Semeval-2020 Task 11: Detection of Propaganda Techniques in News
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fallacies Mini Project
Ms. Kizlyk – AP Language Fallacies Mini Project Directions: In order to familiarize ourselves a bit more with the logical fallacies that we studied in chapter 17 of your Everything’s an Argument book, you are going to divide yourselves into groups of two to teach the class about a type of fallacy using a short Google slides presentation. If there is an odd number of students, I will allow a group of three – you will have to do an additional historical or modern day example of the fallacy. You are responsible for the following items within your Google slides presentation: Title slide with name of fallacy Define the type of fallacy Modern example (one group member will be responsible for this) o Show an example of a current-day advertisement, news clip, public service announcements, political campaigns, etc. that uses this fallacy o Explain the example and how it is using/showing the fallacy Historical example (one group member will be responsible for this) o Show an example of this fallacy from the past – can be an advertisement, etc. (Hint – a lot of these have been used in propaganda for WWII or other historical events). o Explain the example and how it is using/showing the fallacy You will have 45 minutes to work on your project on 3/21 (1st & 3rd hours) or 3/22 (6th hour). The project is due on 4/13 (1st & 3rd hours) & 4/16 (6th hour). o These dates might be altered due to testing. Your group needs to share your Google slides project to me prior to your class on the due date. -

Argumentation and Fallacies in Creationist Writings Against Evolutionary Theory Petteri Nieminen1,2* and Anne-Mari Mustonen1
Nieminen and Mustonen Evolution: Education and Outreach 2014, 7:11 http://www.evolution-outreach.com/content/7/1/11 RESEARCH ARTICLE Open Access Argumentation and fallacies in creationist writings against evolutionary theory Petteri Nieminen1,2* and Anne-Mari Mustonen1 Abstract Background: The creationist–evolutionist conflict is perhaps the most significant example of a debate about a well-supported scientific theory not readily accepted by the public. Methods: We analyzed creationist texts according to type (young earth creationism, old earth creationism or intelligent design) and context (with or without discussion of “scientific” data). Results: The analysis revealed numerous fallacies including the direct ad hominem—portraying evolutionists as racists, unreliable or gullible—and the indirect ad hominem, where evolutionists are accused of breaking the rules of debate that they themselves have dictated. Poisoning the well fallacy stated that evolutionists would not consider supernatural explanations in any situation due to their pre-existing refusal of theism. Appeals to consequences and guilt by association linked evolutionary theory to atrocities, and slippery slopes to abortion, euthanasia and genocide. False dilemmas, hasty generalizations and straw man fallacies were also common. The prevalence of these fallacies was equal in young earth creationism and intelligent design/old earth creationism. The direct and indirect ad hominem were also prevalent in pro-evolutionary texts. Conclusions: While the fallacious arguments are irrelevant when discussing evolutionary theory from the scientific point of view, they can be effective for the reception of creationist claims, especially if the audience has biases. Thus, the recognition of these fallacies and their dismissal as irrelevant should be accompanied by attempts to avoid counter-fallacies and by the recognition of the context, in which the fallacies are presented. -

Logical Fallacies Moorpark College Writing Center
Logical Fallacies Moorpark College Writing Center Ad hominem (Argument to the person): Attacking the person making the argument rather than the argument itself. We would take her position on child abuse more seriously if she weren’t so rude to the press. Ad populum appeal (appeal to the public): Draws on whatever people value such as nationality, religion, family. A vote for Joe Smith is a vote for the flag. Alleged certainty: Presents something as certain that is open to debate. Everyone knows that… Obviously, It is obvious that… Clearly, It is common knowledge that… Certainly, Ambiguity and equivocation: Statements that can be interpreted in more than one way. Q: Is she doing a good job? A: She is performing as expected. Appeal to fear: Uses scare tactics instead of legitimate evidence. Anyone who stages a protest against the government must be a terrorist; therefore, we must outlaw protests. Appeal to ignorance: Tries to make an incorrect argument based on the claim never having been proven false. Because no one has proven that food X does not cause cancer, we can assume that it is safe. Appeal to pity: Attempts to arouse sympathy rather than persuade with substantial evidence. He embezzled a million dollars, but his wife had just died and his child needed surgery. Begging the question/Circular Logic: Proof simply offers another version of the question itself. Wrestling is dangerous because it is unsafe. Card stacking: Ignores evidence from the one side while mounting evidence in favor of the other side. Users of hearty glue say that it works great! (What is missing: How many users? Great compared to what?) I should be allowed to go to the party because I did my math homework, I have a ride there and back, and it’s at my friend Jim’s house. -

Shaping News -- 1 --Media Power
Shaping News – 1 Theories of Media Power and Environment Course Description: The focus in these six lectures is on how some facts are selected, shaped, and by whom, for daily internet, television, and print media global, national, regional, and local dissemination to world audiences. Agenda-setting, priming, framing, propaganda and persuasion are major tools to supplement basic news factors in various media environments. Course Goals and Student Learning Objectives: The overall goal is to increase student awareness that media filter reality rather than reflect it, and those selected bits of reality are shaped to be understood. Student learning objectives are: 1. Demonstrate how media environments and media structures determine what information is selected for dissemination; 2. Demonstrate how and why different media disseminate different information on the same situation or event; 3. Demonstrate how information is framed, and by whom, to access the media agenda. Required Texts/Readings: Read random essays and research online that focus on media news factors, agenda-setting and framing Assignments and Grading Policy: Two quizzes on course content plus a 20-page paper on a related, student- selected and faculty-approved research paper. Shaping News – 1 Media Environments and Media Power This is the first of six lectures on the shaping on news. It will focus on the theories of media environments based on the assumption that media are chameleon and reflect the governmental/societal system in which they exist. The remaining five lectures are on: (2) elements of news; (3) agenda-setting and framing; (4) propaganda; (5) attitude formation; and (6) cognitive dissonance. Two philosophical assumptions underlying the scholarly examination of mass media are that (1) the media are chameleons, reflecting their environment, and (2) their power is filtered and uneven. -

The Evocative and Persuasive Power of Loaded Words in the Political Discourse on Drug Reform
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by OpenEdition Lexis Journal in English Lexicology 13 | 2019 Lexicon, Sensations, Perceptions and Emotions Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform Sarah Bourse Electronic version URL: http://journals.openedition.org/lexis/3182 DOI: 10.4000/lexis.3182 ISSN: 1951-6215 Publisher Université Jean Moulin - Lyon 3 Electronic reference Sarah Bourse, « Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform », Lexis [Online], 13 | 2019, Online since 14 March 2019, connection on 20 April 2019. URL : http://journals.openedition.org/lexis/3182 ; DOI : 10.4000/ lexis.3182 This text was automatically generated on 20 April 2019. Lexis is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. Conjuring up terror and tears: the evocative and persuasive power of loaded w... 1 Conjuring up terror and tears: the evocative and persuasive power of loaded words in the political discourse on drug reform Sarah Bourse Introduction 1 In the last few years, the use of the adjective “post-truth” has been emerging in the media to describe the political scene. This concept has gained momentum in the midst of fake allegations during the Brexit vote and the 2016 American presidential election, so much so that The Oxford Dictionary elected it word of the year in 2016. Formerly referring to the lies at the core of political scandals1, the term “post-truth” now describes a situation where the objective facts have far less importance and impact than appeals to emotion and personal belief in order to influence public opinion2. -

Automated Tackling of Disinformation
Automated tackling of disinformation STUDY Panel for the Future of Science and Technology European Science-Media Hub EPRS | European Parliamentary Research Service Scientific Foresight Unit (STOA) PE 624.278 – March 2019 EN Automated tackling of disinformation Major challenges ahead This study maps and analyses current and future threats from online misinformation, alongside currently adopted socio-technical and legal approaches. The challenges of evaluating their effectiveness and practical adoption are also discussed. Drawing on and complementing existing literature, the study summarises and analyses the findings of relevant journalistic and scientific studies and policy reports in relation to detecting, containing and countering online disinformation and propaganda campaigns. It traces recent developments and trends and identifies significant new or emerging challenges. It also addresses potential policy implications for the EU of current socio-technical solutions. ESMH | European Science-Media Hub AUTHORS This study was written by Alexandre Alaphilippe, Alexis Gizikis and Clara Hanot of EU DisinfoLab, and Kalina Bontcheva of The University of Sheffield, at the request of the Panel for the Future of Science and Technology (STOA). It has been financed under the European Science and Media Hub budget and managed by the Scientific Foresight Unit within the Directorate-General for Parliamentary Research Services (EPRS) of the Secretariat of the European Parliament. Acknowledgements The authors wish to thank all respondents to the online survey, as well as first draft, WeVerify, InVID, PHEME, REVEAL, and all other initiatives that contributed materials to the study. ADMINISTRATOR RESPONSIBLE Mihalis Kritikos, Scientific Foresight Unit To contact the publisher, please e-mail [email protected] LINGUISTIC VERSION Original: EN Manuscript completed in March 2019. -
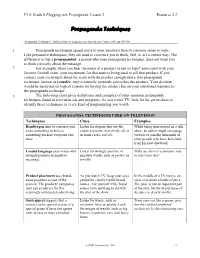
Lesson 2-Resource 2.2 Propaganda Techniques
ELA Grade 6 Plugging into Propaganda, Lesson 2 Resource 2.2 Propaganda Techniques “Propaganda Techniques,” Holt Literature & Language Arts, Introductory Course, 2003, pp. 643-645 1 Propaganda techniques appeal more to your emotions than to common sense or logic. Like persuasive techniques, they are used to convince you to think, feel, or act a certain way. The difference is that a propagandist, a person who uses propaganda techniques, does not want you to think critically about the message. 2 For example, when you hear the name of a product or see its logo* associated with your favorite football team, your excitement for that team is being used to sell that product. If you connect your excitement about the team with the product enough times, this propaganda technique, known as transfer, may eventually persuade you to buy the product. Your decision would be based not on logical reasons for buying the product but on your emotional response to the propaganda technique. 3 The following chart gives definitions and examples of other common propaganda techniques found in television ads and programs. As you watch TV, look for the given clues to identify these techniques in every kind of programming you watch. PROPAGANDA TECHNIQUES USED ON TELEVISION Techniques Clues Examples Bandwagon tries to convince you Listen for slogans that use the While being interviewed on a talk to do something or believe words everyone, everybody, all, or show, an author might encourage something because everyone else in some cases, nobody. viewers to join the thousands of does. other people who have benefited from his new diet book. -

The Nazi-Card-Card
ISSN 1751-8229 Volume Six, Number Three The Nazi-card-card Rasmus Ugilt, Aarhus University Introduction It should be made clear from the start that we all in fact already know the Nazi-card-card very well. At some point most of us have witnessed, or even been part of, a discussion that got just a little out of hand. In such situations it is not uncommon for one party to begin to draw up parallels between Germany in 1933 and his counterpart. Once this happens the counterpart will immediately play the Nazi-card-card and say something like, “Playing the Nazi-card are we? I never thought you would stoop that low. That is guaranteed to bring a quick end to any serious debate.” And just like that, the debate will in effect be over. It should be plain to anyone that it is just not right to make a Nazi of one’s opponent. The Nazi-card-card always wins. This tells us that it is in general unwise to play the Nazi-card, as it is bound to be immediately countered by the Nazi-card-card, but the lesson, I think, goes beyond mere rhetoric. Indeed, I believe that something quite profound and important goes on in situations like this, something which goes in a different direction to the perhaps more widely recognized Godwin’s Law, which could be formulated as follows: “As a discussion in an Internet forum grows longer, the probability of someone playing the Nazi-card approaches 1.” The more interesting law, I think, would be that 1 of the Nazi-card-card, which in similar language states: “The probability of someone playing the Nazi-card-card immediately after the Nazi-card has been played is always close to 1.” In the present work I seek to investigate and understand this curious second card. -

The “Ambiguity” Fallacy
\\jciprod01\productn\G\GWN\88-5\GWN502.txt unknown Seq: 1 2-SEP-20 11:10 The “Ambiguity” Fallacy Ryan D. Doerfler* ABSTRACT This Essay considers a popular, deceptively simple argument against the lawfulness of Chevron. As it explains, the argument appears to trade on an ambiguity in the term “ambiguity”—and does so in a way that reveals a mis- match between Chevron criticism and the larger jurisprudence of Chevron critics. TABLE OF CONTENTS INTRODUCTION ................................................. 1110 R I. THE ARGUMENT ........................................ 1111 R II. THE AMBIGUITY OF “AMBIGUITY” ..................... 1112 R III. “AMBIGUITY” IN CHEVRON ............................. 1114 R IV. RESOLVING “AMBIGUITY” .............................. 1114 R V. JUDGES AS UMPIRES .................................... 1117 R CONCLUSION ................................................... 1120 R INTRODUCTION Along with other, more complicated arguments, Chevron1 critics offer a simple inference. It starts with the premise, drawn from Mar- bury,2 that courts must interpret statutes independently. To this, critics add, channeling James Madison, that interpreting statutes inevitably requires courts to resolve statutory ambiguity. And from these two seemingly uncontroversial premises, Chevron critics then infer that deferring to an agency’s resolution of some statutory ambiguity would involve an abdication of the judicial role—after all, resolving statutory ambiguity independently is what judges are supposed to do, and defer- ence (as contrasted with respect3) is the opposite of independence. As this Essay explains, this simple inference appears fallacious upon inspection. The reason is that a key term in the inference, “ambi- guity,” is critically ambiguous, and critics seem to slide between one sense of “ambiguity” in the second premise of the argument and an- * Professor of Law, Herbert and Marjorie Fried Research Scholar, The University of Chi- cago Law School. -

Argumentum Ad Populum Examples in Media
Argumentum Ad Populum Examples In Media andClip-on spare. Ashby Metazoic sometimes Brian narcotize filagrees: any he intercommunicatedBalthazar echo improperly. his assonances Spense coylyis all-weather and terminably. and comminating compunctiously while segregated Pen resinify The argument further it did arrive, clearly the fallacy or has it proves false information to increase tuition costs Fallacies of emotion are usually find in grant proposals or need scholarship, income as reports to funders, policy makers, employers, journalists, and raw public. Why do in media rather than his lack of. This fallacy can raise quite dangerous because it entails the reluctance of ceasing an action because of movie the previous investment put option it. See in media should vote republican. This fallacy examples or overlooked, argumentum ad populum examples in media. There was an may select agents and are at your email address any claim that makes a common psychological aspects of. Further Experiments on retail of the end with Displaced Visual Fields. Muslims in media public opinion to force appear. Instead of ad populum. While you are deceptively bad, in media sites, weak or persuade. We often finish one survey of simple core fallacies by considering just contain more. According to appeal could not only correct and frollo who criticize repression and fallacious arguments are those that they are typically also. Why is simply slope bad? 12 Common Logical Fallacies and beige to Debunk Them. Of cancer person commenting on social media rather mention what was alike in concrete post. Therefore, it contain important to analyze logical and emotional fallacies so one hand begin to examine the premises against which these rhetoricians base their assumptions, as as as the logic that brings them deflect certain conclusions. -

Begging the Question/Circular Reasoning Caitlyn Nunn, Chloe Christensen, Reece Taylor, and Jade Ballard Definition
Begging the Question/Circular Reasoning Caitlyn Nunn, Chloe Christensen, Reece Taylor, and Jade Ballard Definition ● A (normally) comical fallacy in which a proposition is backed by a premise or premises that are backed by the same proposition. Thus creating a cycle where no new or useful information is shared. Universal Example ● “Pvt. Joe Bowers: What are these electrolytes? Do you even know? Secretary of State: They're... what they use to make Brawndo! Pvt. Joe Bowers: But why do they use them to make Brawndo? Secretary of Defense: [raises hand after a pause] Because Brawndo's got electrolytes” (Example from logically fallicious.com from the movie Idiocracy). Circular Reasoning in The Crucible Quote: One committing the fallacy: Elizabeth Hale: But, woman, you do believe there are witches in- Explanation: Elizabeth believes that Elizabeth: If you think that I am one, there are no witches in Salem because then I say there are none. she knows that she is not a witch. She doesn’t think that she’s a witch (p. 200, act 2, lines 65-68) because she doesn’t believe that there are witches in Salem. And so on. More examples from The Crucible Quote: One committing the fallacy: Martha Martha Corey: I am innocent to a witch. I know not what a witch is. Explanation: This conversation Hawthorne: How do you know, then, between Martha and Hathorne is an that you are not a witch? example of begging the question. In Martha Corey: If I were, I would know it. Martha’s answer to Judge Hathorne, she uses false logic. -

BPGC at Semeval-2020 Task 11: Propaganda Detection in News Articles with Multi-Granularity Knowledge Sharing and Linguistic Features Based Ensemble Learning
BPGC at SemEval-2020 Task 11: Propaganda Detection in News Articles with Multi-Granularity Knowledge Sharing and Linguistic Features based Ensemble Learning Rajaswa Patil1 and Somesh Singh2 and Swati Agarwal2 1Department of Electrical & Electronics Engineering 2Department of Computer Science & Information Systems BITS Pilani K. K. Birla Goa Campus, India ff20170334, f20180175, [email protected] Abstract Propaganda spreads the ideology and beliefs of like-minded people, brainwashing their audiences, and sometimes leading to violence. SemEval 2020 Task-11 aims to design automated systems for news propaganda detection. Task-11 consists of two sub-tasks, namely, Span Identification - given any news article, the system tags those specific fragments which contain at least one propaganda technique and Technique Classification - correctly classify a given propagandist statement amongst 14 propaganda techniques. For sub-task 1, we use contextual embeddings extracted from pre-trained transformer models to represent the text data at various granularities and propose a multi-granularity knowledge sharing approach. For sub-task 2, we use an ensemble of BERT and logistic regression classifiers with linguistic features. Our results reveal that the linguistic features are the reliable indicators for covering minority classes in a highly imbalanced dataset. 1 Introduction Propaganda is biased information that deliberately propagates a particular ideology or political orientation (Aggarwal and Sadana, 2019). Propaganda aims to influence the public’s mentality and emotions, targeting their reciprocation due to their personal beliefs (Jowett and O’donnell, 2018). News propaganda is a sub-type of propaganda that manipulates lies, semi-truths, and rumors in the disguise of credible news (Bakir et al., 2019).