Web Application Obfuscation This Page Intentionally Left Blank Web Application Obfuscation ‘-/Wafs..Evasion..Filters//Alert (/Obfuscation/)-’
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Microsoft's Internet Exploration: Predatory Or Competitive?
Cornell Journal of Law and Public Policy Volume 9 Article 3 Issue 1 Fall 1999 Microsoft’s Internet Exploration: Predatory or Competitive Thomas W. Hazlett Follow this and additional works at: http://scholarship.law.cornell.edu/cjlpp Part of the Law Commons Recommended Citation Hazlett, Thomas W. (1999) "Microsoft’s Internet Exploration: Predatory or Competitive," Cornell Journal of Law and Public Policy: Vol. 9: Iss. 1, Article 3. Available at: http://scholarship.law.cornell.edu/cjlpp/vol9/iss1/3 This Article is brought to you for free and open access by the Journals at Scholarship@Cornell Law: A Digital Repository. It has been accepted for inclusion in Cornell Journal of Law and Public Policy by an authorized administrator of Scholarship@Cornell Law: A Digital Repository. For more information, please contact [email protected]. MICROSOFT'S INTERNET EXPLORATION: PREDATORY OR COMPETITIVE? Thomas W. Hazlettt In May 1998 the U.S. Department of Justice ("DOJ") accused Microsoft of violatirig the Sherman Antitrust Act by vigorously compet- ing against Netscape's Navigator software with Microsoft's rival browser, Internet Explorer. The substance of the allegation revolves around defensive actions taken by Microsoft to protect the dominant po- sition enjoyed by Microsoft's Windows operating system. The DOJ's theory is that, were it not for Microsoft's overly aggressive reaction to Netscape, Navigator software would have been more broadly distributed, thus enabling competition to Windows. This competition would have come directly from Java, a computer language developed by Sun Microsystems and embedded in Netscape software, allowing applications to run on any underlying operating system. -

Free Software an Introduction
Free Software an Introduction By Steve Riddett using Scribus 1.3.3.12 and Ubuntu 8.10 Contents Famous Free Software...................................................... 2 The Difference.................................................................. 3 Stallman and Torvalds.......................................................4 The Meaning of Distro......................................................5 Linux and the Holy Grail.................................................. 6 Frequently Asked Questions............................................. 7 Where to find out more.....................................................8 2 Free Software - an Introduction Famous Free Software Firefox is a web browser similar to Microsoft's Internet Explorer but made the Free software way. The project started in 2003 from the source code of the Netscape browser which had been released when Netscape went bust. In April 2009, Firefox recorded 29% use worldwide (34% in Europe). Firefox is standards compliant and has a system of add-ons which allow innovative new features to be added by the community. OpenOffice.org is an office suite similar to Microsoft Office. It started life as Star Office. Sun Microsystems realised it was cheaper to buy out Star Office than to pay Microsoft for licence fees for MS Office. Sun then released the source code for Star Office under the name OpenOffice.org. OpenOffice.org is mostly compatible with MS Office file formats, which allows users to open .docs and .xls files in Open Office. Microsoft is working on a plug-in for MS Office that allows it to open .odf files. ODF (Open Document Format) is Open Office's default file format. Once this plug-in is complete there will 100% compatiblity between the two office suites. VLC is the VideoLAN Client. It was originally designed to allow you to watch video over the network. -
World Wide Web: Introduzione E Componenti
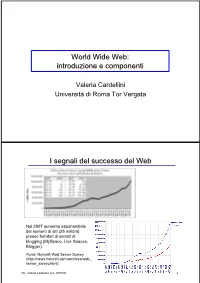
World Wide Web: introduzione e componenti Valeria Cardellini Università di Roma Tor Vergata I segnali del successo del Web Nel 2007 aumento esponenziale del numero di siti (25 milioni) presso fornitori di servizi di blogging (MySpace, Live Spaces, Blogger) Fonte: Netcraft Web Server Survey (http://news.netcraft.com/archives/web_ server_survey.html) IW - Valeria Cardellini, A.A. 2007/08 2 I segnali del successo del Web (2) • Fino all’introduzione dei sistemi P2P, il Web è stata l’applicazione killer di Internet (75% del traffico di Internet nel 1998) Event Period Peak day Peak minute NCSA server (Oct. 1995) - 2 Million - Olympic Summer Games 192 Million 8 Million - (Aug. 1996) (17 days) Nasa Pathfinder 942 Million 40 Million - (July 1997) (14 days) Olympic Winter Games 634.7 Million 55 Million 110,000 (Feb. 1998) (16 days) Wimbledon (July 1998) - - 145,000 FIFA World Cup 1,350 Million 73 Million 209,000 (July 1998) (84 days) Wimbledon (July 1999) - 125 Million 430,000 Wimbledon (July 2000) - 282 Million 964,000 Olympic Summer Games - 875 Million 1,200,000 (Sept. 2000) [Carico misurato in contatti] • Inoltre: google.com, msn.com, yahoo.com (> 200 milioni di contatti al giorno) IW - Valeria Cardellini, A.A. 2007/08 3 I motivi alla base del successo del Web • Digitalizzazione dell’informazione – Qualsiasi informazione rappresentabile in binario come sequenza di 0 e 1 • Diffusione di Internet (dagli anni 1970) – Trasporto dell’informazione ovunque, in tempi rapidissimi e a costi bassissimi • Diffusione dei PC (dagli anni 1980) – Accesso, memorizzazione ed elaborazione dell’informazione da parte di chiunque a costi bassissimi • Semplicità di utilizzo e trasparenza dell’allocazione delle risorse – Semplicità di utilizzo mediante l’uso di interfacce grafiche IW - Valeria Cardellini, A.A. -

Technical Description of Using Multiple Browsers in Denton
Technical Description of Using Multiple Browsers In Denton ISD By Garrett Chandler The global IT industry, as a whole, is in an interesting transition period. There are a variety of variables that play into why users, both consumers and enterprises alike, must use a number of different web browsers on their computer. In order to understand why we are experiencing these issues today, it’s important to look at three things: where the IT industry once was and where it’s going, the current trends of web developers, and finally, how Denton ISD utilizes certain services such as Eduphoria, and TAC. Please bear with me as things may get slightly technical. HTML 5 is code for designing web pages on the Internet. HTML5 has grown tremendously over the past few years and is quickly becoming the code of choice for web developers. Eventually, trends suggest, that HTML 5 will be the standard code across the web, as designated by the World Wide Web Consortium (W3C). However, this adoption is entirely up to the web developers and how it meets their requirements in the services they provide, their business goals, and marketing strategies. HTML 4.01 is the current standard by W3C, which has been the standard since 1999. Aside from HTML, as the web has grown from its adolescence, it has learned new languages in the form of other types of code, especially as technology as a whole progresses. For years Internet Explorer was the most common web browser on PC’s as Microsoft dominated the enterprise market. However, with the imminent demise of Microsoft Windows XP on the horizon, other companies like Google and Mozilla have seized the opportunity to own the web. -

MHCC Accessibility Conformance Report
Mt. Hood Community College Website Accessibility Conformance Report WCAG Edition VPAT® Version 2.3 (Revised) – April 2019 Name of Product/Version: www.mhcc.edu Product Description: MHCC Main Website Report Date: August 2, 2019 Contact Information: Tristan Price – [email protected] Notes: Evaluation Methods Used: IAAP WAS Testing Methodology, SiteImprove, Manual Testing __________________________________ “Voluntary Product Accessibility Template” and “VPAT” are registered service marks of the Information Technology Industry Council (ITI) Page 1 of 5 Applicable Standards/Guidelines This report covers the degree of conformance for the following accessibility standard/guidelines: Standard/Guideline Included In Report Web Content Accessibility Guidelines 2.0 Level A (Yes / No ) Level AA (Yes / No ) Level AAA (Yes / No ) Web Content Accessibility Guidelines 2.1 Level A (Yes / No ) Level AA (Yes / No ) Level AAA (Yes / No ) Terms The terms used in the Conformance Level information are defined as follows: • Supports: The functionality of the product has at least one method that meets the criterion without known defects or meets with equivalent facilitation. • Partially Supports: Some functionality of the product does not meet the criterion. • Does Not Support: The majority of product functionality does not meet the criterion. • Not Applicable: The criterion is not relevant to the product. • Not Evaluated: The product has not been evaluated against the criterion. This can be used only in WCAG 2.0 Level AAA. WCAG 2.x Report Note: When reporting on conformance with the WCAG 2.x Success Criteria, they are scoped for full pages, complete processes, and accessibility-supported ways of using technology as documented in the WCAG 2.0 Conformance Requirements. -

Bypassing Web Application Firewalls
Bypassing Web Application Firewalls Pavol Lupták [email protected] CEO, Nethemba s.r.o Abstract The goal of the presentation is to describe typical obfuscation attacks that allow an attacker to bypass standard security measures such as various input filters, output encoding mechanisms used in web-based intrusion detection systems (IDS), intrusion prevention systems (IPS) and web application firewalls (WAFs). These attacks may include different networking tricks, polymorphic shellcode and various code techniques. At the beginning we analyse and compare different HTML parsing and interpretation approaches used by most-common browsers that can lead to unique attack vectors. Javascript, with a full range of features, represents another effective way that can be used to obfuscate or de-obfuscate code – some existing obfuscation tools are mentioned. We describe how it is possible to construct “non-alphanumeric Javascript code” which does not contain alphabetic or numeric characters, but still can contain malicious executable code. Despite the fact that most current applications are immune to SQL injection attacks, it is still possible to find many vulnerable applications. We focus on different fuzzy techniques (and useful open source SQL injection tools that implement them) which can still be used to bypass weak input validation controls. We conclude our presentation with a demonstration of the most basic obfuscation techniques that can be successfully used to bypass traditional web application firewalls (WAFs). Finally, we briefly describe current mitigation techniques that are recommended for efficient malicious Javascript code analysis and sanitizing user input containing untrusted code. Keywords: WAF, IPS, IDS, obfuscation, SQL injection, XSS, CSS, CSRF. -

Comodo System Cleaner Version 3.0
Comodo System Cleaner Version 3.0 User Guide Version 3.0.122010 Versi Comodo Security Solutions 525 Washington Blvd. Jersey City, NJ 07310 Comodo System Cleaner - User Guide Table of Contents 1.Comodo System-Cleaner - Introduction ............................................................................................................ 3 1.1.System Requirements...........................................................................................................................................5 1.2.Installing Comodo System-Cleaner........................................................................................................................5 1.3.Starting Comodo System-Cleaner..........................................................................................................................9 1.4.The Main Interface...............................................................................................................................................9 1.5.The Summary Area.............................................................................................................................................11 1.6.Understanding Profiles.......................................................................................................................................12 2.Registry Cleaner............................................................................................................................................. 15 2.1.Clean.................................................................................................................................................................16 -
Opera Software the Best Browsing Experience on Any Device
Opera Software The best browsing experience on any device The best Internet experience on any device Web Standards for the Future – Bruce Lawson, Opera.com • Web Evangelist, Opera • Tech lead, Law Society & Solicitors Regulation Authority (2004-8) • Author 2 books on Web Standards, edited 2 • Committee member for British Standards Institution (BSI) for the new standard for accessible websites • Member of Web Standards Project: Accessibility Task Force • Member of W3C Mobile Best Practices Working Group Web Standards for the Future – Bruce Lawson, Opera.com B.A., Honours English Literature and Language with Drama Theresa is blind But she can use the Web if made with standards The big picture WWW The big picture Western Western Web A web (pre)history • 1989 TBL proposes a project • 1992 <img> in Mosaic beta. Now 99.57% (MAMA) • 1994 W3C started at MIT • 1996 The Browser Wars • 1999 WAP, Web Content Accessibility Guidelines (WCAG) • 2000 Flash Modern web history • 2000-ish .com Crash - Time to grow up... • 2002 Opera Mobile with Small Screen Rendering • 2005 WHAT-WG founded, W3C Mobile Web Initiative starts • 2007 W3C adopts WHAT-WG spec as basis for HTML 5 • January 22, 2008 First public working draft of HTML 5 Standards at Opera • 25 employees work on standards • Mostly at W3C - a big player • Working on many standards • Bringing new work to W3C • Implementing Standards properly (us and you!) (Web Standards Curriculum www.opera.com/wsc) Why standards? The Web works everywhere - The Web is the platform • Good standards help developers: validate; separate content and presentation - means specialisation and maintainability. -

Coursphp.Pdf
PHP 5 POEC – PHP 2017 1 Qu'est-ce que PHP ? PHP (PHP Hypertext PreProcessor) est un langage de programmation. Il s’agit d’un langage interprété et indépendant de la plate-forme d'exécution. Il permet de générer des pages HTML dynamiques. Il s’avère utile pour utiliser de ressources serveurs comme des bases de données. Une large communauté d’utilisateurs PHP existe. De nombreuses documentations et ressources sont disponibles. 2 Licence de PHP ? PHP est distribué via une licence propre qui permet sa rediffusion, son utilisation, sa modification. PHP est distribué librement et gratuitement. 3 Que faire avec PHP ? Des sites Web La partie serveur de tout type d’application : Application Web Application mobile Applications utilisables en ligne de commande (scripting) 4 Quelques technologies concurrentes à PHP • JSP : Java-Server Pages • Technologie de Sun • Semblable à PHP mais la partie dynamique est écrite en Java • ASP.Net: Active Server Pages • Produit de Microsoft • Contenu dynamique pouvant être écrit dans tous les langages de la plateforme .Net (les plus utilisés étant le C# et le VB.Net) • Le choix entre PHP, JSP et ASP.Net est plus "politique" que technique. 5 Intérêts d’utiliser PHP • Très populaire et très utilisé – Utilisé par des sites internet à très fort trafic tels Yahoo ou Facebook • Amène un certain nombre de personnes à améliorer le langage – Simplifie l’accès à de la documentation • Syntaxe simple à prendre en main (héritée du C, du Shell et du Perl) • Très portable (fonctionne sous Windows, Linux, Mac…) • -

SA4VBE08KN/12 Philips MP4 Player with Fullsound™
Philips GoGEAR MP4 player with FullSound™ Vibe 8GB* SA4VBE08KN Feel the vibes of sensational sound Small, colorful and entertaining The colored Philips GoGEAR Vibe MP4 player SA4VBE08KN comes with FullSound to bring music and videos to life, and Songbird to synchronize music and enjoy entertainment. SafeSound protects your ears and FastCharge offers quick charging. Superb quality sound • Fullsound™ to bring your MP3 music to life • SafeSound for maximum music enjoyment without hearing damage Complements your life • 4.6 cm/1.8" full color screen for easy, intuitive browsing • Soft and smooth finish for easy comfort and handling • Enjoy up to 20 hours of music or 4 hours of video playback Easy and intuitive • Philips Songbird: one simple program to discover, play, sync • LikeMusic for playlists of songs that sound great together • Quick 5-minute charge for 90 minutes of play • Folder view to organize and view media files like on your PC MP4 player with FullSound™ SA4VBE08KN/12 Vibe 8GB* Highlights FullSound™ level or allow SafeSound to automatically Philips Songbird regulate the volume for you – no need to fiddle with any settings. In addition, SafeSound provides daily and weekly overviews of your sound exposure so you can take better charge of your hearing health. 4.6 cm/1.8" full color screen Philips' innovative FullSound technology One simple, easy-to-use program that comes faithfully restores sonic details to compressed with your GoGear player, Philips Songbird lets MP3 music, dramatically enriching and you discover and play all your media, and sync enhancing it, so you can experience CD music it seamlessly with your Philips GoGear. -

HTTP Cookie - Wikipedia, the Free Encyclopedia 14/05/2014
HTTP cookie - Wikipedia, the free encyclopedia 14/05/2014 Create account Log in Article Talk Read Edit View history Search HTTP cookie From Wikipedia, the free encyclopedia Navigation A cookie, also known as an HTTP cookie, web cookie, or browser HTTP Main page cookie, is a small piece of data sent from a website and stored in a Persistence · Compression · HTTPS · Contents user's web browser while the user is browsing that website. Every time Request methods Featured content the user loads the website, the browser sends the cookie back to the OPTIONS · GET · HEAD · POST · PUT · Current events server to notify the website of the user's previous activity.[1] Cookies DELETE · TRACE · CONNECT · PATCH · Random article Donate to Wikipedia were designed to be a reliable mechanism for websites to remember Header fields Wikimedia Shop stateful information (such as items in a shopping cart) or to record the Cookie · ETag · Location · HTTP referer · DNT user's browsing activity (including clicking particular buttons, logging in, · X-Forwarded-For · Interaction or recording which pages were visited by the user as far back as months Status codes or years ago). 301 Moved Permanently · 302 Found · Help 303 See Other · 403 Forbidden · About Wikipedia Although cookies cannot carry viruses, and cannot install malware on 404 Not Found · [2] Community portal the host computer, tracking cookies and especially third-party v · t · e · Recent changes tracking cookies are commonly used as ways to compile long-term Contact page records of individuals' browsing histories—a potential privacy concern that prompted European[3] and U.S. -

C++11 Metaprogramming Applied to Software Obfuscation
C++11 METAPROGRAMMING APPLIED TO SOFTWARE OBFUSCATION SEBASTIEN ANDRIVET About me ! Senior Security Engineer at SCRT (Swiss) ! CTO at ADVTOOLS (Swiss) Sebastien ANDRIVET Cyberfeminist & hacktivist Reverse engineer Intel & ARM C++, C, Obj-C, C# developer Trainer (iOS & Android appsec) PROBLEM Reverse engineering • Reverse engineering of an application if often like following the “white rabbit” • i.e. following string literals • Live demo • Reverse engineering of an application using IDA • Well-known MDM (Mobile Device Management) for iOS A SOLUTION OBFUSCATION What is Obfuscation? Obfuscator O O ( ) = YES! It is also Katy Perry! • (almost) same semantics • obfuscated Obfuscation “Deliberate act of creating source or machine code difficult for humans to understand” – WIKIPEDIA, APRIL 2014 C++ templates OBJECT2 • Example: Stack of objects OBJECT1 • Push • Pop Without templates Stack singers; class Stack { singers.push(britney); void push(void* object); void* pop(); }; Stack apples; apples.push(macintosh); • Reuse the same code (binary) singers apples • Only 1 instance of Stack class With C++ templates template<typename T > Stack<Singer> singers; class Stack singers.push(britney); { void push(T object); T pop(); Stack<Apple> apples; }; apples.push(macintosh); With C++ templates Stack<Singer> singers; singers.push(britney); Stack<Singers> Stack<Apples*> Stack<Apple> apples; apples.push(macintosh); singers apples C++ templates • Two instances of Stack class • One per type • Does not reuse code • By default • Permit optimisations based on types • For ex. reuse code for all pointers to objects • Type safety, verified at compile time Type safety • singers.push(apple); // compilation error Optimisation based on types • Generate different code based on types (template parameters) template<typename T> class MyClass • Example: enable_if { ..