A Recommendation for a Complete Open Source Policy
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Solar and Space Physics: a Science for a Technological Society
Solar and Space Physics: A Science for a Technological Society The 2013-2022 Decadal Survey in Solar and Space Physics Space Studies Board ∙ Division on Engineering & Physical Sciences ∙ August 2012 From the interior of the Sun, to the upper atmosphere and near-space environment of Earth, and outwards to a region far beyond Pluto where the Sun’s influence wanes, advances during the past decade in space physics and solar physics have yielded spectacular insights into the phenomena that affect our home in space. This report, the final product of a study requested by NASA and the National Science Foundation, presents a prioritized program of basic and applied research for 2013-2022 that will advance scientific understanding of the Sun, Sun- Earth connections and the origins of “space weather,” and the Sun’s interactions with other bodies in the solar system. The report includes recommendations directed for action by the study sponsors and by other federal agencies—especially NOAA, which is responsible for the day-to-day (“operational”) forecast of space weather. Recent Progress: Significant Advances significant progress in understanding the origin from the Past Decade and evolution of the solar wind; striking advances The disciplines of solar and space physics have made in understanding of both explosive solar flares remarkable advances over the last decade—many and the coronal mass ejections that drive space of which have come from the implementation weather; new imaging methods that permit direct of the program recommended in 2003 Solar observations of the space weather-driven changes and Space Physics Decadal Survey. For example, in the particles and magnetic fields surrounding enabled by advances in scientific understanding Earth; new understanding of the ways that space as well as fruitful interagency partnerships, the storms are fueled by oxygen originating from capabilities of models that predict space weather Earth’s own atmosphere; and the surprising impacts on Earth have made rapid gains over discovery that conditions in near-Earth space the past decade. -

Solar Chromospheric Flares
Solar Chromospheric Flares A proposal for an ISSI International Team Lyndsay Fletcher (Glasgow) and Jana Kasparova (Ondrejov) Summary Solar flares are the most energetic energy release events in the solar system. The majority of energy radiated from a flare is produced in the solar chromosphere, the dynamic interface between the Sun’s photosphere and corona. Despite solar flare radiation having been known for decades to be principally chromospheric in origin, the attention of the community has re- cently been strongly focused on the corona. Progress in understanding chromospheric flare physics and the diagnostic potential of chromospheric observations has stagnated accord- ingly. But simultaneously, motivated by the available chromospheric observations, the ‘stan- dard flare model’, of energy transport by an electron beam from the corona, is coming under scrutiny. With this team we propose to return to the chromosphere for basic understanding. The present confluence of high quality chromospheric flare observations and sophisticated numerical simulation techniques, as well as the prospect of a new generation of missions and telescopes focused on the chromosphere, makes it an excellent time for this endeavour. The international team of experts in the theory and observation of solar chromospheric flares will focus on the question of energy deposition in solar flares. How can multi-wavelength, high spatial, spectral and temporal resolution observations of the flare chromosphere from space- and ground-based observatories be interpreted in the context of detailed modeling of flare radiative transfer and hydrodynamics? With these tools we can pin down the depth in the chromosphere at which flare energy is deposited, its time evolution and the response of the chromosphere to this dramatic event. -

Manual Ls40tha H-Alpha Solar-Telescope
Manual LS40THa H-alpha Solar-Telescope Telescope for solar observation in the H-Alpha wavelength. The H-alpha wavelength is the most impressive way to observe the sun, here prominences at the solar edge become visible, filaments and flares on the surface, and much more. Included Contents: - LS40THa telescope - H-alpha unit with tilt-tuning - Blocking-filter B500, B600, or B1200 - 1.25 inch Helical focuser - Dovetail bar (GP level) for installing at astronomical mounts - 1/4-20 tapped base (standard thread for photo-tripods) inside the dovetail for installing at photo-tripods - Sol-searcher Please note: Please keep the foam insert from the delivery box. The optionally available transport-case for the LS40THa (item number 0554010) is not supplied without such a foam insert, the original foam insert from the delivery box fits exactly into this transport-case. Congratulations and thank you for purchasing the LS40THa telescope from Lunt Solar Systems! The easy handling makes this telescope ideal for starting H-Alpha solar observation. Due to its compact dimensions it is also a good travel telescope for the experienced solar observers. Safety Information: There are inherent dangers when looking at the Sun thru any instrument. Lunt Solar Systems has taken your safety very seriously in the design of our systems. With safety being the highest priority we ask that you read and understand the operation of your telescope or filter system prior to use. Never attempt to disassemble the telescope! Do not use your system if it is in someway compromised due to mishandling or damage. Please contact our customer service with any questions or concerns regarding the safe use of your instrument. -

Formation and Evolution of Coronal Rain Observed by SDO/AIA on February 22, 2012?
A&A 577, A136 (2015) Astronomy DOI: 10.1051/0004-6361/201424101 & c ESO 2015 Astrophysics Formation and evolution of coronal rain observed by SDO/AIA on February 22, 2012? Z. Vashalomidze1;2, V. Kukhianidze2, T. V. Zaqarashvili1;2, R. Oliver3, B. Shergelashvili1;2, G. Ramishvili2, S. Poedts4, and P. De Causmaecker5 1 Space Research Institute, Austrian Academy of Sciences, Schmiedlstrasse 6, 8042 Graz, Austria e-mail: [teimuraz.zaqarashvili]@oeaw.ac.at 2 Abastumani Astrophysical Observatory at Ilia State University, Cholokashvili Ave.3/5, Tbilisi, Georgia 3 Departament de Física, Universitat de les Illes Balears, 07122, Palma de Mallorca, Spain 4 Dept. of Mathematics, Centre for Mathematical Plasma Astrophysics, Celestijnenlaan 200B, 3001 Leuven, Belgium 5 Dept. of Computer Science, CODeS & iMinds-iTEC, KU Leuven, KULAK, E. Sabbelaan 53, 8500 Kortrijk, Belgium Received 30 April 2014 / Accepted 25 March 2015 ABSTRACT Context. The formation and dynamics of coronal rain are currently not fully understood. Coronal rain is the fall of cool and dense blobs formed by thermal instability in the solar corona towards the solar surface with acceleration smaller than gravitational free fall. Aims. We aim to study the observational evidence of the formation of coronal rain and to trace the detailed dynamics of individual blobs. Methods. We used time series of the 171 Å and 304 Å spectral lines obtained by the Atmospheric Imaging Assembly (AIA) on board the Solar Dynamic Observatory (SDO) above active region AR 11420 on February 22, 2012. Results. Observations show that a coronal loop disappeared in the 171 Å channel and appeared in the 304 Å line more than one hour later, which indicates a rapid cooling of the coronal loop from 1 MK to 0.05 MK. -
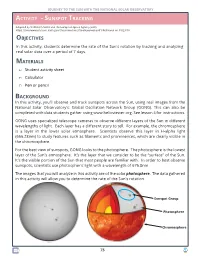
Activity - Sunspot Tracking
JOURNEY TO THE SUN WITH THE NATIONAL SOLAR OBSERVATORY Activity - SunSpot trAcking Adapted by NSO from NASA and the European Space Agency (ESA). https://sohowww.nascom.nasa.gov/classroom/docs/Spotexerweb.pdf / Retrieved on 01/23/18. Objectives In this activity, students determine the rate of the Sun’s rotation by tracking and analyzing real solar data over a period of 7 days. Materials □ Student activity sheet □ Calculator □ Pen or pencil bacKgrOund In this activity, you’ll observe and track sunspots across the Sun, using real images from the National Solar Observatory’s: Global Oscillation Network Group (GONG). This can also be completed with data students gather using www.helioviewer.org. See lesson 4 for instructions. GONG uses specialized telescope cameras to observe diferent layers of the Sun in diferent wavelengths of light. Each layer has a diferent story to tell. For example, the chromosphere is a layer in the lower solar atmosphere. Scientists observe this layer in H-alpha light (656.28nm) to study features such as flaments and prominences, which are clearly visible in the chromosphere. For the best view of sunspots, GONG looks to the photosphere. The photosphere is the lowest layer of the Sun’s atmosphere. It’s the layer that we consider to be the “surface” of the Sun. It’s the visible portion of the Sun that most people are familiar with. In order to best observe sunspots, scientists use photospheric light with a wavelength of 676.8nm. The images that you will analyze in this activity are of the solar photosphere. The data gathered in this activity will allow you to determine the rate of the Sun’s rotation. -

Multi-Spacecraft Analysis of the Solar Coronal Plasma
Multi-spacecraft analysis of the solar coronal plasma Von der Fakultät für Elektrotechnik, Informationstechnik, Physik der Technischen Universität Carolo-Wilhelmina zu Braunschweig zur Erlangung des Grades einer Doktorin der Naturwissenschaften (Dr. rer. nat.) genehmigte Dissertation von Iulia Ana Maria Chifu aus Bukarest, Rumänien eingereicht am: 11.02.2015 Disputation am: 07.05.2015 1. Referent: Prof. Dr. Sami K. Solanki 2. Referent: Prof. Dr. Karl-Heinz Glassmeier Druckjahr: 2016 Bibliografische Information der Deutschen Nationalbibliothek Die Deutsche Nationalbibliothek verzeichnet diese Publikation in der Deutschen Nationalbibliografie; detaillierte bibliografische Daten sind im Internet über http://dnb.d-nb.de abrufbar. Dissertation an der Technischen Universität Braunschweig, Fakultät für Elektrotechnik, Informationstechnik, Physik ISBN uni-edition GmbH 2016 http://www.uni-edition.de © Iulia Ana Maria Chifu This work is distributed under a Creative Commons Attribution 3.0 License Printed in Germany Vorveröffentlichung der Dissertation Teilergebnisse aus dieser Arbeit wurden mit Genehmigung der Fakultät für Elektrotech- nik, Informationstechnik, Physik, vertreten durch den Mentor der Arbeit, in folgenden Beiträgen vorab veröffentlicht: Publikationen • Mierla, M., Chifu, I., Inhester, B., Rodriguez, L., Zhukov, A., 2011, Low polarised emission from the core of coronal mass ejections, Astronomy and Astrophysics, 530, L1 • Chifu, I., Inhester, B., Mierla, M., Chifu, V., Wiegelmann, T., 2012, First 4D Recon- struction of an Eruptive Prominence -

The Solar Optical Telescope
NASATM109240 The Solar Optical Telescope (NAS.A- TM- 109240) TELESCOPE (NASA) NASA The Solar Optical Telescope is shown in the Sun-pointed configuration, mounted on an Instrument Pointing System which is attached to a Spacelab Pallet riding in the Shuttle Orbiter's Cargo Bay. The Solar Optical Telescope - will study the physics of the Sun on the scale at which many of the important physical processes occur - will attain a resolution of 73km on the Sun or 0.1 arc seconds of angular resolution 1 SOT-I GENERAL CONFIGURATION ARTICULATED VIEWPOINT DOOR PRIMARY MIRROR op IPS SENSORS WAVEFRONT SENSOR - / i— VENT LIGHT TUNNEL-7' ,—FINAL I 7 I FOCUS IPS INTERFACE E-BOX SHELF GREGORIAN POD---' U (1 of 4) HEAT REJECTION MIRROR-S 1285'i Why is the Solar Optical Telescope Needed? There may be no single object in nature that mankind For exrmple, the hedii nq and expns on of the solar wind U 2 is more dependent upon than the Sun, unless it is the bathes the Earth in solar plasma is ultimately attributable to small- Earth itself. Without the Sun's radiant energy, there scale processes that occur close to the solar surface. Only by would be no life on Earth as we know it. Even our prim- observing the underlying processes on the small scale afforded ary source of energy today, fossil fuels, is available be- by the Solar Optical Telescope can we hope to gain a profound cause of solar energy millions of years ago; and when understanding of how the Sun transfers its radiant and particle mankind succeeds in taming the nuclear reaction that energy through the different atmospheric regions and ultimately converts hydrogen into helium for our future energy to our Earth. -

Can You Spot the Sunspots?
Spot the Sunspots Can you spot the sunspots? Description Use binoculars or a telescope to identify and track sunspots. You’ll need a bright sunny day. Age Level: 10 and up Materials • two sheets of bright • Do not use binoculars whose white paper larger, objective lenses are 50 • a book mm or wider in diameter. • tape • Binoculars are usually described • binoculars or a telescope by numbers like 7 x 35; the larger • tripod number is the diameter in mm of • pencil the objective lenses. • piece of cardboard, • Some binoculars cannot be easily roughly 30 cm x 30 cm attached to a tripod. • scissors • You might need to use rubber • thick piece of paper, roughly bands or tape to safely hold the 10 cm x 10 cm (optional) binoculars on the tripod. • rubber bands (optional) Time Safety Preparation: 5 minutes Do not look directly at the sun with your eyes, Activity: 15 minutes through binoculars, or through a telescope! Do not Cleanup: 5 minutes leave binoculars or a telescope unattended, since the optics can be damaged by too much Sun exposure. 1 If you’re using binoculars, cover one of the objective (larger) lenses with either a lens cap or thick piece of folded paper (use tape, attached to the body of the binoculars, to hold the paper in position). If using a telescope, cover the finderscope the same way. This ensures that only a single image of the Sun is created. Next, tape one piece of paper to a book to make a stiff writing surface. If using binoculars, trace both of the larger, objective lenses in the middle of the piece of cardboard. -
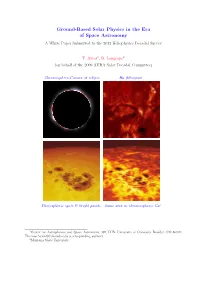
Ground-Based Solar Physics in the Era of Space Astronomy a White Paper Submitted to the 2012 Heliophysics Decadal Survey
Ground-Based Solar Physics in the Era of Space Astronomy A White Paper Submitted to the 2012 Heliophysics Decadal Survey T. Ayres1, D. Longcope2 (on behalf of the 2009 AURA Solar Decadal Committee) Chromosphere-Corona at eclipse Hα filtergram Photospheric spots & bright points Same area in chromospheric Ca+ 1Center for Astrophysics and Space Astronomy, 389 UCB, University of Colorado, Boulder, CO 80309; [email protected] (corresponding author) 2Montana State University SUMMARY. A report, previously commissioned by AURA to support advocacy efforts in advance of the Astro2010 Decadal Survey, reached a series of conclusions concerning the future of ground-based solar physics that are relevant to the counterpart Heliophysics Survey. The main findings: (1) The Advanced Technology Solar Telescope (ATST) will continue U.S. leadership in large aperture, high-resolution ground-based solar observations, and will be a unique and powerful complement to space-borne solar instruments; (2) Full-Sun measurements by existing synoptic facilities, and new initiatives such as the Coronal Solar Magnetism Observatory (COSMO) and the Frequency Agile Solar Radiotelescope (FASR), will balance the narrow field of view captured by ATST, and are essential for the study of transient phenomena; (3) Sustaining, and further developing, synoptic observations is vital as well to helioseismology, solar cycle studies, and Space Weather prediction; (4) Support of advanced instrumentation and seeing compensation techniques for the ATST, and other solar telescopes, is necessary to keep ground-based solar physics at the cutting edge; and (5) Effective planning for ground-based facilities requires consideration of the synergies achieved by coordination with space-based observatories. -

The New Heliophysics Division Template
NASA Heliophysics Division Update Heliophysics Advisory Committee October 1, 2019 Dr. Nicola J. Fox Director, Heliophysics Division Science Mission Directorate 1 The Dawn of a New Era for Heliophysics Heliophysics Division (HPD), in collaboration with its partners, is poised like never before to -- Explore uncharted territory from pockets of intense radiation near Earth, right to the Sun itself, and past the planets into interstellar space. Strategically combine research from a fleet of carefully-selected missions at key locations to better understand our entire space environment. Understand the interaction between Earth weather and space weather – protecting people and spacecraft. Coordinate with other agencies to fulfill its role for the Nation enabling advances in space weather knowledge and technologies Engage the public with research breakthroughs and citizen science Develop the next generation of heliophysicists 2 Decadal Survey 3 Alignment with Decadal Survey Recommendations NASA FY20 Presidential Budget Request R0.0 Complete the current program Extended operations of current operating missions as recommended by the 2017 Senior Review, planning for the next Senior Review Mar/Apr 2020; 3 recently launched and now in primary operations (GOLD, Parker, SET); and 2 missions currently in development (ICON, Solar Orbiter) R1.0 Implement DRIVE (Diversify, Realize, Implemented DRIVE initiative wedge in FY15; DRIVE initiative is now Integrate, Venture, Educate) part of the Heliophysics R&A baseline R2.0 Accelerate and expand Heliophysics Decadal recommendation of every 2-3 years; Explorer mission AO Explorer program released in 2016 and again in 2019. Notional mission cadence will continue to follow Decadal recommendation going forward. Increased frequency of Missions of Opportunity (MO), including rideshares on IMAP and Tech Demo MO. -

Parker Solar Probe SWG Telecon February 5, 2020 Project Science Report Nour Raouafi Project Status Helene Winters Payload Status SB,JK,DM,RH Solar Orbiter H
Parker Solar Probe SWG Telecon February 5, 2020 Project Science Report Nour Raouafi Project Status Helene Winters Payload Status SB,JK,DM,RH Solar Orbiter H. Gilbert/C. St. Cyr SOC Activities Martha Kusterer Payload SE Telecon S. Hamilton/A. Reiter Theory Group M. Velli/A. Higginson Upcoming Meetings Nour Raouafi Science Presentations: DaviD Malaspina (LASP) & Karl Battams (NRL) Agenda • DCP 5 Information • DCP Type: Data Volume • Venus Flyby • Non-routine Activities & Science Priorities o WISPR o ISOIS o FIELDS o SWEAP • Modeling – Robert Allen • Coordinated observations. Parker Solar Probe Project Science SWG Telecon February 5, 2020 ApJS Special Issue (ApJ/SI) 50+ papers submitted as of Oct. 20, 2019 Early Results from Parker Solar Probe: Ushering a New Frontier in Space Exploration • Publication Date: February 3, 2020 • 48 papers accessible online • Few more papers still under review Corresponding authors: please speed up the reviewing process – Send me your submission info and the manuscript. • Print copies: Science Teams are you interested in ordering print copies of the special issue? 2/7/20 4 Nature Papers ADS not listing all the authors • ADS lists only three authors: the first two and the last one • The issue was addressed for the FIELDS and WISPR papers • But not for the SWEAP and ISOIS papers • ADS stated that that’s the information Nature sent to them • Corrections can submitted through http://adsabs.harvard.edu/adsfeedback/submit_abstract.php. 2/7/20 5 Future Publications • Let’s us know about your results in case we need to prepare for press releases • Animations take time to design and get ready • Please do not for the mission acknowledgements Parker Solar Probe was designed, built, and is now operated by the Johns Hopkins Applied Physics Laboratory as part of NASA’s Living with a Star (LWS) program (contract NNN06AA01C). -

Cloudy with a Chance of Solar Flares: the Sun As a Natural Hazard
National Aeronautics and Space Administration Cloudy with a Chance of Solar Flares: The Sun as a Natural Hazard Jonathan Pellish, Ph.D. NASA Goddard Space Flight Center Greenbelt, MD USA February 2017 www.nasa.gov To be released on http://www.aaas.org/. 1 Background image courtesy of NASA/SDO and the AIA, EVE, and HMI science teams. Acknowledgements • Dr. Antti Pulkkinen o Heliophysics Science Division, NASA Goddard Space Flight Center • Dr. Christian T. Steigies o Institut für Experimentelle und Angewandte Physik, Christian-Albrechts- Universität zu Kiel • Supported in part by: o NASA Electronic Parts and Packaging (NEPP) Program o NASA Goddard Space Flight Center Strategic Collaboration Initiative To be released on http://www.aaas.org/. 2 Space Weather – What Is It and Why Care? • Space Weather o “conditions on the Sun and in the solar wind, magnetosphere, ionosphere, and thermosphere that can influence the performance and reliability of space-borne and ground-based technological systems and can endanger human life or health.” [US National Space Weather Program] • <Space> Climate o “The historical record and description of average daily and seasonal <space> weather events that help describe a region. Statistics are usually drawn over several decades.” [Dave Schwartz the Weatherman – Weather.com] “Space weather” refers to the dynamic These emissions can interact with Earth conditions of the space environment that and its surrounding space, including the arise from emissions from the Sun, which Earth’s magnetic field, potentially include solar flares, solar energetic disrupting […] technologies and particles, and coronal mass ejections. infrastructures. National Space Weather Strategy, Office of Science and Technology Policy, October 2015 To be released on http://www.aaas.org/.