Data Structures and Network Algorithms [Tarjan 1987-01-01].Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
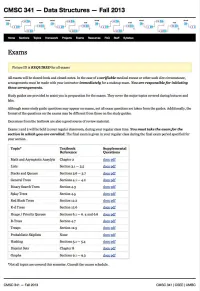
CMSC 341 Data Structure Asymptotic Analysis Review
CMSC 341 Data Structure Asymptotic Analysis Review These questions will help test your understanding of the asymptotic analysis material discussed in class and in the text. These questions are only a study guide. Questions found here may be on your exam, although perhaps in a different format. Questions NOT found here may also be on your exam. 1. What is the purpose of asymptotic analysis? 2. Define “Big-Oh” using a formal, mathematical definition. 3. Let T1(x) = O(f(x)) and T2(x) = O(g(x)). Prove T1(x) + T2(x) = O (max(f(x), g(x))). 4. Let T(x) = O(cf(x)), where c is some positive constant. Prove T(x) = O(f(x)). 5. Let T1(x) = O(f(x)) and T2(x) = O(g(x)). Prove T1(x) * T2(x) = O(f(x) * g(x)) 6. Prove 2n+1 = O(2n). 7. Prove that if T(n) is a polynomial of degree x, then T(n) = O(nx). 8. Number these functions in ascending (slowest growing to fastest growing) Big-Oh order: Number Big-Oh O(n3) O(n2 lg n) O(1) O(lg0.1 n) O(n1.01) O(n2.01) O(2n) O(lg n) O(n) O(n lg n) O (n lg5 n) 1 9. Determine, for the typical algorithms that you use to perform calculations by hand, the running time to: a. Add two N-digit numbers b. Multiply two N-digit numbers 10. What is the asymptotic performance of each of the following? Select among: a. O(n) b. -

Search Trees
Lecture III Page 1 “Trees are the earth’s endless effort to speak to the listening heaven.” – Rabindranath Tagore, Fireflies, 1928 Alice was walking beside the White Knight in Looking Glass Land. ”You are sad.” the Knight said in an anxious tone: ”let me sing you a song to comfort you.” ”Is it very long?” Alice asked, for she had heard a good deal of poetry that day. ”It’s long.” said the Knight, ”but it’s very, very beautiful. Everybody that hears me sing it - either it brings tears to their eyes, or else -” ”Or else what?” said Alice, for the Knight had made a sudden pause. ”Or else it doesn’t, you know. The name of the song is called ’Haddocks’ Eyes.’” ”Oh, that’s the name of the song, is it?” Alice said, trying to feel interested. ”No, you don’t understand,” the Knight said, looking a little vexed. ”That’s what the name is called. The name really is ’The Aged, Aged Man.’” ”Then I ought to have said ’That’s what the song is called’?” Alice corrected herself. ”No you oughtn’t: that’s another thing. The song is called ’Ways and Means’ but that’s only what it’s called, you know!” ”Well, what is the song then?” said Alice, who was by this time completely bewildered. ”I was coming to that,” the Knight said. ”The song really is ’A-sitting On a Gate’: and the tune’s my own invention.” So saying, he stopped his horse and let the reins fall on its neck: then slowly beating time with one hand, and with a faint smile lighting up his gentle, foolish face, he began.. -

Functional Data Structures with Isabelle/HOL
Functional Data Structures with Isabelle/HOL Tobias Nipkow Fakultät für Informatik Technische Universität München 2021-6-14 1 Part II Functional Data Structures 2 Chapter 6 Sorting 3 1 Correctness 2 Insertion Sort 3 Time 4 Merge Sort 4 1 Correctness 2 Insertion Sort 3 Time 4 Merge Sort 5 sorted :: ( 0a::linorder) list ) bool sorted [] = True sorted (x # ys) = ((8 y2set ys: x ≤ y) ^ sorted ys) 6 Correctness of sorting Specification of sort :: ( 0a::linorder) list ) 0a list: sorted (sort xs) Is that it? How about set (sort xs) = set xs Better: every x occurs as often in sort xs as in xs. More succinctly: mset (sort xs) = mset xs where mset :: 0a list ) 0a multiset 7 What are multisets? Sets with (possibly) repeated elements Some operations: f#g :: 0a multiset add mset :: 0a ) 0a multiset ) 0a multiset + :: 0a multiset ) 0a multiset ) 0a multiset mset :: 0a list ) 0a multiset set mset :: 0a multiset ) 0a set Import HOL−Library:Multiset 8 1 Correctness 2 Insertion Sort 3 Time 4 Merge Sort 9 HOL/Data_Structures/Sorting.thy Insertion Sort Correctness 10 1 Correctness 2 Insertion Sort 3 Time 4 Merge Sort 11 Principle: Count function calls For every function f :: τ 1 ) ::: ) τ n ) τ define a timing function Tf :: τ 1 ) ::: ) τ n ) nat: Translation of defining equations: E[[f p1 ::: pn = e]] = (Tf p1 ::: pn = T [[e]] + 1) Translation of expressions: T [[g e1 ::: ek]] = T [[e1]] + ::: + T [[ek]] + Tg e1 ::: ek All other operations (variable access, constants, constructors, primitive operations on bool and numbers) cost 1 time unit 12 Example: @ E[[ [] @ ys = ys ]] = (T@ [] ys = T [[ys]] + 1) = (T@ [] ys = 2) E[[ (x # xs)@ ys = x #(xs @ ys) ]] = (T@ (x # xs) ys = T [[x #(xs @ ys)]] + 1) = (T@ (x # xs) ys = T@ xs ys + 5) T [[x #(xs @ ys)]] = T [[x]] + T [[xs @ ys]] + T# x (xs @ ys) = 1 + (T [[xs]] + T [[ys]] + T@ xs ys) + 1 = 1 + (1 + 1 + T@ xs ys) + 1 13 if and case So far we model a call-by-value semantics Conditionals and case expressions are evaluated lazily. -

Leftist Trees
DEMO : Purchase from www.A-PDF.com to remove the watermark5 Leftist Trees 5.1 Introduction......................................... 5-1 5.2 Height-Biased Leftist Trees ....................... 5-2 Definition • InsertionintoaMaxHBLT• Deletion of Max Element from a Max HBLT • Melding Two Max HBLTs • Initialization • Deletion of Arbitrary Element from a Max HBLT Sartaj Sahni 5.3 Weight-Biased Leftist Trees....................... 5-8 University of Florida Definition • Max WBLT Operations 5.1 Introduction A single-ended priority queue (or simply, a priority queue) is a collection of elements in which each element has a priority. There are two varieties of priority queues—max and min. The primary operations supported by a max (min) priority queue are (a) find the element with maximum (minimum) priority, (b) insert an element, and (c) delete the element whose priority is maximum (minimum). However, many authors consider additional operations such as (d) delete an arbitrary element (assuming we have a pointer to the element), (e) change the priority of an arbitrary element (again assuming we have a pointer to this element), (f) meld two max (min) priority queues (i.e., combine two max (min) priority queues into one), and (g) initialize a priority queue with a nonzero number of elements. Several data structures: e.g., heaps (Chapter 3), leftist trees [2, 5], Fibonacci heaps [7] (Chapter 7), binomial heaps [1] (Chapter 7), skew heaps [11] (Chapter 6), and pairing heaps [6] (Chapter 7) have been proposed for the representation of a priority queue. The different data structures that have been proposed for the representation of a priority queue differ in terms of the performance guarantees they provide. -

Leftist Heap: Is a Binary Tree with the Normal Heap Ordering Property, but the Tree Is Not Balanced. in Fact It Attempts to Be Very Unbalanced!
Leftist heap: is a binary tree with the normal heap ordering property, but the tree is not balanced. In fact it attempts to be very unbalanced! Definition: the null path length npl(x) of node x is the length of the shortest path from x to a node without two children. The null path lengh of any node is 1 more than the minimum of the null path lengths of its children. (let npl(nil)=-1). Only the tree on the left is leftist. Null path lengths are shown in the nodes. Definition: the leftist heap property is that for every node x in the heap, the null path length of the left child is at least as large as that of the right child. This property biases the tree to get deep towards the left. It may generate very unbalanced trees, which facilitates merging! It also also means that the right path down a leftist heap is as short as any path in the heap. In fact, the right path in a leftist tree of N nodes contains at most lg(N+1) nodes. We perform all the work on this right path, which is guaranteed to be short. Merging on a leftist heap. (Notice that an insert can be considered as a merge of a one-node heap with a larger heap.) 1. (Magically and recursively) merge the heap with the larger root (6) with the right subheap (rooted at 8) of the heap with the smaller root, creating a leftist heap. Make this new heap the right child of the root (3) of h1. -

Binary Trees, Binary Search Trees
Binary Trees, Binary Search Trees www.cs.ust.hk/~huamin/ COMP171/bst.ppt Trees • Linear access time of linked lists is prohibitive – Does there exist any simple data structure for which the running time of most operations (search, insert, delete) is O(log N)? Trees • A tree is a collection of nodes – The collection can be empty – (recursive definition) If not empty, a tree consists of a distinguished node r (the root), and zero or more nonempty subtrees T1, T2, ...., Tk, each of whose roots are connected by a directed edge from r Some Terminologies • Child and parent – Every node except the root has one parent – A node can have an arbitrary number of children • Leaves – Nodes with no children • Sibling – nodes with same parent Some Terminologies • Path • Length – number of edges on the path • Depth of a node – length of the unique path from the root to that node – The depth of a tree is equal to the depth of the deepest leaf • Height of a node – length of the longest path from that node to a leaf – all leaves are at height 0 – The height of a tree is equal to the height of the root • Ancestor and descendant – Proper ancestor and proper descendant Example: UNIX Directory Binary Trees • A tree in which no node can have more than two children • The depth of an “average” binary tree is considerably smaller than N, eventhough in the worst case, the depth can be as large as N – 1. Example: Expression Trees • Leaves are operands (constants or variables) • The other nodes (internal nodes) contain operators • Will not be a binary tree if some operators are not binary Tree traversal • Used to print out the data in a tree in a certain order • Pre-order traversal – Print the data at the root – Recursively print out all data in the left subtree – Recursively print out all data in the right subtree Preorder, Postorder and Inorder • Preorder traversal – node, left, right – prefix expression • ++a*bc*+*defg Preorder, Postorder and Inorder • Postorder traversal – left, right, node – postfix expression • abc*+de*f+g*+ • Inorder traversal – left, node, right. -

2 Graphs and Graph Theory
2 Graphs and Graph Theory chapter:graphs Graphs are the mathematical objects used to represent networks, and graph theory is the branch of mathematics that involves the study of graphs. Graph theory has a long history. The notion of graph was introduced for the first time in 1763 by Euler, to settle a famous unsolved problem of his days, the so-called “K¨onigsberg bridges” problem. It is no coin- cidence that the first paper on graph theory arose from the need to solve a problem from the real world. Also subsequent works in graph theory by Kirchhoff and Cayley had their root in the physical world. For instance, Kirchhoff’s investigations on electric circuits led to his development of a set of basic concepts and theorems concerning trees in graphs. Nowadays, graph theory is a well established discipline which is commonly used in areas as diverse as computer science, sociology, and biology. To make some examples, graph theory helps us to schedule airplane routings, and has solved problems such as finding the maximum flow per unit time from a source to a sink in a network of pipes, or coloring the regions of a map using the minimum number of different colors so that no neighbouring regions are colored the same way. In this chapter we introduce the basic definitions, set- ting up the language we will need in the following of the book. The two last sections are respectively devoted to the proof of the Euler theorem, and to the description of a graph as an array of numbers. -

Graphs Introduction and Depth-First Algorithm Carol Zander
Graphs Introduction and Depth‐first algorithm Carol Zander Introduction to graphs Graphs are extremely common in computer science applications because graphs are common in the physical world. Everywhere you look, you see a graph. Intuitively, a graph is a set of locations and edges connecting them. A simple example would be cities on a map that are connected by roads. Or cities connected by airplane routes. Another example would be computers in a local network that are connected to each other directly. Constellations of stars (among many other applications) can be also represented this way. Relationships can be represented as graphs. Section 9.1 has many good graph examples. Graphs can be viewed in three ways (trees, too, since they are special kind of graph): 1. A mathematical construction – this is how we will define them 2. An abstract data type – this is how we will think about interfacing with them 3. A data structure – this is how we will implement them The mathematical construction gives the definition of a graph: graph G = (V, E) consists of a set of vertices V (often called nodes) and a set of edges E (sometimes called arcs) that connect the edges. Each edge is a pair (u, v), such that u,v ∈V . Every tree is a graph, but not vice versa. There are two types of graphs, directed and undirected. In a directed graph, the edges are ordered pairs, for example (u,v), indicating that a path exists from u to v (but not vice versa, unless there is another edge.) For the edge, (u,v), v is said to be adjacent to u, but not the other way, i.e., u is not adjacent to v. -

Problem 1: “ Buzzin' in 3-Space” (36 Pts) Problem 2:“Ding Dong Bell
Name CMSC 420 Data Structures Sample Midterm Given Spring, 2000 Dr. Michelle Hugue Problem 1: “ Buzzin’ in 3-Space” (36 pts) (6) 1.1 Build a K-D tree from the set of points below using the following assumptions: • the points are inserted in alphabetical order by label • the x coordinate is the first key discriminator • if the key discriminators are equal, go left A: (0,7,1 ) B: (1,2,8) C: ( 6, 5,1) D: (4,0,6) E: (3,1,4) F: ( 4, 0,9) G: (9,9,10 ) H: (3,4,7) I: ( 1, 1,1) (6) 1.2 Explain an algorithm to identify all points within a k-d tree that are within a given distance, r, of the point (x0,y0,z0). Your algorithm should be efficient, in the sense that it should not always need to examine all the nodes. (6) 1.3 The three-dimensional analog of a point-quadtree is a point-octree. Give an expression for the minimum number of nodes in a left complete point-octree with levels numbered 0, 1,...,k. (6) 1.4 Explain the difficulties, if any, with deletion of nodes in a point octree. Hint: One way that deletions are performed is by re-inserting any nodes in the subtrees of the deleted one. Why? (6) 1.5 Describe a set of attributes of the data set, or any other reason, that would cause you to choose a k-d tree over a point-octree, and explain your reasoning. Or, if you can’t imagine ever choosing the k-d tree instead of the point-octree, explain why. -

Package 'Igraph'
Package ‘igraph’ February 28, 2013 Version 0.6.5-1 Date 2013-02-27 Title Network analysis and visualization Author See AUTHORS file. Maintainer Gabor Csardi <[email protected]> Description Routines for simple graphs and network analysis. igraph can handle large graphs very well and provides functions for generating random and regular graphs, graph visualization,centrality indices and much more. Depends stats Imports Matrix Suggests igraphdata, stats4, rgl, tcltk, graph, Matrix, ape, XML,jpeg, png License GPL (>= 2) URL http://igraph.sourceforge.net SystemRequirements gmp, libxml2 NeedsCompilation yes Repository CRAN Date/Publication 2013-02-28 07:57:40 R topics documented: igraph-package . .5 aging.prefatt.game . .8 alpha.centrality . 10 arpack . 11 articulation.points . 15 as.directed . 16 1 2 R topics documented: as.igraph . 18 assortativity . 19 attributes . 21 autocurve.edges . 23 barabasi.game . 24 betweenness . 26 biconnected.components . 28 bipartite.mapping . 29 bipartite.projection . 31 bonpow . 32 canonical.permutation . 34 centralization . 36 cliques . 39 closeness . 40 clusters . 42 cocitation . 43 cohesive.blocks . 44 Combining attributes . 48 communities . 51 community.to.membership . 55 compare.communities . 56 components . 57 constraint . 58 contract.vertices . 59 conversion . 60 conversion between igraph and graphNEL graphs . 62 convex.hull . 63 decompose.graph . 64 degree . 65 degree.sequence.game . 66 dendPlot . 67 dendPlot.communities . 68 dendPlot.igraphHRG . 70 diameter . 72 dominator.tree . 73 Drawing graphs . 74 dyad.census . 80 eccentricity . 81 edge.betweenness.community . 82 edge.connectivity . 84 erdos.renyi.game . 86 evcent . 87 fastgreedy.community . 89 forest.fire.game . 90 get.adjlist . 92 get.edge.ids . 93 get.incidence . 94 get.stochastic . -

Py4cytoscape Documentation Release 0.0.1
py4cytoscape Documentation Release 0.0.1 The Cytoscape Consortium Jun 21, 2020 CONTENTS 1 Audience 3 2 Python 5 3 Free Software 7 4 History 9 5 Documentation 11 6 Indices and tables 271 Python Module Index 273 Index 275 i ii py4cytoscape Documentation, Release 0.0.1 py4cytoscape is a Python package that communicates with Cytoscape via its REST API, providing access to a set over 250 functions that enable control of Cytoscape from within standalone and Notebook Python programming environ- ments. It provides nearly identical functionality to RCy3, an R package in Bioconductor available to R programmers. py4cytoscape provides: • functions that can be leveraged from Python code to implement network biology-oriented workflows; • access to user-written Cytoscape Apps that implement Cytoscape Automation protocols; • logging and debugging facilities that enable rapid development, maintenance, and auditing of Python-based workflow; • two-way conversion between the igraph and NetworkX graph packages, which enables interoperability with popular packages available in public repositories (e.g., PyPI); and • the ability to painlessly work with large data sets generated within Python or available on public repositories (e.g., STRING and NDEx). With py4cytoscape, you can leverage Cytoscape to: • load and store networks in standard and nonstandard data formats; • visualize molecular interaction networks and biological pathways; • integrate these networks with annotations, gene expression profiles and other state data; • analyze, profile, and cluster these networks based on integrated data, using new and existing algorithms. py4cytoscape enables an agile collaboration between powerful Cytoscape, Python libraries, and novel Python code so as to realize auditable, reproducible and sharable workflows. -

Priority Queues and Heaps
CMSC 206 Binary Heaps Priority Queues Priority Queues n Priority: some property of an object that allows it to be prioritized with respect to other objects of the same type n Min Priority Queue: homogeneous collection of Comparables with the following operations (duplicates are allowed). Smaller value means higher priority. q void insert (Comparable x) q void deleteMin( ) q Comparable findMin( ) q Construct from a set of initial values q boolean isEmpty( ) q boolean isFull( ) q void makeEmpty( ) Priority Queue Applications n Printer management: q The shorter document on the printer queue, the higher its priority. n Jobs queue within an operating system: q Users’ tasks are given priorities. System has high priority. n Simulations q The time an event “happens” is its priority. n Sorting (heap sort) q An elements “value” is its priority. Possible Implementations n Use a sorted list. Sorted by priority upon insertion. q findMin( ) --> list.front( ) q insert( ) --> list.insert( ) q deleteMin( ) --> list.erase( list.begin( ) ) n Use ordinary BST q findMin( ) --> tree.findMin( ) q insert( ) --> tree.insert( ) q deleteMin( ) --> tree.delete( tree.findMin( ) ) n Use balanced BST q guaranteed O(lg n) for Red-Black Min Binary Heap n A min binary heap is a complete binary tree with the further property that at every node neither child is smaller than the value in that node (or equivalently, both children are at least as large as that node). n This property is called a partial ordering. n As a result of this partial ordering, every path from the root to a leaf visits nodes in a non- decreasing order.