Towards Malleable Distributed Storage Systems: from Models to Practice Nathanaël Cheriere
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ISA RULEBOOK & CONTEST ADMINISTRATION MANUAL 1 December 2018
ISA RULEBOOK & CONTEST ADMINISTRATION MANUAL 1 December 2018 ISA Rule Book –1 Decembert 2018 1 CHAPTER 1: ISA Introduction and Operations .......................................................................................................................... 4 I. About the ISA ................................................................................................................................................................. 4 II. ISA Membership Categories ........................................................................................................................................... 4 III. ISA Participating vs. Non-Participating Members ........................................................................................................... 4 IV. ISA Membership Sub Categories ................................................................................................................................... 5 V. ISA Recognized Continental Associations ...................................................................................................................... 5 VI. ISA Recognized Organizations ....................................................................................................................................... 5 VII. Application for ISA Membership ..................................................................................................................................... 5 VIII. ISA Member Nations (100) ............................................................................................................................................ -
21 Cdc Master Both
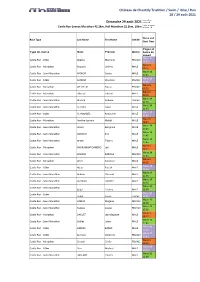
Château de Chantilly Triathlon / Swim / Bike / Run 28 / 29 août 2021 Colour of race Dimanche 29 août 2021 number ê Couleur du numéro Castle Run Events: Marathon 42.2km, Half Marathon 21.1km, 10km de course ê Wave and Race Type Last Name First Name Gender Start Time Vague et Type de course Nom Prénom Genre heure de départ Wave 16 Castle Run - 10km Ababou Marilyne FEMALE 12:30 Wave 5 Castle Run - Marathon Acquart Jérôme MALE 09:15 Wave 14 Castle Run - Semi Marathon AFONSO Carlos MALE 11:45 Wave 16 Castle Run - 10km AFONSO Charlotte FEMALE 12:30 Wave 5 Castle Run - Marathon AIT-HELAL Touria FEMALE 09:15 Wave 5 Castle Run - Marathon akkaoui sofiane MALE 09:15 Wave 14 Castle Run - Semi Marathon Alazard Noémie FEMALE 11:45 Wave 14 Castle Run - Semi Marathon ALFANO Fabio MALE 11:45 Wave 17 Castle Run - 10km ALI MOKBEL Rodouane MALE 12:45 Wave 5 Castle Run - Marathon Amiche-Lechani Mehdi MALE 09:15 Wave 14 Castle Run - Semi Marathon Amiot Benjamin MALE 11:45 Wave 14 Castle Run - Semi Marathon ANDIOLE Eric MALE 11:45 Wave 14 Castle Run - Semi Marathon Andre Thierry MALE 11:45 Wave 5 Castle Run - Marathon ANDRIANANTOANDRO Joël MALE 09:15 Wave 14 Castle Run - Semi Marathon AOUDIA RAFICKA FEMALE 11:45 Wave 5 Castle Run - Marathon Aricò Salvatore MALE 09:15 Wave 16 Castle Run - 10km Attias Patrick MALE 12:30 Wave 14 Castle Run - Semi Marathon Aubrée Clément MALE 11:45 Wave 14 Castle Run - Semi Marathon AUDRAN FABRICE MALE 11:45 Wave 15 Castle Run - Semi Marathon babel frederic MALE 12:00 Wave 16 Castle Run - 10km Babel Suada FEMALE 12:30 Wave 15 Castle -

Common Catalogue of Varieties of Vegetable Species 28Th Complete Edition (2009/C 248 A/01)
16.10.2009 EN Official Journal of the European Union C 248 A/1 II (Information) INFORMATION FROM EUROPEAN UNION INSTITUTIONS AND BODIES COMMISSION Common catalogue of varieties of vegetable species 28th complete edition (2009/C 248 A/01) CONTENTS Page Legend . 7 List of vegetable species . 10 1. Allium cepa L. 10 1 Allium cepa L. — Aggregatum group — Shallot . 10 2 Allium cepa L. — Cepa group — Onion or Echalion . 10 2. Allium fistulosum L. — Japanese bunching onion or Welsh onion . 34 3. Allium porrum L. — Leek . 35 4. Allium sativum L. — Garlic . 41 5. Allium schoenoprasum L. — Chives . 44 6. Anthriscus cerefolium L. — Hoffm. Chervil . 44 7. Apium graveolens L. 44 1 Apium graveolens L. — Celery . 44 2 Apium graveolens L. — Celeriac . 47 8. Asparagus officinalis L. — Asparagus . 49 9. Beta vulgaris L. 51 1 Beta vulgaris L. — Beetroot, including Cheltenham beet . 51 2 Beta vulgaris L. — Spinach beet or Chard . 55 10. Brassica oleracea L. 58 1 Brassica oleracea L. — Curly kale . 58 2 Brassica oleracea L. — Cauliflower . 59 3 Brassica oleracea L. — Sprouting broccoli or Calabrese . 77 C 248 A/2 EN Official Journal of the European Union 16.10.2009 Page 4 Brassica oleracea L. — Brussels sprouts . 81 5 Brassica oleracea L. — Savoy cabbage . 84 6 Brassica oleracea L. — White cabbage . 89 7 Brassica oleracea L. — Red cabbage . 107 8 Brassica oleracea L. — Kohlrabi . 110 11. Brassica rapa L. 113 1 Brassica rapa L. — Chinese cabbage . 113 2 Brassica rapa L. — Turnip . 115 12. Capsicum annuum L. — Chili or Pepper . 120 13. Cichorium endivia L. 166 1 Cichorium endivia L. -

Iqfoil Junior & Youth World Championships 2021 U19
iQFoil Junior & Youth World Championships 2021 U19 Men 26-31 July 2021, Campione del Garda, ITALY Slalom Groups for Day 2 - 28th July 2021 Page 1 Nat Sail No Slalom Group Flight HelmName Count = 19 B1 BEL 120 B1 Blue Tibby Caroen ESP 679 B1 Blue Javier Clement Serna FRA 90 B1 Blue Grabriel Grouzis FRA 148 B1 Blue Antoine Massuard FRA 373 B1 Blue Clément Destombes FRA 376 B1 Blue Ewen Kermorgant FRA 684 B1 Blue Bastien Groueix FRA 987 B1 Blue Lory Corentin GBR 593 B1 Blue Roan Clarke GBR 713 B1 Blue Duncan Monaghan GBR 783 B1 Blue Tommy Millard HKG 19 B1 Blue Cyrus Cheuk Hin Lai ITA 200 B1 Blue Pietro Gamberini POL 46 B1 Blue Daniel Ugniewski POL 107 B1 Blue Maciej Pietrzak POL 168 B1 Blue Leonard Domachowski POL 197 B1 Blue Antoni Siwek POL 375 B1 Blue Maksymilian Szweda POL 520 B1 Blue Antoni Antoniewski Page 2 Nat Sail No Flight Slalom Group HelmName Count = 19 B2 BEL 224 B2 Blue Siebe Elsmoortel CZE 784 B2 Blue Adam Nevelos FRA 251 B2 Blue Louis Dutertre Salnelle FRA 316 B2 Blue Titouan Billy FRA 379 B2 Blue Gaspard Carfantan FRA 1111 B2 Blue Armand Genevois FRA 2004 B2 Blue Thibault Charra GBR 262 B2 Blue Max Beaman GBR 706 B2 Blue Luke Pailing GER 37 B2 Blue Elias Von Maydell HUN9 B2 Blue Balint Antal Morvai HUN 183 B2 Blue Milán Schneider ISR 23 B2 Blue Guy Havoinik ISR 615 B2 Blue Twil Noar ISR 665 B2 Blue Harriel Mizrachi ITA 135 B2 Blue Giorgio Falqui Cao ITA 155 B2 Blue Leonardo Tomasini LAT 78 B2 Blue Henrijs Vigants LAT 401 B2 Blue Arturs Sprindzuks Page 3 Nat Sail No Flight Slalom Group HelmName Count = 19 B3 CHI2 B3 Blue -

46Th Annual Convention
NORTHEAST MODERNM LANGUAGLE ASSOACIATION Northeast Modern Language Association 46th Annual Convention April 30 – May 3, 2015 TORONTO, ONTARIO Local Host: Ryerson University Administrative Sponsor: University at Buffalo www.buffalo.edu/nemla Northeast-Modern_language Association-NeMLA #NeMLA2015 CONVENTION STAFF Executive Director Marketing Coordinator Carine Mardorossian Derek McGrath University at Buffalo Stony Brook University, SUNY Associate Executive Director Local Liaisons Brandi So Alison Hedley Stony Brook University, SUNY Ryerson University Andrea Schofield Administrative Coordinator Ryerson University Renata Towne University at Buffalo Webmaster Jesse Miller Chair Coordinator University at Buffalo Kristin LeVeness SUNY Nassau Community College Fellows CV Clinic Assistant Fellowship and Awards Assistant Indigo Erikson Angela Wong Northern Virginia Community College SUNY Buffalo Chair and Media Assistant Professional Development Assistant Caroline Burke Erin Grogan Stony Brook University, SUNY SUNY Buffalo Convention Program Assistant Promotions Assistants W. Dustin Parrott Adam Drury SUNY Buffalo SUNY Buffalo Allison Siehnel Declan Gould SUNY Buffalo SUNY Buffalo Exhibitor Assistants Schedule Assistant Jesse Miller Iven Heister SUNY Buffalo SUNY Buffalo Brandi So Stony Brook University, SUNY Travel Awards Assistant Travis Matteson SUNY Buffalo 2 3 Board of Directors Welcome to Toronto and NeMLA’s much awaited return to Canada! This multicultural and President multilingual city is the perfect gathering place to offer our convention Daniela B. Antonucci | Princeton University attendees a vast and diversified selection of cultural attractions. While First Vice President in Toronto, enjoy a performance of W. Somerset Maugham’s Of Human Benjamin Railton | Fitchburg State University Bondage at the Soul Pepper Theatre, with tickets discounted thanks to Second Vice President the negotiations of NeMLA and our host, Ryerson University. -
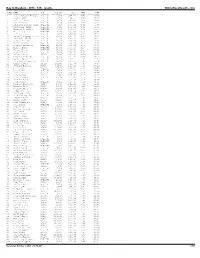
Bay to Breakers - 2015 - 12K - Results Onlineraceresults.Com
Bay to Breakers - 2015 - 12K - results OnlineRaceResults.com PLACE NAME DIV DIV PL HILL PACE TIME ----- ---------------------- ------- --------- ----------- ------- ----------- 1 Isaac Mukundi Mwangi M-ELITE 1/29 2:54.73 4:45 35:25 2 Bashir Abdi M-ELITE 2/29 2:44.13 4:46 35:27 3 Julius Kieter M-ELITE 3/29 2:50.80 4:46 35:30 4 Kevin Kochei M-ELITE 4/29 3:02.84 4:48 35:47 5 Afewerki Berhane Hidru M-ELITE 5/29 2:55.90 4:49 35:49 6 MacDonard Ondara M-ELITE 6/29 2:59.49 4:49 35:53 7 Kimutai Cheruiyot M-ELITE 7/29 2:52.57 4:50 35:57 8 Frezer Legesse M-ELITE 8/29 2:55.66 4:51 36:04 9 Hillary Too M-ELITE 9/29 2:59.80 4:52 36:13 10 Kenneth Kipyego Rotich M-ELITE 10/29 2:51.16 4:53 36:23 11 Fernando Cabada M-ELITE 11/29 3:00.13 4:53 36:24 12 Nick Arciniaga M-ELITE 12/29 3:05.60 4:54 36:29 13 Danny Mercado M-ELITE 13/29 3:00.20 4:54 36:30 14 Tesfaye Alemayehu M-ELITE 14/29 3:01.08 4:55 36:33 15 Elisha Barno M-ELITE 15/29 2:57.23 4:55 36:36 16 Tuemay Tsegay M-ELITE 16/29 2:50.07 4:57 36:48 17 Nick Hilton M-ELITE 17/29 2:52.27 4:57 36:55 18 Jesse Cherry M2529 1/2182 3:07.43 4:58 36:58 19 Malcolm Richards M-ELITE 18/29 3:11.73 5:00 37:13 20 Nelson Oyugi M-ELITE 19/29 2:49.61 5:02 37:25 21 John Muritu Wanjiku M-ELITE 20/29 3:01.17 5:02 37:26 22 Chris Chavez M2529 2/2182 3:11.78 5:07 38:07 23 Stewart Harwell M3034 1/2342 3:15.30 5:10 38:29 24 Rio Reina M2529 3/2182 3:16.33 5:12 38:40 25 Daniel Wallis M-ELITE 21/29 3:17.27 5:12 38:47 26 Forest Misenti M-ELITE 22/29 3:07.76 5:14 38:55 27 Dave Berden M3034 2/2342 3:25.64 5:17 39:17 28 Linus Chumba M-ELITE -

Saint-Piat Et Ses Hameaux N° 89 - Janvier 2021
Saint-Piat et ses hameaux n° 89 - janvier 2021 Bulletin communal d’informations retrouvez toutes les informations sur le site internet de la mairie http://www.saint-piat.fr Agenda Renseignements Janvier pratiques Mairie Tél. 02 37 32 30 20 Dimanche 31 janvier : loto de l’A.P.E. fax 02 37 32 49 44 Ouverture au public Février mardi et jeudi 17 h 00 à 18 h 30 Mardi 23 février : repas partagé du Club de la Vallée. mercredi 10 h 00 à 12 h 00 samedi 9h30 à 11 h 00 Mars Permanence du Maire samedi 9 h 30 à 12 h 00 13/14 mars : spectacle du Comité des Fêtes. Permanence urbanisme sur rendez-vous uniquement 20/21 mars : vide dressing de l’Amicale des 4 Villages. Permanence CCAS le mardi de 17 h 00 à 18 h 30 Samedi 27 mars : soirée dansante du Club de la Vallée. C.C. des Portes Euréliennes 02 37 83 49 33 Avril Service des eaux 02 37 32 38 88 3 avril : festival d’humour. Fontainier 06 71 36 96 53 10/11 avril : exposition « carnets de voyage » de Syndicat scolaire 02 37 32 48 61 Kaléidos’Art. Ecole 02 37 32 45 25 17 avril : concert Cécile Corbel. Bibliothèque 02 37 32 35 24 24/25 avril : « Mon voisin est un artiste » par le Comité des ouverture le lundi de 17 h 00 à 19 h 00 Fêtes. et le mercredi de 14 h 00 à 17 h 00 Mai Pharmacie 02 37 32 36 17 Mardi 4 mai : repas de printemps du Club de la Vallée. -

Challenge De Wissous Benjamins 28/03/2010 18:50:17
Document Engarde Challenge de Wissous Benjamins 28/03/2010 18:50:17 Classement général (ordre des rangs) rang nom prénom club 1 PERES Hugo BOURG REINE 2 AYMERICH Pierre ST GERMAIN E 3 CEDOLIN Anthony CHILLY MORAN 3 KOUN Camille ST MICHEL SP 5 JALLET Benoit VANVES SE 6 GALBERT Tom CHILLY MORAN 7 MARINHO Mathieu MASSY CE 8 GOUBAND Paul ANTONY 9 HEURTIER Audric ISSY MOUSQUE 10 GUIGNES Nicolas MENNECY 11 COLLY Vincent VANVES SE 12 MANGUIN GOURITIN Clement WISSOUS 13 BIAU Alexandre MASSY CE 14 BALLEYGUIER Theophile PALAISEAU 15 ADOLEHOUME Augustin VANVES SE 16 PENNER Julia Marie ST GERMAIN E 17 THIMOLEON Nicolas BREUILLET 18 CAZARD Gregory BREUILLET 19 MASCLET RAULT Alexandre ST MICHEL SP 20 TAIBI Malik WISSOUS 21 SALAUN Margot BREUILLET 22 RAVEAUX Isis BREUILLET Document Engarde Challenge de Wissous - Poussins 2001 28/03/2010 18:51:05 Classement général (ordre des rangs) rang nom prénom club 1 LE BOUQUIN Nicolas CADETS ESSON 2 BARTHEL Baptiste VILLE AVRAY 3 EICH GOZZI Aymeric BOURG REINE 3 VAN RENTERGUEM Josephine BREUILLET 5 KOUN Valentin ST MICHEL SP 6 WILLIOT Antoine BREUILLET 7 ROBIN Raphael BOURG REINE 8 DAROWNY Titouan BREUILLET 9 DIB Adrien BOURG REINE 10 PARADIS Floscel VILLE AVRAY 11 LE GARREC Clemnt BREUILLET 12 RIEBEL Nicolas VILLE AVRAY 13 SIBY Artur MONTGERON 14 JOUFFLINEAU Oceane MASSY CE 15 BOLZE Olivier ISSY MOUSQUE 16 LOHMULLER Hugo ST GERMAIN E 17 CHAHKAR Saman Antony ANTONY 18 RAMADANI Houssama VAL D ORGE 19 LAURENTIE Adrien BOURG REINE 20 AMIOT Gabriel CADETS ESSON 21 PERROTTE Mathis VILLE AVRAY 22 NOUVELLON Pierre Louis -

Contractor License Hy-Tek's MEET MANAGER 11:31 AM 4/18/2019 Page 1 Georgia Tech Invitational - 4/19/2019 to 4/20/2019 George C
Delta Timing Group - Contractor License Hy-Tek's MEET MANAGER 11:31 AM 4/18/2019 Page 1 Georgia Tech Invitational - 4/19/2019 to 4/20/2019 George C. Griffin Track Meet Program Event 1 Men Hammer Throw Event 3 Men Javelin Throw Top 9 advance to final. Top 9 advance to final. Minimum measurement: 44.00m / 144' 4" Minimum measurement: 48.00m / 157' 6" Pos Name School Seed Mark Pos Name School Seed Mark Flight 1 of 1 Finals Flight 1 of 1 Finals 1 Ryan Sheldon Belmont 1 Logan Blomquist SE Missouri 2 Corey Claiborne Unattached 2 Chris Jernigan Emory 3 Stephen Gibson Belmont 3 Titouan Sajous SE Missouri 4 Stephen Zagurski SE Missouri 4 Samuel Duarte Lee (Tenn.) 5 Michael Coppolino Brown 5 Andrew Ryan SE Missouri 6 Logan Blomquist SE Missouri 6 Michael Willingham Jr. Tennessee St 7 Owen Russell Brown 7 Patrick Crockett Emory 8 Joe Frye Music City M 8 Mark Kimura Smith Georgia Tech 9 Quann Shears Unattached Event 2 Women Hammer Throw 10 Jonah Gosnay So. Conn. St Top 9 advance to final. 11 Joe Grula Brown Minimum measurement: 44.00m / 144' 4" 12 Hunter Stokes So. Conn. St Pos Name School Seed Mark 13 Capers Williamson Unattached Flight 1 of 2 Finals 1 Cody Chandler Unattached Event 4 Women Javelin Throw 2 Jewel Wagner Murray State Top 9 advance to final. 3 Alexis Gant Georgia Sout Minimum measurement: 36.00m / 118' 1" 4 Destiny Carey Murray State Pos Name School Seed Mark 5 Shanell Atkins UCF Flight 1 of 1 Finals 6 Lana Fulcher Georgia Stat 1 Alexis Stevens Lee (Tenn.) 7 Nicole Humphreys SE Missouri 2 Alexus Groom Murray State 8 Soteria Russell -
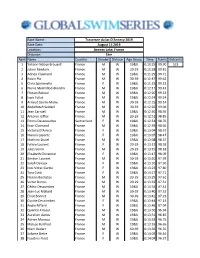
Race Name: Race Date: Location: Distance: Rank Name Country Gender Division Age Group Time Points Entrants 1 Yohann Ndoye Brouar
Race Name: Traversee du lac D'Annecy 2019 Race Date: August 15 2019 Location: Annecy Lake, France Distance: 1km Rank Name Country Gender Division Age Group Time Points Entrants 1 Yohann Ndoye Brouard France M W 19&U 0:10:25 99.90 523 2 Julien Randoin France M W 20-29 0:11:28 99.81 3 Adrien Claimand France M W 19&U 0:11:29 99.71 4 Robin Pla France M W 30-39 0:11:47 99.62 5 Clara Sgaramella France F W 19&U 0:11:52 99.52 6 Pierre Mermillod-Blondin France M W 19&U 0:12:17 99.43 7 Florian Reboul France M W 19&U 0:12:20 99.33 8 Isaïe Follet France M W 19&U 0:12:24 99.24 9 Arnaud Sainte-Marie France M W 30-39 0:12:25 99.14 10 Abdelfetah Saidani France M W 30-39 0:12:26 99.04 11 Jean Carruel France M W 19&U 0:12:30 98.95 12 Antoine Jaffiol France M W 20-29 0:12:52 98.85 13 Emma Descoeudres Switzerland F W 19&U 0:12:54 98.76 14 Evan Claimand France M W 19&U 0:12:59 98.66 15 Victoria D'Amico France F W 19&U 0:13:04 98.57 16 Manon Laporte France F W 19&U 0:13:07 98.47 17 Mathieu Stutel France M W 19&U 0:13:08 98.37 18 Félicie Laurent France F W 20-29 0:13:13 98.28 19 Jules Voirin France M W 20-29 0:13:15 98.18 20 Elisabeth Chirenine France F W 19&U 0:13:17 98.09 21 Siméon Laurent France M W 20-29 0:13:20 97.99 22 Sarah Devaux France F W 19&U 0:13:20 97.90 23 Ines Vitrac Garcia France F W 19&U 0:13:23 97.80 24 Tara Cotti France F W 19&U 0:13:27 97.71 25 Florian Bochaton France M W 20-29 0:13:29 97.61 26 Victor Darras France M W 20-29 0:13:33 97.51 27 Cédric Descombes France M W 19&U 0:13:34 97.42 28 Jean-Luc Mallard France M W 50-59 0:13:40 97.32 -

Mountain Bike Ranking - Men
Mountain Bike ranking - Men Rank Rider UCIID NAT Age Total 1 SCHURTER Nino 10004151580 SUI 34 2517 2 AVANCINI Henrique 10005558383 BRA 31 2315 3 FLUECKIGER Mathias 10003344258 SUI 32 1872 4 KERSCHBAUMER Gerhard 10006446137 ITA 29 1871 5 SARROU Jordan 10006804431 FRA 28 1821 6 CINK Ondrej 10006456342 CZE 30 1555 7 VADER Milan 10008833347 NED 24 1504 8 TEMPIER Stephane 10004229382 FRA 34 1442 9 CAROD Titouan 10007705218 FRA 26 1434 10 KORETZKY Victor 10007624382 FRA 26 1424 11 MAROTTE Maxime 10003393566 FRA 34 1383 12 BRAIDOT Luca 10006120074 ITA 29 1375 13 VAN DER POEL Mathieu 10007946203 NED 25 1344 14 DASCALU Vlad 10010129006 ROU 23 1266 15 BRANDL Maximilian 10009586513 GER 23 1215 16 HATHERLY Alan 10008833751 RSA 24 1213 17 COLOMBO Filippo 10009586210 SUI 23 1212 18 VALERO SERRANO David 10008594281 ESP 32 1194 18 FORSTER Lars 10006915070 SUI 27 1194 20 BOUCHARD Leandre 10090960318 CAN 28 1158 21 SWENSON Keegan 10007709157 USA 26 1096 22 ULLOA AREVALO Jose Gerardo 10008865881 MEX 24 1088 23 STIRNEMANN Matthias 10006453312 SUI 29 1070 24 COOPER Anton 10007693191 NZL 26 1049 25 BRAIDOT Daniele 10006444723 ITA 29 1044 26 GRIOT Thomas 10008081801 FRA 26 1043 27 ANDREASSEN Simon 10009436363 DEN 23 1042 28 WAWAK Bartlomiej 10007312366 POL 27 1033 29 FINI CARSTENSEN Sebastian 10008129590 DEN 25 1020 30 FUMIC Manuel 10002455700 GER 38 1004 31 FRISCHKNECHT Andri 10007591747 SUI 26 1003 32 MCCONNELL Daniel 10075237628 AUS 35 979 33 SINTSOV Anton 10002843292 RUS 35 977 34 COLLEDANI Nadir 10007946001 ITA 25 965 35 HARING Martin 10005540195 SVK 34 -
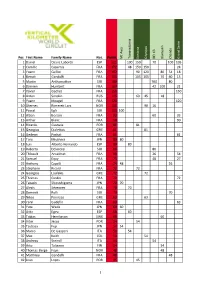
Full Ranking
Pos First Name Family Name Nat. Points Mt Awa Transvulcania Santana Olympus K3 BEI Blamann Chando Serre Grand 1 Daniel Osanz Laborda ESP 525 100 150 70 100 105 2 Camille Caparros FRA 372 48 150 150 24 3 Yoann Caillot FRA 362 90 120 80 54 18 4 Benoit Gandolfi FRA 355 105 105 70 60 15 5 Martin Anthamatten SUI 180 100 80 6 Damien Humbert FRA 163 42 100 21 7 Xavier Gachet FRA 150 150 8 Anton Sorokin RUS 126 63 45 18 9 Yoann Mougel FRA 120 120 10 Åkernes Rimereit Lars NOR 106 90 16 11 Pascal Egli SUI 100 100 12 Alban Berson FRA 93 60 33 13 Arthur Blanc FRA 90 90 14 Ricardo Gouveia POR 81 81 15 Georgios Dialektos GRE 81 81 16 Gedeon Pochat FRA 81 81 17 Toru Miyahara JPN 80 80 18 Luis Alberto Hernando ESP 80 80 19 Roberto Delorenzi SUI 80 80 20 Thibault Anselmet FRA 80 26 54 21 Samuel Equy FRA 75 48 27 22 Anthony Capelli FRA 74 48 26 23 Stephane Ricard FRA 72 72 24 Georgios Loufekis GRE 72 72 25 Thomas Cardin FRA 72 72 26 Takashi Shinushigome JPN 70 70 27 Alexis Sévennec FRA 70 70 28 Dominik Rolli SUI 70 70 29 Nikos Ponireas GRE 63 63 30 Yann Gudefin FRA 63 63 31 Yota Wada JPN 60 60 32 Aritz Egea ESP 60 60 33 Tobias Henriksson SWE 60 60 34 Vitor Jesus POR 54 54 35 Tsubasa Fuji JPN 54 54 36 Marco De Gasperi ITA 54 54 37 Max Keith COL 54 54 38 Andreas Steindl ITA 54 54 39 Arto Talvinen FIN 54 54 40 Thomas Berge Foyn NOR 48 48 41 Matthieu Gandolfi FRA 48 48 42 Joao Lopes POR 45 45 1 43 Adrien Perret FRA 45 45 44 Toshiharu Obata JPN 42 42 45 Morgan Elliott USA 42 42 46 Maximilian Bie NOR 42 42 47 Mattia Roncoroni ITA 42 42 48 Américo Caldeira POR