Amazon Sagemaker Debugger:Asystemfor Real-Time Insights Into Machine Learning Model Training
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Global SCRUM GATHERING® Berlin 2014
Global SCRUM GATHERING Berlin 2014 SESSION DESCRIPTION TABLE OF CONTENTS SESSION TIMETABLE Monday, September 22nd – AM Sessions WELCOME & OPENING KEYNOTE - 9:00 – 10:30 Welcome Remarks ROOM Dave Sharrock & Marion Eickmann Opening Keynote Potsdam I/III Enabling the organization as a complex eco-system Dave Snowden AM BREAK – 10:30 – 11:00 90 MINUTE SESSIONS - 11:00 – 12:30 SESSION & SPEAKER TRACK LEVEL ROOM Managing Agility: Effectively Coaching Agile Teams Bring Down the Performing Tegel Andrea Tomasini, Bent Myllerup Wall Temenos – Build Trust in Yourself, Your Team, Successful Scrum Your Organization Practices: Berlin Norming Bellevue Christine Neidhardt, Olaf Lewitz Never Sleeps A Curious Mindset: basic coaching skills for Managing Agility: managers and other aliens Bring Down the Norming Charlottenburg II Deborah Hartmann Preuss, Steve Holyer Wall Building Creative Teams: Ideas, Motivation and Innovating beyond Retrospectives Core Scrum: The Performing Charlottenburg I Cara Turner Bohemian Bear Scrum Principles: Building Metaphors for Retrospectives Changing the Forming Tiergarted I/II Helen Meek, Mark Summers Status Quo Scrum Principles: My Agile Suitcase Changing the Forming Charlottenburg III Martin Heider Status Quo Game, Set, Match: Playing Games to accelerate Thinking Outside Agile Teams Forming Kopenick I/II the box Robert Misch Innovating beyond Let's Invent the Future of Agile! Core Scrum: The Performing Postdam III Nigel Baker Bohemian Bear Monday, September 22nd – PM Sessions LUNCH – 12:30 – 13:30 90 MINUTE SESSIONS - 13:30 -

Building Alexa Skills Using Amazon Sagemaker and AWS Lambda
Bootcamp: Building Alexa Skills Using Amazon SageMaker and AWS Lambda Description In this full-day, intermediate-level bootcamp, you will learn the essentials of building an Alexa skill, the AWS Lambda function that supports it, and how to enrich it with Amazon SageMaker. This course, which is intended for students with a basic understanding of Alexa, machine learning, and Python, teaches you to develop new tools to improve interactions with your customers. Intended Audience This course is intended for those who: • Are interested in developing Alexa skills • Want to enhance their Alexa skills using machine learning • Work in a customer-focused industry and want to improve their customer interactions Course Objectives In this course, you will learn: • The basics of the Alexa developer console • How utterances and intents work, and how skills interact with AWS Lambda • How to use Amazon SageMaker for the machine learning workflow and for enhancing Alexa skills Prerequisites We recommend that attendees of this course have the following prerequisites: • Basic familiarity with Alexa and Alexa skills • Basic familiarity with machine learning • Basic familiarity with Python • An account on the Amazon Developer Portal Delivery Method This course is delivered through a mix of: • Classroom training • Hands-on Labs Hands-on Activity • This course allows you to test new skills and apply knowledge to your working environment through a variety of practical exercises • This course requires a laptop to complete lab exercises; tablets are not appropriate Duration One Day Course Outline This course covers the following concepts: • Getting started with Alexa • Lab: Building an Alexa skill: Hello Alexa © 2018, Amazon Web Services, Inc. -
Innovation on Every Front
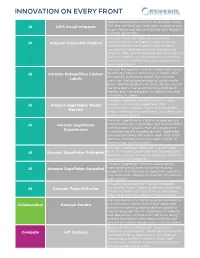
INNOVATION ON EVERY FRONT AWS DeepComposer uses AI to compose music. AI AWS DeepComposer The new service gives developers a creative way to get started and become familiar with machine learning capabilities. Amazon Transcribe Medical is a machine AI Amazon Transcribe Medical learning service that makes it easy to quickly create accurate transcriptions from medical consultations between patients and physician dictated notes, practitioner/patient consultations, and tele-medicine are automatically converted from speech to text for use in clinical documen- tation applications. Amazon Rekognition Custom Labels helps users AI Amazon Rekognition Custom identify the objects and scenes in images that are specific to business needs. For example, Labels users can find corporate logos in social media posts, identify products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected plants, or detect animated characters in videos. Amazon SageMaker Model Monitor is a new AI Amazon SageMaker Model capability of Amazon SageMaker that automatically monitors machine learning (ML) Monitor models in production, and alerts users when data quality issues appear. Amazon SageMaker is a fully managed service AI Amazon SageMaker that provides every developer and data scientist with the ability to build, train, and deploy ma- Experiments chine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models. Amazon SageMaker Debugger is a new capa- AI Amazon SageMaker Debugger bility of Amazon SageMaker that automatically identifies complex issues developing in machine learning (ML) training jobs. Amazon SageMaker Autopilot automatically AI Amazon SageMaker Autopilot trains and tunes the best machine learning models for classification or regression, based on your data while allowing to maintain full control and visibility. -
Build Your Own Anomaly Detection ML Pipeline
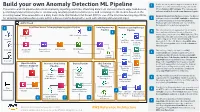
Device telemetry data is ingested from the field Build your own Anomaly Detection ML Pipeline 1 devices on a near real-time basis by calls to the This end-to-end ML pipeline detects anomalies by ingesting real-time, streaming data from various network edge field devices, API via Amazon API Gateway. The requests get performing transformation jobs to continuously run daily predictions/inferences, and retraining the ML models based on the authenticated/authorized using Amazon Cognito. incoming newer time series data on a daily basis. Note that Random Cut Forest (RCF) is one of the machine learning algorithms Amazon Kinesis Data Firehose ingests the data in for detecting anomalous data points within a data set and is designed to work with arbitrary-dimensional input. 2 real time, and invokes AWS Lambda to transform the data into parquet format. Kinesis Data AWS Cloud Firehose will automatically scale to match the throughput of the data being ingested. 1 Real-Time Device Telemetry Data Ingestion Pipeline 2 Data Engineering Machine Learning Devops Pipeline Pipeline The telemetry data is aggregated on an hourly 3 3 basis and re-partitioned based on the year, month, date, and hour using AWS Glue jobs. The Amazon Cognito AWS Glue Data Catalog additional steps like transformations and feature Device #1 engineering are performed for training the SageMaker AWS CodeBuild Anomaly Detection ML Model using AWS Glue Notebook Create ML jobs. The training data set is stored on Amazon Container S3 Data Lake. Amazon Kinesis AWS Lambda S3 Data Lake AWS Glue Device #2 Amazon API The training code is checked in an AWS Gateway Data Firehose 4 AWS SageMaker CodeCommit repo which triggers a Machine Training CodeCommit Containers Learning DevOps (MLOps) pipeline using AWS Dataset for Anomaly CodePipeline. -

Enabling Devops on Premise Or Cloud with Jenkins
Enabling DevOps on Premise or Cloud with Jenkins Sam Rostam [email protected] Cloud & Enterprise Integration Consultant/Trainer Certified SOA & Cloud Architect Certified Big Data Professional MSc @SFU & PhD Studies – Partial @UBC Topics The Context - Digital Transformation An Agile IT Framework What DevOps bring to Teams? - Disrupting Software Development - Improved Quality, shorten cycles - highly responsive for the business needs What is CI /CD ? Simple Scenario with Jenkins Advanced Jenkins : Plug-ins , APIs & Pipelines Toolchain concept Q/A Digital Transformation – Modernization As stated by a As established enterprises in all industries begin to evolve themselves into the successful Digital Organizations of the future they need to begin with the realization that the road to becoming a Digital Business goes through their IT functions. However, many of these incumbents are saddled with IT that has organizational structures, management models, operational processes, workforces and systems that were built to solve “turn of the century” problems of the past. Many analysts and industry experts have recognized the need for a new model to manage IT in their Businesses and have proposed approaches to understand and manage a hybrid IT environment that includes slower legacy applications and infrastructure in combination with today’s rapidly evolving Digital-first, mobile- first and analytics-enabled applications. http://www.ntti3.com/wp-content/uploads/Agile-IT-v1.3.pdf Digital Transformation requires building an ecosystem • Digital transformation is a strategic approach to IT that treats IT infrastructure and data as a potential product for customers. • Digital transformation requires shifting perspectives and by looking at new ways to use data and data sources and looking at new ways to engage with customers. -

Integrating the GNU Debugger with Cycle Accurate Models a Case Study Using a Verilator Systemc Model of the Openrisc 1000
Integrating the GNU Debugger with Cycle Accurate Models A Case Study using a Verilator SystemC Model of the OpenRISC 1000 Jeremy Bennett Embecosm Application Note 7. Issue 1 Published March 2009 Legal Notice This work is licensed under the Creative Commons Attribution 2.0 UK: England & Wales License. To view a copy of this license, visit http://creativecommons.org/licenses/by/2.0/uk/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. This license means you are free: • to copy, distribute, display, and perform the work • to make derivative works under the following conditions: • Attribution. You must give the original author, Jeremy Bennett of Embecosm (www.embecosm.com), credit; • For any reuse or distribution, you must make clear to others the license terms of this work; • Any of these conditions can be waived if you get permission from the copyright holder, Embecosm; and • Nothing in this license impairs or restricts the author's moral rights. The software for the SystemC cycle accurate model written by Embecosm and used in this document is licensed under the GNU General Public License (GNU General Public License). For detailed licensing information see the file COPYING in the source code. Embecosm is the business name of Embecosm Limited, a private limited company registered in England and Wales. Registration number 6577021. ii Copyright © 2009 Embecosm Limited Table of Contents 1. Introduction ................................................................................................................ 1 1.1. Why Use Cycle Accurate Modeling .................................................................... 1 1.2. Target Audience ................................................................................................ 1 1.3. Open Source ..................................................................................................... 2 1.4. Further Sources of Information ......................................................................... 2 1.4.1. -

Cloud Computing & Big Data
Cloud Computing & Big Data PARALLEL & SCALABLE MACHINE LEARNING & DEEP LEARNING Ph.D. Student Chadi Barakat School of Engineering and Natural Sciences, University of Iceland, Reykjavik, Iceland Juelich Supercomputing Centre, Forschungszentrum Juelich, Germany @MorrisRiedel LECTURE 11 @Morris Riedel @MorrisRiedel Big Data Analytics & Cloud Data Mining November 10, 2020 Online Lecture Review of Lecture 10 –Software-As-A-Service (SAAS) ▪ SAAS Examples of Customer Relationship Management (CRM) Applications (PAAS) (introducing a growing range of machine (horizontal learning and scalability artificial enabled by (IAAS) intelligence Virtualization capabilities) in Clouds) [5] AWS Sagemaker [4] Freshworks Web page [3] ZOHO CRM Web page modfied from [2] Distributed & Cloud Computing Book [1] Microsoft Azure SAAS Lecture 11 – Big Data Analytics & Cloud Data Mining 2 / 36 Outline of the Course 1. Cloud Computing & Big Data Introduction 11. Big Data Analytics & Cloud Data Mining 2. Machine Learning Models in Clouds 12. Docker & Container Management 13. OpenStack Cloud Operating System 3. Apache Spark for Cloud Applications 14. Online Social Networking & Graph Databases 4. Virtualization & Data Center Design 15. Big Data Streaming Tools & Applications 5. Map-Reduce Computing Paradigm 16. Epilogue 6. Deep Learning driven by Big Data 7. Deep Learning Applications in Clouds + additional practical lectures & Webinars for our hands-on assignments in context 8. Infrastructure-As-A-Service (IAAS) 9. Platform-As-A-Service (PAAS) ▪ Practical Topics 10. Software-As-A-Service -

Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide
Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS: AWS Technical Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Table of Contents Abstract and introduction .................................................................................................................... i Abstract .................................................................................................................................... 1 Introduction .............................................................................................................................. 1 Personas for an ML platform ............................................................................................................... 2 AWS accounts .................................................................................................................................... 3 Networking architecture ..................................................................................................................... -

Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework
Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework Analytics Lens: AWS Well-Architected Framework Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Analytics Lens AWS Well-Architected Framework Table of Contents Abstract ............................................................................................................................................ 1 Abstract .................................................................................................................................... 1 Introduction ...................................................................................................................................... 2 Definitions ................................................................................................................................. 2 Data Ingestion Layer ........................................................................................................... 2 Data Access and Security Layer ............................................................................................ 3 Catalog and Search Layer ................................................................................................... -

Code Profilers Choosing a Tool for Analyzing Performance
Code Profilers Choosing a Tool for Analyzing Performance Freescale Semiconductor Author, Rick Grehan Document Number: CODEPROFILERWP Rev. 0 11/2005 A profiler is a development tool that lets you look inside your application to see how each component—each routine, each block, sometimes each line and even each instruction—performs. You can find and correct your application’s bottlenecks. How do they work this magic? CONTENTS 1. Passive Profilers ...............................................3 6. Comparing Passive and Active 1.1 How It Is Done—PC Sampling ................4 Profilers .................................................................9 1.2 It Is Statistical ................................................4 6.1 Passive Profilers—Advantages ...............9 6.2 Passive Profilers—Disadvantages .........9 2. Active Profilers ...................................................4 6.3 Active Profilers—Advantages ................10 2.1 Methods of Instrumentation .....................5 6.4 Active Profilers—Disadvantages ..........11 3. Source Code Instrumentation ...................5 7. Conclusion .........................................................12 3.1 Instrumenting by Hand ..............................5 8. Addendum: Recursion and 4. Object Code Instrumentation ....................5 Hierarchies ........................................................12 4.1 Direct Modification .......................................6 4.2 Indirect Modification ...................................7 5. Object Instrumentation vs. Source Instrumentation -

Debugging and Profiling with Arm Tools
Debugging and Profiling with Arm Tools [email protected] • Ryan Hulguin © 2018 Arm Limited • 4/21/2018 Agenda • Introduction to Arm Tools • Remote Client Setup • Debugging with Arm DDT • Other Debugging Tools • Break • Examples with DDT • Lunch • Profiling with Arm MAP • Examples with MAP • Obtaining Support 2 © 2018 Arm Limited Introduction to Arm HPC Tools © 2018 Arm Limited Arm Forge An interoperable toolkit for debugging and profiling • The de-facto standard for HPC development • Available on the vast majority of the Top500 machines in the world • Fully supported by Arm on x86, IBM Power, Nvidia GPUs and Arm v8-A. Commercially supported by Arm • State-of-the art debugging and profiling capabilities • Powerful and in-depth error detection mechanisms (including memory debugging) • Sampling-based profiler to identify and understand bottlenecks Fully Scalable • Available at any scale (from serial to petaflopic applications) Easy to use by everyone • Unique capabilities to simplify remote interactive sessions • Innovative approach to present quintessential information to users Very user-friendly 4 © 2018 Arm Limited Arm Performance Reports Characterize and understand the performance of HPC application runs Gathers a rich set of data • Analyses metrics around CPU, memory, IO, hardware counters, etc. • Possibility for users to add their own metrics Commercially supported by Arm • Build a culture of application performance & efficiency awareness Accurate and astute • Analyses data and reports the information that matters to users insight • Provides simple guidance to help improve workloads’ efficiency • Adds value to typical users’ workflows • Define application behaviour and performance expectations Relevant advice • Integrate outputs to various systems for validation (e.g. -

All Services Compute Developer Tools Machine Learning Mobile
AlL services X-Ray Storage Gateway Compute Rekognition d Satellite Developer Tools Amazon Sumerian Athena Machine Learning Elastic Beanstalk AWS Backup Mobile Amazon Transcribe Ground Station EC2 Servertess Application EMR Repository Codestar CloudSearch Robotics Amazon SageMaker Customer Engagement Amazon Transtate AWS Amplify Amazon Connect Application Integration Lightsail Database AWS RoboMaker CodeCommit Management & Governance Amazon Personalize Amazon Comprehend Elasticsearch Service Storage Mobile Hub RDS Amazon Forecast ECR AWS Organizations Step Functions CodeBuild Kinesis Amazon EventBridge AWS Deeplens Pinpoint S3 AWS AppSync DynamoDe Amazon Textract ECS CloudWatch Blockchain CodeDeploy Quicksight EFS Amazon Lex Simple Email Service AWS DeepRacer Device Farm ElastiCache Amazont EKS AWS Auto Scaling Amazon Managed Blockchain CodePipeline Data Pipeline Simple Notification Service Machine Learning Neptune FSx Lambda CloudFormation Analytics Cloud9 AWS Glue Simple Queue Service Amazon Polly Business Applications $3 Glacer AR & VR Amazon Redshift SWF Batch CloudTrail AWS Lake Formation Server Migration Service lot Device Defender Alexa for Business GuardDuty MediaConnect Amazon QLDB WorkLink WAF & Shield Config AWS Well. Architected Tool Route 53 MSK AWS Transfer for SFTP Artifact Amazon Chime Inspector lot Device Management Amazon DocumentDB Personal Health Dashboard C MediaConvert OpsWorks Snowball API Gateway WorkMait Amazon Macie MediaLive Service Catalog AWS Chatbot Security Hub Security, Identity, & Internet of Things loT