Knowledge-Aware Dialogue Generation Via Hierarchical Infobox
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Silicon Valley of the East
August 2017 henhenzhen SSThe Silicon Valley of the East August 2017 WeChat: Paper online: PAPER MAGAZINE PAPER www.neo-ads.com/paper 05 cover story 24 star chef Shenzhen used to be a backward fishing 25 yummy village. Today it is a bustling metropolis in South China, with plans to surpass the Silicon Valley in the near future. Paper Magazine 27 cheers explores why Shenzhen will replace Silicon Valley as the technology hub of the world. 28 cru Contact Tel: (8620) 8365 2811 08 city window 30 out n about Email: [email protected] Chief Operating Officer: LC Chau 10 arts & events 32 mice Director: Italiana Granni Consulting Director: Allan Au 12 fortune 34 living Editing Consultant: May Guan Editor in Chief: William Chia 14 jetsetter 34 cotchin Guest Editor: Ben Chu Financial Controller: Takuto Other than tech companies like Google 35 education Marketing Director: Shirley Tse and Facebook, Silicon Valley also has some Marketing Manager: interesting museums, places of attraction and 36 supremos Ambro Chow, Purple Liu cafes. Paper Magazine explores these quirky Designer: Joanna Kong places in Silicon Valley, every tech geek’s Paper Magazine caught up with renowned Publication Co-coordinator: heaven. mixed media artist Terry Dixon as he was Nana Cheung in Guangzhou for his inaugural exhibition Photographer: Luciano Kelly, Leona 16 auto at Redtory. The artist shared with us his inspirations for his artwork. Contributors: 18 eureka Allan CW Au, Anna G, Charmmy Choi, 38 destination Gregory Louraichi, GiGi Chik, 19 muse Jessie Huang, John Chu, Kenny Tan, 40 bulletin Kee Lee, Lena Liu, Peter Fenton, 20 fighting fit Roy Moorfield, Sukanya Mukherjee, 42 diary Yuyao.K. -

1St China Onscreen Biennial
2012 1st China Onscreen Biennial LOS ANGELES 10.13 ~ 10.31 WASHINGTON, DC 10.26 ~ 11.11 Presented by CONTENTS Welcome 2 UCLA Confucius Institute in partnership with Features 4 Los Angeles 1st China Onscreen UCLA Film & Television Archive All Apologies Biennial Academy of Motion Picture Arts and Sciences Are We Really So Far from the Madhouse? Film at REDCAT Pomona College 2012 Beijing Flickers — Pop-Up Photography Exhibition and Film Seeding cross-cultural The Cremator dialogue through the The Ditch art of film Double Xposure Washington, DC Feng Shui Freer and Sackler Galleries of the Smithsonian Institution Confucius Institute at George Mason University Lacuna — Opening Night Confucius Institute at the University of Maryland The Monkey King: Uproar in Heaven 3D Confucius Institute Painted Skin: The Resurrection at Mason 乔治梅森大学 孔子学院 Sauna on Moon Three Sisters The 2012 inaugural COB has been made possible with Shorts 17 generous support from the following Program Sponsors Stephen Lesser The People’s Secretary UCLA Center for Chinese Studies Shanghai Strangers — Opening Night UCLA Center for Global Management (CGM) UCLA Center for Management of Enterprise in Media, Entertainment and Sports (MEMES) Some Actions Which Haven’t Been Defined Yet in the Revolution Shanghai Jiao Tong University Chinatown Business Improvement District Mandarin Plaza Panel Discussion 18 Lois Lambert of the Lois Lambert Gallery Film As Culture | Culture in Film Queer China Onscreen 19 Our Story: 10 Years of Guerrilla Warfare of the Beijing Queer Film Festival and -

Cloud Village Inc. (A Company Incorporated in the Cayman Islands with Limited Liability)
Disclaimer Statement The Stock Exchange of Hong Kong Limited and the Securities and Futures Commission take no responsibility for the contents of this Post Hearing Information Pack, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this Post Hearing Information Pack. Post Hearing Information Pack of Cloud Village Inc. (A company incorporated in the Cayman Islands with limited liability) (the “Company”) WARNING The publication of this Post Hearing Information Pack is required by The Stock Exchange of Hong Kong Limited (the “Stock Exchange”) and the Securities and Futures Commission solely for the purpose of providing information to the public in Hong Kong. This Post Hearing Information Pack is in draft form. The information contained in it is incomplete and is subject to change which can be material. By viewing this document, you acknowledge, accept and agree with the Company, its respective sponsors, advisers and members of the underwriting syndicate that: (a) this document is only for the purpose of providing information about the Company to the public in Hong Kong and not for any other purposes. No investment decision should be based on the information contained in this document; (b) the publication of this document or any supplemental, revised or replacement pages on the Stock Exchange’s website does not give rise to any obligation of the Company, its respective sponsors, advisers or members of the underwriting syndicate to proceed with an offering in Hong Kong or any other jurisdiction. -

Introduction to P.B.E.Syllabus™
INTRODUCTION TO P.B.E.SYLLABUS™ Two decades in the making, the meticulously crafted approach has been evolving and improving since - Play by Ear Syllabus™ (Study of Contemporary Music Improvisation & Aural Techniques) . It is a teaching methodology that was written by an international team of teaching professionals and performing musicians, designed to make the experience of learning music and improvisation easily accessible to all ages, regardless of their experience with music. It helps any student, even a complete novice, to acquire essential musical knowledge and gain the ability to play the instrument in a reasonable span of time, without going through years of traditional or classical training. This is done possible using the modular approach, in which students can choose to learn what they like and apply them to the choices of songs they prefer. Because all students are from various walks of life, P.B.E.S™ ensures that what is learned will only complement and not conflict with previous music training (if any). Above all, the training never disregards the rudiments of music such as proper posture, fingerings and notation reading. It is the fundamental assurance that every student learns only what is deemed correct in the educational system of music. Our courses, in-conjunction with P.B.E.S™, pave the way for anyone to attain their desired musical proficiency – be it as a subject of academic study, for proficiency of performance or for personal enjoyment. The courses available include Pop Piano Improvisation, Jazz Piano Improvisation, Pop Guitar Improvisation, Pop Vocal Improvisation & Pop Piano Junior. Each course comes in 8 levels of difficulty (with the exception of Jazz Piano Improvisation). -

Saison 21/22
Saison 21/22 Sommaire 04 109 Éditos Les séances scolaires Et nos représentations 10 en soirée recomman- Les spectacles dées aux classes en un coup d’œil 111 15 Prenez place ! La saison Réservations 99 et Pass / Tarifs / Bienvenue chez vous Venir au théâtre Autour des 119 spectacles / Comité Calendrier de spectateurs 103 Vous êtes… Édito Georges Mischo, Bourgmestre Pim Knaff, Échevin à la Culture Exceptionnelle, la saison passée l’a certaine- ment été. Si le Escher Theater a pu présen- ter la majorité des spectacles initialement programmés et réussi à en reporter d’autres, c’est grâce, il faut le dire, à un heureux mé- lange de dévouement professionnel, de sens de l’improvisation et, bien sûr, de chance. Nous vivons une époque témoin : moins un grand chamboulement qu’une lente prise de conscience, moins une révolution qu’un ré- examen prudent et attentif de nos sociétés, auxquels l’activité culturelle – et le théâtre en particulier – apportera une contribution essen- tielle. Les objectifs d’Esch2022 Capitale euro- péenne de la culture coïncident parfaitement avec notre démarche de mettre la culture au cœur de notre ville. Esch2022 n’est pas une fin en soi, mais fait partie du long processus 4 de changement et d’innovation durable que nous avons initié dans notre commune. À l’heure actuelle, cette mise en perspective européenne est déjà une grande réussite : fa- cilitatrice et accélératrice, elle nous a permis, en peu de temps, de créer de nouvelles infra- structures comme le Bâtiment 4, la Konscht- hal, le Bridderhaus et l’Ariston. Seconde salle de spectacle du Escher Theater, l’Ariston ouvrira de nouvelles possibilités et consoli- dera le rayonnement du théâtre au-delà de nos frontières – nous tenons ici à remercier la directrice et toute son équipe pour leurs efforts inlassables de renouvellement depuis 3 ans. -

St Lawrence's Church Launches Gift Shop to Promote Catholicism
SUSPECTS CHARGED TRUMP EFFECT BENEFITS WITH MURDER HO’S CHINA’S RICHEST Appearing calm and solemn, DEFENSE 36 Chinese billionaires have increased their wealth by 13.2 two young women were MAKES GAFFE accused of smearing VX nerve percent since Donald Trump was AT COURT agent on Kim Jong Nam elected U.S. president P3 P5 P11 THU.02 Mar 2017 T. 14º/ 23º C H. 30/ 80% facebook.com/mdtimes + 11,000 MOP 7.50 2754 N.º HKD 9.50 FOUNDER & PUBLISHER Kowie Geldenhuys EDITOR-IN-CHIEF Paulo Coutinho www.macaudailytimes.com.mo “ THE TIMES THEY ARE A-CHANGIN’ ” WORLD BRIEFS GAMING AP PHOTO February revenue hits two-year high P6 BREXIT The government lead by Theresa May is expected to suffer a defeat in Parliament over the right of European Union PAULO BARBOSA PAULO citizens to stay in the U.K. after Brexit. The House of Lords is due to vote early today [Macau time] on an amendment that inserts a commitment to protecting EU nationals’ rights into to a bill authorizing the start of EU exit talks. SOUTH CHINA SEA Vietnam has slammed a fishing ban China has imposed in parts of the disputed South China Sea, saying it violates Vietnamese sovereignty and further complicates the tense situation in the troubled waters. China’s Ministry of Agriculture issued a seasonal fishing ban in parts of the South China Sea, including waters near the Paracel islands claimed by Vietnam but occupied by China. CHINA has staged a fresh display of military might in its western Xinjiang region, sending more than 10,000 armed police, columns of armored vehicles and helicopters rumbling through the regional capital. -

Introduction
高科大應用外語學報 第十一期 Introduction In the early 2007, a singing contest was aired in Taiwan. The program, One Million Dollar initiated as a nameless contest with only less than 1% viewing rate. However, it ended in the first season hilariously: contestants were frequently listed in Yahoo as the popular key words for online surfing and the program was also listed as the top ten must-know news. Popularity of One Million Dollar manifests the trend of TV contests is as famous as that in America (Super Idol) and England (Pop Idol or British Got Talent). None the less, the program employed a new strategy in fabricating an idol by website. Take the first season as an example. Audience enjoyed chatting or even arguing in Xuite (an official website of One Million Dollar, Season One). This also formed a sense of communities. In Xuite, the audience were separated gradually by the stars they supported and became fans. With the end of the first season, to pursue a perpetual fandom, these fans built up forums for their stars. This paper, thus, introduced one of the fan forums—Acid YOGA. Acid YOGA is a fan forum for Yoga Lin who found his fame from One Million Dollar in particular as the champion of Season One. The study of this forum lays on the membership—at least most of the active participators are over 20 years old (in fact, the thirty-something occupy the major part) and some of them are even well-educated (which means at least bachelor degree—a period of age which is rarely connected with fandom, or stardom, to be specific). -
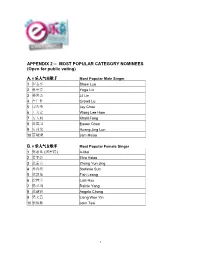
MOST POPULAR CATEGORY NOMINEES (Open for Public Voting)
APPENDIX 2 – MOST POPULAR CATEGORY NOMINEES (Open for public voting) A. e 乐人气男歌手 Most Popular Male Singer 1 罗志祥 Show Luo 2 林宥嘉 Yoga Lin 3 林俊杰 JJ Lin 4 卢广仲 Crowd Lu 5 周杰伦 Jay Chou 6 王力宏 Wang Lee Hom 7 方大同 Khalil Fong 8 陈奕迅 Eason Chan 9 黄靖伦 Huang Jing Lun 10 萧敬腾 Jam Hsiao B. e 乐人气女歌手 Most Popular Female Singer 1 张惠妹 ( 阿密特) A-Mei 2 萧亚轩 Elva Hsiao 3 张芸京 Zhang Yun Jing 4 孙燕姿 Stefanie Sun 5 梁静茹 Fish Leong 6 徐佳莹 Lala Hsu 7 杨丞琳 Rainie Yang 8 张韶涵 Angela Chang 9 梁文音 Liang Wen Yin 10 蔡依林 Jolin Tsai 1 C. e 乐人气本地歌手 Most Popular Local Singer 1 伍家辉 Wu Jiahui 2 Olivia Ong Olivia Ong 3 孙燕姿 Stefanie Sun 4 林俊杰 JJ Lin 5 阿杜 A-Do 6 蔡健雅 Tanya Chua 7 蔡淳佳 Joi Chua 8 陈伟联 Chen Weilian 9 何维健 Derrick Ho 10 黄靖伦 Huang Jing Lun D. e 乐人气乐团 Most Popular Band 1 五月天 Mayday 2 苏打绿 Soda Green 3 纵贯线 Superband 4 F.I.R. F.I.R. 5 Tizzy Bac Tizzy Bac E. e 乐人气组合 Most Popular Group 1 SHE SHE 2 飞轮海 Fahrenheit 3 BY2 BY2 4 大嘴巴 Da Mouth 5 棒棒堂 Lollipop F. e 乐人气海外新人 Most Popular Regional Newcomer 1 郭书瑶 ( 瑶瑶) Yao Yao 2 张芸京 Zhang Yun Jing 3 潘裕文 Peter Pan 4 徐佳莹 Lala Hsu 5 纵贯线 Superband 6 棉花糖 KatnCandiX2 7 黄鸿升 ( 小鬼) Alien Huang (Xiao Gui) 8 谢和弦 Chord 9 袁咏琳 Cindy Yen 10 梁文音 Liang Wen Ying 2 G. -

Free Download
SISTER PUBLICATION Follow Us on WeChat Now Advertising Hotline 400 820 8428 APRIL / MAY 2017 Chief Editor Alyssa Marie Wieting Production Manager Ivy Zhang 张怡然 Designers Joan Dai 戴吉莹 Aries Ji 季燕 Contributors Andrew Chin, Betty Richardson, Celine Song, Charlotte Godwyn, Dominic Ngai, Frances Arnold, Gareth Thomas, Ilona Dielis, Kendra Perkins, Lauren Hogan, Nate Balfanz, Shirani Alfreds, Steven Hu Operations Shanghai (Head Office) 上海和舟广告有限公司 上海市蒙自路169号智造局2号楼305-306室 邮政编码:200023 Room 305-306, Building 2, No.169 Mengzi Lu, Shanghai 200023 电话:021-8023 2199 传真:021-8023 2190 Guangzhou 广告代理: 上海和舟广告有限公司广州分公司 电话:020-8358 6125, 传真:020-8357 3859-800 Shenzhen 广告代理: 上海和舟广告有限公司广州分公司 电话:0755-8623 3220, 传真:0755-8623 3219 Beijing 广告代理: 上海和舟广告有限公司 电话: 010-8447 7002 传真: 010-8447 6455 CEO Leo Zhou 周立浩 Sales Manager Doris Dong 董雯 BD Manager Tina Zhou 周杨 Sales & Advertising Jessica Ying Linda Chen 陈璟琳 Celia Chen 陈琳 Chris Chen 陈熠辉 Leah Li 李佳颖 Head of Communication Ned Kelly Marketing Zoe Zhou 周铮峥 Summer Wang 王玥 Sharon Xie 谢晓雯 George Xu 徐林峰 Operations Manager Penny Li 李彦洁 HR/Admin Sharon Sun 孙咏超 Distribution Zac Wang 王蓉铮 General enquiries and switchboard (021) 8023 2199 [email protected] Editorial (021) 8023 2199*5802 [email protected] Distribution (021) 8023 2199*2802 [email protected] Marketing/Subscription (021) 8023 2199*2806 [email protected] Advertising (021) 8023 2199*7802 [email protected] online.thatsmags.com shanghai.urban-family.com Advertising Hotline: 400 820 8428 城市家 出版发行:云南出版集团 云南科技出版社有限责任公司 地 址:云南省昆明市环城西路609号云南新闻出版大楼2306室 -

HIM International Music (8446 TT)
Company Report May 09 2017 HIM International Music (8446 TT) BUY Close (NTD) 121.50 3M target price (NTD) 144.00 Significant increases in quarterly earnings from 2Q17 onwards; 12M target price (NTD) 144.00 initiate coverage with BUY Last report date, rating, previous close Key takeaways: (1) Recommendation : We initiate coverage with BUY and TP of NTD144 due to the following: a) the company’s valuation appears low as the current stock price Company information already reflected operating declines during the low season in 1Q17; b) the Paid-in capital (NTD mn) 428 company is expected to organize nearly 20 concerts in Taiwan and abroad in 2Q17, significantly catalyzing its revenue and quarterly earnings; c) the Market cap (NTD bn) 5 company may organize significantly more concerts in FY17 than it did in FY16 BVPS (NTD) 26.09 and post steady income from other sources; FY17 EPS is forecasted to approach FINI holding (%) 13.98 NTD7.19; d) the market’s demand for live performances has risen persistently, Local fund holding (%) 1.51 suggesting solid earnings in the long run. Major shareholders (%) 35.19 (2) 2Q17 consolidated revenue is estimated at NTD522mn (+104.71% QoQ) Margin buying (‘000 shrs) 1,584 with net profit of NTD67mn (+121.05% QoQ) or EPS of NTD1.57 : In 2Q17, Cash Div. Payout Ratio (F) (%) 76.11 HIM International Music (HIM) is estimated to organize 16 overseas concerts, 3 concerts in Taiwan and six stage plays. The details are as follows: a) ~10 Product mix concerts featuring Taiwanese artists Hebe and Power Station; b) Yoga Lin already kicked off two concerts (2017 The Great Yoga) in APR17; he is expected to perform at another four overseas concerts; c) Shin’s 2017 Gentle Monster concert is scheduled to commence later in MAY17; d) Hebe’s JUN17 Serenade stage play is scheduled to be held in Taichung and Kaohsiung in JUN17. -

Li, Chor-Yu, Samantha
How independent is independent music, and how commercial is Title commercial music in Hong Kong? Author(s) Li, Chor-yu, Samantha Li, C. S.. (2015). How independent is independent music, and Citation how commercial is commercial music in Hong Kong?. (Thesis). University of Hong Kong, Pokfulam, Hong Kong SAR. Issued Date 2015 URL http://hdl.handle.net/10722/223419 The author retains all proprietary rights, (such as patent rights) and the right to use in future works.; This work is licensed under Rights a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. Department of Sociology The University of Hong Kong 2014-2015 Master of Media, Culture and Creative Cities SOCI8030 Capstone Project How independent is independent music, and how commercial is commercial music in Hong Kong? Li Chor Yu Samantha 2009071727 ACKNOWLEDGEMENT This capstone project could not be made possible without the help and advice from all these parties. Thank you Dr Ng Chun Hung for his effort in pairing me up with my community partner at the very last minute, since I insisted I would like to work on music theme and it is definitely not easy to find an organization or institute that can provide that much time and resources in intellectual publication. Thank you Wow Music for being my community partner. Miss Flora Kwong has definitely given me great insights into the music industry and corrected many of my misinterpretations. Her kind arrangement of inviting me to observe their artist's work environment is also of vital importance to gain a first hand look of this industry. -
'Mando-Pop' Super Idols in Spectacular Showcase of Concerts
FOR IMMEDIATE RELEASE Studio City Celebrates Taiwan’s ‘Mando-Pop’ Super Idols in Spectacular Showcase of Concerts Live ‘Taiwan Music Series’ Officially Launched – A First for Studio City Event Center MACAU, Tuesday, September 29, 2015 – Nine Taiwan ‘Mando-Pop’ stars including Show Lo, JJ Lin, A-Lin and Hebe Tien are set to headline a spectacular showcase series of concerts this November at Studio City Event Center (“SCEC”), located at the new cinematically-themed entertainment and leisure destination resort in Macau: Studio City. Tickets are now on sales at the official website of Studio City. Exclusively presented by SCEC, the ‘Taiwan Music Series’ is the world-class center’s first branded music series consisting of an electrifying ‘three-concert’ program featuring a line-up of top Taiwanese artistes and produced by renowned music producer Chen Cheng Chuang and his acclaimed production team. ‘I have produced many top concerts and awards ceremonies in my career, yet it is my first time to be invited to tailor-make a concert series with such a unique concept. As inspired by the ‘This is Entertainment’ vision of Studio City, I realize that my concert series for Studio City has to be a top quality entertainment production and a true musical journey for everyone. The first series, headlined by all-time favorite Show Lo, will be a music extravaganza with hot dance and music. The second, led by JJ Lin and A-Lin, will be a romantic feast for music lovers. The finale will be a signature concert with live band and featuring Yoga Lin and Hebe as the headliner,’ said Chen.