Motion Pattern Recognition for Interactive Dance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Evaluation of the CSF Firewall
Bachelor Thesis in Software Engineering, 15 credits May 2013 Evaluation of the CSF Firewall Ahmad Mudhar Contact Information: Ahmad Mudhar E-mail: [email protected] University advisor: Kari Rönkkö Nina Fogelström School of Computing Internet : www.bth.se/com Blekinge Institute of Technology Phone : +46 455 38 50 00 SE-371 79 Karlskrona Fax : +46 455 38 50 57 Sweden 1 Abstract The subject of web server security is vast, and it is becoming bigger as time passes by. Every year, researches, both private and public, are adding to the number of possible threats to the security of web servers, and coming up with possible solutions to them. A number of these solutions are considered to be expensive, complex, and incredibly time-consuming, while not able to create the perfect web to challenge any breach to the server security. In the study that follows, an attempt will be made to check whether a particular firewall can ensure a strong security measure and deal with some security breaches or severe threat to an existing web server. The research conducted has been done with the CSF Firewall, which provides a suit of scripts that ensure a portal’s security through a number of channels. The experiments conducted under the research provided extremely valuable insights about the application in hand, and the number of ways the CSF Firewall can help in safety of a portal against Secured Shell (SSH) attacks, dedicated to break the security of it, in its initial stages. It further goes to show how simple it is to actually detect the prospective attacks, and subsequently stop the Denial of Service (DoS) attacks, as well as the port scans made to the server, with the intent of breaching the security, by finding out an open port. -

Kosten Senken Dank Open Source?
View metadata, citation and similar papers at core.ac.uk brought to you by CORE Kosten senken dank Open Source? provided by Bern Open Repository andStrategien Information System (BORIS) | downloaded: 13.3.2017 https://doi.org/10.7892/boris.47380 source: 36 Nr. 01/02 | Februar 2014 Swiss IT Magazine Strategien Kosten senken dank Open Source? Mehr Geld im Portemonnaie und weniger Sorgen im Gepäck Der Einsatz von Open Source Software kann das IT-Budget schonen, wenn man richtig vorgeht. Viel wichtiger sind aber strategische Vorteile wie die digitale Nachhaltigkeit oder die Unabhängigkeit von Herstellern, die sich durch den konsequenten Einsatz von Open Source ergeben. V ON D R . M ATTHIAS S TÜR M ER ines vorweg: Open Source ist nicht gra- tis. Oder korrekt ausgedrückt: Der Download von Open Source Software (OSS) von den vielen Internet-Portalen wieE Github, Google Code, Sourceforge oder Freecode ist selbstverständlich kostenlos. Aber wenn Open-Source-Lösungen professionell eingeführt und betrieben werden, verursacht dies interne und/oder externe Kosten. Geschäftskritische Lösungen benötigen stets zuverlässige Wartung und Support, ansonsten steigt das Risiko erheblich, dass zentrale Infor- matiksysteme ausfallen oder wichtige Daten verloren gehen oder gestohlen werden. Für den sicheren Einsatz von Open Source Soft- ware braucht es deshalb entweder interne INHALT Ressourcen und Know-how, wie die entspre- chenden Systeme betrieben werden. Oder es MEHR GELD im PORTemoNNaie UND weNIGER SorgeN im GEPÄck 36 wird ein Service Level Agreement (SLA) bei- MarkTÜbersicHT: 152 SCHweiZer OPEN-SOUrce-SPEZialisTEN 40 spielsweise in Form einer Subscription mit einem kommerziellen Anbieter von Open- SpareN ODER NICHT spareN 48 Source-Lösungen abgeschlossen. -

Databits: an Electronic Newsletter for Information Managers
DataBits: An electronic newsletter for Information Managers Wade Sheldon (GCE) and Margaret O’Brien (SBC), co-editors Spring 2008 Issue Table of Contents Feature Articles The FCE LTER Website has a NEW look! - Linda Powell ......................................................1 Developing a Searchable Document and Imagery Archive for the GCE-LTER Web Site - Wade Sheldon....................................................................................................................5 Improving the Basic Keyword Search for Datasets by Employing Text Mining Techniques and Indexing - Hung V. Nguyen, Corinna Gries, Hasan Davulcu ..................9 Developing and Using APIs in System Design - James Connors, Mason Kortz ....................12 FinLTSER Network: New addition to the global LTER network - Helena Karasti ..............14 Commentary Using Xen and VMWare to Manage Virtual Machines: A New User’s Saga - John H. Porter.................................................................................................................18 Making Sense of Collaboration Software - James W Brunt....................................................20 Big Science and Local Meetings - Karen Baker, Sabine Grabner..........................................23 Preservation Metadata: Another Chapter in the Metadata Story - Lynn Yarmey ....................25 Data Quality: Yet Another Chapter in the Metadata Story - Lynn Yarmey.............................27 Good Tools and Programs Specifik, a Taxonomic Reference Tool to Support Synthesis of Vegetation -

Neural Network FAQ, Part 1 of 7: Introduction
Neural Network FAQ, part 1 of 7: Introduction Archive-name: ai-faq/neural-nets/part1 Last-modified: 2002-05-17 URL: ftp://ftp.sas.com/pub/neural/FAQ.html Maintainer: [email protected] (Warren S. Sarle) Copyright 1997, 1998, 1999, 2000, 2001, 2002 by Warren S. Sarle, Cary, NC, USA. --------------------------------------------------------------- Additions, corrections, or improvements are always welcome. Anybody who is willing to contribute any information, please email me; if it is relevant, I will incorporate it. The monthly posting departs around the 28th of every month. --------------------------------------------------------------- This is the first of seven parts of a monthly posting to the Usenet newsgroup comp.ai.neural-nets (as well as comp.answers and news.answers, where it should be findable at any time). Its purpose is to provide basic information for individuals who are new to the field of neural networks or who are just beginning to read this group. It will help to avoid lengthy discussion of questions that often arise for beginners. SO, PLEASE, SEARCH THIS POSTING FIRST IF YOU HAVE A QUESTION and DON'T POST ANSWERS TO FAQs: POINT THE ASKER TO THIS POSTING The latest version of the FAQ is available as a hypertext document, readable by any WWW (World Wide Web) browser such as Netscape, under the URL: ftp://ftp.sas.com/pub/neural/FAQ.html. If you are reading the version of the FAQ posted in comp.ai.neural-nets, be sure to view it with a monospace font such as Courier. If you view it with a proportional font, tables and formulas will be mangled. -

Virtual Organization Clusters: Self-Provisioned Clouds on the Grid Michael Murphy Clemson University, [email protected]
Clemson University TigerPrints All Dissertations Dissertations 5-2010 Virtual Organization Clusters: Self-Provisioned Clouds on the Grid Michael Murphy Clemson University, [email protected] Follow this and additional works at: https://tigerprints.clemson.edu/all_dissertations Part of the Computer Sciences Commons Recommended Citation Murphy, Michael, "Virtual Organization Clusters: Self-Provisioned Clouds on the Grid" (2010). All Dissertations. 511. https://tigerprints.clemson.edu/all_dissertations/511 This Dissertation is brought to you for free and open access by the Dissertations at TigerPrints. It has been accepted for inclusion in All Dissertations by an authorized administrator of TigerPrints. For more information, please contact [email protected]. Virtual Organization Clusters: Self-Provisioned Clouds on the Grid A Dissertation Presented to the Graduate School of Clemson University In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy Computer Science by Michael A. Murphy May 2010 Accepted by: Dr. Sebastien Goasguen, Committee Chair Dr. Jim Martin Dr. Walt Ligon Dr. Robert Geist Abstract Virtual Organization Clusters (VOCs) provide a novel architecture for overlaying dedicated cluster systems on existing grid infrastructures. VOCs provide customized, homogeneous execution environments on a per-Virtual Organization basis, without the cost of physical cluster construction or the overhead of per-job containers. Administrative access and overlay network capabilities are granted to Virtual Organizations (VOs) that choose to implement VOC technology, while the system remains completely transparent to end users and non-participating VOs. Unlike alternative systems that require explicit leases, VOCs are autonomically self-provisioned according to configurable usage policies. As a grid computing architecture, VOCs are designed to be technology agnostic and are implementable by any combination of software and services that follows the Virtual Organization Cluster Model. -

Comparing User Experiences in Using Twiki & Mediawiki To
Liang, M., Chu, S., Siu, F., & Zhou, A. (2009). Comparing User Experiences in Using Twiki & Mediawiki to Facilitate Collaborative Learning. Proceedings of the 2009 International Conference on Knowledge Management [CD-ROM]. Hong Kong, Dec 3-4, 2009. COMPARING USER EXPERIENCES IN USING TWIKI & MEDIAWIKI TO FACILITATE COLLABORATIVE LEARNING MICHAEL LIANG* IT and Management Consulting Division, WiderWorld Company Ltd. [email protected] † SAM CHU , FELIX SIU and AUDREY ZHOU Faculty of Education, the University of Hong Kong † [email protected] This research seeks to determine the perceived effectiveness of using TWiki and MediaWiki in collaborative work and knowledge management; and to compare the use of TWiki and MediaWiki in terms of user experiences in the master’s level of study at the University of Hong Kong. Through a multiple case study approach, the study adopted a mixed methods research design which used both quantitative and qualitative methods to analyze findings from specific user groups in two study programmes. In the study, both wiki platforms were regarded as suitable tools for group work co-construction, which were found to be effective in improving group collaboration and work quality. Wikis were also viewed as enabling tools for knowledge management. MediaWiki was rated more favorably than TWiki, especially in the ease of use and enjoyment experienced. The paper should be of interest to educators who may want to explore wiki as a platform to enhance students’ collaborative group work. 1. Introduction Rote learning, which focuses on the direct transmission of knowledge from teachers to students using a traditional didactic approach, is the prevalent norm in education in many countries (Jang, 2007). -

Tutorial: Wikis in the Workplace" for Wiki Symposium, Montreal, Canada, 22 Oct 2007
This is the presentation material for the 3 hour session on "Tutorial: Wikis in the Workplace" for Wiki Symposium, Montreal, Canada, 22 Oct 2007. Slide 1: Tutorial: Wikis in the Workplace "Wikis have changed the way we run meetings, plan releases, document our product and generally communicate with each other" - Eric Baldeschwieler, Director of Software Development of Yahoo! • Wiki, a writable web: Communities can share content and organize it in a way most meaningful and useful to them • If extended with the right set of functionality, a wiki can be applied to the workplace to schedule, manage, document, and support daily activities • A structured wiki combines the benefits of a wiki and a database • This tutorial explains publishing wikis and structured wiki, covers its deployment, and shows some sample applications using TWiki, an open source enterprise wiki platform Presentation for Wiki Symposium, Montreal, Canada, 22 Oct 2007 -- Peter Thoeny - [email protected] - TWIKI.NET Slide 2: About Peter • Peter Thoeny - [email protected] • Founder of TWiki, the leading wiki for corporate collaboration, managing the open-sourced project for the last 9 years • Co-founder of TWIKI.NET , a company offering services and support for TWiki • Co-author of Wikis for Dummies book • Invented the concept of Structured Wikis - where free form wiki content can be structured with tailored wiki applications • Recognized thought-leader in Wikis and social software, featured in numerous articles and technology conferences including -
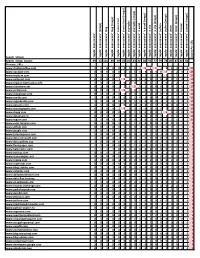
Regular Expressions Search String Counts
"regular expressions" (image) "regular expressions" blog"regular expressions" blog"regular (image) expressions" cheat"regular sheet expressions" cheat"regular sheet (image) expressions" examples "regular expressions" examples"regular (image) expressions" in "regular excel expressions" in (image) "regular excel expressions" in "regular vba expressions" in "regular vba (image) expressions" python"regular expressions" python"regular (image) expressions" tester"regular expressions" tester "regular (image) expressions" tutorial"regular expressions" tutorial"regular (image) Counts URL Per Search_Strings expressions""regular Search_String_Counts 99 91 101 89 99 85 ## 85 ## 80 96 77 99 78 ## 87 ## 86 Primary_URLs www.stackoverflow.com 1 1 0 0 0 0 1 1 1 6 1 5 1 2 1 3 1 0 25 www.youtube.com 0 3 0 0 0 1 0 3 0 3 0 4 0 5 0 2 0 4 25 www.medium.com 1 1 1 0 1 1 1 2 1 1 1 1 1 2 1 1 1 3 21 www.pinterest.com 0 0 0 0 1 9 0 1 0 0 0 1 0 4 0 1 0 2 19 www.regular-expressions.info 1 3 1 0 1 0 2 0 1 0 1 1 1 0 2 2 1 1 18 www.slideshare.net 0 1 0 0 1 2 0 5 0 1 0 0 0 3 0 2 0 2 17 www.scribd.com 0 0 0 2 1 8 0 0 0 0 0 1 0 2 0 0 0 1 15 www.slideplayer.com 0 1 0 1 0 1 0 4 0 1 0 0 0 3 0 2 0 2 15 www.oreilly.com 1 1 0 0 0 0 1 1 0 1 0 0 1 1 1 1 1 1 11 www.regexbuddy.com 1 3 0 0 0 0 0 1 0 0 0 0 1 1 1 2 1 0 11 www.amazon.com 1 1 0 0 1 0 0 0 1 0 1 1 1 0 0 0 1 2 10 www.cheatography.com 0 1 0 0 1 6 0 0 0 0 0 1 0 1 0 0 0 0 10 www.chegg.com 0 0 0 0 0 0 0 1 0 0 0 0 1 6 0 0 0 2 10 www.dataquest.io 0 1 1 1 1 1 0 0 1 0 0 0 1 1 1 0 1 0 10 www.regexr.com 1 1 0 0 1 1 0 0 1 0 1 0 0 0 -

Foswiki Xwiki
Foswiki & XWiki News IT-CDA project Documentation Project Documentation Project Meeting 15-June-2020 Project Status Report Peter Jones IT-CDA 2 Overview • Documentation with wikis • Wiki options • Configurations of the applications • Basic look, structure and functionality • Editing options • Look & Feel • Navigation and Search 3 Documentation with Wikis Advantages: • Easy for anyone to enter content in the browser • Updates of documents are seen immediately • WYSIWYG and text editors (for markup, markdown, HTML) available • Automatic organization of documents • Documents are grouped and have a hierarchy (indexes, lists, trees, changes) • Colleagues files and their changes are visible to all with access rights • Notifications available • Built in revision control • Access control on single or groups of documents • Import and Export (PDF, Office, HTML etc) • Possibility to create dynamic pages • Flexible look & feel depending on user, group or document • 100s of additional feature available (macros, charts, latex, real-time editing…) • Extendible – new features • Available anywhere with very fast response times Foswiki and XWiki can offer all of the above: • Which is best for documentation? • Which is the best for our current TWiki users? • Which is the best for our current SharePoint users? • Which is the best for IT environment and support? 4 Background of the Wikis TWiki – Used at CERN since 2003 • Heavily used for Documentation and as a Collaboration tool • Open source GPL - perl • Stable but little recent change Foswiki – A fork of -

Open Source Platforms - Content Management Systems (CMS)
Open Source Platforms - Content Management Systems (CMS) Γιάκας Αθανάσιος ΑΕΜ 531 Συστήματα Διαχείρισης Περιεχομένου ● Τα Συστήματα Διαχείρισης Περιεχομένου (ΣΔΠ, Content Management Systems, CMS) είναι διαδικτυακές εφαρμογές που επιτρέπουν την online τροποποίηση του περιεχομένου ενός δικτυακού τόπου. ● Οι διαχειριστές μέσω του διαδικτύου ενημερώνουν το περιεχόμενο στο ΣΔΠ, το οποίο είναι εγκατεστημένο σ' ένα διακομιστή. Οι αλλαγές αυτές γίνονται αυτόματα διαθέσιμες πάλι μέσω του διαδικτύου, σε όλους τους επισκέπτες και χρήστες του δικτυακού τόπου. Κατάλογος Συστημάτων Διαχείρισης Περιεχομένου Ανοιχτού Κώδικα ανά πλατφόρμα ● ASP.NET: DotNetNuke Community Edition , mojoPortal , Umbraco , N2 CMS , MvcCms ● JAVA: jAPS, OpenCms, Liferay, Dspace, Fedora, dotCMS, Nuxeo EP, Alfresco, Magnolia, Hippo, Calenco ● Perl: blosxom ,Bricolage , MojoMojo, Movable Type ,Twiki ,Scoop ,Slash ,WebGUI ● PHP: AdaptCMS Lite, Atutor, b2evolution, Bedita, BLOG:CMS, CivicSpace, CMS Made Simple, Concrete5, Dotclear, Drupal ,DynPG, eFront ,e107, Exponent CMS, eZ Publish, Frog CMS, Gamboo Web Suite, GCMS, ImpressCMS, Jaws, Joomla!, Habari, KnowledgeTree Document Management System, Lyceum,Mambo,Merlintalk, MiaCMS, Midgard CMS MODx, MySource Matrix (Squiz), Nucleus ,Opus,PHP-Fusion, PHP-Nuke, PHPSlash, phpWebSite,Pixie (CMS),RavenNuke CMS,SilverStripe,SPIP, TangoCMS, Textpattern,TikiWiki CMS/Groupware ,Tribiq CMS ,TYPO3 ,whCMS,WordPress,Website Baker, Xaraya, Zikula Κάποιοα από τα πιο δημοφιλή open source CMS ● Drupal ● Wordpress ● Joomla ● Textpattern ● Radiant CMS -

Undergraduate Research Report Samantha Wohlstadter 1 PHY4902
Undergraduate Research Report Samantha Wohlstadter 1 PHY4902: Undergraduate Research Research Report Samantha Wohlstadter Undergraduate Research Report Samantha Wohlstadter 2 Table of Contents Overview and Goals 4 CE and Nodes 5 NAS Maintenance 6 UPS Maintenance 10 Software 11 MySQL and Website . 11 Condor . 13 Root................................... 14 CMS Software . 14 Undergraduate Research Report Samantha Wohlstadter 3 List of Figures 1 The Cluster . .4 2 An example of the output of 'zpool status' . .6 3 An example of the output of tw cli, showing the hard drives that the RAID card can detect. .7 Undergraduate Research Report Samantha Wohlstadter 4 Overview and Goals The main goal of this project is to set up CMS software locally on the Cluster in order to simulate Mehdi's event samples. To accomplish this goal, the work was divided into multiple steps: • Ensure that the Cluster is functional, including the compute nodes, the Storage Element (SE), the Compute Element (CE), the NAS units, and the UPS units. • Reconfigure MySQL after installing the nodes, so that the website is accessible. • Set up Condor, the job submission software, to automatically run data between the different steps of the simulation process. • Install and set up the CMS simulation software, including Root. Before this project began, the cluster was still in the first step. The new CE had just been installed and set up, including: the ROCKS OS installation, the zpool for the OS drives, and most of the node integration. The remaining tasks to complete this step included verifying the node integration, though there was also ongoing general maintenance of the cluster such as hard drive and battery replacements. -
Kosten Senken Dank Open Source? Strategien
Kosten senken dank Open Source? Strategien 36 Nr. 01/02 | Februar 2014 Swiss IT Magazine Strategien Kosten senken dank Open Source? Mehr Geld im Portemonnaie und weniger Sorgen im Gepäck Der Einsatz von Open Source Software kann das IT-Budget schonen, wenn man richtig vorgeht. Viel wichtiger sind aber strategische Vorteile wie die digitale Nachhaltigkeit oder die Unabhängigkeit von Herstellern, die sich durch den konsequenten Einsatz von Open Source ergeben. V ON D R . M ATTHIAS S TÜR M ER ines vorweg: Open Source ist nicht gra- tis. Oder korrekt ausgedrückt: Der Download von Open Source Software (OSS) von den vielen Internet-Portalen wieE Github, Google Code, Sourceforge oder Freecode ist selbstverständlich kostenlos. Aber wenn Open-Source-Lösungen professionell eingeführt und betrieben werden, verursacht dies interne und/oder externe Kosten. Geschäftskritische Lösungen benötigen stets zuverlässige Wartung und Support, ansonsten steigt das Risiko erheblich, dass zentrale Infor- matiksysteme ausfallen oder wichtige Daten verloren gehen oder gestohlen werden. Für den sicheren Einsatz von Open Source Soft- ware braucht es deshalb entweder interne INHALT Ressourcen und Know-how, wie die entspre- chenden Systeme betrieben werden. Oder es MEHR GELD im PORTemoNNaie UND weNIGER SorgeN im GEPÄck 36 wird ein Service Level Agreement (SLA) bei- MarkTÜbersicHT: 152 SCHweiZer OPEN-SOUrce-SPEZialisTEN 40 spielsweise in Form einer Subscription mit einem kommerziellen Anbieter von Open- SpareN ODER NICHT spareN 48 Source-Lösungen abgeschlossen. Dieser be- GÜNSTIGE HocHVERFÜgbarkeiT 50 schäftigt wiederum Mitarbeitende, die lang- MEHR EIGENREGIE daNK OpeN SOUrce 52 jährige Erfahrungen mit den jeweiligen Syste- men haben und deshalb im Bedarfsfall rasch SO GUT SCHLÄFT maN miT OpeN SOUrce 54 und kompetent eingreifen können.