August 1997 Submitted to HPTS 97
Storage Metrics Jim Gray, Goetz Graefe Microsoft Research, 301 Howard St. #830, SF, CA 94105 {Gray, GoetzG}@Microsoft.com
Abstract: Simple economic and performance arguments indicated appropriate lifetimes for main memory pages and sizes of main memory buffer pools. The fundamental tradeoffs are the prices and bandwidths of DRAMs and disks. They roughly indicate that current systems should have about 10 MB of DRAM per randomly accessed disk, and 100 MB of DRAM per sequentially accessed disk. They also indicate that 16 KB is a good size for index pages today. These rules-of-thumb change in predictable ways as technology ratios change.
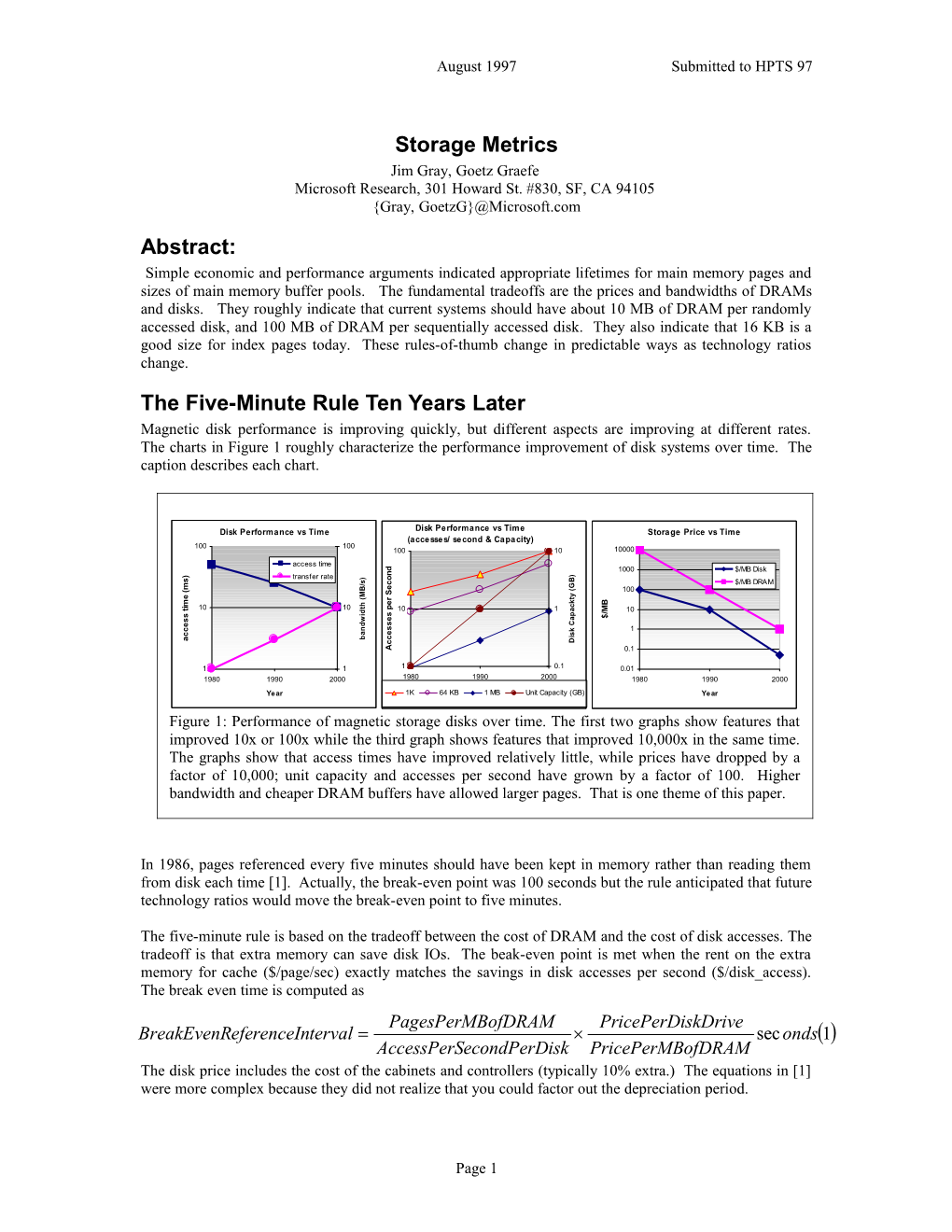
The Five-Minute Rule Ten Years Later Magnetic disk performance is improving quickly, but different aspects are improving at different rates. The charts in Figure 1 roughly characterize the performance improvement of disk systems over time. The caption describes each chart.
Disk Performance vs Time Disk Performance vs Time Storage Price vs Time (accesses/ second & Capacity) 100 100 100 10 10000 access time
d 1000 $/MB Disk n ) ) )
transfer rate o B s s c
/ $/MB DRAM G e m ( B (
100
S y M e t ( r
k e B h m c i t p
t 10 10 a 10 1 M
10 d / i p s s $ a e w s C s d e
s n k c 1 a e s c i b c a D c
A 0.1
1 1 1 0.1 0.01 1980 1990 2000 1980 1990 2000 1980 1990 2000 Year 1K 64 KB Year1 MB Unit Capacity (GB) Year
Figure 1: Performance of magnetic storage disks over time. The first two graphs show features that improved 10x or 100x while the third graph shows features that improved 10,000x in the same time. The graphs show that access times have improved relatively little, while prices have dropped by a factor of 10,000; unit capacity and accesses per second have grown by a factor of 100. Higher bandwidth and cheaper DRAM buffers have allowed larger pages. That is one theme of this paper.
In 1986, pages referenced every five minutes should have been kept in memory rather than reading them from disk each time [1]. Actually, the break-even point was 100 seconds but the rule anticipated that future technology ratios would move the break-even point to five minutes.
The five-minute rule is based on the tradeoff between the cost of DRAM and the cost of disk accesses. The tradeoff is that extra memory can save disk IOs. The beak-even point is met when the rent on the extra memory for cache ($/page/sec) exactly matches the savings in disk accesses per second ($/disk_access). The break even time is computed as PagesPerMBofDRAM PricePerDiskDrive BreakEvenReferenceInterval seconds1 AccessPerSecondPerDisk PricePerMBofDRAM The disk price includes the cost of the cabinets and controllers (typically 10% extra.) The equations in [1] were more complex because they did not realize that you could factor out the depreciation period.
Page 1 August 1997 Submitted to HPTS 97
The price and performance from a recent DELL TPC-C benchmark [2] gives the following numbers for Equation 1:
PagesPerMBofDRAM = 128 pages/MB (i.e., 8KB pages) AccessesPerSecondPerDisk = 64 access/sec/disk PricePerDiskDrive = 2000 $/disk (9GB + controller) PricePerMBofDRAM = 15 $/MB_DRAM
Evaluating Equation 1 with these values gives a reference interval of 266 seconds -- about five minutes. The current 2 KB page-size of Microsoft SQL Server 6.5 gives a reference interval of 20 minutes. So, data referenced every five minutes should be kept in main memory.
The DELL prices are very competitive. Server hardware prices are often three times higher for than "street prices" for the same components. DEC Polaris DRAM is half the price of DELL. If recent TPC-C Compaq prices are used then DRAM costs 3x as much (47$/MB) and disk costs twice as much (3129$/drive) giving a two-minute rule. The March 1997 SUN+Oracle TPC-C benchmark [3] had prices even better than DELL (13$/MB of DRAM and 1690$ per 4GB disks and controllers). These systems all are near the five-minute rule. Mainframes are at 130$/MB for DRAM (and 10K$/MIP) and 12k$/drive so mainframes follow a three-minute rule.
Looking at the trend lines in Figure 1, the technology ratio is shifting. Page size has increased with accesses/second so the first term of Equation 1 (PagesPerMBofDRAM/AccessPerSecondPerDisk) has decreased ten fold (from 512/30 = 17 to 128/60 = 2). Disk drive prices dropped 10x and DRAM prices dropped 200x, so that the second ratio of equation (1) was cut in half (20k$/2k$=10 to 2k$/10$=200). The consequent reference interval of equation (1) went from 170 seconds (17x10) to 400 seconds (2x200). The net is that the reference interval of Equation (1) is almost unchanged, dispite these 10x, 100x, and 1,000x changes. It is still in the 1-minute to 10-minute range.
One interesting consequence that batch operations like sort or hash-join that have a one-pass or two-pass option, should only go to two passes if the utility will run for several minutes. Since an SMP sort can currently process about 5GB/minute [4], this suggests that sorts smaller than 25 GB should be done in one pass. The issues are slightly more complex because sort and these other utilities use sequential IO. That means that they can move data 10x or 100x more efficiently than small (8KB) random IO. The next section explores that issue.
One-Pass or Two-Pass Sorts Consider the memory-disk access behavior of Sort in particular. Sort uses sequential data access and large disk transfers to optimize disk utilization and bandwidth. In addition, the reference interval of pages is sometimes known to be extremely long. Using the DEC TPC-C prices, suppose that the page size goes to 64KB. Then the page transfer time (at 6.4MB/s) is 10 milliseconds, and the disk service time is about 22ms. With large transfer sizes, the disk can service at most 50 accesses per second. Let’s assume about 2/3 utilization at 33 accesses per second per disk. PagesPerMBofDRAM = 16 pages/MB AccessesPerSecondPerDisk = 32 access/sec/disk (i.e. 2/3 utilization)
With these parameters Equation 1 yields a break-even reference interval of 100 seconds. That means that hash joins, sorts, cubes, and other sequential operations should use main memory to remember data if the algorithm will revisit the data within 100 seconds. For example, a one-pass sort is known to run at about 5 GB/minute. Such sorts use 1/2 the IO bandwidth of a 2-pass sort. If the sorted file is less than 8 GB the sort should run within 100 seconds on a dedicated machine. Below 8 GB a one-pass sort is warranted. Beyond that size, a two-pass sort is warranted. Two pass sorts are known to need approximately:
MemoryForTwoPasssSort 6 Buffer _ Size 3 Buffer _ Size File _ Size...... (2)
Page 2 August 1997 Submitted to HPTS 97
This equation derives from the fact that the first pass produces about (File_Size/Memory_Size) runs while the second pass can merge Memory_Size/Buffer_Size runs. The constants (3 and 6) depend on the particular sort algorithm. Equation 2 is graphed in Figure 2 for file sizes from Megabytes to Exabytes. Figure 2 shows that files smaller than a few gigabytes should be sorted in one-pass. Once you cross the economic threshold (about 5 GB), use a two-pass sort. With 5GB of DRAM a two-pass sort can sort 100 Terabytes. This covers ALL current sorting needs.
DRAM Needed for aTwo-pass Sort Gigabytes Can Sort PetaBytes 1.E+12 d e d e e n 1.E+09 One e z i Pass s
M Region A R D
1.E+06 1.E+06 1.E+09 1.E+12 1.E+15 1.E+18 Size of input file
Figure 2: A two-pass sort can process 100 terabyte files with a 5 GB DRAM buffer. So, with current technology, use a 1-pass sort up to 5GB files and then go to a 2-pass sort.
Similar comments apply to sequential operations (group by, rollup, cube, hash join, index build,…)
How Much Memory Should Be Allocated to TempDB (Query Working Storage)? Since both buffer space and bandwidth are shared (multiplexed) among multiple concurrent sort, hash, aggregate, and utility operations, the analysis above applies not only to a single operation but also to the system as a whole. Note that the "batch" memory considered above is separate from the general-purpose I/O buffer inasmuch as the bandwidth to tempdb is separate from the bandwidth to persistent databases. If sort and hash operations perform I/O operations in 64 KB units, the calculations above suggest that each buffer should turn over once every two minutes (~100 seconds). Therefore the entire buffer space should turn over in this time. That means it should be read and perhaps written in this time. If the total bandwidth to the buffer pool (when using this I/O size) is 40 MB/s, the merge or partitioning bandwidth is 20 MB/s (to account for reading and writing). Thus, the buffer space should be 20 MB/s * 100 s = 2 GB. If the tempdb bandwidth is lower or higher, the calculated buffer space will be proportionately lower or higher proportionally, e.g., 10 GB for 100 MB/s instead of 20 MB/s. Put another way, each 5 MBps sequential disk needs to be complemented with a 250MB of DRAM for buffer space. At current prices this is 1 k$ of DRAM for a 2 k$ disk (and controller). Current TPC-C benchmarks typically have 10 MB of DRAM per disk, but these benchmarks are doing random IO which is 10x less bandwidth. Using these arguments, one would expect 20MB of DRAM per disk. This is close to the observed value. Another way of thinking of this is that the current Intel 4xP6 delivers about 50MB/s of IO bandwidth on typical applications (100 MBps max), and typically comes with 2 GB of DRAM (a 80 second turnover time). One cautionary note, systems are often controller-limited rather than disk limited. Controllers are limited to 7, 15, or 30 MBps depending on the generation -- but the controllers often attach 5 or 10 drives. So, it is dangerous to measure bandwidth by counting disks. The real metric is min{bus, controllers, disks}.
Page 3 August 1997 Submitted to HPTS 97
Checkpoint Strategies In Light of the 10-minute Rule Buffer managers typically use an LRU or Clock2 (two round clock) algorithm to manage the buffer pool. In general, they flush (write to disk) pages if (1) there is contention for cache space, or (2) checkpoint if the page has been dirty for a long time. The checkpoint interval is typically five minutes. This limits recovery to redoing the last five or ten minutes of the log.
Hot standby or remote disaster systems reduce the need for checkpoints because they continuously run recovery on their version of the database and can take over within seconds. In these disaster tolerant systems, checkpoints can be very infrequent and almost all flushes are contention flushes.
To implement the N-minute rule for contention flushes and evictions, the buffer manager keeps a list of the names of all pages touched within the last N minutes. When a page is re-read from disk, if it is in the N- minute list, it is given an N-minute lifetime (it will not be evicted for N-minutes in the future). This simple algorithm assures that frequently accessed pages are kept in the pool, while pages that are not re-referenced are aggressively y evicted.
Summary of Changes to the Five-Minute Rule In summary, the five-minute rule still seems to apply to randomly accessed pages, primarily because page sizes have grown from 1KB to 8KB to compensate for changing technology ratios. For large (64KB pages) and sequential access, a two-minute rule applies today.
How Large Should Index Pages Be? The size of an internal index page determines its retrieval cost and fan-out. The utility of an index page measures how much closer the index brings an associative search to the destination data record. In general, a B-tree indexing N items will have height log2(N)/log2(EntriesPerPage). The utility of an internal index page is proportional to the logarithm base 2 of the fan-out (the log of the average number of entries per page). IndexPageUtility = log2(EntriesPerPage) (3) The idea is that utility measures how many levels of a binary tree the index page covers. Each level represents one step closer to the answer. For example, if each index entry is 20 bytes, then a 2 KB index page that is 70% full will contain about 70 entries. Such a page will have a utility of 6.2, about half the utility of a 128 KB index page (see Table 4).
Figure 3: The utility of an index page is the number Table 4: TabulationAn of index page utility and benefit/costof levels for of 20the bytetree indexthat it entriestraverses. assuming The utility each risespage is 70% full and assumingindex a 10ms latency 10 MBps transferas the rate. log of the page size. The cost of the access page sizepage entries per page Indexgoes Page up linearly withdisk page page size. Consequently,benefit/ for a KB Fan-out Utilityparticular disk latencyread time and (ms) transfer rate,cost there (20B) is an 2 72 optimal6.2 index page size.10.2 0.60 4 143 7.2 10.4 0.69 8 287 8.2 10.8 0.75 16 573 9.2 11.6 0.79 32 1,147 10.2 13.3 0.77 64 2,294 11.2 16.6 0.67 128 4,588 12.2 23.1 0.53
Reading an index page from disk has a certain cost. Reading a 2 KB page from a disk with a 10 ms average access time (seek and rotation) and 10 MB/s transfer rate uses 10.2 ms of disk device time. The service time for such a request is twice that if the disk is 50% utilized. So the read cost is 10.2 ms or 20.4 milliseconds. More generally, the cost of accessing an index page is either the storage cost in main memory if the page is cached there, or the access cost if the page is stored on disk. The index page disk access cost is
Page 4 August 1997 Submitted to HPTS 97
IndexPageAccessCost = Disk Latency + PageSize / DiskTransferRate (4) The benefit-cost ratio of a certain page size and entry size is the ratio of the two quantities. IndexPageBenift/Cost = IndexPageUtility / IndexPageAccessCost. (5) The right column of Table 4 shows this computation for various page sizes assuming 20-byte index entries. It indicates that 16 KB pages are near optimal for these parameters.
Index Page Utility vs Page Size Index Page Utility vs Page Size and Index Elemet Size and Disk Performance 1.00 1.00
0.90 0.90
0.80 10 MB/s 0.80 y t i y
16 byte entries l t i i
t 0.70 l i 0.70 t 32 byte U 5 MB/s
U 0.60 0.60 64 byte 0.50 3 MB/s 0.50 128 byte 1MB/s 0.40 2 4 8 16 32 64 128 0.40 2 4 8 16 32 64 128 40 MB/s 0.65 0.74 0.83 0.91 0.97 0.99 0.94 16 B 0.64 0.72 0.78 0.82 0.79 0.69 0.54 10 MB/s 0.64 0.72 0.78 0.82 0.79 0.69 0.54 32 B 0.54 0.62 0.69 0.73 0.71 0.63 0.50 5 MB/s 0.62 0.69 0.73 0.71 0.63 0.50 0.34 64 B 0.44 0.53 0.60 0.64 0.64 0.57 0.45 3 MB/s 0.51 0.56 0.58 0.54 0.46 0.34 0.22 128 B 0.34 0.43 0.51 0.56 0.56 0.51 0.41 1 MB/s 0.40 0.44 0.44 0.41 0.33 0.24 0.16 Page Size (KB) Page Size (KB)
Figure 5. (a) The left graph shows the utility of index pages versus page size for various index entry sizes using a high-performance disk (10ms latency, 10 MB/s transfer rate). (b) The graphs at right use a 16-byte entry and show the graphs for lower-performance disk transfer rates ranging from 1MB/s to 10MB/s.
Figure 5 graphs the benefit/cost ratios for various entry sizes and page sizes for both current, and next- generation disks. The graphs indicate that, small pages have low benefit because they have low utility and high fixed disk read costs. Very large pages also have low benefit because utility grows only as the log of the page size, but transfer cost grows linearly with page size. Table 4 and Figure 5 indicate that for current devices, index page sizes in the range of 8 KB to 32 KB are preferable to smaller and larger page sizes. By the year 2003, disks are predicted to have 40 MB/s transfer rates and so 8 KB pages will probably be too small.
Summary The fact that disk access speeds have increased ten-fold in the last twenty years is impressive. But it pales when compared to the hundred-fold increase in disk unit capacity and the ten-thousand-fold decrease in storage costs (Figure 1). In part, growing page sizes sixteen-fold from 512 bytes to 8 KB has ameliorated these differential changes. This growth preserved the five-minute rule for randomly accessed pages. A hundred-second rule applies to sequentially accessed pages.
References [1] J. Gray & G. F. Putzolu, "The Five-minute Rule for Trading Memory for Disc Accesses, and the 10 Byte Rule for Trading Memory for CPU Time," Proceedings of SIGMOD 87, June 1987, pp. 395- 398.
Page 5 August 1997 Submitted to HPTS 97
[2] Dell-Microsoft TPC-C Executive summary: http://www.tpc.org/results/individual_results/Dell/dell.6100.es.pdf [3] Sun-Oracle TPC-C Executive summary: http://www.tpc.org/results/individual_results/Sun/sun.ue6000.oracle.es.pdf [4] Ordinal Corp. http://www.ordinal.com/
Page 6