Host-Microbe Relations: a Phylogenomics-Driven Bioinformatic Approach to the Characterization of Microbial DNA from Heterogeneous Sequence Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
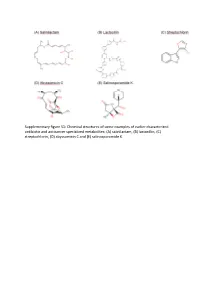
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

The 2014 Golden Gate National Parks Bioblitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event
National Park Service U.S. Department of the Interior Natural Resource Stewardship and Science The 2014 Golden Gate National Parks BioBlitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event Natural Resource Report NPS/GOGA/NRR—2016/1147 ON THIS PAGE Photograph of BioBlitz participants conducting data entry into iNaturalist. Photograph courtesy of the National Park Service. ON THE COVER Photograph of BioBlitz participants collecting aquatic species data in the Presidio of San Francisco. Photograph courtesy of National Park Service. The 2014 Golden Gate National Parks BioBlitz - Data Management and the Event Species List Achieving a Quality Dataset from a Large Scale Event Natural Resource Report NPS/GOGA/NRR—2016/1147 Elizabeth Edson1, Michelle O’Herron1, Alison Forrestel2, Daniel George3 1Golden Gate Parks Conservancy Building 201 Fort Mason San Francisco, CA 94129 2National Park Service. Golden Gate National Recreation Area Fort Cronkhite, Bldg. 1061 Sausalito, CA 94965 3National Park Service. San Francisco Bay Area Network Inventory & Monitoring Program Manager Fort Cronkhite, Bldg. 1063 Sausalito, CA 94965 March 2016 U.S. Department of the Interior National Park Service Natural Resource Stewardship and Science Fort Collins, Colorado The National Park Service, Natural Resource Stewardship and Science office in Fort Collins, Colorado, publishes a range of reports that address natural resource topics. These reports are of interest and applicability to a broad audience in the National Park Service and others in natural resource management, including scientists, conservation and environmental constituencies, and the public. The Natural Resource Report Series is used to disseminate comprehensive information and analysis about natural resources and related topics concerning lands managed by the National Park Service. -

하구 및 연안생태학 Estuarine and Coastal Ecology
하구 및 연안생태학 Estuarine and coastal ecology 2010 년 11월 2 계절적 변동 • 빛과 영양염분의 조건에 따라 • 봄 가을 대발생 계절적 변동 Sverdrup 에 의한 대발생 모델 • Compensation depth (보상심도) • Critical depth (임계수심) Sverdrup 에 의한 대발생 모델 홍재상외, 해양생물학 Sverdrup 에 의한 대발생 모델 봄 여름 가을 겨울 수심 혼합수심 임계수심 (mixed layer depth) (critical depth) Sverdrup 에 의한 대발생 모델 봄 여름 가을 겨울 수심 혼합수심 임계수심 (mixed layer depth) (critical depth) Diatoms (규조류) • Bacillariophyceae (1 fragment of centrics, 19 fragments of pennates in Devonian marble in Poland Kwiecinska & Sieminska 1974) Diatoms (규조류) • Bacillariophyceae • Temperate and high latitude (everywhere) Motility: present in pennate diatoms with a raphe (and male gametes) Resting cells (spores): heavily silicified, often with spines (Î보충설명) Biotopes: marine and freshwater, plankton, benthos, epiphytic, epizooic (e.g., on whales, crustaceans) endozoic, endophytic, discolouration of arctic and Antarctic sea ice Snow Algae (규조류 아님) Snow algae describes cold-tolerant algae and cyanobacteria that grow on snow and ice during alpine and polar summers. Visible algae blooms may be called red snow or watermelon snow. These extremophilic organisms are studied to understand the glacial ecosystem. Snow algae have been described in the Arctic, on Arctic sea ice, and in Greenland, the Antarctic, Alaska, the west coast, east coast, and continental divide of North America, the Himalayas, Japan, New Guinea, Europe (Alps, Scandinavia and Carpathians), China, Patagonia, Chile, and the South Orkney Islands. Diatoms (규조류) • Bacillariophyceae • Temperate and high latitude (everywhere) • 2~1000 um • siliceous frustules • Various patterns in frustule Centric vs Pennate Centric diatom Pennete small discoid plastid large plate plastid Navicula sp. -

Pinpointing the Origin of Mitochondria Zhang Wang Hanchuan, Hubei
Pinpointing the origin of mitochondria Zhang Wang Hanchuan, Hubei, China B.S., Wuhan University, 2009 A Dissertation presented to the Graduate Faculty of the University of Virginia in Candidacy for the Degree of Doctor of Philosophy Department of Biology University of Virginia August, 2014 ii Abstract The explosive growth of genomic data presents both opportunities and challenges for the study of evolutionary biology, ecology and diversity. Genome-scale phylogenetic analysis (known as phylogenomics) has demonstrated its power in resolving the evolutionary tree of life and deciphering various fascinating questions regarding the origin and evolution of earth’s contemporary organisms. One of the most fundamental events in the earth’s history of life regards the origin of mitochondria. Overwhelming evidence supports the endosymbiotic theory that mitochondria originated once from a free-living α-proteobacterium that was engulfed by its host probably 2 billion years ago. However, its exact position in the tree of life remains highly debated. In particular, systematic errors including sparse taxonomic sampling, high evolutionary rate and sequence composition bias have long plagued the mitochondrial phylogenetics. This dissertation employs an integrated phylogenomic approach toward pinpointing the origin of mitochondria. By strategically sequencing 18 phylogenetically novel α-proteobacterial genomes, using a set of “well-behaved” phylogenetic markers with lower evolutionary rates and less composition bias, and applying more realistic phylogenetic models that better account for the systematic errors, the presented phylogenomic study for the first time placed the mitochondria unequivocally within the Rickettsiales order of α- proteobacteria, as a sister clade to the Rickettsiaceae and Anaplasmataceae families, all subtended by the Holosporaceae family. -

Characterization of the Interaction Between R. Conorii and Human
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 4-5-2018 Characterization of the Interaction Between R. Conorii and Human Host Vitronectin in Rickettsial Pathogenesis Abigail Inez Fish Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Bacteria Commons, Bacteriology Commons, Biology Commons, Immunology of Infectious Disease Commons, and the Pathogenic Microbiology Commons Recommended Citation Fish, Abigail Inez, "Characterization of the Interaction Between R. Conorii and Human Host Vitronectin in Rickettsial Pathogenesis" (2018). LSU Doctoral Dissertations. 4566. https://digitalcommons.lsu.edu/gradschool_dissertations/4566 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. CHARACTERIZATION OF THE INTERACTION BETWEEN R. CONORII AND HUMAN HOST VITRONECTIN IN RICKETTSIAL PATHOGENESIS A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Interdepartmental Program in Biomedical and Veterinary Medical Sciences Through the Department of Pathobiological Sciences by Abigail Inez -

Flagellum Couples Cell Shape to Motility in Trypanosoma Brucei
Flagellum couples cell shape to motility in Trypanosoma brucei Stella Y. Suna,b,c, Jason T. Kaelberd, Muyuan Chene, Xiaoduo Dongf, Yasaman Nematbakhshg, Jian Shih, Matthew Doughertye, Chwee Teck Limf,g, Michael F. Schmidc, Wah Chiua,b,c,1, and Cynthia Y. Hef,h,1 aDepartment of Bioengineering, James H. Clark Center, Stanford University, Stanford, CA 94305; bDepartment of Microbiology and Immunology, James H. Clark Center, Stanford University, Stanford, CA 94305; cSLAC National Accelerator Laboratory, Stanford University, Menlo Park, CA 94025; dDepartment of Molecular Virology and Microbiology, Baylor College of Medicine, Houston, TX 77030; eVerna and Marrs McLean Department of Biochemistry and Molecular Biology, Baylor College of Medicine, Houston, TX 77030; fMechanobiology Institute, National University of Singapore, Singapore 117411; gDepartment of Mechanical Engineering, National University of Singapore, Singapore 117575; and hDepartment of Biological Sciences, Center for BioImaging Sciences, National University of Singapore, Singapore 117543 Contributed by Wah Chiu, May 17, 2018 (sent for review December 29, 2017; reviewed by Phillipe Bastin and Abraham J. Koster) In the unicellular parasite Trypanosoma brucei, the causative Cryo-electron tomography (cryo-ET) allows us to view 3D agent of human African sleeping sickness, complex swimming be- supramolecular details of biological samples preserved in their havior is driven by a flagellum laterally attached to the long and proper cellular context without chemical fixative and/or metal slender cell body. Using microfluidic assays, we demonstrated that stain. However, samples thicker than 1 μm are not accessible to T. brucei can penetrate through an orifice smaller than its maxi- cryo-ET because at typical accelerating voltages (≤300 kV), few mum diameter. -

Developing a Genetic Manipulation System for the Antarctic Archaeon, Halorubrum Lacusprofundi: Investigating Acetamidase Gene Function
www.nature.com/scientificreports OPEN Developing a genetic manipulation system for the Antarctic archaeon, Halorubrum lacusprofundi: Received: 27 May 2016 Accepted: 16 September 2016 investigating acetamidase gene Published: 06 October 2016 function Y. Liao1, T. J. Williams1, J. C. Walsh2,3, M. Ji1, A. Poljak4, P. M. G. Curmi2, I. G. Duggin3 & R. Cavicchioli1 No systems have been reported for genetic manipulation of cold-adapted Archaea. Halorubrum lacusprofundi is an important member of Deep Lake, Antarctica (~10% of the population), and is amendable to laboratory cultivation. Here we report the development of a shuttle-vector and targeted gene-knockout system for this species. To investigate the function of acetamidase/formamidase genes, a class of genes not experimentally studied in Archaea, the acetamidase gene, amd3, was disrupted. The wild-type grew on acetamide as a sole source of carbon and nitrogen, but the mutant did not. Acetamidase/formamidase genes were found to form three distinct clades within a broad distribution of Archaea and Bacteria. Genes were present within lineages characterized by aerobic growth in low nutrient environments (e.g. haloarchaea, Starkeya) but absent from lineages containing anaerobes or facultative anaerobes (e.g. methanogens, Epsilonproteobacteria) or parasites of animals and plants (e.g. Chlamydiae). While acetamide is not a well characterized natural substrate, the build-up of plastic pollutants in the environment provides a potential source of introduced acetamide. In view of the extent and pattern of distribution of acetamidase/formamidase sequences within Archaea and Bacteria, we speculate that acetamide from plastics may promote the selection of amd/fmd genes in an increasing number of environmental microorganisms. -

Periodic and Coordinated Gene Expression Between a Diazotroph and Its Diatom Host
The ISME Journal (2019) 13:118–131 https://doi.org/10.1038/s41396-018-0262-2 ARTICLE Periodic and coordinated gene expression between a diazotroph and its diatom host 1 1,2 1 3 4 Matthew J. Harke ● Kyle R. Frischkorn ● Sheean T. Haley ● Frank O. Aylward ● Jonathan P. Zehr ● Sonya T. Dyhrman1,2 Received: 11 April 2018 / Revised: 28 June 2018 / Accepted: 28 July 2018 / Published online: 16 August 2018 © International Society for Microbial Ecology 2018 Abstract In the surface ocean, light fuels photosynthetic carbon fixation of phytoplankton, playing a critical role in ecosystem processes including carbon export to the deep sea. In oligotrophic oceans, diatom–diazotroph associations (DDAs) play a keystone role in ecosystem function because diazotrophs can provide otherwise scarce biologically available nitrogen to the diatom host, fueling growth and subsequent carbon sequestration. Despite their importance, relatively little is known about the nature of these associations in situ. Here we used metatranscriptomic sequencing of surface samples from the North Pacific Subtropical Gyre (NPSG) to reconstruct patterns of gene expression for the diazotrophic symbiont Richelia and we – 1234567890();,: 1234567890();,: examined how these patterns were integrated with those of the diatom host over day night transitions. Richelia exhibited significant diel signals for genes related to photosynthesis, N2 fixation, and resource acquisition, among other processes. N2 fixation genes were significantly co-expressed with host nitrogen uptake and metabolism, as well as potential genes involved in carbon transport, which may underpin the exchange of nitrogen and carbon within this association. Patterns of expression suggested cell division was integrated between the host and symbiont across the diel cycle. -

“Candidatus Deianiraea Vastatrix” with the Ciliate Paramecium Suggests
bioRxiv preprint doi: https://doi.org/10.1101/479196; this version posted November 27, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The extracellular association of the bacterium “Candidatus Deianiraea vastatrix” with the ciliate Paramecium suggests an alternative scenario for the evolution of Rickettsiales 5 Castelli M.1, Sabaneyeva E.2, Lanzoni O.3, Lebedeva N.4, Floriano A.M.5, Gaiarsa S.5,6, Benken K.7, Modeo L. 3, Bandi C.1, Potekhin A.8, Sassera D.5*, Petroni G.3* 1. Centro Romeo ed Enrica Invernizzi Ricerca Pediatrica, Dipartimento di Bioscienze, Università 10 degli studi di Milano, Milan, Italy 2. Department of Cytology and Histology, Faculty of Biology, Saint Petersburg State University, Saint-Petersburg, Russia 3. Dipartimento di Biologia, Università di Pisa, Pisa, Italy 4 Centre of Core Facilities “Culture Collections of Microorganisms”, Saint Petersburg State 15 University, Saint Petersburg, Russia 5. Dipartimento di Biologia e Biotecnologie, Università degli studi di Pavia, Pavia, Italy 6. UOC Microbiologia e Virologia, Fondazione IRCCS Policlinico San Matteo, Pavia, Italy 7. Core Facility Center for Microscopy and Microanalysis, Saint Petersburg State University, Saint- Petersburg, Russia 20 8. Department of Microbiology, Faculty of Biology, Saint Petersburg State University, Saint- Petersburg, Russia * Corresponding authors, contacts: [email protected] ; [email protected] 1 bioRxiv preprint doi: https://doi.org/10.1101/479196; this version posted November 27, 2018. -

Construction and Loss of Bacterial Flagellar Filaments
biomolecules Review Construction and Loss of Bacterial Flagellar Filaments Xiang-Yu Zhuang and Chien-Jung Lo * Department of Physics and Graduate Institute of Biophysics, National Central University, Taoyuan City 32001, Taiwan; [email protected] * Correspondence: [email protected] Received: 31 July 2020; Accepted: 4 November 2020; Published: 9 November 2020 Abstract: The bacterial flagellar filament is an extracellular tubular protein structure that acts as a propeller for bacterial swimming motility. It is connected to the membrane-anchored rotary bacterial flagellar motor through a short hook. The bacterial flagellar filament consists of approximately 20,000 flagellins and can be several micrometers long. In this article, we reviewed the experimental works and models of flagellar filament construction and the recent findings of flagellar filament ejection during the cell cycle. The length-dependent decay of flagellar filament growth data supports the injection-diffusion model. The decay of flagellar growth rate is due to reduced transportation of long-distance diffusion and jamming. However, the filament is not a permeant structure. Several bacterial species actively abandon their flagella under starvation. Flagellum is disassembled when the rod is broken, resulting in an ejection of the filament with a partial rod and hook. The inner membrane component is then diffused on the membrane before further breakdown. These new findings open a new field of bacterial macro-molecule assembly, disassembly, and signal transduction. Keywords: self-assembly; injection-diffusion model; flagellar ejection 1. Introduction Since Antonie van Leeuwenhoek observed animalcules by using his single-lens microscope in the 18th century, we have entered a new era of microbiology. -

Ehrlichiosis and Anaplasmosis Are Tick-Borne Diseases Caused by Obligate Anaplasmosis: Intracellular Bacteria in the Genera Ehrlichia and Anaplasma
Ehrlichiosis and Importance Ehrlichiosis and anaplasmosis are tick-borne diseases caused by obligate Anaplasmosis: intracellular bacteria in the genera Ehrlichia and Anaplasma. These organisms are widespread in nature; the reservoir hosts include numerous wild animals, as well as Zoonotic Species some domesticated species. For many years, Ehrlichia and Anaplasma species have been known to cause illness in pets and livestock. The consequences of exposure vary Canine Monocytic Ehrlichiosis, from asymptomatic infections to severe, potentially fatal illness. Some organisms Canine Hemorrhagic Fever, have also been recognized as human pathogens since the 1980s and 1990s. Tropical Canine Pancytopenia, Etiology Tracker Dog Disease, Ehrlichiosis and anaplasmosis are caused by members of the genera Ehrlichia Canine Tick Typhus, and Anaplasma, respectively. Both genera contain small, pleomorphic, Gram negative, Nairobi Bleeding Disorder, obligate intracellular organisms, and belong to the family Anaplasmataceae, order Canine Granulocytic Ehrlichiosis, Rickettsiales. They are classified as α-proteobacteria. A number of Ehrlichia and Canine Granulocytic Anaplasmosis, Anaplasma species affect animals. A limited number of these organisms have also Equine Granulocytic Ehrlichiosis, been identified in people. Equine Granulocytic Anaplasmosis, Recent changes in taxonomy can make the nomenclature of the Anaplasmataceae Tick-borne Fever, and their diseases somewhat confusing. At one time, ehrlichiosis was a group of Pasture Fever, diseases caused by organisms that mostly replicated in membrane-bound cytoplasmic Human Monocytic Ehrlichiosis, vacuoles of leukocytes, and belonged to the genus Ehrlichia, tribe Ehrlichieae and Human Granulocytic Anaplasmosis, family Rickettsiaceae. The names of the diseases were often based on the host Human Granulocytic Ehrlichiosis, species, together with type of leukocyte most often infected. -

Sanguineus Bacterial Communities Rhipicephalus
Composition and Seasonal Variation of Rhipicephalus turanicus and Rhipicephalus sanguineus Bacterial Communities Itai Lalzar, Shimon Harrus, Kosta Y. Mumcuoglu and Yuval Gottlieb Appl. Environ. Microbiol. 2012, 78(12):4110. DOI: 10.1128/AEM.00323-12. Published Ahead of Print 30 March 2012. Downloaded from Updated information and services can be found at: http://aem.asm.org/content/78/12/4110 These include: SUPPLEMENTAL MATERIAL Supplemental material http://aem.asm.org/ REFERENCES This article cites 44 articles, 17 of which can be accessed free at: http://aem.asm.org/content/78/12/4110#ref-list-1 CONTENT ALERTS Receive: RSS Feeds, eTOCs, free email alerts (when new articles cite this article), more» on June 10, 2013 by guest Information about commercial reprint orders: http://journals.asm.org/site/misc/reprints.xhtml To subscribe to to another ASM Journal go to: http://journals.asm.org/site/subscriptions/ Composition and Seasonal Variation of Rhipicephalus turanicus and Rhipicephalus sanguineus Bacterial Communities Itai Lalzar,a Shimon Harrus,a Kosta Y. Mumcuoglu,b and Yuval Gottlieba Koret School of Veterinary Medicine, The Robert H. Smith Faculty of Agriculture, Food and Environment, The Hebrew University of Jerusalem, Rehovot, Israel,a and Department of Microbiology and Molecular Genetics, The Kuvin Center for the Study of Infectious and Tropical Diseases, Hadassah Medical School, The Institute for Medical Research Israel-Canada, The Hebrew University of Jerusalem, Jerusalem, Israelb A 16S rRNA gene approach, including 454 pyrosequencing and quantitative PCR (qPCR), was used to describe the bacterial com- munity in Rhipicephalus turanicus and to evaluate the dynamics of key bacterial tenants of adult ticks during the active questing season.