A Goal-Oriented User Interface for Personalized Semantic Search
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Behringer PODCAST & RECORDING
PODCAST & RECORDING QUICK-START GUIDE Welcome to the Behringer PODCAST & RECORDING quick-start guide Thank you for choosing one of our podcast-capable recording products. This top-notch hardware bundle lets you creatively produce professional-sounding podcasts, voice-over sessions, narration, and music projects for online distribution. If you’re a vlogger, you’ll have a superb pack of equipment to dramatically enhance the audio quality of your videos compared to the built-in camera microphone, giving your broadcasts a more professional appeal. Move up to the next step in the evolution of broadcasting and free yourself from the limitations of conventional communication. Podcasting Basics Before you get started, it is important to understand some of the terminology and uses surrounding the emerging field of podcasting. Podcasting is a term derived from the combination of the words “iPod” and “broadcasting,” and is defined as the distribution of audio or video files, such as radio programs or music clips, over the Internet. This is accomplished by using one of two syndication techniques that allow users to access media on such portable media devices as smart phones, tablets, MP3 players, and laptop computers. RSS (Really Simple Syndication) and Atom are Web content syndication formats written in XML that provide either podcast content or summaries that link to content and additional file information. Podcast is a feed of audio or video files placed on the Internet for public access. Anyone can subscribe to the feed and download the media files. This allows you to collect programs from a wide range of sources for listening or viewing media content, either online or offline with your computer or an appropriate portable device. -

Digital Fountain Erasure-Recovery in Bittorrent
UNIVERSITÀ DEGLI STUDI DI BERGAMO Facoltà di Ingegneria Corso di Laurea Specialistica in Ingegneria Informatica Classe n. 35/S – Sistemi Informatici Digital Fountain Erasure Recovery in BitTorrent: integration and security issues Relatore: Chiar.mo Prof. Stefano Paraboschi Correlatore: Chiar.mo Prof. Andrea Lorenzo Vitali Tesi di Laurea Specialistica Michele BOLOGNA Matricola n. 56108 ANNO ACCADEMICO 2007 / 2008 This thesis has been written, typeset and prepared using LATEX 2". Printed on December 5, 2008. Alla mia famiglia “Would you tell me, please, which way I ought to go from here?” “That depends a good deal on where you want to get to,” said the Cat. “I don’t much care where —” said Alice. “Then it doesn’t matter which way you go,” said the Cat. “— so long as I get somewhere,” Alice added as an explanation. “Oh, you’re sure to do that,” said the Cat, “if you only walk enough.” Lewis Carroll Alice in Wonderland Acknowledgments (in Italian) Ci sono molte persone che mi hanno aiutato durante lo svolgimento di questo lavoro. Il primo ringraziamento va ai proff. Stefano Paraboschi e Andrea Vitali per la disponibilità, la competenza, i consigli, la pazienza e l’aiuto tecnico che mi hanno saputo dare. Grazie di avermi dato la maggior parte delle idee che sono poi confluite nella mia tesi. Un sentito ringraziamento anche a Andrea Rota e Ruben Villa per l’aiuto e i chiarimenti che mi hanno gentilmente fornito. Vorrei ringraziare STMicroelectronics, ed in particolare il gruppo Advanced System Technology, per avermi offerto le infrastrutture, gli spa- zi e tutto il necessario per svolgere al meglio il mio periodo di tirocinio. -

Rand Middle East Research Rand Center for Middle East Public Policy
CENTER FOR MIDDLE EAST PUBLIC POLICY International Programs at RAND RAND MIDDLE EAST RESEARCH RAND CENTER FOR MIDDLE EAST PUBLIC POLICY WWW.RAND.ORG/CMEPP The RAND Center for Middle East Public Policy brings together analytic excellence and regional expertise from across the RAND Corporation to address the most critical political, social, and economic challenges facing the Middle East today. We focus not only on near-term challenges but also on critical long-term trends and solutions. Our goal is to inform policy in order to help improve the security and well-being of people living in the region. Our work in the region helps decisionmakers better understand how to tackle their domestic challenges and build capacity in ways that will make their societies safer, smarter, and more prosperous. WWW.RAND.ORG/CMEPP As part of a nonprofit and nonpartisan organization, RAND’s Middle East experts are committed to high-quality, objective research and analysis. They hold advanced degrees in an array of disciplines and specialize in a uniquely broad range of capabilities, including long-range planning and forecasting, risk assessment, and program evaluation. Many of our Middle East experts have advanced regional language skills and were born or have lived in the region. RAND’s Middle East work is funded by governments, by private foundations, and through the generous philanthropic support of individual donors and the RAND Center for Middle East Public Policy Advisory Board. Many of our publications are available in Arabic at www.rand.org/ar WWW.RAND.ORG/CMEPP PEACE AND PROSPERITY ACROSS THE MIDDLE EAST Reimagining U.S. -

The Top 10 Open Source Music Players Scores of Music Players Are Available in the Open Source World, and Each One Has Something That Is Unique
For U & Me Overview The Top 10 Open Source Music Players Scores of music players are available in the open source world, and each one has something that is unique. Here are the top 10 music players for you to check out. verybody likes to use a music player that is hassle- Amarok free and easy to operate, besides having plenty of Amarok is a part of the KDE project and is the default music Efeatures to enhance the music experience. The open player in Kubuntu. Mark Kretschmann started this project. source community has developed many music players. This The Amarok experience can be enhanced with custom scripts article lists the features of the ten best open source music or by using scripts contributed by other developers. players, which will help you to select the player most Its first release was on June 23, 2003. Amarok has been suited to your musical tastes. The article also helps those developed in C++ using Qt (the toolkit for cross-platform who wish to explore the features and capabilities of open application development). Its tagline, ‘Rediscover your source music players. Music’, is indeed true, considering its long list of features. 98 | FEBRUARY 2014 | OPEN SOURCE FOR YoU | www.LinuxForU.com Overview For U & Me Table 1: Features at a glance iPod sync Track info Smart/ Name/ Fade/ gapless and USB Radio and Remotely Last.fm Playback and lyrics dynamic Feature playback device podcasts controlled integration resume lookup playlist support Amarok Crossfade Both Yes Both Yes Both Yes Yes (Xine), Gapless (Gstreamer) aTunes Fade only -

Discontinued Browsers List
Discontinued Browsers List Look back into history at the fallen windows of yesteryear. Welcome to the dead pool. We include both officially discontinued, as well as those that have not updated. If you are interested in browsers that still work, try our big browser list. All links open in new windows. 1. Abaco (discontinued) http://lab-fgb.com/abaco 2. Acoo (last updated 2009) http://www.acoobrowser.com 3. Amaya (discontinued 2013) https://www.w3.org/Amaya 4. AOL Explorer (discontinued 2006) https://www.aol.com 5. AMosaic (discontinued in 2006) No website 6. Arachne (last updated 2013) http://www.glennmcc.org 7. Arena (discontinued in 1998) https://www.w3.org/Arena 8. Ariadna (discontinued in 1998) http://www.ariadna.ru 9. Arora (discontinued in 2011) https://github.com/Arora/arora 10. AWeb (last updated 2001) http://www.amitrix.com/aweb.html 11. Baidu (discontinued 2019) https://liulanqi.baidu.com 12. Beamrise (last updated 2014) http://www.sien.com 13. Beonex Communicator (discontinued in 2004) https://www.beonex.com 14. BlackHawk (last updated 2015) http://www.netgate.sk/blackhawk 15. Bolt (discontinued 2011) No website 16. Browse3d (last updated 2005) http://www.browse3d.com 17. Browzar (last updated 2013) http://www.browzar.com 18. Camino (discontinued in 2013) http://caminobrowser.org 19. Classilla (last updated 2014) https://www.floodgap.com/software/classilla 20. CometBird (discontinued 2015) http://www.cometbird.com 21. Conkeror (last updated 2016) http://conkeror.org 22. Crazy Browser (last updated 2013) No website 23. Deepnet Explorer (discontinued in 2006) http://www.deepnetexplorer.com 24. Enigma (last updated 2012) No website 25. -

Special Characters A
453 Index ■ ~/Library/Safari/WebpageIcons.db file, Special Characters 112 $(pwd) command, 89–90 ~/Library/Saved Searches directory, 105 $PWD variable, 90 ~/Library/Services directory, 422–423 % (Execute As AppleScript) menu option, ~/Library/Workflow/Applications/Folder 379 Actions folder, 424 ~/ directory, 6, 231 ~/Library/Workflows/Applications/Image ~/bin directory, 6, 64, 291 Capture folder, 426 ~/Documents directory, 281, 290 ~/Movies directory, 323, 348 ~/Documents/Knox directory, 255 ~/Music directory, 108, 323 ~/Downloads option, 221, 225 ~/Music/Automatically Add To iTunes ~/Downloads/Convert For iPhone folder, folder, 424 423–424 ~/Pictures directory, 281 ~/Downloads/MacUpdate ~/.s3conf directory, 291 Desktop/MacUpdate Desktop ~/ted directory, 231 2010-02-20 directory, 16 ~/Templates directory, 60 ~/Downloads/To Read folder, 425 ~/Templates folder, 62 ~/Dropbox directory, 278–282 Torrent program, 236 ~/Library folder, 28 1Password, 31, 135, 239–250 ~/Library/Application 1Password extension button, 247–248 Support/Evom/ffmpeg directory, 1Password.agilekeychain file, 249 338 1PasswordAnywhere tool, 249 ~/Library/Application 1Password.html file, 250 Support/Fluid/SSB/[Your 2D Black option, 52 SSB]/Userstyles/ directory, 190 2D With Transparency Effect option, 52 ~/Library/Application Support/TypeIt4Me/ 2-dimensional, Dock, 52 directory, 376 7digital Music Store extension, 332 ~/Library/Caches/com.apple.Safari/Webp age Previews directory, 115 ~/Library/Internet Plug-Ins directory, 137 ■A ~/Library/LaunchAgents directory, 429, 432 -

Comprehensive Annual Financial Report Fiscal Year Ended June 30, 2015
LOS ANGELES UNIFIED SCHOOL DISTRICT LOS ANGELES, CALIFORNIA COMPREHENSIVE ANNUAL FINANCIAL REPORT FISCAL YEAR ENDED JUNE 30, 2015 MR. RAMON C. CORTINES SUPERINTENDENT OF SCHOOLS (EFFECTIVE OCTOBER 20, 2014) MR. JOHN E. DEASY SUPERINTENDENT OF SCHOOLS (APRIL 18, 2011 – OCTOBER 15, 2014) MS. MEGAN K. REILLY CHIEF FINANCIAL OFFICER MR. V. LUIS BUENDIA CONTROLLER PREPARED BY ACCOUNTING AND DISBURSEMENTS DIVISION 333 S. BEAUDRY AVENUE LOS ANGELES, CALIFORNIA 90017 LOS ANGELES UNIFIED SCHOOL DISTRICT Comprehensive Annual Financial Report Year Ended June 30, 2015 Table of Contents I N T R O D U C T O R Y S E C T I O N Page Letter of Transmittal ………………………………………………………………………………………………….……… i Certificate of Achievement for Excellence in Financial Reporting ………………………………………………………… vi Board of Education and Principal School District Officials ………………………………………………………………… vii Organizational Structure …………………………………………………………………………………………………… viii F I N A N C I A L S E C T I O N Independent Auditor's Report ……………………………………………………………………………………………… 1 Management’s Discussion and Analysis …………………………………………………………………………………… 4 B a s i c F i n a n c i a l S t a t e m e n t s: G o v e r n m e n t - w i d e F i n a n c i al S t a t e m e n t s: Statement of Net Position ……………………………………………………………………………………………… 14 Statement of Activities ………………………………………………………………………………………………… 15 F u n d F i n a n c i a l S t a t e m e n t s: Balance Sheet – Governmental Funds ………………………………………………………………………………… 16 Reconciliation of the Governmental Funds Balance Sheet to the Statement of Net Position -
Towards a Regenerative Melbourne
REGEN MELBOURNE Towards a regenerative Melbourne Embracing Doughnut Economics to create a new compass for Melbourne ACKNOWLEDGEMENTS We acknowledge and pay our respects to the Our work has been enabled and greatly enhanced This report includes quotes from a diverse group of Traditional Custodians of what we now call by a talented and deeply thoughtful group of prominent leaders in Melbourne who generously Melbourne, the Bunurong Boon Wurrung and facilitators and graphic scribes. We thank this team gave their time for interviews to discuss their love Wurundjeri Woi Wurrung peoples of the Eastern for their dedication and the depth that they have for our city, their experience of the COVID-19 Kulin Nation. We pay our respects to elders past, brought to this project and the formation of the disruption, the lessons that emerged for them and present and emerging. We recognise that we need Regen Melbourne network: Rachel Bucknall, their vision for our city. These individuals include: to build conversations like these, about the future Devon Bunce, Nicki Colls, Anna Crabb, Abbie of our city, on the wisdom of First Nations people, Freestone, Kiran Kashyap, Phoebe Roberts, Fiona Armstrong and with an understanding and appreciation of the Katherine Sundermann, Matt Sykes and with a CEO, CLIMATE AND HEALTH ALLIANCE ongoing impacts of colonialism and dispossession. very special mention to our Doughnut Champion Cheryl Batagol PSM Sovereignty was never ceded. This always was and Alison Whitten. CHAIR, CRC FOR WATER SENSITIVE CITIES always will be Aboriginal land. Dr Catherine Brown OAM This project has not been an attempt to create a CEO, LORD MAYOR’S CHARITABLE We acknowledge and support the Victorian Treaty “representative” snapshot of Melbourne. -

Miro— Open and Decentralized Internet TV
INTERNET TV Miro— open and decentralized Internet TV Dean Jansen Participatory Culture Foundation Miro is a free, open-source platform for Internet TV. Ideal for high-definition video, it features an open content guide with over 5,000 channels that can be freely subscribed to. The application boasts nearly 500,000 users and has been downloaded more than three million times in the last year. Miro has been compared to Tivo, Firefox and iTunes; it functions as both a video library and a very intuitive system for subscribing to and watching internet video channels. Additionally, Miro can search and save videos from video-sharing sites, such as YouTube and Daily Motion. For public broadcasters, Miro (http://getmiro.com) offers a distribution platform that is perfect for moving high-quality, long-form video to a large, non-technical audience. The user-friendly integra- tion of BitTorrent in Miro lets publishers leverage the scalability and low cost of P2P distribution without confusing non-technical users. Public broadcasters can create custom versions of Miro that feature their own content and their own brand. Furthermore, Miro is open source and cross-plat- form, leaving broadcasters and their audience independent of any proprietary software (Adobe Flash, Apple iTunes) or operating system (Miro can run on Mac, Windows and Linux). Miro’s user base and content guide are both expanding rapidly. The application itself is on a tight development curve, releasing major updates and improvements five to seven times per year. Miro is being developed by the Participatory Culture Foundation (PCF), a US.based 501c3 non-profit organ- ization. -

Introducing HTML5 Second Edition
HTMLINTRODUCING SECOND 5EDITION BRUCE LAWSON REMY SHARP Introducing HTML5, Second Edition Bruce Lawson and Remy Sharp New Riders 1249 Eighth Street Berkeley, CA 94710 510/524-2178 510/524-2221 (fax) Find us on the Web at: www.newriders.com To report errors, please send a note to [email protected] New Riders is an imprint of Peachpit, a division of Pearson Education Copyright © 2012 by Remy Sharp and Bruce Lawson Project Editor: Michael J. Nolan Development Editor: Margaret S. Anderson/Stellarvisions Technical Editors: Patrick H. Lauke (www.splintered.co.uk), Robert Nyman (www.robertnyman.com) Production Editor: Cory Borman Copyeditor: Gretchen Dykstra Proofreader: Jan Seymour Indexer: Joy Dean Lee Compositor: Danielle Foster Cover Designer: Aren Howell Straiger Cover photo: Patrick H. Lauke (splintered.co.uk) Notice of Rights All rights reserved. No part of this book may be reproduced or transmitted in any form by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. For informa- tion on getting permission for reprints and excerpts, contact permissions@ peachpit.com. Notice of Liability The information in this book is distributed on an “As Is” basis without war- ranty. While every precaution has been taken in the preparation of the book, neither the authors nor Peachpit shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the instructions contained in this book or by the com- puter software and hardware products described in it. Trademarks Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. -

Comodo System Cleaner Software Version 3.0
Comodo System Cleaner Software Version 3.0 User Guide Guide Version 3.0.011811 Comodo Security Solutions 1255 Broad Street STE 100 Clifton, NJ 07013 Comodo System Cleaner - User Guide Table of Contents 1.Comodo System- Cleaner - Introduction ................................................................................................................................. 3 1.1.System Requirements......................................................................................................................................................... 5 1.2.Installing Comodo System-Cleaner..................................................................................................................................... 5 1.3.Starting Comodo System-Cleaner....................................................................................................................................... 9 1.4.The Main Interface............................................................................................................................................................ 10 1.5.The Summary Area........................................................................................................................................................... 11 1.6.Understanding Profiles...................................................................................................................................................... 12 2.Registry Cleaner...................................................................................................................................................................... -
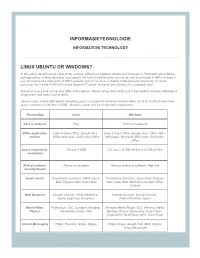
Informasietegnologie Linux Ubuntu Or Windows?
POST LIST INFORMASIETEGNOLOGIE INFORMATION TECHNOLOGY LINUX UBUNTU OR WINDOWS? In this article we will look at a few of the common differences between Ubuntu and windows 8. Firstly with any software package before making decisions most people will look at what it would cost me as user to purchase it. With windows 8 you are looking at a retail price of R800 upwards, but of course as a student of Stellenbosch University, it can be purchased for a mere R180-00 from the Student IT Centre. However with Ubuntu, it’s completely free! Now let’s have a look at how they differ at first glance, Ubuntu brings their Unity look to the platform whereas Windows 8 brings there new metro look to theirs. Ubuntu is also a fairly light weight operating system compared to Windows 8 which takes up 16 to 20 GB of hard drive space compared to Ubuntu’s 4.5GB. Below is a table of a list of relevant comparisons. Feature/App Linux Windows Cost to end-user Free R800 and upwards Office application Libre & Open Office, Google docs, Libre & Open Office, Google docs, Office 365 + choices Office Web Apps, Soft maker Office Web Apps, Microsoft Office suite, Soft maker Office Space required for OS size 4.5GB OS size is 16 GB (32-bit) or 20 GB (64-bit) installation Risk of software Almost non existent Various malicious software, High risk security threats Email clients Thunderbird, Evolution, KMail, Opera Thunderbird, Evolution, Opera Mail, Pegasus Mail, Pegasus Mail, Claws Mail Mail, Claws Mail, Windows Live Mail, Office Outlook Web Browsers Google Chrome, Firefox/Waterfox,