Gestural Interaction Design for Information Exchange Between Large Public Displays and Personal Mobile Devices
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Material Data & Design Workstation Reviews Biomimicry
January 2019 FOCUS ON: New Vehicle Lightweighting Design Meshless Simulation Simulate Additive Manufacturing DigitalEngineering247.com A Touch of AR MATERIAL DATA & DESIGN WORKSTATION REVIEWS BIOMIMICRY DE_0119_Cover.indd 2 12/13/18 4:41 PM ANSYS.indd 1 12/10/18 3:56 PM @XI_Computer.indd 1 12/10/18 3:54 PM //////////////////////////////////////////////////////////////// | DEGREES OF FREEDOM | by Jamie J. Gooch Hack Your New Year’s Resolution T’S THAT TIME of year when we reflect on the past to go back to school to get another degree, maybe resolve to and look ahead to the future. On one hand, this makes take a course in programming, finite element analysis or design sense: The calendar year ends and a new year begins. for additive manufacturing. Small successes can lead to setting What better time to make resolutions? On the other loftier goals, but the trick is to build on each success to get there, Ihand, it seems a bit arbitrary to make important life and rather than trying to achieve too much too soon. work goals based on a date chosen by the pope in 1582 to Another way to engineer yourself to keep your resolutions be the first day of the year. is to share your goals. Research shows that telling people about your goals can help you stick with them. Committing Research has shown that New Year’s Resolutions don’t to something like professional training, where you tell your work for most people, but just barely. According to a 2002 supervisor your intentions, or improving your standard op- study by John C. -

Thinkpad T550.Indd
ThinkPad T550 Platform Specifi cations Product Specifi cations Reference (PSREF) Processor 5th Generation Intel® Core™ i5 / i7 Processor Smart card readerOptional: Smart card reader Processor # of # of Base Max Turbo Memory Processor Multicard reader 4-in-1 reader (MMC, SD, SDHC, SDXC) Cache Number Cores Threads Frequency Frequency Speed Graphics Ports Three USB 3.0 (one Always On), VGA, MiniDP, Ethernet (RJ-45), Dock connector Camera (optional) HD720p resolution, low light sensitive, fi xed focus i5-5200U 2.2 GHz 2.7 GHz 3MB Intel HD ® i5-5300U24 2.3 GHz 2.9 GHz 3MB DDR3L-1600 Graphics Audio support HD Audio, Realtek ALC3232 codec / stereo speakers, 1W x 2 / dual array microphone, combo audio/microphone jack i7-5600U 2.6 GHz 3.2 GHz 4MB 5500 Keyboard 6-row, spill-resistant, multimedia Fn keys, numeric keypad, optional LED backlight Graphics Intel HD Graphics 5500 in processor only, or UltraNav™ TrackPoint® pointing device and buttonless Mylar surface touchpad, multi-touch Intel HD Graphics 5500 in processor and NVIDIA GeForce® 940M, 1GB memory; supports external analog monitor via VGA and digital monitor via Mini DisplayPort; Security Power-on password, hard disk password, supervisor password, security keyhole supports three independent displays; Security chip Trusted Platform Module, TCG 1.2-compliant Max resolution: 3840x2160@60Hz (DP via mDP cable); 2560x1600@60Hz (VGA) ThinkEngine Delivers improved thermal and power effi ciency, up to 30 day standby, faster resume time, enhanced security, as well as anti-tampering measures Chipset Intel -

The Trackball, a Related Pointing Device, Was Invented in 1941 By
The trackball, a related pointing device, was invented in 1941 by Ralph Benjamin as part of a World War II-era fire-control radar plotting system called Comprehensive Display System (CDS). Benjamin was then working for the British Royal NavyScientific Service. Benjamin's project used analog computers to calculate the future position of target aircraft based on several initial input points provided by a user with a joystick. Benjamin felt that a more elegant input device was needed and invented a ball tracker called "roller ball", for this purpose.[5][6] The device was patented in 1947,[6] but only a prototype using a metal ball rolling on two rubber- coated wheels was ever built, and the device was kept as a military secret.[5] Another early trackball was built by British electrical engineer Kenyon Taylor in collaboration with Tom Cranston and Fred Longstaff. Taylor was part of the original Ferranti Canada, working on the Royal Canadian Navy's DATAR (Digital Automated Tracking and Resolving) system in 1952.[7] DATAR was similar in concept to Benjamin's display. The trackball used four disks to pick up motion, two each for the X and Y directions. Several rollers provided mechanical support. When the ball was rolled, the pickup discs spun and contacts on their outer rim made periodic contact with wires, producing pulses of output with each movement of the ball. By counting the pulses, the physical movement of the ball could be determined. A digital computer calculated the tracks, and sent the resulting data to other ships in a task force using pulse-code modulation radio signals. -

Survey of Eye-Free Text Entry Techniques of Touch Screen
Covenant Journal of Informatics and Communication Technology (CJICT) Vol. 1, No. 2, December, 2013. Survey of Eye-Free Text Entry Techniques of Touch Screen Mobile Devices Designed for Visually Impaired Users Sonali Banubakode1, Chitra Dhawale 2 [email protected] 2MCA Department, P.R. Pote College, Amravati, India [email protected] Abstract: Now a days touch screen mobiles are becoming more popular amongst sighted as well visually impaired people due to its simple interface and efficient interaction techniques. Most of the touch screen devices designed for visually impaired users based on screen readers, haptic and different user interface (UI). In this paper we present a critical review of different keypad layouts designed for visually impaired users and their effect on text entry speed. And try to list out key issues to extend accessibility and text entry rate of touch screen devices. Keywords: Text entry rate, touch screen mobile devices, visually impaired users. I. Introduction increasingly common in both sighted Visual impairment describes any and visually impaired people. These kind of vision loss, whether it‟s devices used not only for about total blindness or partial vision entertainment and communication loss. Some people are totally blind purpose but for learning, browsing, but many others have legal e-billing and many more. But they blindness. They don‟t have enough are highly visual demanding. Touch vision to see the object stands 20 feet screen is highly sensitive; it contains away from them (Arditi & lots of tiny icons and requires more Rosenthal, 1998). According to concentration as well as fast action. recent statistics of WHO (Chatterjee, It is not easy for any person with 1198) 285 million people are vision problem to handle such visually impaired. -

HPC Options for Simulation P.42 Multiphysics Optimizes Battery Design P.28
June 2014 / deskeng.com HPC Options for Simulation P.42 Multiphysics Optimizes Battery Design P.28 TECHNOLOGY FOR DESIGN ENGINEERING FEA for Thermal Analysis P.32 FOCUS ON: CAD Prototyping toCAM Reinforce simulated machining with real-world CAM experience. P. 20 REVIEW: DELL M3800 MOBILE WORKSTATION P. 46 REVIEW: V-RAY 3.0 FOR 3DS MAX P. 38 DESIGN COLLABORATION AT WHIRLPOOL P. 52 de0614_Cover_Darlene.indd 1 5/14/14 1:09 PM RedANSYS.indd Bull Ad-Desktop 1 Engineering.indd 1 4/28/20145/8/14 1:15:10 1:37 PM PM Bluebeam.indd 1 5/8/14 1:41 PM Degrees of Freedom by Jamie J. Gooch Seeing is Understanding very day, many of us do the same basic types of tasks. through traditional or more unconventional means, the free- As we often highlight in Desktop Engineering, there dom to prototype and create is a key tool of design thinkers. are amazing advantages to using technology to com- In fact, the Kelleys call it the “best way to make progress plete those tasks faster and better. However, there toward your goal.” Eis a danger in focusing on improving the efficiency of the That freedom is not something every organization sup- routine: It’s easy to get into a rut. ports, even if it’s inadvertent, which tends to permeate a com- Innovation comes from designing a new and different way pany’s culture to the point of diminishing design confidence for people to interact with the products you’re modeling and and therefore efficacy. In a live video chat from the d.school simulating. -
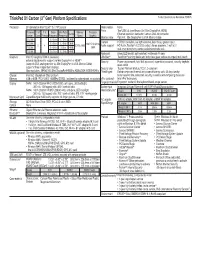
Thinkpad X1 Carbon 3Rd.Indd
ThinkPad X1 Carbon (3rd Gen) Platform Specifi cations Product Specifi cations Reference (PSREF) Processor 5th Generation Intel® Core™ i5 / i7 Processor Media reader None Processor # of # of Base Max Turbo Memory Processor Ports Two USB 3.0 (one Always On), Mini DisplayPort, HDMI, Cache Number Cores Threads Frequency Frequency Speed Graphics Ethernet extension connector, Lenovo OneLink connector Monitor cable Optional: Mini DisplayPort to VGA Monitor Cable i5-5200U 2.2 GHz 2.7 GHz 3MB Camera HD720p resolution, low light sensitive, fi xed focus, gesture input i5-5300U 2.3 GHz 2.9 GHz 3MB Intel HD Graphics ® 24 DDR3L-1600 Audio support HD Audio, Realtek ALC3232 codec / stereo speakers, 1 watt x 2 / 5500 i7-5500U 2.4 GHz 3 GHz 4MB dual array microphone, combo audio/microphone jack i7-5600U 2.6 GHz 3.2 GHz 4MB Keyboard 6-row, LED backlit, spill-resistant, multimedia Fn keys Graphics Intel HD Graphics 5500 in processor, UltraNav™ TrackPoint® pointing device and buttonless glass surface touchpad, multi-touch ™ external digital monitor support via Mini DisplayPort or HDMI Security Power-on password, hard disk password, supervisor password, security keyhole, (supports VGA analog monitor via Mini DisplayPort to VGA Monitor Cable); reset switch supports three independent displays; Security chip Trusted Platform Module, TCG 1.2-compliant Max resolution: 3840x2160 (Mini DisplayPort)@60Hz; 4096x2304 (HDMI)@24Hz ThinkEngine Delivers improved thermal and power effi ciency, up to 30 day standby, Chipset Intel SoC (System on Chip) platform faster resume time, -

Dell Precision 3540 & 3541 P.30 Paramatters Cognicad P.36 Autodesk Fusion P.42
September 2019 FOCUS ON: Democratization Software Bundles P.14 P.10 Path to Simulation P.19 Budget Workstations P.28 DigitalEngineering247.com REVIEWS: DELL PRECISION 3540 & 3541 P.30 PARAMATTERS COGNICAD P.36 AUTODESK FUSION P.42 DE_0919_Cover_Digital_Edition.indd 1 8/16/19 4:45 PM PERVASIVE ENGINEERING MEANS Twin-Twin Propositions With ANSYS Twin Builder, you can build, validate and deploy a digital twin for unparalleled insight into your asset’s performance — and cut maintenance costs by up to 20 percent. Learn more: ansys.com/twin-builder ANSYS.indd 1 8/12/19 4:46 PM Digital Engineering and NAFEMS Americas are teaming up to present CAASE19, a one-day Virtual Conference on Advancing Analysis & Simulation in Engineering 19 Virtual Conference October 8, 2019 TRACK 1: Simulation-Driven Design TRACK 2: Simulation Governance & Democratization TRACK 3: Manufacturing Processes & Additive Manufacturing TRACK 4: Addressing Business Strategies & Challenges Go to: digitalengineering247.com/joincaase19 to view the presentations from Ford Motor Co., Embraer, Procter & Gamble and others, and register for this great day of learning. Sign Up Today! CAASE19_Virtual_Conference_0919.indd 1 8/12/19 4:53 PM //////////////////////////////////////////////////////////////// | DEGREES OF FREEDOM | By Brian Albright A More Open, Accessible Future F YOU HAD TOLD ME A YEAR AGO that I’d soon be overseeing my first issue of Digital Engineering at its editorial director, I would have quickly dismissed the notion. Jamie Gooch has been the “face” of DE for as long as I’ve been a contributor. I was surprised when the post suddenly became available, and also thrilled at the opportunity to dive into the I work that this magazine has been doing so well for so long. -

Proyecto Fin De Carrera
UNIVERSIDAD AUTÓNOMA DE MADRID ESCUELA POLITÉCNICA SUPERIOR PROYECTO FIN DE CARRERA Design and creation of a drag-and-drop editor that allows the customization of a sales application in NFC payment terminals José María Angulo Pinedo Abril 2014 INGENIERÍA DE TELECOMUNICACIÓN i Design and creation of a drag-and-drop editor that allows the customization of a sales application in NFC payment terminals Autor: José María Angulo Pinedo Tutor: Heinz Bircher-Nagy Ponente: Germán Montoro Manrique Software Development Avance Pay AG Abril de 2014 ii iii Resumen El objetivo de este proyecto es el diseño y creación de un editor drag & drop que permita la personalización de aplicaciones utilizadas en terminales móviles, como TPV (Terminales Punto de Venta). El editor será desarrollado tanto para entornos Android como para clientes web, y tiene como objetivo facilitar la personalización de sus aplicaciones de venta a los pequeños comerciantes que utilicen el sistema de pago de Avance Pay. En esta memoria primero se ofrece una visión general de los sistemas de pago móviles mediante la tecnología NFC y las ventajas de utilizar un terminal móvil como TPV. Luego se realiza un estudio del funcionamiento de los sistemas drag & drop, así como de los programas WYSIWYG. A su vez se hace una comparación de los distintos editores existentes para Android. Antes de crear el editor drag & drop se aborda el diseño de la aplicación TPV para entornos Android. Para ello se analizan las características de aplicaciones TPV ya existentes en el mercado, con el propósito de reunir los requerimientos oportunos. Además, se desarrolla un prototipo acorde al diseño propuesto. -

Gestures for Pointing Devices in Screen-Based Environments
Gestures for pointing devices in screen-based environments Florian Weil, www.derhess.de December 4, 2010 Abstract This paper analyses gesture design for pointing devices in screen-based envi- ronments. By exploring design patterns the analysis investigated the gesture design of ve dierent end-user products: Desktop operating systems, mobile operating systems, 3rd Party software, small software products, and common hardware products. The beginning of the paper denes what a gesture is, and the various kinds of gestures. Afterwards the analysis merges the gesture design results with the basic commands for pointing devices. This approach points out which gestures are often used, and in which context they are used. The re- sults give interaction designers and software engineers a guide for implementing gestures in their own products. Furthermore, the paper proposes solutions for gesture documentation, and a conceptual framework for complicated gestures. The last section takes an industrial design perspective on pointing devices as an input channel. It discusses the evolution of interface design from a hardware driven to a software driven approach. Contents 1 Introduction 1 2 Gestures for pointing devices 3 2.1 Denition of gesture in Human-Computer-Interaction . 3 2.2 Types of gestures . 4 2.3 Commands for gestures . 6 3 Analysis of gesture based Interaction for end-user products 9 3.1 Concept and analysis model . 9 3.2 Results from a Interaction Design view . 12 3.2.1 Level 1 gestures . 12 3.2.2 Level 2 gestures . 13 3.2.3 Level 3 gestures . 15 3.2.4 Level 4 and level 5 gestures . -

Thinkpad T450s Platform Specifications
ThinkPad T450s Platform Specifi cations Product Specifi cations Reference (PSREF) Processor 5th Generation Intel® Core™ i5 / i7 Processor Smart card readerOptional: Smart card reader Processor # of # of Base Max Turbo Memory Processor Media reader 4-in-1 reader (MMC, SD, SDHC, SDXC) Cache Number Cores Threads Frequency Frequency Speed Graphics Ports Three USB 3.0 (one Always On), VGA, Mini DisplayPort, Ethernet (RJ-45), Dock connector (integrated models only) i5-5200U 2.2 GHz 2.7 GHz 3MB Intel HD Camera HD720p resolution, low light sensitive, fi xed focus i5-5300U24 2.3 GHz 2.9 GHz 3MB DDR3L-1600 Graphics ® 5500 Audio support HD Audio, Realtek ALC3232 codec / stereo speakers, 2W x 2 / i7-5600U 2.6 GHz 3.2 GHz 4MB dual array microphone, combo audio/microphone jack Graphics Intel HD Graphics 5500 in processor only, or Keyboard 6-row, spill-resistant, multimedia Fn keys, optional LED backlight Intel HD Graphics 5500 in processor and NVIDIA GeForce® 940M, 1GB memory UltraNav™ TrackPoint® pointing device and buttonless glass surface touchpad, multi-touch (discrete models are only available in Western Europe); supports external analog monitor via VGA and digital monitor via Mini DisplayPort; Security Power-on password, hard disk password, supervisor password, security keyhole supports three independent displays; Security chip Trusted Platform Module, TCG 1.2-compliant Max resolution: 3840x2160@60Hz (DP via mDP cable); 1920x1200@60Hz (VGA) ThinkEngine Delivers improved thermal and power effi ciency, up to 30 day standby, faster resume time, enhanced -

Resourceful Guide By: Latif Salim ©KVSS SUB-ICT 2018
1 Resourceful guide by: latif salim ©KVSS SUB-ICT 2018 RESOURCEFUL GUIDE TO SUBSIDIARY-ICT 850/1 COMPUTER STUDIES DEPARTMENT Kiira View Secondary School By: latif salim muwalo (Bsc.IT) Tel: +256782-977944, +256752-977944 Email: [email protected] [email protected] ©2018 Page 1 of 92 2 Resourceful guide by: latif salim ©KVSS SUB-ICT 2018 SET ONE: 1. (a). Write the acronym ICT in full. (01 mark) Information, Communications Technology (b). Mention two ways ICT can be used to improve teaching and learning. (02 marks) Computer-based training, which includes: Computer-Assisted Instructions (CAI), so that teachers can use computers and other IT equipment to present teaching materials in a more interesting way. Computer-Assisted Learning (CAL), so that students can use computers and appropriate software to learn at their own pace. Computer-Assisted Assessment (CAA), which may reduce the time and labor to mark the answer scripts. Distance learning through computer-based training and Web-based training. Simulations of experiments or real-life situations that may be hazardous. Electronic library system for searching, borrowing, and returning books. The School Administration and Management System (SAMS) for keeping records of students and producing report cards or other related documents. Edutainment, which is a type of educational software that combines education with entertainment. (c). Give two ways ICT has affected work today. (02 marks) It has led to unemployment among workers. It has led to job displacement. It has improved work space environment and efficiency. It has led to working from home away from standard offices (telecommuting). It has increases presence of workflows 24/7. -

NET PROGRAMMING Author: Dr
ALAGAPPA UNIVERSITY [Accredited with ‘A+’ Grade by NAAC (CGPA:3.64) in the Third Cycle and Graded as Category–I University by MHRD-UGC] (A State University Established by the Government of Tamil Nadu) KARAIKUDI – 630 003 Directorate of Distance Education B.Sc. [Information Technology] VI - Semester 129 64 LAB: .NET PROGRAMMING Author: Dr. Preety Khatri, Assistant Professor-SOIT IMS, Noida "The copyright shall be vested with Alagappa University" All rights reserved. No part of this publication which is material protected by this copyright notice may be reproduced or transmitted or utilized or stored in any form or by any means now known or hereinafter invented, electronic, digital or mechanical, including photocopying, scanning, recording or by any information storage or retrieval system, without prior written permission from the Alagappa University, Karaikudi, Tamil Nadu. Information contained in this book has been published by VIKAS® Publishing House Pvt. Ltd. and has been obtained by its Authors from sources believed to be reliable and are correct to the best of their knowledge. However, the Alagappa University, Publisher and its Authors shall in no event be liable for any errors, omissions or damages arising out of use of this information and specifically disclaim any implied warranties or merchantability or fitness for any particular use. Vikas® is the registered trademark of Vikas® Publishing House Pvt. Ltd. VIKAS® PUBLISHING HOUSE PVT. LTD. E-28, Sector-8, Noida - 201301 (UP) Phone: 0120-4078900 x Fax: 0120-4078999 Regd. Office: A-27, 2nd Floor, Mohan Co-operative Industrial Estate, New Delhi 1100 44 x Website: www.vikaspublishing.com x Email: [email protected] Work Order No.