Project Zero
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The 2016 SNIA Dictionary
A glossary of storage networking data, and information management terminology SNIA acknowledges and thanks its Voting Member Companies: Cisco Cryptsoft DDN Dell EMC Evaluator Group Fujitsu Hitachi HP Huawei IBM Intel Lenovo Macrosan Micron Microsoft NetApp Oracle Pure Storage Qlogic Samsung Toshiba Voting members as of 5.23.16 Storage Networking Industry Association Your Connection Is Here Welcome to the Storage Networking Industry Association (SNIA). Our mission is to lead the storage industry worldwide in developing and promoting standards, technologies, and educational services to empower organizations in the management of information. Made up of member companies spanning the global storage market, the SNIA connects the IT industry with end-to-end storage and information management solutions. From vendors, to channel partners, to end users, SNIA members are dedicated to providing the industry with a high level of knowledge exchange and thought leadership. An important part of our work is to deliver vendor-neutral and technology-agnostic information to the storage and data management industry to drive the advancement of IT technologies, standards, and education programs for all IT professionals. For more information visit: www.snia.org The Storage Networking Industry Association 4360 ArrowsWest Drive Colorado Springs, Colorado 80907, U.S.A. +1 719-694-1380 The 2016 SNIA Dictionary A glossary of storage networking, data, and information management terminology by the Storage Networking Industry Association The SNIA Dictionary contains terms and definitions related to storage and other information technologies, and is the storage networking industry's most comprehensive attempt to date to arrive at a common body of terminology for the technologies it represents. -
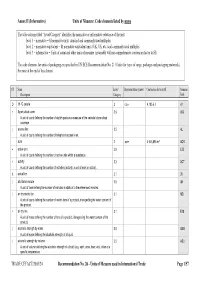
Units of Measure Used in International Trade Page 1/57 Annex II (Informative) Units of Measure: Code Elements Listed by Name
Annex II (Informative) Units of Measure: Code elements listed by name The table column titled “Level/Category” identifies the normative or informative relevance of the unit: level 1 – normative = SI normative units, standard and commonly used multiples level 2 – normative equivalent = SI normative equivalent units (UK, US, etc.) and commonly used multiples level 3 – informative = Units of count and other units of measure (invariably with no comprehensive conversion factor to SI) The code elements for units of packaging are specified in UN/ECE Recommendation No. 21 (Codes for types of cargo, packages and packaging materials). See note at the end of this Annex). ST Name Level/ Representation symbol Conversion factor to SI Common Description Category Code D 15 °C calorie 2 cal₁₅ 4,185 5 J A1 + 8-part cloud cover 3.9 A59 A unit of count defining the number of eighth-parts as a measure of the celestial dome cloud coverage. | access line 3.5 AL A unit of count defining the number of telephone access lines. acre 2 acre 4 046,856 m² ACR + active unit 3.9 E25 A unit of count defining the number of active units within a substance. + activity 3.2 ACT A unit of count defining the number of activities (activity: a unit of work or action). X actual ton 3.1 26 | additional minute 3.5 AH A unit of time defining the number of minutes in addition to the referenced minutes. | air dry metric ton 3.1 MD A unit of count defining the number of metric tons of a product, disregarding the water content of the product. -

“ICT Equipment Societies”?? Measuring the Digital Information
Information Societies or “ICT equipment societies”? Measuring the information processing capacity of a society in bits and bytes Information Societies or “ICT equipment societies”? Measuring the digital information processing capacity of a society in bits and bytes Martin Hilbert1, Priscila López2, Cristián Vásquez3 This is the author’s pre-print version of the article finally published as: Hilbert, M., López, P., & Vásquez, C. (2010). Information Societies or “ICT Equipment Societies?” Measuring the Digital Information-Processing Capacity of a Society in Bits and Bytes. The Information Society, 26(3), 157–178. doi:10.1080/01972241003712199 http://www.tandfonline.com/doi/abs/10.1080/01972241003712199 Information Societies or “ICT equipment societies”? Measuring the digital information processing capacity of a society in bits and bytes............................................................... 1 Multiple dimensions of technology diffusion ............................................................. 3 The closing digital equipment divide .......................................................................... 7 The three subsystems of information processing ...................................................... 10 The amount of digital information ............................................................................ 13 The digital divide as a moving target ........................................................................ 18 Limitations and resulting research challenges ......................................................... -

Lecture 4” Area
● Log into the Moodle site ● Enter the “Lecture 4” area ● At 14:00, choose “Daily Quiz 3” ● Answer the multiple choice quiz (you have until 14:10 to finish) Let's try! ● In the remote machine, inside directory ~jmalves/PE8/ ● Try commands ls -l and cd on directories: another_dir also_a_dir some_dir third_dir J.M.P. Alves 2 / 49 BMP0260 / ICB5765 / IBI5765 Now you do it! Go to the course site and enter Practical Exercise 8 Follow the instructions to answer the questions in the exercise Remember: in a PE, you should do things in practice before answering the question! J.M.P. Alves 3 / 49 BMP0260 / ICB5765 / IBI5765 How to change permissions ● The chmod command allows one to change permissions for a file or a directory (if one has permission to do that, of course!) ● This command can use a symbolic (i.e., letters) or octal (numbers) mode ● The symbolic mode uses letters u, g, o, a, r, w, and x ● u, g, o, a are for user (owner), group, others, and all, respectively ● r, w, x are read, write, execute, as usual ● The octal mode uses numbers 0 to 7 (eight digits, thus octal) J.M.P. Alves 4 / 49 BMP0260 / ICB5765 / IBI5765 Description Symbol Octal code Read r 4 Write w 2 Execute x 1 Read and Execute rx 5 (4 + 1) Read and Write rw 6 (4 + 2) Read, Write and Execute rwx 7 (4 + 2 + 1) -rwxr-xr-x 1 joe bmp0260 12456 Feb 31 13:37 file.txt Remove read and execute permissions for others (i.e., not user or group): chmod o-rx file.txt symbolic or chmod 750 file.txt octal -rwxr-x--- 1 joe bmp0260 12456 Feb 31 13:37 file.txt J.M.P. -

File Organization & Management
1 UNESCO -NIGERIA TECHNICAL & VOCATIONAL EDUCATION REVITALISATION PROJECT -PHASE II NATIONAL DIPLOMA IN COMPUTER TECHNOLOGY File Organization and Management YEAR II- SE MESTER I THEORY Version 1: December 2008 1 2 Table of Contents WEEK 1 File Concepts .................................................................................................................................6 Bit: . .................................................................................................................................................7 Binary digit .....................................................................................................................................8 Representation ...............................................................................................................................9 Transmission ..................................................................................................................................9 Storage ............................................................................................................................................9 Storage Unit .....................................................................................................................................9 Abbreviation and symbol ............................................................................................................ 10 More than one bit ......................................................................................................................... 11 Bit, trit, -

PC Maintenance and Repair Career Diploma Sample
System Boards and Component Identification THE SYSTEM BOARD In this section of the study unit, we’re going to learn about the system board. The system board is the main printed circuit board (PCB) in a PC that enables the interaction and control of all other components and devices in a computer system. A system board can be compared to a mass transit system in a large city. Mass transit in a city has intercon- nected streets, avenues, and highways that are used for transportation. Similarly, with a system board, data and information is transported via the bus, which can have numerous components attached to its “roadways.” In a city, we have stop lights, stop signs, and other ways of controlling traffic, as well as people who use the transportation system to get from place to place. If we didn’t have ways to manage the traffic, we might get lost, end up in a traffic jam, or be involved in an accident. Similarly, the system board has a system clock to synchronize the operation of the bus and other components. The system clock keeps data and information flowing smoothly to its correct destination, and hopefully without error. Professional Tip Don’t confuse the system clock with the operating system (OS) clock in Windows. The OS clock is a software component of the Windows operating system, and uses the Real-Time Clock/Calendar (RTCC) chip to display and adjust the date and time. 1 The system board is the most important module and the The system board may also be referred to as main PCB in the computer. -

The 2016 SNIA Dictionary
Storage Networking Industry Association (SNIA) SNIA is the globally recognized and trusted authority for storage leadership, standards, and technology expertise. Leading the storage industry by developing and promoting vendor-neutral architectures, standards and educational services that facilitate the efficient management, movement and security of information. The SNIA Dictionary, 18th Edition The SNIA Dictionary contains terms and definitions related to storage and other information technologies, and is the storage networking industry's most comprehensive effort to arrive at a common body of terminology for the technologies it represents. The terms go through a rigorous technical review and approval process by the SNIA Technical Council to assure their accuracy. The SNIA Technical Council is a group of technical experts elected by the members of SNIA to guide SNIA’s technical efforts. Their extensive individual technical backgrounds cover all aspects of storage. The reader should recognize that in this rapidly evolving field, new terminology is constantly being introduced, and common usage is shifting. SNIA regards this dictionary as a living document, to be updated as necessary to reflect a consensus on common usage, and encourages readers to treat it in that spirit. Suggestions for improvement are welcomed at any time and may be sent to [email protected]. SNIA owns the rights to all submitted comments and suggestions. Proposals for new terms or definitions, or modifications to existing ones, should be submitted on the form located at: http://www.snia.org/education/dictionary/submittal Periodically SNIA regional groups translate the SNIA dictionary into local languages. There are versions of the dictionary in Japanese, Portuguese, and Chinese. -

Single-Event Effects of Space and Atmospheric Radiation on Memory Components
DEPARTMENT OF PHYSICS, UNIVERSITY OF JYVÄSKYLÄ LIRMM, UNIVERSITY OF MONTPELLIER/CNRS RESEARCH REPORT No. 10/2017 SINGLE-EVENT EFFECTS OF SPACE AND ATMOSPHERIC RADIATION ON MEMORY COMPONENTS by Alexandre Louis BOSSER Academic Dissertation for the Degree of Doctor of Philosophy To be presented, by permission of the Faculty of Mathematics and Science of the University of Jyväskylä and the President of the University of Montpellier, for public examination in Auditorium FYS 1 of the University of Jyväskylä on December 20th, 2017 at 12 noon. Jyväskylä, Finland 2017 2 Author Alexandre Louis Bosser Department of Physics, University of Jyväskylä Jyväskylä, Finland LIRMM, University of Montpellier/CNRS Montpellier, France email: [email protected] Supervisors Professor Ari Virtanen Department of Physics, University of Jyväskylä Jyväskylä, Finland Assistant Professor Arto Javanainen Department of Physics, University of Jyväskylä Jyväskylä, Finland School of Engineering, Vanderbilt University Nashville, TN, USA Professor Luigi Dilillo LIRMM, University of Montpellier/CNRS Montpellier, France Reviewers Professor Ronald Schrimpf Institute for Space and Defense Electronics, Vanderbilt University Nashville, TN, USA Professor Simone Gerardin Department of Information Engineering, University of Padova Padova, Italy Opponent Professor Fernanda Lima Kastensmidt Institute of Informatics, Federal University of Rio Grande do Sul Porto Alegre, Brazil 3 Abstract Electronic memories are ubiquitous components in electronic systems: they are used to store -

The Complete List of Measurement Units Supported
28.3.2019 The Complete List of Units to Convert The List of Units You Can Convert Pick one and click it to convert Weights and Measures Conversion The Complete List of Measurement Units Supported # A B C D E F G H I J K L M N O P Q R S T U V W X Y Z # ' (minute) '' (second) Common Units, Circular measure Common Units, Circular measure % (slope percent) % (percent) Slope (grade) units, Circular measure Percentages and Parts, Franctions and Percent ‰ (slope permille) ‰ (permille) Slope (grade) units, Circular measure Percentages and Parts, Franctions and Percent ℈ (scruple) ℔, ″ (pound) Apothecaries, Mass and weight Apothecaries, Mass and weight ℥ (ounce) 1 (unit, point) Apothecaries, Mass and weight Quantity Units, Franctions and Percent 1/10 (one tenth or .1) 1/16 (one sixteenth or .0625) Fractions, Franctions and Percent Fractions, Franctions and Percent 1/2 (half or .5) 1/3 (one third or .(3)) Fractions, Franctions and Percent Fractions, Franctions and Percent 1/32 (one thirty-second or .03125) 1/4 (quart, one forth or .25) Fractions, Franctions and Percent Fractions, Franctions and Percent 1/5 (tithe, one fifth or .2) 1/6 (one sixth or .1(6)) Fractions, Franctions and Percent Fractions, Franctions and Percent 1/7 (one seventh or .142857) 1/8 (one eights or .125) Fractions, Franctions and Percent Fractions, Franctions and Percent 1/9 (one ninth or .(1)) ångström Fractions, Franctions and Percent Metric, Distance and Length °C (degrees Celsius) °C (degrees Celsius) Temperature increment conversion, Temperature increment Temperature scale -

The 2015 SNIA Dictionary Was Underwritten by the Generous Contributions Of
The 2015 SNIA Dictionary was underwritten by the generous contributions of: If your organization is a SNIA member and is interested in sponsoring the 2016 edition of this dictionary, please contact [email protected]. 4360 ArrowsWest Drive Colorado Springs, CO 80907 719.694.1380 www.snia.org SNIA acknowledges and thanks its Voting Member Companies: Cisco Computerworld Cryptsoft Cygate DDN Dell EMC Emulex Evaluator Group Flexstar Fujitsu Hitachi HP Huawei IBM Intel Macrosan Microsoft NetApp NTP Software Oracle Pure Storage QLogic Samsung Toshiba XIO Voting members as of 3.23.15 Storage Networking Industry Association Your Connection Is Here Welcome to the Storage Networking Industry Association (SNIA). Our mission is to lead the storage industry worldwide in developing and promoting standards, technologies, and educational services to empower organizations in the management of information. Made up of member companies spanning the global storage market, the SNIA connects the IT industry with end-to-end storage and information management solutions. From vendors, to channel partners, to end users, SNIA members are dedicated to providing the industry with a high level of knowledge exchange and thought leadership. An important part of our work is to deliver vendor-neutral and technology-agnostic information to the storage and data management industry to drive the advancement of IT technologies, standards, and education programs for all IT professionals. For more information visit: www.snia.org The Storage Networking Industry Association 4360 ArrowsWest Drive Colorado Springs, Colorado 80907, U.S.A. +1 719-694-1380 The 2015 SNIA Dictionary A glossary of storage networking, data, and information management terminology by the Storage Networking Industry Association The SNIA Dictionary contains terms and definitions related to storage and other information technologies, and is the storage networking industry's most comprehensive attempt to date to arrive at a common body of terminology for the technologies it represents. -

Underwater Acoustics
UNDERWATER ACOUSTICS - TASK 3: REPORTING A report prepared by TNO for the Joint Industry Programme on E&P Sound and Marine Life JIP Topic - Sound source characterisation and propagation 2016 www.soundandmarinelife.org About the E&P Sound & Marine Life Programme The ocean is filled with a wide variety of natural and man-made sounds. Since the [early 1990s], there has been increasing environmental and regulatory focus on man-made sounds in the sea and on the effects these sounds may have on marine life. There are now many national and international regimes that regulate how we introduce sound to the marine environment. We believe that effective policies and regulations should be firmly rooted in sound independent science. This allows regulators to make consistent and reasonable regulations while also allowing industries that use or introduce sound to develop effective mitigation strategies. In 2005, a broad group of international oil and gas companies and the International Association of Geophysical Contractors (IAGC) committed to form a Joint Industry Programme under the auspices of the International Association of Oil and Gas Producers (IOGP) to identify and conduct a research programme that improves understanding of the potential impact of exploration and production sound on marine life. The Objectives of the programme were (and remain): 1. To support planning of E&P operations and risk assessments 2. To provide the basis for appropriate operational measures that are protective of marine life 3. To inform policy and regulation. The members of the JIP are committed to ensuring that wherever possible the results of the studies it commissions are submitted for scrutiny through publication in peer-reviewed journals. -
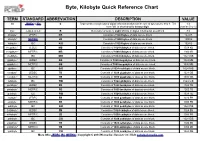
Byte, Kilobyte Quick Reference Chart
Byte, Kilobyte Quick Reference Chart TERM STANDARD ABBREVIATION DESCRIPTION VALUE bit JEDEC & IEC b Represents a single unit of digital information that can be one of two values: 0 or 1. The 1 b term “bit” is shorthand for binary digit. (can be 0 or 1) byte JEDEC & IEC B Generally consists of eight (8) bits of digital information as a block. 8 b kilobyte1 JEDEC KB Consists of 1024 bytes of data as one block. 1024 B kilobyte2 METRIC kB Consists of 1000 bytes of data as one block. 1000 B kibibyte IEC KiB Consists of 1024 bytes of data as one block. 1024 B megabyte1 JEDEC MB Consists of 1024 kilobytes of data as one block. 1024 KB megabyte2 METRIC MB Consists of 1000 kilobytes of data as one block. 1000 kB mebibyte IEC MiB Consists of 1024 kibibytes of data as one block. 1024 KiB gigabyte1 JEDEC GB Consists of 1024 megabytes of data as one block. 1024 MB gigabyte2 METRIC GB Consists of 1000 megabytes of data as one block. 1000 MB gibibyte IEC GiB Consists of 1024 mebibytes of data as one block. 1024 MiB terabyte1 JEDEC TB Consists of 1024 gigabytes of data as one block. 1024 GB terabyte2 METRIC TB Consists of 1000 gigabytes of data as one block. 1000 GB tebibyte IEC TiB Consists of 1024 gibibytes of data as one block. 1024 GiB petabyte1 JEDEC PB Consists of 1024 terabytes of data as one block. 1024 TB petabyte2 METRIC PB Consists of 1000 terabytes of data as one block. 1000 TB pebibyte IEC PiB Consists of 1024 tebibytes of data as one block.