HW2: Section 1.2
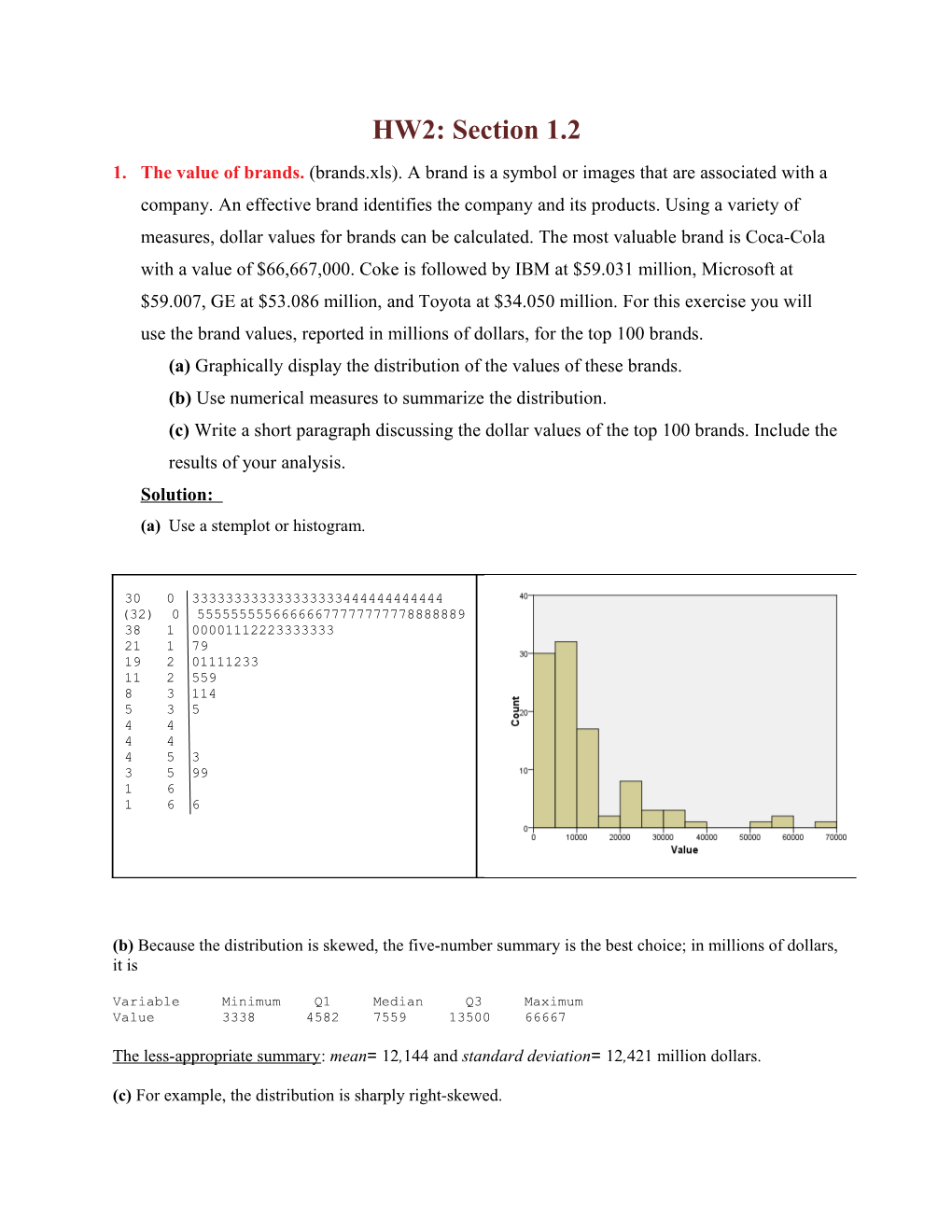
1. The value of brands. (brands.xls). A brand is a symbol or images that are associated with a company. An effective brand identifies the company and its products. Using a variety of measures, dollar values for brands can be calculated. The most valuable brand is Coca-Cola with a value of $66,667,000. Coke is followed by IBM at $59.031 million, Microsoft at $59.007, GE at $53.086 million, and Toyota at $34.050 million. For this exercise you will use the brand values, reported in millions of dollars, for the top 100 brands. (a) Graphically display the distribution of the values of these brands. (b) Use numerical measures to summarize the distribution. (c) Write a short paragraph discussing the dollar values of the top 100 brands. Include the results of your analysis. Solution: (a) Use a stemplot or histogram.
30 0 333333333333333333444444444444 (32) 0 55555555566666677777777778888889 38 1 00001112223333333 21 1 79 19 2 01111233 11 2 559 8 3 114 5 3 5 4 4 4 4 4 5 3 3 5 99 1 6 1 6 6
(b) Because the distribution is skewed, the five-number summary is the best choice; in millions of dollars, it is
Variable Minimum Q1 Median Q3 Maximum Value 3338 4582 7559 13500 66667
The less-appropriate summary: mean= 12,144 and standard deviation= 12,421 million dollars.
(c) For example, the distribution is sharply right-skewed. 2. Salaries of the New York Mets. The mean salary of the players on the 2008 New York Mets baseball team was $4,910,900 while the median salary was $2,375,000. What explains the difference between these two measures of centre? Solution: Salary distributions (especially in professional sports) tend to be skewed to the right. This skew makes the mean higher than the median.
3. Potatoes. (potatoes.xls). A quality product is one that is consistent and has very little variability in its characteristics. Controlling variability can be more difficult with agricultural products than with those that are manufactured. The following table gives the weights, in ounces, of the 25 potatoes sold in a 10-pound bag. (a) Summarize the data graphically and numerically. Give reasons for methods you chose to use in your summaries. (b) Do you think that your numerical summaries do an effective job of describing these data? Why or why not? (c) There appear to be two distinct clusters of weights for these potatoes. Divide the sample into two subsamples based on the clustering. Give the mean and standard deviation for each subsample. Do you think that this way of summarizing these data is better than a numerical summary that uses all of the data as a single sample? Give a reason for your answer. Solution: (a)
Histogram of weight 1 3 8 35 2 4 2 6 4 6777 30 8 5 22 8 5 25 12 6 0023
(1) 6 7 t
n 20
12 7 02 e c r
10 7 678899999 e
P 15 1 8 2
10
5
0 4 5 6 7 8 weight Here the distribution is left-skewed. Therefore the 5-number summary is preferable as a numerical summary and it is shown below:
Minimum Q1 Median Q3 Maximum
3.8 4.95 6.7 7.85 8.2
(b) The numerical summary does not reveal the two weight clusters (visible in a stemplot or histogram). (c) Descriptive Statistics: For small potatoes (less than 6 oz)
Variable N Mean StDev Small 8 4.638 0.469
Descriptive Statistics: For large potatoes
Variable N Mean StDev Large 17 7.294 0.767
Because there are clearly two groups, it seems appropriate to treat them separately.
4. Longleaf pine trees. The Wade Tract in Thomas County, Georgia, is an old-growth forest of longleaf pine trees (Pinus palustris) that has survived in a relatively undisturbed state since before the settlement of the area by Europeans. A study collected data about 584 of these trees. One of the variables measured was the diameter at breast height (DBH). This is the diameter of the tree at 4.5 feet and the units are centimetres (cm). Only trees with DBH greater than 1.5 cm were sampled. Here are the diameters of a random sample of 40 of these trees: (longleaf.xls) (a) Find the five-number summary for these data. (b) Make a boxplot. (c) Make a histogram. (d) Write a short summary of the major features of this distribution. Do you prefer the boxplot or the histogram for these data? Solution: (a) Five-number summary:
Variable Minimum Q1 Median Q3 Maximum Diameter 2.20 10.73 28.50 42.60 69.30 (b) Boxplot:
6. 5.
(d) (c) Solution: salary? isthe What median mean? than less Howofthe the firm? many employees earn at this paid mean isthe salary firm’s $320,000.What owner and the $80,000each, accountants junior versus median. Mean the higher median. thethan strongskew to mean be rich. become pulls This have few ormodest but a little wealth, would have accumulated families wouldgenerally Most right: to skewed the surely be strongly worth wouldalmost distribution ofhousehold net The Solution: is $556,300. families net worthofU.S.these mean net families is$120,300.The median the that versus meanfor networth. Median visible in visible the histogram. plots reveal butboxplotBoth thethis the right-skew distribution, does peaksof not show the two Histogram: Histogram:
What explains the difference between these two measures ofcentre? these twomeasures between difference the explains What Dataset A small accounting firm pays each ofits sixclerks payseach $35,000,two accountingfirm small A
Frequency 0 1 2 3 4 5 6 7 8 9 0
Diameter 10 10 20 30 40 50 60 70 0 20 A report on the assets of American households says says onthehouseholds ofAmerican assets report A Histogram of Diameter 30 Diameter Boxplot of Diameter 40 50 60 70 80 35000
35000
35000
35000 Sum of Dataset = 690000
35000 Mean of Dataset = 76666.7 35000 Six of the nine employees earn less than the 80000 mean. 80000
320000
7. How does the median change? The firm in Problem 6 gives no raises to the clerks and junior accountants, while the owner’s take increases to $455,000. How does this change affect the mean? How does it affect the median? Solution: Dataset_2
35000
35000
35000 Mean of Dataset_2 = 91666.7
35000 Median of Dataset_2 = 35000
35000
35000
80000
80000
455000 8. Metabolic rates. Calculate the mean and standard deviation of the metabolic rates , showing each step in detail: MetabolicRate 1792 1666 1362 1614 1460 1867 1439 First find the mean by summing the 7 observations and dividing by 7. Then find each of the deviations and their squares. Check that the deviations have sum 0. Calculate the variance as an average of the squared deviations (remember to divide by n − 1). Finally, obtain s as the square root of the variance. Solution:
9. Hummingbirds and flowers. (heliconia.xls). Different varieties of the tropical flower Heliconia are fertilized by different species of hummingbirds. Over time, the lengths of the flowers and the form of the hummingbirds’ beaks have evolved to match each other. Here are data on the lengths in millimetres of three varieties of these flowers on the island of Dominica: Make boxplots to compare the three distributions. Report the five-number summaries along with your graph. What are the most important differences among the three varieties of flower? Solution: Boxplot of Length by Variety
50.0
47.5
45.0 h t
g 42.5 n e L 40.0
37.5
35.0
bihai red yellow Variety
Descriptive Statistics: Length
Variable Variety Minimum Q1 Median Q3 Maximum Length bihai 46.340 46.690 47.120 48.293 50.260 red 37.400 38.070 39.160 41.690 43.090 yellow 34.570 35.450 36.110 36.820 38.130