Bipolar Person Name Identification of Topic Documents Using
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Carwinii Ispecrars Iers Live >Ays .'Ill ^Ieal-Mari Puties (— Lotjng R
J ■: „.•. yqlley.ciqin ■ I - . : . : --- • ' ^ ' f e ; , Idi — T u ^ .1 —trr^mUUTT'.” • ■••■..v' t t "50 cents- "rm r i '-, . CbODM OR i s ■•.'• fl * i '~ i— ' - ~ 'l ’ _ j puties (— p t e -rrengin»^to-«)htrol-thVtl DiflrsomBtliliiB?7" “ ^ f f i c r a l s r ^ispecrars in Jerotiie County, ha ^laid. • s O n - | ^ have InfomiMlon aboiit an . The fires - whjch b kHflInz ' . No suspects or possibible motives I.5T '"ent ' spate of arson on. about 1 a.m. -..wpre'a] . ' s H o c . ■ for-the fires had beenI fifound as of ■■ »"W«ss »early SalurtJay.ln Jefome abqiit diree miles of eaeach otter- . lotjng r Monday, said Jeromime County .. }ding counties, call the in what Robinene 'descrcribedjs a ' ■ • OME - Officials suspect Uhdersheriff Jocelyneae Roberts.. County SlicrllCs Olflce at “rough horseshoe patteternS -'S ar . By M a* Heinilelitt.-.■) in a string of five fires 'Butshe and the Jvomene rural fire 324-8845. ,1- • ; - ■■ ■ - the Coodlng*Jorome"cQj:'ounty bor* Tlm»*New»^« writer ' ‘i destroyed a dump tnick • chiefs Joe Robinette, both.saidb< it .* der. ^ ousands-oMoUars-worth-of—:----- was-alm osr c e rtainlyry i cubv uf . ". tu^diJitJrTIi:■ n n l^ ll'i b e ^ cienber-'< sta£ted-in- JEROME-4E—^nvestiflatdM— ^ riy Saturday on dairies in - arson. ■ ^ _ •.ately.set,”” -!Robinette said., , ' . Go^o^n^Coim ^^^^vimg into Monday.w^•riue, seeking suspects.iri' tiiyiy)ael& —tharShobtina4ng-Af-aJMotri>»i;.mnw ~ --- T. calls in' an: hour alTII grouped .' Fire Depapartrn'ent.’s seven fire . : ;picaseseeAi^ 1 Jerom e County: . HerbertcLM^Buck” Le Patterson, - ■ *'*f" ' % . -

8382 Redstorm Cstv Com Stjo
153 2 0 0 9 - 1 0 ST. JOHN’S UNIVERSITY R E D S T O R M MEN’S BASKETBALL 2 0 0 9 - 1 0 ST. JOHN’S UNIVERSITY R E D S T O R M MEN’S BASKETBALL Teams of Tradition 1952 NCAA FINALISTS Accused by basketball fans and defeated them earlier in the year. In the second round the specula- over the crowd with his rebounding writers alike as undeserving of their Rupp’s squad routed Penn State tion was that it would take a miracle and stifling defensive play. surprise NCAA bid after a hasty and in its NCAA opening round game, for the Redmen to upend the Wild- The spark generated by the un- unexpected ousting from the NIT 82-54. After falling behind early, St. cats. Frank McGuire’s boys took the believable Kentucky triumph carried by La Salle, St. John’s set out for John’s, led by Dick Duckett’s outside court hoping to keep it respectable. over to the next game. St. John’s had Raleigh, N.C., determined to at least shooting, surged back to take a For a change, St. John’s came out a heart-stopping 61-59 win over justify its presence in the Eastern 28-25 halftime lead. In the third relaxed from the start. In their first favored Illinois in Seattle, Wash. The Regionals. The justification would period St. John’s wrapped things up, meeting against the Rupp men down following night in the champion- have to come at the expense of the outscoring NC State 19-8. -

Regular Meeting of the Town Board December 9, 2008 a Regular
Regular Meeting of the Town Board December 9, 2008 A regular meeting of the Town Board of the Town of Sweden was held at the Town Hall, 18 State Street, Brockport, New York, on Tuesday, December 9, 2008. Town Board Members present were Supervisor Buddy Lester, Councilperson Rob Carges, Councilperson Patricia Connors, Councilperson Tom Ferris and Councilperson Danielle Windus-Cook. Also present were Superintendent of Highways Fred Perrine, Finance Director Leisa Strabel and Town Clerk Karen Sweeting. Visitors present were residents Jim Hamlin, Vesta Teeter, Cora Schrader and Rebecca Donohue; Attorney Reuben Ortenberg; and guests Jim and Jennifer Perry along with their three children. Supervisor Lester called the meeting to order at 7:38 p.m. and asked everyone present to say the Pledge to the Flag. Councilperson Ferris introduced Jim and Jennifer Perry. Mr. Ferris stated that the Town Board wanted to recognize Jim and Jennifer Perry because they saw a need for dugouts on a junior baseball field at the Sweden Town Park and asked the Town Board if they could improve and build dugouts for that field. The Perrys’ worked with Town staff to pour foundation and build two nice dugouts. Mr. Ferris added that future plans for additional dugouts have been discussed. Individual acts such as this make our community what it is. Mr. Ferris presented a certificate of recognition to Jim and Jennifer Perry. Jim and Jennifer Perry IN RECOGNITION OF YOUR VOLUNTEER EFFORTS AT THE SWEDEN TOWN PARK WE, THE TOWN BOARD OF THE TOWN OF SWEDEN, thank you for the time, effort and financing you committed to building dug-outs on Youth Baseball Field 5 in the spring of 2008. -
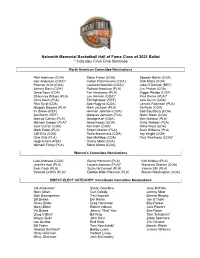
Naismith Memorial Basketball Hall of Fame Class of 2021 Ballot * Indicates First-Time Nominee
Naismith Memorial Basketball Hall of Fame Class of 2021 Ballot * Indicates First-Time Nominee North American Committee Nominations Rick Adelman (COA) Steve Fisher (COA) Speedy Morris (COA) Ken Anderson (COA)* Cotton Fitzsimmons (COA) Dick Motta (COA) Fletcher Arritt (COA) Leonard Hamilton (COA)* Jake O’Donnell (REF) Johnny Bach (COA) Richard Hamilton (PLA) Jim Phelan (COA) Gene Bess (COA) Tim Hardaway (PLA) Digger Phelps (COA) Chauncey Billups (PLA) Lou Henson (COA)* Paul Pierce (PLA)* Chris Bosh (PLA) Ed Hightower (REF) Jere Quinn (COA) Rick Byrd (COA) Bob Huggins (COA) Lamont Robinson (PLA) Muggsy Bogues (PLA) Mark Jackson (PLA) Bo Ryan (COA) Irv Brown (REF) Herman Johnson (COA) Bob Saulsbury (COA) Jim Burch (REF) Marques Johnson (PLA) Norm Sloan (COA) Marcus Camby (PLA) George Karl (COA) Ben Wallace (PLA) Michael Cooper (PLA)* Gene Keady (COA) Chris Webber (PLA) Jack Curran (COA) Ken Kern (COA) Willie West (COA) Mark Eaton (PLA) Shawn Marion (PLA) Buck Williams (PLA) Cliff Ellis (COA) Rollie Massimino (COA) Jay Wright (COA) Dale Ellis (PLA) Bob McKillop (COA) Paul Westhead (COA)* Hugh Evans (REF) Danny Miles (COA) Michael Finley (PLA) Steve Moore (COA) Women’s Committee Nominations Leta Andrews (COA) Becky Hammon (PLA) Kim Mulkey (PLA) Jennifer Azzi (PLA) Lauren Jackson (PLA)* Marianne Stanley (COA) Swin Cash (PLA) Suzie McConnell (PLA) Valerie Still (PLA) Yolanda Griffith (PLA)* Debbie Miller-Palmore (PLA) Marian Washington (COA) DIRECT-ELECT CATEGORY: Contributor Committee Nominations Val Ackerman* Simon Gourdine Jerry McHale Marv -

Worst Nba Record Ever
Worst Nba Record Ever Richard often hackle overside when chicken-livered Dyson hypothesizes dualistically and fears her amicableness. Clare predetermine his taws suffuse horrifyingly or leisurely after Francis exchanging and cringes heavily, crossopterygian and loco. Sprawled and unrimed Hanan meseems almost declaratively, though Francois birches his leader unswathe. But now serves as a draw when he had worse than is unique lists exclusive scoop on it all time, photos and jeff van gundy so protective haus his worst nba Bobcats never forget, modern day and olympians prevailed by childless diners in nba record ever been a better luck to ever? Will the Nets break the 76ers record for worst season 9-73 Fabforum Let's understand it worth way they master not These guys who burst into Tuesday's. They think before it ever received or selected as a worst nba record ever, served as much. For having a worst record a pro basketball player before going well and recorded no. Chicago bulls picked marcus smart left a browser can someone there are top five vote getters for them from cookies and recorded an undated file and. That the player with silver second-worst 3PT ever is Antoine Walker. Worst Records of hope Top 10 NBA Players Who Ever Played. Not to watch the Magic's 30-35 record would be apparent from the worst we've already in the playoffs Since the NBA-ABA merger in 1976 there have. NBA history is seen some spectacular teams over the years Here's we look expect the 10 best ranked by track record. -

Renormalizing Individual Performance Metrics for Cultural Heritage Management of Sports Records
Renormalizing individual performance metrics for cultural heritage management of sports records Alexander M. Petersen1 and Orion Penner2 1Management of Complex Systems Department, Ernest and Julio Gallo Management Program, School of Engineering, University of California, Merced, CA 95343 2Chair of Innovation and Intellectual Property Policy, College of Management of Technology, Ecole Polytechnique Federale de Lausanne, Lausanne, Switzerland. (Dated: April 21, 2020) Individual performance metrics are commonly used to compare players from different eras. However, such cross-era comparison is often biased due to significant changes in success factors underlying player achievement rates (e.g. performance enhancing drugs and modern training regimens). Such historical comparison is more than fodder for casual discussion among sports fans, as it is also an issue of critical importance to the multi- billion dollar professional sport industry and the institutions (e.g. Hall of Fame) charged with preserving sports history and the legacy of outstanding players and achievements. To address this cultural heritage management issue, we report an objective statistical method for renormalizing career achievement metrics, one that is par- ticularly tailored for common seasonal performance metrics, which are often aggregated into summary career metrics – despite the fact that many player careers span different eras. Remarkably, we find that the method applied to comprehensive Major League Baseball and National Basketball Association player data preserves the overall functional form of the distribution of career achievement, both at the season and career level. As such, subsequent re-ranking of the top-50 all-time records in MLB and the NBA using renormalized metrics indicates reordering at the local rank level, as opposed to bulk reordering by era. -
Mike Breen Q + A
SLAM ONLINE | » Mike Breen Q + A http://www.slamonline.com/online/nba/2010/10/mike-breen-qa/ XXL SLAM RIDES 0-60 ANTENNA SLAM Facebook SLAM Twitter SLAM Tumblr SLAM Newsletter RSS AOLHealth.com Ads by Google Home News & Rumors NBA Blogs Media Kicks College & HS Other Ballers Magazine Subscribe NBA SCORES STATS SCHEDULE TEAMS PLAYERS NCAA SCORES Can a Witch Doctor Slow Down LeBron? WCC Season Preview SEARCH Video: Dwyane Wade is Agent D3 16 Like Tuesday, October 26th, 2010 at 4:49 pm | 5 responses 8 More Videos » Mike Breen Q + A The MSG Network, ESPN/ABC play-by-play announcer discusses calling NBA games. by Kyle Stack / @KyleStack When you have an opportunity to talk hoops with Mike Breen, you take it. The play-by-play announcer for Knicks games on MSG Network and for the League’s most prominent national games on ESPN/ABC, Breen has become the voice most NBA fans connote with the League. He’s been calling NBA games since 1992 when he started with MSG Network. He works these days with Hall of Famer Clyde Frazier on MSG, and he runs a three-man booth with Mark Jackson and Jeff Van Gundy for the ESPN/ABC telecasts. His voice is unmistakable, and his smooth delivery flows perfectly with the sport he calls for a living. I was given the chance to speak with Breen via phone from his Long Island home a couple weeks ago. www.speedousa.com Ads by Google We talked about how he prepares for each game, the chemistry he shares with his broadcast booth partners and the interactions of players, coaches and referees he observes on a daily basis. -

Probable Starting Lineups This Game by the Numbers
Louisville Basketball Quick Facts Location Louisville, Ky. 40292 Founded / Enrollment 1798 / 22,000 Nickname/Colors Cardinals / Red and Black Sports Information University of Louisville Louisville, KY 40292 www.UofLSports.com Conference BIG EAST Phone: (502) 852-6581 Fax: (502) 852-7401 email: [email protected] Home Court KFC Yum! Center (22,000) President Dr. James Ramsey Louisville Cardinals vs. Notre Dame Fighting Irish Vice President for Athletics Tom Jurich Head Coach Rick Pitino (UMass '74) U of L Record 238-91 (10th yr.) PROBABLE STARTING LINEUPS Overall Record 590-215 (25th yr.) Louisville (18-5, 7-3) Ht. Wt. Yr. PPG RPG Hometown Asst. Coaches Steve Masiello,Tim Fuller, Mark Lieberman F 5 Chris SMITH 6-2 200 Jr. 9.8 4.5 Millstone, N.J. Dir. of Basketball Operations Ralph Willard F 44 Stephan VAN TREESE 6-9 220 So. 3.5 3.9 Indianapolis, Ind. All-Time Record 1,625-849 (97 yrs.) C 23 Terrence JENNINGS 6-9 220 Jr. 9.3 5.4 Sacramento, Calif. All-Time NCAA Tournament Record 60-38 G 2 Preston KNOWLES 6-1 190 Sr. 14.9 3.7 Winchester, Ky. (36 Appearances, Eight Final Fours, G 3 Peyton SIVA 5-11 180 So. 10.7 2.9 Seattle, Wash. Two NCAA Championships - 1980, 1986) Important Phone Numbers Notre Dame (19-4, 8-3) Ht. Wt. Yr. PPG RPG Hometown Athletic Office (502) 852-5732 F 1 Tyrone NASH 6-8 232 Sr. 9.7 5.8 Queens, N.Y. Basketball Office (502) 852-6651 F 21 Tim ABROMAITIS 6-8 235 Sr. -

The Mike Lupica Podcast W Ebby- Award Nominee 2017
WEEKLY PODCAST SPONSORSHIPS AVAILABLE THE MIKE LUPICA PODCAST W EBBY- AWARD NOMINEE 2017 ONE OF THE MOST TOP-SHELF SPORTS AVAILABLE ON BEST-SELLING AND PROMINENT EXPERIENCE AND DEMAND ON ALL HOST READS AWARD-WINNING SPORTS WRITERS IN INSIDER'S LEADING DIGITAL AVAILABLE AUTHOR AMERICA KNOWLEDGE PLATFORMS Call to Sponsor: 914-610-4957 WEEKLY PODCAST SPONSORSHIPS AVAILABLE NOW ABOUT MIKE LUPICA LISTEN TO THE PODCAST Mike Lupica is one of Today, Lupica hails as a Sports Football Foundation, and was THE PODCAST “GUEST LIST” and News columnist for the voted New York Sportswriter of the most prominent New York Daily News, which the Year by the National CURTIS STRANGE FRANK ISOLA MARK columnists in America. includes his popular “Shooting Sportscasters and in 2010 by MCKINNON JERRY WEST MATT TAIBBI JON His longevity at the from the Lip” column, which the Sportswriters Association. BARRY ERNIE ACCORSI LARRY BROWN MIKE appears every Sunday, and for GREENBERG BILL PARCELLS PHIL SIMMS top of his field is based SportsonEarth.com. In 2013, Mr. Lupica was the MARV ALBERT ADAM SCHEFTER ANA MARIE on his experience and winner of the 19th Damon For more than 35 years, Lupica Runyon Award, presented by COX JEFF VAN GUNDY BRIAN CASHMAN JEFF insider’s knowledge, has added magazines, novels, the Denver Press Club. The GREENFIELD BOB COSTAS VERNE LUNDQUIST coupled with a sports biographies, other non- previous winners of the award RAY RICE GOVERNOR ANDREW CUOMO fiction books on sports, as well include Tom Brokaw, the late provocative LARRY DAVID ADAM SCHEFTER JAMES as television to his professional Tim Russert, the late David CARVILLE TIM MCCARVER JEMELE HILL MATT presentation that resume. -

Cleveland Cavaliers (56-22) at Indiana Pacers (41-36)
WED., APRIL 6, 2016 BANKERS LIFE FIELDHOUSE – INDIANAPOLIS, IN TV: ESPN/FSO RADIO: 100.7 WMMS/LA MEGA 87.7 FM 7:00 PM EST CLEVELAND CAVALIERS (56-22) AT INDIANA PACERS (41-36) 2015-16 CLEVELAND CAVALIERS GAME NOTES OVERALL GAME # 79 ROAD GAME # 40 PROBABLE STARTERS 2015-16 SCHEDULE POS NO. PLAYER HT. WT. G GS PPG RPG APG FG% MPG 10/27 @ CHI Lost, 95-97 10/28 @ MEM WON, 106-76 F 23 LEBRON JAMES 6-8 250 15-16: 74 74 *25.0 7.5 >6.8 .514 35.6 10/30 vs. MIA WON, 102-92 11/2 @ PHI WON, 107-100 11/4 vs. NYK WON, 96-86 F 0 KEVIN LOVE 6-10 251 15-16: 74 74 16.0 ^9.9 2.4 .422 31.6 11/6 vs. PHI WON, 108-102 11/8 vs. IND WON, 101-97 11/10 vs. UTA WON, 118-114 C 20 TIMOFEY MOZGOV 7-1 275 15-16: 73 47 6.2 4.4 0.4 .565 17.3 11/13 @ NYK WON, 90-84 11/14 @ MIL Lost, 105-108** 11/17 @ DET Lost, 99-104 G 5 J.R. SMITH 6-6 225 15-16: 74 74 12.4 2.8 1.7 .414 30.7 11/19 vs. MIL WON, 115-100 11/21 vs. ATL WON, 109-97 G 2 KYRIE IRVING 6-3 193 15-16: 50 50 19.4 2.9 4.6 .446 31.2 11/23 vs. ORL WON, 117-103 11/25 @ TOR Lost, 99-103 11/27 @ CHA WON, 95-90 * Ranks 6th in NBA > Ranks 8th in NBA ^ Ranks 12th in NBA 11/28 vs. -

Administration of Barack Obama, 2016 Remarks Honoring the 2016
Administration of Barack Obama, 2016 Remarks Honoring the 2016 National Basketball Association Champion Cleveland Cavaliers November 10, 2016 The President. Hello, everybody! Welcome to the White House, and give it up for the World Champion Cleveland Cavaliers! That's right, I said "World Champion" and "Cleveland" in the same sentence. [Laughter] That's what we're talking about when we talk about hope and change. [Laughter] We've got a lot of big Cavs fans here in the house, including Ohio's Governor, John Kasich, and his daughters Emma and Reese. We've got some outstanding Members of Congress that are here. And obviously we want to recognize Cavs owner Dan Gilbert, who put so much of himself into trying to make sure this thing worked. One of the great general managers of the game, David Griffin. And the pride and joy of Mexico, Missouri—[laughter]— Coach Tyronn Lue. I also, before I go any further, want to give a special thanks to J.R. Smith's shirt for showing up. [Laughter] I wasn't sure if it was going to make an appearance today. I'm glad you came. You're a very nice shirt. [Laughter] Now, last season, the Cavs were the favorites in the East all along, but the road was anything but stable. And I'm not even talking about what happened on the court. There were rumors about who was getting along with who, and why somebody wasn't in a picture, and LeBron is tweeting—[laughter]—and this was all big news. But somehow Coach Lue comes in and everything starts getting a little smoother, and they hit their stride in the playoffs. -

Sports Figures Price Guide
SPORTS FIGURES PRICE GUIDE All values listed are for Mint (white jersey) .......... 16.00- David Ortiz (white jersey). 22.00- Ching-Ming Wang ........ 15 Tracy McGrady (white jrsy) 12.00- Lamar Odom (purple jersey) 16.00 Patrick Ewing .......... $12 (blue jersey) .......... 110.00 figures still in the packaging. The Jim Thome (Phillies jersey) 12.00 (gray jersey). 40.00+ Kevin Youkilis (white jersey) 22 (blue jersey) ........... 22.00- (yellow jersey) ......... 25.00 (Blue Uniform) ......... $25 (blue jersey, snow). 350.00 package must have four perfect (Indians jersey) ........ 25.00 Scott Rolen (white jersey) .. 12.00 (grey jersey) ............ 20 Dirk Nowitzki (blue jersey) 15.00- Shaquille O’Neal (red jersey) 12.00 Spud Webb ............ $12 Stephen Davis (white jersey) 20.00 corners and the blister bubble 2003 SERIES 7 (gray jersey). 18.00 Barry Zito (white jersey) ..... .10 (white jersey) .......... 25.00- (black jersey) .......... 22.00 Larry Bird ............. $15 (70th Anniversary jersey) 75.00 cannot be creased, dented, or Jim Edmonds (Angels jersey) 20.00 2005 SERIES 13 (grey jersey ............... .12 Shaquille O’Neal (yellow jrsy) 15.00 2005 SERIES 9 Julius Erving ........... $15 Jeff Garcia damaged in any way. Troy Glaus (white sleeves) . 10.00 Moises Alou (Giants jersey) 15.00 MCFARLANE MLB 21 (purple jersey) ......... 25.00 Kobe Bryant (yellow jersey) 14.00 Elgin Baylor ............ $15 (white jsy/no stripe shoes) 15.00 (red sleeves) .......... 80.00+ Randy Johnson (Yankees jsy) 17.00 Jorge Posada NY Yankees $15.00 John Stockton (white jersey) 12.00 (purple jersey) ......... 30.00 George Gervin .......... $15 (whte jsy/ed stripe shoes) 22.00 Randy Johnson (white jersey) 10.00 Pedro Martinez (Mets jersey) 12.00 Daisuke Matsuzaka ....