理工学院出版社还邀得其中多位作了公 开演讲。 Philip W Anderson Sir Derek H R Barton Aage Niels Bohr Subrahmanyan Chandrasekhar Murray Gell-Mann Georges Charpak Nicolaas Bloembergen Baruch S Blumberg Hans A Bethe Aaron J Ciechanover Claude Steven Chu Cohen-Tannoudji Leon N Cooper Pierre-Gilles de Gennes Niels K Jerne Richard Feynman Kenichi Fukui Lawrence R Klein Herbert Kroemer Vitaly L Ginzburg David Gross H Gobind Khorana Rita Levi-Montalcini Harry M Markowitz Karl Alex Müller Sir Nevill F Mott Ben Roy Mottelson 诺贝尔奖相关图书 THE PERIODIC TABLE AND A MISSED NOBEL PRIZES THAT CHANGED MEDICINE NOBEL PRIZE edited by Gilbert Thompson (Imperial College London) by Ulf Lagerkvist & edited by Erling Norrby (The Royal Swedish Academy of Sciences) This book brings together in one volume fifteen Nobel Prize- winning discoveries that have had the greatest impact upon medical science and the practice of medicine during the 20th “This is a fascinating account of how century and up to the present time. Its overall aim is to groundbreaking scientists think and enlighten, entertain and stimulate. work. This is the insider’s view of the process and demands made on the Contents: The Discovery of Insulin (Robert Tattersall) • The experts of the Nobel Foundation who Discovery of the Cure for Pernicious Anaemia, Vitamin B12 assess the originality and significance (A Victor Hoffbrand) • The Discovery of -

Murray Gell-Mann Hadrons, Quarks And
A Life of Symmetry Dennis Silverman Department of Physics and Astronomy UC Irvine Biographical Background Murray Gell-Mann was born in Manhattan on Sept. 15, 1929, to Jewish parents from the Austro-Hungarian empire. His father taught German to Americans. Gell-Mann was a child prodigy interested in nature and math. He started Yale at 15 and graduated at 18 with a bachelors in Physics. He then went to graduate school at MIT where he received his Ph. D. in physics at 21 in 1951. His thesis advisor was the famous Vicky Weisskopf. His life and work is documented in remarkable detail on videos that he recorded on webofstories, which can be found by just Google searching “webofstories Gell-Mann”. The Young Murray Gell-Mann Gell-Mann’s Academic Career (from Wikipedia) He was a postdoctoral fellow at the Institute for Advanced Study in 1951, and a visiting research professor at the University of Illinois at Urbana– Champaign from 1952 to 1953. He was a visiting associate professor at Columbia University and an associate professor at the University of Chicago in 1954-55, where he worked with Fermi. After Fermi’s death, he moved to the California Institute of Technology, where he taught from 1955 until he retired in 1993. Web of Stories video of Gell-Mann on Fermi and Weisskopf. The Weak Interactions: Feynman and Gell-Mann •Feynman and Gell-Mann proposed in 1957 and 1958 the theory of the weak interactions that acted with a current like that of the photon, minus a similar one that included parity violation. -

A Peek Into Spin Physics
A Peek into Spin Physics Dustin Keller University of Virginia Colloquium at Kent State Physics Outline ● What is Spin Physics ● How Do we Use It ● An Example Physics ● Instrumentation What is Spin Physics The Physics of exploiting spin - Spin in nuclear reactions - Nucleon helicity structure - 3D Structure of nucleons - Fundamental symmetries - Spin probes in beyond SM - Polarized Beams and Targets,... What is Spin Physics What is Spin Physics ● The Physics of exploiting spin : By using Polarized Observables Spin: The intrinsic form of angular momentum carried by elementary particles, composite particles, and atomic nuclei. The Spin quantum number is one of two types of angular momentum in quantum mechanics, the other being orbital angular momentum. What is Spin Physics What Quantum Numbers? What is Spin Physics What Quantum Numbers? Internal or intrinsic quantum properties of particles, which can be used to uniquely characterize What is Spin Physics What Quantum Numbers? Internal or intrinsic quantum properties of particles, which can be used to uniquely characterize These numbers describe values of conserved quantities in the dynamics of a quantum system What is Spin Physics But a particle is not a sphere and spin is solely a quantum-mechanical phenomena What is Spin Physics Stern-Gerlach: If spin had continuous values like the classical picture we would see it What is Spin Physics Stern-Gerlach: Instead we see spin has only two values in the field with opposite directions: or spin-up and spin-down What is Spin Physics W. Pauli (1925) -

The Beta-Decay Induced by Neutrino Flux B
9 772153119007 0605 Journal of Modern Physics, 2020, 11, 593-765 https://www.scirp.org/journal/jmp ISSN Online: 2153-120X ISSN Print: 2153-1196 Table of Contents Volume 11 Number 5 May 2020 How to See Invisible Universes A. A. Antonov………………….………………………………………………………………………………………593 The Beta-Decay Induced by Neutrino Flux B. V. Vasiliev…………………………………………...………………………………………………………………608 The Pioneer Effect: A New Physics with a New Principle R. Bagdoo………………………………………………………………………………………………………………616 Density Profiles of Gases and Fluids in Gravitational Potentials from a Generalization of Hydrostatic Equilibrium R. B. Holmes………………………....…………………………………………………………………………………648 Photon Can Be Described as the Normalized Mutual Energy Flow S.-R. Zhao………………………………………………………………………………………………………………668 Kolmogorov’s Probability Spaces for “Entangled” Data-Subsets of EPRB Experiments: No Violation of Einstein’s Separation Principle K. Hess…………………………………….……………………………………………………………………………683 Melia’s Rh = ct Model Is by No Means Flat R. Burghardt…………………………...………………………………………….……………………………………703 Theoretical Prediction of Negative Energy Specific to the Electron K. Suto……………………………….…………………………………………………………………………………712 The Bell Inequalities: Identifying What Is Testable and What Is Not L. Sica……………………………………….…………………………………………..………………………………725 Proton and Neutron Electromagnetic Form Factors Based on Bound System in 3 + 1 Dimensional QCD T. Kurai…………………….……………………………………………………………..……………………………741 The figure on the front cover is from the article published in Journal of Modern Physics, 2020, -

High-Energy Physics from 1945 to 1952/ 53
CHS-17 March 1985 STUDIES IN CERN HISTORY High-energy physics from 1945 to 1952/ 53 Ulrike Mersits GENEVA 1985 The Study of CERN History is a project financed by Institutions in several CERN Member Countries. This report presents preliminary findings, and is intended for incorporation into a more comprehensive study of CERN's history. It is distributed primarily to historians and scientists to provoke discussion, and no part of it should be cited or reproduced without written permission from the Team Leader. Comments are welcome and should be sent to: Study Team for CERN History c/oCERN CH-1211 GENEVE23 Switzerland © Copyright Study Team for CERN History, Geneva 1985 CERN-Service d'information scientifique - 300- mars 1985 HIGH-ENERGY PHYSICS from 1945 to 1952/53 I. The scientific situation in 'elementary particle physics' around 1945/46 I.1. Cosmic-ray physics I.2 Nuclear physics II. Institutional changes in nuclear physics due to the war III. The post-war accelerator programmes III.1. The principle of phase stability III.2. The United States III.3. Great Britain - the leading country in Europe III.4. Continental western Europe III.5. AG focusing - another step into higher energy regions IV. Experimental particle physics: developments from 1946 to 1953 IV.1. The leptonic nature of the mesotron and the detection of the pi meson (1946/47) IV.2. The artificial production of charged and uncharged pi-mesons (1948/49) IV.3. The complexity of the mass spectrum (1947-1953) IV.3.1.The V-particles IV.3.2.The heavy mesons IV.3.3.The Bagneres-de-Bigorre Conference (1953) V. -

Lesson 49: Quarks
Lesson 49: Quarks By 1960 physicists felt pretty much like you do right now... confused! • Leptons are really small, and there are only six of them (and their antiparticles), so it seems like they are probably fundamental particles. • The hadrons (mesons and baryons) are really big, and there are so many of them, that it seems like maybe they are made up of just a few other smaller fundamental particles. ◦ In 1963 Murray Gell-Mann and George Zweig independently suggested the properties of the fundamental particles that make up the hadrons, named quarks. To explain the two most important hadrons, protons and neutrons, we only need two of these quarks... 2 up quark with a e charge → symbol is u. ◦ 3 1 down quark with a − e charge → symbol is d. ◦ 3 • This bothered physicists, since it involved having charges that were a fraction of an elementary charge, which had never been seen. electrons ◦ By 1967 the Stanford Linear Accelerator was u u being used to shoot high energy electrons at protons. The electrons deflected around the d proton in an uneven pattern that suggested the electrons proton charge of a proton was not evenly spread out, just as the quark model suggested. Illustration 1: The electrons are deflected around • The quark model eventually built up to having six the proton because of the concentration of quarks and their antiparticles (wow! just like there positively charged quarks near the top and are six leptons and their antiparticles). negatively charged quarks near the bottom. ◦ With these six quarks and their antiquarks we can explain all the hadrons.