Self-Aware Effective Identification and Response to Viral Cyber Threats
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Task-Based Taxonomy of Cognitive Biases for Information Visualization
A Task-based Taxonomy of Cognitive Biases for Information Visualization Evanthia Dimara, Steven Franconeri, Catherine Plaisant, Anastasia Bezerianos, and Pierre Dragicevic Three kinds of limitations The Computer The Display 2 Three kinds of limitations The Computer The Display The Human 3 Three kinds of limitations: humans • Human vision ️ has limitations • Human reasoning 易 has limitations The Human 4 ️Perceptual bias Magnitude estimation 5 ️Perceptual bias Magnitude estimation Color perception 6 易 Cognitive bias Behaviors when humans consistently behave irrationally Pohl’s criteria distilled: • Are predictable and consistent • People are unaware they’re doing them • Are not misunderstandings 7 Ambiguity effect, Anchoring or focalism, Anthropocentric thinking, Anthropomorphism or personification, Attentional bias, Attribute substitution, Automation bias, Availability heuristic, Availability cascade, Backfire effect, Bandwagon effect, Base rate fallacy or Base rate neglect, Belief bias, Ben Franklin effect, Berkson's paradox, Bias blind spot, Choice-supportive bias, Clustering illusion, Compassion fade, Confirmation bias, Congruence bias, Conjunction fallacy, Conservatism (belief revision), Continued influence effect, Contrast effect, Courtesy bias, Curse of knowledge, Declinism, Decoy effect, Default effect, Denomination effect, Disposition effect, Distinction bias, Dread aversion, Dunning–Kruger effect, Duration neglect, Empathy gap, End-of-history illusion, Endowment effect, Exaggerated expectation, Experimenter's or expectation bias, -

Red Letters, White Paper, Black Ink: Race, Writing, Colors, and Characters in 1850S America
Red Letters, White Paper, Black Ink: Race, Writing, Colors, and Characters in 1850s America Samuel Arrowsmith Turner Portland, Maine B.A., Vassar College, 1997 A Dissertation presented to the Graduate Faculty of the University of Virginia in Candidacy for the Degree of Doctor of Philosophy Department of English University of Virginia August, 2013 ii Abstract It’s well known that both the idea of race and the idea of writing acquired new kinds of importance for Americans in the mid-nineteenth century. Less obvious has been the extent to which the relationship between the two ideas, each charged by antebellum America with an ever-broader range of ideological functions, has itself served for some authors both as an object of inquiry and as a politico-aesthetic vocabulary. “White Paper, Black Ink, Red Letters” concerns this race-writing dialectic, and takes as its point of departure the fact that both writing and race depend on a priori notions of visibility and materiality to which each nonetheless is – or seems to be – irreducible. That is, though any given utterance of racial embodiment or alphabetic inscription becomes intelligible by its materialization as part of a field of necessarily visible signifiers (whether shapes of letters or racially encoded features of the body) the power of any such signifier to organize or regulate experience depends on its perceived connection to a separate domain of invisible meanings. iii For many nineteenth-century Americans race offered an increasingly persuasive narrative of identity at a time when the self-evidence of class, gender, and nationality as modes of affiliation seemed to be waning. -

The Art of Thinking Clearly
For Sabine The Art of Thinking Clearly Rolf Dobelli www.sceptrebooks.co.uk First published in Great Britain in 2013 by Sceptre An imprint of Hodder & Stoughton An Hachette UK company 1 Copyright © Rolf Dobelli 2013 The right of Rolf Dobelli to be identified as the Author of the Work has been asserted by him in accordance with the Copyright, Designs and Patents Act 1988. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means without the prior written permission of the publisher, nor be otherwise circulated in any form of binding or cover other than that in which it is published and without a similar condition being imposed on the subsequent purchaser. A CIP catalogue record for this title is available from the British Library. eBook ISBN 978 1 444 75955 6 Hardback ISBN 978 1 444 75954 9 Hodder & Stoughton Ltd 338 Euston Road London NW1 3BH www.sceptrebooks.co.uk CONTENTS Introduction 1 WHY YOU SHOULD VISIT CEMETERIES: Survivorship Bias 2 DOES HARVARD MAKE YOU SMARTER?: Swimmer’s Body Illusion 3 WHY YOU SEE SHAPES IN THE CLOUDS: Clustering Illusion 4 IF 50 MILLION PEOPLE SAY SOMETHING FOOLISH, IT IS STILL FOOLISH: Social Proof 5 WHY YOU SHOULD FORGET THE PAST: Sunk Cost Fallacy 6 DON’T ACCEPT FREE DRINKS: Reciprocity 7 BEWARE THE ‘SPECIAL CASE’: Confirmation Bias (Part 1) 8 MURDER YOUR DARLINGS: Confirmation Bias (Part 2) 9 DON’T BOW TO AUTHORITY: Authority Bias 10 LEAVE YOUR SUPERMODEL FRIENDS AT HOME: Contrast Effect 11 WHY WE PREFER A WRONG MAP TO NO -

Pete Aldridge Well, Good Afternoon, Ladies and Gentlemen, and Welcome to the Fifth and Final Public Hearing of the President’S Commission on Moon, Mars, and Beyond
The President’s Commission on Implementation of United States Space Exploration Policy PUBLIC HEARING Asia Society 725 Park Avenue New York, NY Monday, May 3, and Tuesday, May 4, 2004 Pete Aldridge Well, good afternoon, ladies and gentlemen, and welcome to the fifth and final public hearing of the President’s Commission on Moon, Mars, and Beyond. I think I can speak for everyone here when I say that the time period since this Commission was appointed and asked to produce a report has elapsed at the speed of light. At least it seems that way. Since February, we’ve heard testimonies from a broad range of space experts, the Mars rovers have won an expanded audience of space enthusiasts, and a renewed interest in space science has surfaced, calling for a new generation of space educators. In less than a month, we will present our findings to the White House. The Commission is here to explore ways to achieve the President’s vision of going back to the Moon and on to Mars and beyond. We have listened and talked to experts at four previous hearings—in Washington, D.C.; Dayton, Ohio; Atlanta, Georgia; and San Francisco, California—and talked among ourselves and we realize that this vision produces a focus not just for NASA but a focus that can revitalize US space capability and have a significant impact on our nation’s industrial base, and academia, and the quality of life for all Americans. As you can see from our agenda, we’re talking with those experts from many, many disciplines, including those outside the traditional aerospace arena. -
Infographic I.10
The Digital Health Revolution: Leaving No One Behind The global AI in healthcare market is growing fast, with an expected increase from $4.9 billion in 2020 to $45.2 billion by 2026. There are new solutions introduced every day that address all areas: from clinical care and diagnosis, to remote patient monitoring to EHR support, and beyond. But, AI is still relatively new to the industry, and it can be difficult to determine which solutions can actually make a difference in care delivery and business operations. 59 Jan 2021 % of Americans believe returning Jan-June 2019 to pre-coronavirus life poses a risk to health and well being. 11 41 % % ...expect it will take at least 6 The pandemic has greatly increased the 65 months before things get number of US adults reporting depression % back to normal (updated April and/or anxiety.5 2021).4 Up to of consumers now interested in telehealth going forward. $250B 76 57% of providers view telehealth more of current US healthcare spend % favorably than they did before COVID-19.7 could potentially be virtualized.6 The dramatic increase in of Medicare primary care visits the conducted through 90% $3.5T telehealth has shown longevity, with rates in annual U.S. health expenditures are for people with chronic and mental health conditions. since April 2020 0.1 43.5 leveling off % % Most of these can be prevented by simple around 30%.8 lifestyle changes and regular health screenings9 Feb. 2020 Apr. 2020 OCCAM’S RAZOR • CONJUNCTION FALLACY • DELMORE EFFECT • LAW OF TRIVIALITY • COGNITIVE FLUENCY • BELIEF BIAS • INFORMATION BIAS Digital health ecosystems are transforming• AMBIGUITY BIAS • STATUS medicineQUO BIAS • SOCIAL COMPARISONfrom BIASa rea• DECOYctive EFFECT • REACTANCEdiscipline, • REVERSE PSYCHOLOGY • SYSTEM JUSTIFICATION • BACKFIRE EFFECT • ENDOWMENT EFFECT • PROCESSING DIFFICULTY EFFECT • PSEUDOCERTAINTY EFFECT • DISPOSITION becoming precise, preventive,EFFECT • ZERO-RISK personalized, BIAS • UNIT BIAS • IKEA EFFECT and • LOSS AVERSION participatory. -

S:\FULLCO~1\HEARIN~1\Committee Print 2018\Henry\Jan. 9 Report
Embargoed for Media Publication / Coverage until 6:00AM EST Wednesday, January 10. 1 115TH CONGRESS " ! S. PRT. 2d Session COMMITTEE PRINT 115–21 PUTIN’S ASYMMETRIC ASSAULT ON DEMOCRACY IN RUSSIA AND EUROPE: IMPLICATIONS FOR U.S. NATIONAL SECURITY A MINORITY STAFF REPORT PREPARED FOR THE USE OF THE COMMITTEE ON FOREIGN RELATIONS UNITED STATES SENATE ONE HUNDRED FIFTEENTH CONGRESS SECOND SESSION JANUARY 10, 2018 Printed for the use of the Committee on Foreign Relations Available via World Wide Web: http://www.gpoaccess.gov/congress/index.html U.S. GOVERNMENT PUBLISHING OFFICE 28–110 PDF WASHINGTON : 2018 For sale by the Superintendent of Documents, U.S. Government Publishing Office Internet: bookstore.gpo.gov Phone: toll free (866) 512–1800; DC area (202) 512–1800 Fax: (202) 512–2104 Mail: Stop IDCC, Washington, DC 20402–0001 VerDate Mar 15 2010 04:06 Jan 09, 2018 Jkt 000000 PO 00000 Frm 00001 Fmt 5012 Sfmt 5012 S:\FULL COMMITTEE\HEARING FILES\COMMITTEE PRINT 2018\HENRY\JAN. 9 REPORT FOREI-42327 with DISTILLER seneagle Embargoed for Media Publication / Coverage until 6:00AM EST Wednesday, January 10. COMMITTEE ON FOREIGN RELATIONS BOB CORKER, Tennessee, Chairman JAMES E. RISCH, Idaho BENJAMIN L. CARDIN, Maryland MARCO RUBIO, Florida ROBERT MENENDEZ, New Jersey RON JOHNSON, Wisconsin JEANNE SHAHEEN, New Hampshire JEFF FLAKE, Arizona CHRISTOPHER A. COONS, Delaware CORY GARDNER, Colorado TOM UDALL, New Mexico TODD YOUNG, Indiana CHRISTOPHER MURPHY, Connecticut JOHN BARRASSO, Wyoming TIM KAINE, Virginia JOHNNY ISAKSON, Georgia EDWARD J. MARKEY, Massachusetts ROB PORTMAN, Ohio JEFF MERKLEY, Oregon RAND PAUL, Kentucky CORY A. BOOKER, New Jersey TODD WOMACK, Staff Director JESSICA LEWIS, Democratic Staff Director JOHN DUTTON, Chief Clerk (II) VerDate Mar 15 2010 04:06 Jan 09, 2018 Jkt 000000 PO 00000 Frm 00002 Fmt 5904 Sfmt 5904 S:\FULL COMMITTEE\HEARING FILES\COMMITTEE PRINT 2018\HENRY\JAN. -

A Framework for Studying Biases in Visualization Research
A Framework for Studying Biases in Visualization Research André Calero Valdez, Martina Ziefle, Michael Sedlmair Real Cognitive Scientists! André Calero Valdez Martina Ziefle Thanks André! Michael Sedlmair A Framework for Studying Biases in Visualization Research. IEEE VIS Decisive Workshop: Phoenix, AZ, USA. Oct 2nd, 2017. 3 Background story • InfoVis 2017 paper: - Priming and Anchoring Effects in Visualization [Wed, 8:30, Perception session] • Geoff told us about DECISIVe • We have to write a paper!! Geoff @EuroVA, Barcelona, 2017 Michael Sedlmair A Framework for Studying Biases in Visualization Research. IEEE VIS Decisive Workshop: Phoenix, AZ, USA. Oct 2nd, 2017. 4 Next step: brainstorming … • There are so many biases out there! • Map by Buster Benson. Michael Sedlmair A Framework for Studying Biases in Visualization Research. IEEE VIS Decisive Workshop: Phoenix, AZ, USA. Oct 2nd, 2017. 5 Next step brainstorming … IV. What Should We I. Too Much Information II. Not Enough Meaning III. Need to act fast remember? a. We notice things 1. Availability Heuristic a. We find stories and 1. Confabulation a. To act, we must be 1. Peltzman effect a. We edit and 1. Spacing effect 2. Attentional Bias 2. Clustering illusion 2. Risk compensation 2. Suggestibility • already primed in 3. Illusory truth effect patterns even in confident we can 3. Effort justification reinforce some 3. False memory 3. Insensitivity to sample size There are so many 4. Mere exposure effect 4. Trait ascription bias 4. Cryptomnesia memory or repeated sparse data 4. Neglect of probability make an impact and memories after the often 5. Centext effect 5. Anecdotal fallacy feel what we do is 5. -

Read Book Hamilton Literary Magazine, Volume 16 Kindle
HAMILTON LITERARY MAGAZINE, VOLUME 16 Author: N y ) Hamilton College (Clinton Number of Pages: none Published Date: 20 May 2016 Publisher: Palala Press Publication Country: United States Language: English ISBN: 9781358036354 DOWNLOAD: HAMILTON LITERARY MAGAZINE, VOLUME 16 Hamilton Literary Magazine, Volume 16 PDF Book The authorship is international, which brings together researchers experienced in conducting educational inquiry in rural places from across European, Australian, American, and Canadian contexts, allowing readers insight into national and regional challenges. Ardeshir DistributedPastingofSmallVotes. Engineering Applications of Neural Networks: 12th International Conference, EANN 2011 and 7th IFIP WG 12. Questions have been raised about what we mean by evidence, about how particular kinds of evidence may be privileged over other kinds of evidence, about the transferability of research findings to practice, and about the consequences of a move to evidence-based practice for governance in education. Contains a wealth of previously unpublished information, including firsthand accounts from those who take part in hacktivist operations. Forgotten Books uses state-of-the-art technology to digitally reconstruct the work, preserving the original format whilst repairing imperfections present in the aged copy. Each term covered in this advanced dictionary includes six elements: Description - how the term is defined Key insights - important insights provided by an understanding of the term Keywords - words to further understand the -
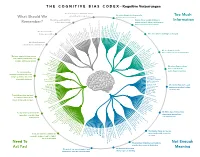
Too Much Information Not Enough Meaning Need to Act Fast What
T H E C O G N I T I V E B I A S C O D E X – Kognitive Verzerrungen We store memories differently based We notice things already primed in on how they were experienced Too Much What Should We memory or repeated often We reduce events and lists Tip of the tongue phenomenon Bizarre, funny, visually striking, or Information Remember? to their key elements Levels–of–processing effect anthropomorphic things stick out more than non-bizarre/unfunny things Absent–mindedness Next–in–line effect Part–set cueingSerial–position effect effect Google effect Testing effect Memory inhibition We discard specifics Recency effect Suffix effect Leveling and sharpening Primacy effect DurationModality neglect effect MisinformationList–length effect effect to form generalities Serial recall effect We notice when something has changed Availability heuristic Attentional bias Illusory truth effect Mere–exposure effect Context effect Cue–dependent forgetting Mood–congruent memory bias Frequency illusion Baader–Meinhof Phenomenon Peak–end rule Empathy gap Fading affect bias Omission bias Base rate fallacy Bizarreness effect Negativity bias Humor effect Von Restorff effect We edit and reinforce ImplicitStereotypical stereotypes bias Picture superiority effect Self–relevance effect Negativity bias some memories after the fact Implicit associationPrejudice Anchoring Conservatism Contrast effect Spacing effect Distinction bias Focusing effect Suggestibility Framing effect We are drawn to details False memory Money illusion Misattribution of memory Weber–Fechner law SourceCryptomnesia -

Cognitive Biases in Fitness to Practise Decision-Making
ADVICE ON BIASES IN FITNESS TO PRACTISE DECISION-MAKING IN ACCEPTED OUTCOME VERSUS PANEL MODELS FOR THE PROFESSIONAL STANDARDS AUTHORITY Prepared by: LESLIE CUTHBERT Date: 31 March 2021 Contents I. Introduction ................................................................................................. 2 Background .................................................................................................. 2 Purpose of the advice.................................................................................... 3 Summary of conclusions ................................................................................ 4 Documents considered .................................................................................. 4 Technical terms and explanations ................................................................... 5 Disclaimer .................................................................................................... 5 II. How biases might affect the quality of decision-making in the AO model, as compared to the panel model .............................................................................. 6 Understanding cognitive biases in fitness to practise decision-making ............... 6 Individual Decision Maker (e.g. a Case Examiner) in AO model ......................... 8 Multiple Case Examiners .............................................................................. 17 Group Decision Maker in a Panel model of 3 or more members ....................... 22 III. Assessment of the impact of these biases, -

Taxonomies of Cognitive Bias How They Built
Three kinds of limitations Three kinds of limitations Three kinds of limitations: humans A Task-based Taxonomy of Cognitive Biases for Information • Human vision ️ has Visualization limitations Evanthia Dimara, Steven Franconeri, Catherine Plaisant, Anastasia • 易 Bezerianos, and Pierre Dragicevic Human reasoning has limitations The Computer The Display The Computer The Display The Human The Human 2 3 4 Ambiguity effect, Anchoring or focalism, Anthropocentric thinking, Anthropomorphism or personification, Attentional bias, Attribute substitution, Automation bias, Availability heuristic, Availability cascade, Backfire effect, Bandwagon effect, Base rate fallacy or Base rate neglect, Belief bias, Ben Franklin effect, Berkson's ️Perceptual bias ️Perceptual bias 易 Cognitive bias paradox, Bias blind spot, Choice-supportive bias, Clustering illusion, Compassion fade, Confirmation bias, Congruence bias, Conjunction fallacy, Conservatism (belief revision), Continued influence effect, Contrast effect, Courtesy bias, Curse of knowledge, Declinism, Decoy effect, Default effect, Denomination effect, Magnitude estimation Magnitude estimation Color perception Behaviors when humans Disposition effect, Distinction bias, Dread aversion, Dunning–Kruger effect, Duration neglect, Empathy gap, End-of-history illusion, Endowment effect, Exaggerated expectation, Experimenter's or expectation bias, consistently behave irrationally Focusing effect, Forer effect or Barnum effect, Form function attribution bias, Framing effect, Frequency illusion or Baader–Meinhof -

Social Bias Cheat Sheet.Pages
COGNITIVE & SOCIAL BIAS CHEAT SHEET Four problems that biases help us address: Problem 1: Too much information. There is just too much information in the world, we have no choice but to filter almost all of it out. Our brain uses a few simple tricks to pick out the bits of information that are most likely going to be useful in some way. We notice flaws in others more easily than flaws in ourselves. Yes, before you see this entire article as a list of quirks that compromise how other people think, realize that you are also subject to these biases. See: Bias blind spot, Naïve cynicism, Naïve realism CONSEQUENCE: We don’t see everything. Problem 2: Not enough meaning. The world is very confusing, and we end up only seeing a tiny sliver of it, but we need to make some sense of it in order to survive. Once the reduced stream of information comes in, we connect the dots, fill in the gaps with stuff we already think we know, and update our mental models of the world. We fill in characteristics from stereotypes, generalities, and prior histories whenever there are new specific instances or gaps in information. When we have partial information about a specific thing that belongs to a group of things we are pretty familiar with, our brain has no problem filling in the gaps with best guesses or what other trusted sources provide. Conveniently, we then forget which parts were real and which were filled in. See: Group attribution error, Ultimate attribution error, Stereotyping, Essentialism, Functional fixedness, Moral credential effect, Just-world hypothesis, Argument from fallacy, Authority bias, Automation bias, Bandwagon effect, Placebo effect We imagine things and people we’re familiar with or fond of as better than things and people we aren’t familiar with or fond of.