UNIVERSITY of CALGARY a Novel Neurodevelopmental Disorder Within the Hutterite Population Maps to 16P and a Possible Causative M
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Building the Vertebrate Codex Using the Gene Breaking Protein Trap Library
Genetics, Development and Cell Biology Publications Genetics, Development and Cell Biology 2020 Building the vertebrate codex using the gene breaking protein trap library Noriko Ichino Mayo Clinic Gaurav K. Varshney National Institutes of Health Ying Wang Iowa State University Hsin-kai Liao Iowa State University Maura McGrail Iowa State University, [email protected] See next page for additional authors Follow this and additional works at: https://lib.dr.iastate.edu/gdcb_las_pubs Part of the Molecular Genetics Commons, and the Research Methods in Life Sciences Commons The complete bibliographic information for this item can be found at https://lib.dr.iastate.edu/ gdcb_las_pubs/261. For information on how to cite this item, please visit http://lib.dr.iastate.edu/howtocite.html. This Article is brought to you for free and open access by the Genetics, Development and Cell Biology at Iowa State University Digital Repository. It has been accepted for inclusion in Genetics, Development and Cell Biology Publications by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Building the vertebrate codex using the gene breaking protein trap library Abstract One key bottleneck in understanding the human genome is the relative under-characterization of 90% of protein coding regions. We report a collection of 1200 transgenic zebrafish strains made with the gene- break transposon (GBT) protein trap to simultaneously report and reversibly knockdown the tagged genes. Protein trap-associated mRFP expression shows previously undocumented expression of 35% and 90% of cloned genes at 2 and 4 days post-fertilization, respectively. Further, investigated alleles regularly show 99% gene-specific mRNA knockdown. -
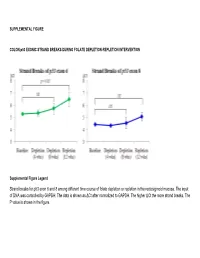
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

Assessment of Network Module Identification Across Complex Diseases
ANALYSIS https://doi.org/10.1038/s41592-019-0509-5 Assessment of network module identification across complex diseases Sarvenaz Choobdar1,2,20, Mehmet E. Ahsen3,117, Jake Crawford4,117, Mattia Tomasoni 1,2, Tao Fang5, David Lamparter1,2,6, Junyuan Lin7, Benjamin Hescott8, Xiaozhe Hu7, Johnathan Mercer9,10, Ted Natoli11, Rajiv Narayan11, The DREAM Module Identification Challenge Consortium12, Aravind Subramanian11, Jitao D. Zhang 5, Gustavo Stolovitzky 3,13, Zoltán Kutalik2,14, Kasper Lage 9,10,15, Donna K. Slonim 4,16, Julio Saez-Rodriguez 17,18, Lenore J. Cowen4,7, Sven Bergmann 1,2,19,21* and Daniel Marbach 1,2,5,21* Many bioinformatics methods have been proposed for reducing the complexity of large gene or protein networks into relevant subnetworks or modules. Yet, how such methods compare to each other in terms of their ability to identify disease-relevant modules in different types of network remains poorly understood. We launched the ‘Disease Module Identification DREAM Challenge’, an open competition to comprehensively assess module identification methods across diverse protein–protein interaction, signaling, gene co-expression, homology and cancer-gene networks. Predicted network modules were tested for association with complex traits and diseases using a unique collection of 180 genome-wide association studies. Our robust assessment of 75 module identification methods reveals top-performing algorithms, which recover complementary trait- associated modules. We find that most of these modules correspond to core disease-relevant pathways, which often com- prise therapeutic targets. This community challenge establishes biologically interpretable benchmarks, tools and guidelines for molecular network analysis to study human disease biology. omplex diseases involve many genes and molecules that inter- assessed on in silico generated benchmark graphs11. -

Overexpression of an Activated REL Mutant Enhances the Transformed State of the Human B-Lymphoma BJAB Cell Line and Alters Its Gene Expression Profile
Oncogene (2009) 28, 2100–2111 & 2009 Macmillan Publishers Limited All rights reserved 0950-9232/09 $32.00 www.nature.com/onc ORIGINAL ARTICLE Overexpression of an activated REL mutant enhances the transformed state of the human B-lymphoma BJAB cell line and alters its gene expression profile M Chin1, M Herscovitch1, N Zhang, DJ Waxman and TD Gilmore Department of Biology, Boston University, Boston, MA, USA The human REL proto-oncogene encodes a transcription factor. Misregulated REL is associated with B-cell factor in the nuclear factor (NF)-kB family. Overexpres- malignancies in several ways (Gilmore et al., sion of REL is acutely transforming in chicken lymphoid 2004). Overexpression of REL protein can transform cells, but has not been shown to transform any mammalian chicken lymphoid cells in vitro. Additionally, the lymphoid cell type. In this report, we show that over- REL locus is amplified in several types of human expression of a highly transforming mutant of REL B-cell lymphoma, including diffuse large B-cell lympho- (RELDTAD1) increases the oncogenic properties of the ma (DLBCL), follicular and primary mediastinal human B-cell lymphoma BJAB cell line, as shown by lymphomas. Moreover, REL mRNA is highly expressed increased colony formation in soft agar, tumor formation in de novo DLBCLs, and this elevated expression in SCID (severe combined immunodeficient) mice, and correlates with increased expression of many adhesion. BJAB-RELDTAD1 cells also show decreased putative REL target genes (Rhodes et al., 2005). activation of caspase in response to doxorubicin. BJAB- Nevertheless, REL has not been shown to be oncogenic RELDTAD1 cells have increased levels of active nuclear in any mammalian B-cell system, either in vitro REL protein as determined by immunofluorescence, or in vivo. -

Oncogenic Potential of the Dual-Function Protein MEX3A
biology Review Oncogenic Potential of the Dual-Function Protein MEX3A Marcell Lederer 1,*, Simon Müller 1, Markus Glaß 1 , Nadine Bley 1, Christian Ihling 2, Andrea Sinz 2 and Stefan Hüttelmaier 1 1 Charles Tanford Protein Center, Faculty of Medicine, Institute of Molecular Medicine, Section for Molecular Cell Biology, Martin Luther University Halle-Wittenberg, Kurt-Mothes-Str. 3a, 06120 Halle, Germany; [email protected] (S.M.).; [email protected] (M.G.).; [email protected] (N.B.); [email protected] (S.H.) 2 Center for Structural Mass Spectrometry, Department of Pharmaceutical Chemistry & Bioanalytics, Institute of Pharmacy, Martin Luther University Halle-Wittenberg, Kurt-Mothes-Str. 3, 06120 Halle (Saale), Germany; [email protected] (C.I.); [email protected] (A.S.) * Correspondence: [email protected] Simple Summary: RNA-binding proteins (RBPs) are involved in the post-transcriptional control of gene expression, modulating the splicing, turnover, subcellular sorting and translation of (m)RNAs. Dysregulation of RBPs, for instance, by deregulated expression in cancer, disturbs key cellular processes such as proliferation, cell cycle progression or migration. Accordingly, RBPs contribute to tumorigenesis. Members of the human MEX3 protein family harbor RNA-binding capacity and E3 ligase activity. Thus, they presumably combine post-transcriptional and post-translational regulatory mechanisms. In this review, we discuss recent studies to emphasize emerging evidence for a pivotal role of the MEX3 protein family, in particular MEX3A, in human cancer. Citation: Lederer, M.; Müller, S.; Glaß, M.; Bley, N.; Ihling, C.; Sinz, A.; Abstract: MEX3A belongs to the MEX3 (Muscle EXcess) protein family consisting of four members Hüttelmaier, S. -

Network of Micrornas-Mrnas Interactions in Pancreatic Cancer
Hindawi Publishing Corporation BioMed Research International Volume 2014, Article ID 534821, 8 pages http://dx.doi.org/10.1155/2014/534821 Research Article Network of microRNAs-mRNAs Interactions in Pancreatic Cancer Elnaz Naderi,1 Mehdi Mostafaei,2 Akram Pourshams,1 and Ashraf Mohamadkhani1 1 Liver and Pancreatobiliary Diseases Research Center, Digestive Diseases Research Institute, Tehran University of Medical Sciences, Tehran, Iran 2 Biotechnology Engineering, Islamic Azad University,Tehran North Branch, Tehran, Iran Correspondence should be addressed to Ashraf Mohamadkhani; [email protected] Received 5 February 2014; Revised 13 April 2014; Accepted 13 April 2014; Published 7 May 2014 Academic Editor: FangXiang Wu Copyright © 2014 Elnaz Naderi et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Background. MicroRNAs are small RNA molecules that regulate the expression of certain genes through interaction with mRNA targets and are mainly involved in human cancer. This study was conducted to make the network of miRNAs-mRNAs interactions in pancreatic cancer as the fourth leading cause of cancer death. Methods. 56 miRNAs that were exclusively expressed and 1176 genes that were downregulated or silenced in pancreas cancer were extracted from beforehand investigations. MiRNA–mRNA interactions data analysis and related networks were explored using MAGIA tool and Cytoscape 3 software. Functional annotations of candidate genes in pancreatic cancer were identified by DAVID annotation tool. Results. This network is made of 217 nodes for mRNA, 15 nodes for miRNA, and 241 edges that show 241 regulations between 15 miRNAs and 217 target genes. -

Identification of MAZ As a Novel Transcription Factor Regulating Erythropoiesis
Identification of MAZ as a novel transcription factor regulating erythropoiesis Darya Deen1, Falk Butter2, Michelle L. Holland3, Vasiliki Samara4, Jacqueline A. Sloane-Stanley4, Helena Ayyub4, Matthias Mann5, David Garrick4,6,7 and Douglas Vernimmen1,7 1 The Roslin Institute and Royal (Dick) School of Veterinary Studies, University of Edinburgh, Easter Bush, Midlothian EH25 9RG, United Kingdom. 2 Institute of Molecular Biology (IMB), 55128 Mainz, Germany 3 Department of Medical and Molecular Genetics, School of Basic and Medical Biosciences, King's College London, London SE1 9RT, UK 4 MRC Molecular Haematology Unit, Weatherall Institute for Molecular Medicine, University of Oxford, John Radcliffe Hospital, Oxford OX3 9DS, United Kingdom. 5 Department of Proteomics and Signal Transduction, Max Planck Institute of Biochemistry, 82152 Martinsried, Germany. 6 Current address : INSERM UMRS-976, Institut de Recherche Saint Louis, Université de Paris, 75010 Paris, France. 7 These authors contributed equally Correspondence: [email protected], [email protected] ADDITIONAL MATERIAL Suppl Fig 1. Erythroid-specific hypersensitivity regions DNAse-Seq. (A) Structure of the α-globin locus. Chromosomal position (hg38 genome build) is shown above the genes. The locus consists of the embryonic ζ gene (HBZ), the duplicated foetal/adult α genes (HBA2 and HBA1) together with two flanking pseudogenes (HBM and HBQ1). The upstream, widely-expressed gene, NPRL3 is transcribed from the opposite strand to that of the HBA genes and contains the remote regulatory elements of the α-globin locus (MCS -R1 to -R3) (indicated by red dots). Below is shown the ATAC-seq signal in human erythroblasts (taken from 8) indicating open chromatin structure at promoter and distal regulatory elements (shaded regions). -

(12) Patent Application Publication (10) Pub. No.: US 2006/0128764 A1 Downes Et Al
US 2006O128764A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2006/0128764 A1 DOWnes et al. (43) Pub. Date: Jun. 15, 2006 (54) NON-STEROIDAL FARNESOD X Publication Classification RECEPTOR MODULATORS AND METHODS FOR THE USE THEREOF (51) Int. Cl. A61K 31/4433 (2006.01) (75) Inventors: Michael R Downes, San Diego, CA A6II 3/44 (2006.01) (US); Ronald M Evans, La Jolla, CA A6II 3 L/353 (2006.01) (US) A6II 3/16 (2006.01) (52) U.S. Cl. ........................... 514/357: 514/456; 514/625 Correspondence Address: FOLEY & LARDNER LLP P.O. BOX 80278 (57) ABSTRACT SAN DIEGO, CA 92138-0278 (US) The efficient regulation of cholesterol synthesis, metabo (73) Assignee: THE SALK INSTITUTE FOR BIO lism, acquisition, and transport is an essential component of LOGICAL STUDES lipid homeostasis. The farnesoid X receptor (FXR) is a transcriptional sensor for bile acids, the primary product of (21) Appl. No.: 10/535,043 cholesterol metabolism. Accordingly, the development of potent, selective, Small molecule agonists, partial agonists, (22) PCT Fed: Nov. 14, 2003 and antagonists of FXR would be an important step in PCT No.: PCT/USO3/36137 further deconvoluting FXR physiology. In accordance with (86) the present invention, the identification of novel potent FXR Related U.S. Application Data activators is described. Two derivatives of invention com pounds, bearing stilbene or biaryl moieties, contain mem (60) Provisional application No. 60/426,664, filed on Nov. bers that are the most potent FXR agonists reported to date 15, 2002. in cell-based assays. These compounds are useful as chemi cal tools to further define the physiological role of FXR as (30) Foreign Application Priority Data well as therapeutic leads for the treatment of diseases linked to cholesterol, bile acids and their metabolism and homeo Sep. -

Building the Vertebrate Codex Using the Gene Breaking Protein Trap Library
TOOLS AND RESOURCES Building the vertebrate codex using the gene breaking protein trap library Noriko Ichino1, MaKayla R Serres1, Rhianna M Urban1, Mark D Urban1, Anthony J Treichel1, Kyle J Schaefbauer1, Lauren E Greif1, Gaurav K Varshney2,3, Kimberly J Skuster1, Melissa S McNulty1, Camden L Daby1, Ying Wang4, Hsin-kai Liao4, Suzan El-Rass5, Yonghe Ding1,6, Weibin Liu1,6, Jennifer L Anderson7, Mark D Wishman1, Ankit Sabharwal1, Lisa A Schimmenti1,8,9, Sridhar Sivasubbu10, Darius Balciunas11, Matthias Hammerschmidt12, Steven Arthur Farber7, Xiao-Yan Wen5, Xiaolei Xu1,6, Maura McGrail4, Jeffrey J Essner4, Shawn M Burgess2, Karl J Clark1*, Stephen C Ekker1* 1Department of Biochemistry and Molecular Biology, Mayo Clinic, Rochester, United States; 2Translational and Functional Genomics Branch, National Human Genome Research Institute, National Institutes of Health, Bethesda, United States; 3Functional & Chemical Genomics Program, Oklahoma Medical Research Foundation, Oklahoma City, United States; 4Department of Genetics, Development and Cell Biology, Iowa State University, Ames, United States; 5Zebrafish Centre for Advanced Drug Discovery & Keenan Research Centre for Biomedical Science, Li Ka Shing Knowledge Institute, St. Michael’s Hospital, Unity Health Toronto & University of Toronto, Toronto, Canada; 6Department of Cardiovascular Medicine, Mayo Clinic, Rochester, United States; 7Department of Embryology, Carnegie Institution for Science, Baltimore, United States; 8Department of Clinical Genomics, Mayo Clinic, Rochester, United States; 9Department of Otorhinolaryngology, Mayo Clinic, Rochester, United States; 10Genomics and Molecular Medicine Unit, CSIR– 11 *For correspondence: Institute of Genomics and Integrative Biology, Delhi, India; Department of [email protected] (KJC); Biology, Temple University, Philadelphia, United States; 12Institute of Zoology, [email protected] (SCE) Developmental Biology Unit, University of Cologne, Cologne, Germany Competing interests: The authors declare that no competing interests exist. -

The Pdx1 Bound Swi/Snf Chromatin Remodeling Complex Regulates Pancreatic Progenitor Cell Proliferation and Mature Islet Β Cell
Page 1 of 125 Diabetes The Pdx1 bound Swi/Snf chromatin remodeling complex regulates pancreatic progenitor cell proliferation and mature islet β cell function Jason M. Spaeth1,2, Jin-Hua Liu1, Daniel Peters3, Min Guo1, Anna B. Osipovich1, Fardin Mohammadi3, Nilotpal Roy4, Anil Bhushan4, Mark A. Magnuson1, Matthias Hebrok4, Christopher V. E. Wright3, Roland Stein1,5 1 Department of Molecular Physiology and Biophysics, Vanderbilt University, Nashville, TN 2 Present address: Department of Pediatrics, Indiana University School of Medicine, Indianapolis, IN 3 Department of Cell and Developmental Biology, Vanderbilt University, Nashville, TN 4 Diabetes Center, Department of Medicine, UCSF, San Francisco, California 5 Corresponding author: [email protected]; (615)322-7026 1 Diabetes Publish Ahead of Print, published online June 14, 2019 Diabetes Page 2 of 125 Abstract Transcription factors positively and/or negatively impact gene expression by recruiting coregulatory factors, which interact through protein-protein binding. Here we demonstrate that mouse pancreas size and islet β cell function are controlled by the ATP-dependent Swi/Snf chromatin remodeling coregulatory complex that physically associates with Pdx1, a diabetes- linked transcription factor essential to pancreatic morphogenesis and adult islet-cell function and maintenance. Early embryonic deletion of just the Swi/Snf Brg1 ATPase subunit reduced multipotent pancreatic progenitor cell proliferation and resulted in pancreas hypoplasia. In contrast, removal of both Swi/Snf ATPase subunits, Brg1 and Brm, was necessary to compromise adult islet β cell activity, which included whole animal glucose intolerance, hyperglycemia and impaired insulin secretion. Notably, lineage-tracing analysis revealed Swi/Snf-deficient β cells lost the ability to produce the mRNAs for insulin and other key metabolic genes without effecting the expression of many essential islet-enriched transcription factors. -

Cell Type Manuscript Rev 180328 Justmaintext
Running Head: PREDICTING CELL TYPE BALANCE 1012 7. Supporting Information 1013 1014 1015 Supplementary Material for: 1016 1017 INFERENCE OF CELL TYPE COMPOSITION FROM HUMAN BRAIN TRANSCRIPTOMIC 1018 DATASETS ILLUMINATES THE EFFECTS OF AGE, MANNER OF DEATH, DISSECTION, 1019 AND PSYCHIATRIC DIAGNOSIS 1020 *Megan Hastings Hagenauer, Ph.D.1, Anton Schulmann, M.D.2, Jun Z. Li, Ph.D.3, Marquis P. Vawter, 1021 Ph.D.4, David M. Walsh, Psy.D.4, Robert C. Thompson, Ph.D.1, Cortney A. Turner, Ph.D.1, William E. 1022 Bunney, M.D.4, Richard M. Myers, Ph.D.5, Jack D. Barchas, M.D.6, Alan F. Schatzberg, M.D.7, Stanley J. 1023 Watson, M.D., Ph.D.1, Huda Akil, Ph.D.1 1024 42 Running Head: PREDICTING CELL TYPE BALANCE 1025 7.1 Additional Methods: Detailed Preprocessing Methods for the Transcriptomic Datasets 1026 1027 7.1.1 RNA-Seq data from Purified Cell Types (GSE52564 and GSE67835) 1028 As initial validation, we used our method to predict sample cell type identity in two RNA-Seq 1029 datasets derived from purified cell types: one derived from from purified cortical cell types in mice 1030 (n=17: two samples per cell type and 3 whole brain samples: GSE52564) (18), and one derived from 466 1031 single-cells dissociated from freshly-resected human cortex (GSE67835) (2). The RNA-Seq data that we 1032 downloaded from GEO was already in the format of FPKM values (Fragments Per Kilobase of exon 1033 model per million mapped fragments) (18) or counts per gene (2). -

Role of the Proliferation-Related Molecules in the Pathogenesis Of
ROLE OF THE PROLIFERATION-RELATED MOLECULES IN THE PATHOGENESIS OF ALZHEIMER’S DISEASE By SHARON CHRISTINE YATES A thesis submitted to the University of Birmingham for the degree of Master of Philosophy Clinical and Experimental Medicine The Medical School University of Birmingham April 2012 University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. ABSTRACT The cell cycle theory of Alzheimer’s Disease (AD) states that neurodegeneration is secondary to aberrant cell cycle activity in neurons. Previous studies suggest that this may be partly attributed to alterations in the mTOR pathway, which promotes cell growth and division, and partly to genetic variants on genes responsible for cell cycle control. In this study we perform a systematic analysis of the rapamycin-regulated genes that are differentially regulated in brain affected by AD compared to control. These genes may serve as novel therapeutic targets or biomarkers of AD. Secondly, we investigate the association of a cancer-associated variant of p21cip1, and a variant of p57kip2, with AD. These cyclin dependent kinase inhibitors are crucial cell cycle regulatory components that function downstream of mTOR.