Large Scale Character Classification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KSEB Junior Assistant Cashier 1996.Pmd
KSEB Junior Assistant/Cashier 1996 1. Who is the recipient of Nobel Prize 1998 for Literature? (a) Seamus Heaney (b) Salman Rushdie (c) Promodya Antora Toer (c) Fritj of Kapra (e) Saramago 2. One of the places where Total Solar Eclipse was visible on 24 October 1995 was Neem Ka Thana. Which State does this place belong to? (a) West Bengal (b) Rajasthan (c) Gujarat (d) Orissa (e) None of these 3. SDR is related to ———— (a) IMF (b) EEC (c) UNICEF (d) ILO (e) None of these 4. The Headquarters of ILO is at ———— (a) Brussels (b) the Hague (c) Geneva (d) Washington (e) None of these 5. Which of the following countries does not belong to OPEC? (a) Kuwait (b) Libya (c) Qatar (d) UAE (e) None of these 6. The Secretary General of the UNO at present is ———— (a) Dag Hammarskjold (b) Boutros Boutros Ghali (c) Kurt Waldheim (d) U Thant (e) Kofi Annan 7. The country expelled from the Commonwealth in 1995 was ———— (a) Nigeria (b) Zambia (c) Namibia (d) Algeria (e) None of these 8. The largest planet in the solar system is ———— (a) Saturn (b) Jupiter (c) Mercury (d) Mars (e) None of these 9. The first man-made satellite was launched into space by the Soviet Union in the year ———— (a) 1961 (b) 1959 (c) 1957 (d) 1962 (e) None of these 10. The first living being launched into space was a ———— (a) man (b) bird (c) monkey (d) dog (e) None of these 11. The longest night in the northern hemisphere is on ———— (a) 21 March (b) 21 June (c) 22 December (d) 23 September (e) None of these 12. -

List of Books 2018 for the Publishers.Xlsx
LIST I LIST OF STATE BARE ACTS TOTAL STATE BARE ACTS 2018 PRICE (in EDITION SL.No. Rupees) COPIES AUTHOR/ REQUIRED PRICE FOR EDN / YEAR PUBLISHER EACH COPY APPROXIMATE K.G. 1 Abkari Laws in Kerala Rajamohan/Ar latest 898 5 4490 avind Menon Govt. 2 Account Code I Kerala latest 160 10 1600 Publication Govt. 3 Account Code II Kerala latest 160 10 1600 Publication Suvarna 4 Advocates Act latest 790 1 790 Publication Advocate's Welfare Fund Act George 5 & Rules a/w Advocate's Fees latest 120 3 360 Johnson Rules-Kerala Arbitration and Conciliation 6 Rules (if amendment of 2016 LBC latest 80 5 400 incorporated) Bhoo Niyamangal Adv. P. 7 latest 1500 1 1500 (malayalam)-Kerala Sanjayan 2nd 8 Biodiversity Laws & Practice LBC 795 1 795 2016 9 Chit Funds-Law relating to LBC 2017 295 3 885 Chitty/Kuri in Kerala-Laws 10 N Y Venkit 2012 160 1 160 on Christian laws in Kerala Santhosh 11 2007 520 1 520 Manual of Kumar S Civil & Criminal Laws in 12 LBC 2011 250 1 250 Practice-A Bunch of Civil Courts, Gram Swamy Law 13 Nyayalayas & Evening 2017 90 2 180 House Courts -Law relating to Civil Courts, Grama George 14 Nyayalaya & Evening latest 130 3 390 Johnson Courts-Law relating to 1 LIST I LIST OF STATE BARE ACTS TOTAL STATE BARE ACTS 2018 PRICE (in EDITION SL.No. Rupees) COPIES AUTHOR/ REQUIRED PRICE FOR EDN / YEAR PUBLISHER EACH COPY APPROXIMATE Civil Drafting and Pleadings 15 With Model / Sample Forms LBC 2016 660 1 660 (6th Edn. -

K. Satchidanandan
1 K. SATCHIDANANDAN Bio-data: Highlights Date of Birth : 28 May 1946 Place of birth : Pulloot, Trichur Dt., Kerala Academic Qualifications M.A. (English) Maharajas College, Ernakulam, Kerala Ph.D. (English) on Post-Structuralist Literary Theory, University of Calic Posts held Consultant, Ministry of Human Resource, Govt. of India( 2006-2007) Secretary, Sahitya Akademi, New Delhi (1996-2006) Editor (English), Sahitya Akademi, New Delhi (1992-96) Professor, Christ College, Irinjalakuda, Kerala (1979-92) Lecturer, Christ College, Irinjalakuda, Kerala (1970-79) Lecturer, K.K.T.M. College, Pullut, Trichur (Dt.), Kerala (1967-70) Present Address 7-C, Neethi Apartments, Plot No.84, I.P. Extension, Delhi 110 092 Phone :011- 22246240 (Res.), 09868232794 (M) E-mail: [email protected] [email protected] [email protected] Other important positions held 1. Member, Faculty of Languages, Calicut University (1987-1993) 2. Member, Post-Graduate Board of Studies, University of Kerala (1987-1990) 3. Resource Person, Faculty Improvement Programme, University of Calicut, M.G. University, Kottayam, Ambedkar University, Aurangabad, Kerala University, Trivandrum, Lucknow University and Delhi University (1990-2004) 4. Jury Member, Kerala Govt. Film Award, 1990. 5. Member, Language Advisory Board (Malayalam), Sahitya Akademi (1988-92) 6. Member, Malayalam Advisory Board, National Book Trust (1996- ) 7. Jury Member, Kabir Samman, M.P. Govt. (1990, 1994, 1996) 8. Executive Member, Progressive Writers’ & Artists Association, Kerala (1990-92) 9. Founder Member, Forum for Secular Culture, Kerala 10. Co-ordinator, Indian Writers’ Delegation to the Festival of India in China, 1994. 11. Co-ordinator, Kavita-93, All India Poets’ Meet, New Delhi. 12. Adviser, ‘Vagarth’ Poetry Centre, Bharat Bhavan, Bhopal. -

Library Stock.Pdf
Acc.No. Title Author Publication Samuhyashasthra Vidyarthimithram, 1 Vidhyabyasathinte saithadhika Rajeshwary V.P Kottayam Adisthanangal-1 Samuhyashasthra Vidyarthimithram, 2 Vidhyabyasathinte saithadhika Rajeshwary V.P Kottayam Adisthanangal-1 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 3 saithadhika Rajeshwary V.P Kottayam Adisthanangal-1 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 4 saithadhika Rajeshwary V.P Kottayam Adisthanangal-1 Adhunika Vidhyabyasathinte Vidyarthimithram, 5 Rajeshwary V.P Saithathikadisthanangal-2 Kottayam Adhunika Vidhyabyasathinte Vidyarthimithram, 6 Rajeshwary V.P Saithathikadisthanangal-2 Kottayam MalayalaBasha Bodhanathinte Vidyarthimithram, 7 Saithathikadisthanam (Pradhesika Rajapan Nair P.K Kottayam Bashabothanam-1) MalayalaBasha Bodhanathinte Vidyarthimithram, 8 Saithathikadisthanam (Pradhesika Rajapan Nair P.K Kottayam Bashabothanam-1) Samuhyashasthra Vidyarthimithram, 9 Vidhyabyasathinte saithadhika Thomas R.S Kottayam Adisthanangal-2 Samuhyashasthra Vidyarthimithram, 10 Vidhyabyasathinte saithadhika Thomas R.S Kottayam Adisthanangal-2 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 11 saithadhika Rajeshwary V.P Kottayam Adisthanangal-2 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 12 saithadhika Rajeshwary V.P Kottayam Adisthanangal-2 Samaniashasthra Vidhyabyasathinte Vidyarthimithram, 13 saithadhika Rajeshwary V.P Kottayam Adisthanangal-2 MalayalaBasha Bodhanathinte Vidyarthimithram, 14 Saithathikadisthanam (Pradhesika Rajapan Nair P.K Kottayam Bashabothanam-2) MalayalaBasha -

SL NO ROLL APP NAME FATHERNAME DOB CENTRE 1 9212000638 a AMBILY a NARAYANAN KUTTTY 17-11-1970 Thrissur 2 9001000376 a IMMACULATE
PROVISIONALLY ADMITTED CANDIDATES LIST FOR SUB‐INSPECTORS IN CPOs, ASSISTANT SUB‐INSPECTORS IN CISF AND INTELLIGENCE OFFICER IN NCB EXAMINATION, 2011 TO BE HELD ON 28.08. -

English Books in Ksa Library
Author Title Call No. Moss N S ,Ed All India Ayurvedic Directory 001 ALL/KSA Jagadesom T D AndhraPradesh 001 AND/KSA Arunachal Pradesh 001 ARU/KSA Bullock Alan Fontana Dictionary of Modern Thinkers 001 BUL/KSA Business Directory Kerala 001 BUS/KSA Census of India 001 CEN/KSA District Census handbook 1 - Kannanore 001 CEN/KSA District Census handbook 9 - Trivandrum 001 CEN/KSA Halimann Martin Delhi Agra Fatepur Sikri 001 DEL/KSA Delhi Directory of Kerala 001 DEL/KSA Diplomatic List 001 DIP/KSA Directory of Cultural Organisations in India 001 DIR/KSA Distribution of Languages in India 001 DIS/KSA Esenov Rakhim Turkmenia :Socialist Republic of the Soviet Union 001 ESE/KSA Evans Harold Front Page History 001 EVA/KSA Farmyard Friends 001 FAR/KSA Gazaetteer of India : Kerala 001 GAZ/KSA Gazetteer of India 4V 001 GAZ/KSA Gazetteer of India : kerala State Gazetteer 001 GAZ/KSA Desai S S Goa ,Daman and Diu ,Dadra and Nagar Haveli 001 GOA/KSA Gopalakrishnan M,Ed Gazetteers of India: Tamilnadu State 001 GOP/KSA Allward Maurice Great Inventions of the World 001 GRE/KSA Handbook containing the Kerala Government Servant’s 001 HAN/KSA Medical Attendance Rules ,1960 and the Kerala Governemnt Medical Institutions Admission and Levy of Fees Rules Handbook of India 001 HAN/KSA Ker Alfred Heros of Exploration 001 HER/KSA Sarawat H L Himachal Pradesh 001 HIM/KSA Hungary ‘77 001 HUN/KSA India 1990 001 IND/KSA India 1976 : A Reference Annual 001 IND/KSA India 1999 : A Refernce Annual 001 IND/KSA India Who’s Who ,1972,1973,1977-78,1990-91 001 IND/KSA India :Questions -

Ac Name Ac Addr1 Ac Addr2 Ac Addr3 Chandy Joseph
AC_NAME AC_ADDR1 AC_ADDR2 AC_ADDR3 CHANDY JOSEPH MOONJATTUPARAMBIL HOUSE MOONJATTUPARAMBIL HOUSEPONGA,KAINAKARY SHARON FELLOWSHIP CHURCH ASOKAPURAM ALUVA OPERATION BY ANY TWO JOINTLY ANTO M L AMBALLUR P O ALAGAPPANAGAR BABY DAVIS C/O P A DAVIS P0AYYAPPILLY HOUSE PO PUDUKKAD JOMON K JOSEPH KANJIRATHINGAL HOUSE P O PUDUKAD SHANTY C L CHUKKIRI HOUSE PUDUKAD SREEKUTTY T S D/O SUNDARAN T B THOTTIPARAMBIL HOUSE CHITTISSERY P O OMANA P C W/O KUNJAPPAN PALIYAMPARAMBIL HOUSE KUMBIDY POOVATHUSSERY R RAMESH FUTURE ELECTRONIC SYSTEM MADATHIL P O MALA KOTTAMURY FRANCIS JACOB THARAYIL HOUSE ANNALLUR P O JOFFY K J S/O.JOHNY KALAPURAKKAL HOUSE MALAPALLIPPURAM.P.O. K S SUJILKUMAR KIZHAKKANOTE HOUSE ASHTAMICHIRA ABDUL KHADER P K S/O ABDUL MUSALIAR POKKOKKATH HOUSE ATTUPURAM. PUNNAYURKULAM.P.O. LAMESH T M S/O MADHAVAN THAIPARAMBIL HOUSE VELIYANCODE P O MALAPPURAM DT SALJU W/O DHANAKESWARAN CHALIL HOUSE PURANGU PO SANJAYAN T S THOTTAPATTUNJALIL HOUSE S VAZHAKUALM SOORAJ K S/O K PADMANABHAN ARATHI, THERU, AZHIKODE KANNUR T V RAFEEK THAHIRA MANZIL POOTHAPPARA,AZHIKODE P OKANNUR ANIL KUMAR.G. NO.13,11TH CROSS ANEPALAYA MAIN ROAD,ADUGODIBANGALORE PO 560030. B.CLUB C/O KRISTU JYOTHI COLLEGE BIJU 10 th CROSS MAGADI ROAD BANGALORE -23 CHRISTOPHER DSOUZA 148/1,GOKUL SUDHA,M M ROAD, FRAZER TOWN,BANGLORE 5. K A FRANCIS NO 120/2, KULANTHAPPA GARDENADUGODI ANEPALAYAM BANGALORE KARTEEK SHARMA S-3,CRYSTAL VIEW APTS,62 ST JOHNS ROAD, BANGALORE-560042 MARY FRANCINA GOOD SHEPHERD HOME MUSEUM ROAD BANGALORE 25 RIZWAN AMEER 481,5TH MAIN 11 STAGE,RAJ MAHA-L VILAS EXTN,DOLLARS COLONYBANGALORE-94 SHRUTI C SEBASTIAN ASHRAY, NO.110, II CROSS, BYAPPANAHALLI NEW EXT. -

Harsham – “Happiness Redefined” Geriatric Care Programme
Harsham – “Happiness Redefined” Geriatric Care Programme Harsham - “Happiness Redefined” An Elderly Care program from Kudumbasree Funding Partner: Kerala Academy for Skill Execellence (KASE) Implemented by: Hindustan Latex Family Planning Promotion Trust (HLFPPT) (A unit of HLL Lifecare Ltd) Harsham – “Happiness Redefined” 2 Harsham – “Happiness Redefined” 3 Since its inception, Kudumbashree Mission have been in the forefront, striving to wipe off poverty from Kerala and make the lives of the people get better in all senses. For the last 20 years, Kudumbashree had been actively functioning in the social scenario of Kerala framing and implementing innovative projects. By making way for the micro entrepreneurs to launch their own enterprises, we envisaged helping them find livelihood of their own and change the lives of many in a positive way. Kudumbashree Mission always aim to find opportunities for livelihood for its members so as to assist them earn better income, identifying the right opportunities. Two years back, we had initiated Harsham programme realizing the opportunities existing in the service sector of Kerala. As we all know, the availability of reliable and trained persons in elderly care is relatively less in Kerala. Those whose are ready to provide this service always would have greater job opportunities. We identified the opportunity in this and launched the Harsham Project for geriatric care. Harsham programme aims at providing intensive training of 15 days to women and equip them to provide service in geriatric care sector. The training for the caregivers was provided with the assistance of doctors, nurses and hospital management in selected hospitals in the state. -

Accused Persons Arrested in Thrissur Rural District from 21.06.2020To27.06.2020
Accused Persons arrested in Thrissur Rural district from 21.06.2020to27.06.2020 Name of Name of the Name of Place at Date & Arresting Court at Sl. Name of the Age & Cr. No & Sec Police the father Address of Accused which Time of Officer, which No. Accused Sex of Law Station of Accused Arrested Arrest Rank & accused Designation produced 1 2 3 4 5 6 7 8 9 10 11 THIYYADI HOUSE, 221/2020 U/s PERINGOTTUKAR 21-06-2020 ANTHIKKA VISWAMBH 65, ANTHIKKA 341, 343, 441, K.J JINESH JFCM NO II VELU A at 14.00 D (Thrissur 1 ARAN Male D 447, 294(b), SI OF POLICE THRISSUR DESOM,KIZHAKK Hrs Rural) 506 IPC UMURI(V) ELANTHARA VADANAP 21-06-2020 750/2020 U/s GOPIKUMAR UNNIKRIS 36, HOUSE VADANAPP PILLY BAILED BY BABU at 09:30 118(e) of KP SI OF POLICE 2 HNAN Male MANGALAM DAM ILLY (Thrissur POLICE Hrs Act (GRADE ) PALAKKAD Rural) 548/2020 U/s 188, 269 IPC & 118(e) of CHALI HOUSE, KP Act & Sec. VARANTH 21-06-2020 CHITHARAN 25, NAYARANGADI MUTTITHA 4(2)(d) r/w 5 ARAPPILLY BAILED BY SHARON SATHYAN at 09:50 JAN 3 Male DESOM, KALLUR DI of Kerala (Thrissur POLICE Hrs SI OF POLICE VILLAGE Epidemic Rural) Diseases Ordinance 2020 1033/2020 NARAYANANKAT ARUN.G 21-06-2020 U/s 118(e) of KODAKAR 24, TIL (H) ALATHUR ISHO BAILED BY SHIJU SHIBU ALATHOOR at 10:05 KP Act & 5 A (Thrissur 4 Male ANANDHAPURA KODAKARA POLICE Hrs OF KEDO Rural) M PS 2020. -

PSC Asked Morethan 10 Times Que.Pmd
ABBREVIATIONS COFEPOSA : Conservation of Foreign Exchange and Prevention of Smuggling Act CARE : Co-operative for American Relief Everywhere CHOGM : Commonwealth Heads of Government Meeting CSO : Central Statistical Organisation CVRDE : Combat Vehicles Research Development Establishment EPZ : Export Processing Zone ESMA : Essential Services Maintenance Act FEMA : Foreign Exchange Management Act GATE : Graduate Aptitude Test in Engineering HUDCO : Housing and Urban Development Corporation SUPERLATIVES Largest delta : Sunderban Largest diamond : The Cullinan Largest archipelago : Indonesia Smallest bird : Humming Bird Largest library : United States Library of Congress, Washington (more than 59,000,000 items) Largest sea bird : Albatross Largest sea : South China Sea Hottest place : Azizia (Libya, Africa 580c (1360F)) Largest peninsula : Arabia Largest museum : American Museum of Natural History, New York City Longest mountain range : Andes, South America - 8,800 km long Deepest lake : Baikal (Siberia); Average depth 701 metre Largest gulf : Gulf of Mexico Largest desert : Sahara (Africa) Largest creature : Blue Whale PARLIAMENTS COUNTRY PARLIAMENT USA - Congress Sweden - Riksdag Russia - Duma Japan - Diet Denmark - Folketing Israel - knesset China - National Peoples Congress Iran - Majlis Nepal - National Panchayat Poland - Sejm Afghanistan - Shora Norway - Storting Spain - Crotes Switzerland - Federal Assembly Branches of Science Eugenics : is the study of ways in which the physical and mental characteristic of the human race may be improved. Modern elemination of genetic diseases. Cryogenics : The science dealing with the production, control and application of very low temperature. Metallurgy : It is the process of extracting metals from their ores. Hydropathy : The cure of disease by the internal and external use of water. Heliotherapy : It is the method of treating diseases by sunlight. -
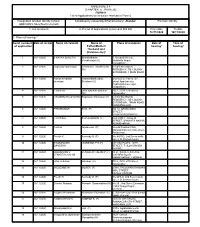
ANNEXURE 5.8 (CHAPTER V , PARA 25) FORM 9 List of Applications For
ANNEXURE 5.8 (CHAPTER V , PARA 25) FORM 9 List of Applications for inclusion received in Form 6 Designated location identity (where Constituency (Assembly/£Parliamentary): Alandur Revision identity applications have been received) 1. List number@ 2. Period of applications (covered in this list) From date To date 16/11/2020 16/11/2020 3. Place of hearing * Serial number$ Date of receipt Name of claimant Name of Place of residence Date of Time of of application Father/Mother/ hearing* hearing* Husband and (Relationship)# 1 16/11/2020 B KAVYA SHRUTHI Bharanidharan 7, Goodwill Avenue, Varadharajan (F) Maxworth Nagar, Kolapakkam, , 2 16/11/2020 Raghavan Srinivasan CHANDRA RAGHAVAN G1 SALMA ROYAL (W) RESIDENCY, SB COLONY EXTENSION, 1 MAIN ROAD , , 3 16/11/2020 Ramya srivatsan KannanMuthusamy plot no E-2, Flat no, S3 , srivatsan Srivatsan (H) srivari Apartnments, Radhakrishnan nagar, kolapakkam, , 4 16/11/2020 R sukumar usha sukumar sukumar AS.2, 35/18 27th street, (W) nanganallur, , 5 16/11/2020 CHANDRA RAGHAVAN Raghavan Srinivasan (H) G1 SALMA ROYAL RESIDENCY, SB COLONY EXTENSION , 1MAIN ROAD NANGANALLUR, , 6 16/11/2020 PREMKUMAR SIVA (F) NO 12, ARUMUGAM STREET, PAZHAVANTHANGAL, , 7 16/11/2020 R RITHIGA S RAJENDRAN (F) PLOT NO 3,, KAVERI STREET, BHARATH NAGAR, ADAMBAKKAM, , 8 16/11/2020 Femina Jayaseelan (F) No.6 B,Shankar Flats, Mariyamman koil cross street, Pallavaram, , 9 16/11/2020 Preethi K Kennedy G (F) No. 44/5-D, 2nd Seven wells street, St.thomas mount, , 10 16/11/2020 SHOBANASRI GANESAN P S (F) 4D VIBA FLATS, 12TH GANESAN STREET, -

Annual Report Ind 2016
ANNUAL REPORT IND 2016 KASARAGOD KANNUR WAYANAD KOZHIKODE MALAPPURAM PALAKKAD Palakkad THRISSUR ERNAKULAM IDUKKI Kochi KOTTAYAM Kotayam Allappuzha ALLAPPUZHA PATHANAMTHITTA KOLLAM Kollam THIRUVANANTHAPURAM Thiruvananthapuram [Trivandrum] WWF’s mission To stop the degradatio of our plaets atural eiroet, and build a future in which huas lie i haroy ith ature i | Page ACKNOWLEDGEMENT We would like to take this opportunity to thank one and all who have contributed in some way or the other, directly or indirectly, to help us fulfill our mission of nature conservation and environment protection, mainly with regard to the needs of Kerala State. We express our special thanks and regards to Mr. Ravi Singh, Secretary General & CEO who has always given ear to all our requests and supported us in immense ways in fulfilling our mission well. Our special thanks goes to Dr. Sejal Worah, Programme Director who has always guided us with her advice and inputs. We extend our thanks to Mr. Karan Bhalla, Chief Operating Officer, Mr. Vivek Dayal, Director-Finance, Mr. Lovekesh Wadhwa, Director-Institutional Development, Gp. Cpt. Naresh Kapila, and Director-HR & Manpower. The support given by the other heads and staff at the Secretariat are also duly acknowledged, namely Ms. Vishaish Uppal, Dr.T.S. Panwar, Dr. Shekar Kumar Niraj, Ms. Moulika Arabhi, Mr. Vinod M. and others. We would like to place on record our most sincere thanks to Mr. G. Vijaya Raghavan, Chairman and Mr.C. Balagopal, Vice-Chairman of the Kerala State Advisory Board for all their guidance and support. Mr. A.V.George, Mr. Suresh Elamon, Mr.