Observations and Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Maximum Internet Security: a Hackers Guide - Networking - Intrusion Detection
- Maximum Internet Security: A Hackers Guide - Networking - Intrusion Detection Exact Phrase All Words Search Tips Maximum Internet Security: A Hackers Guide Author: Publishing Sams Web Price: $49.99 US Publisher: Sams Featured Author ISBN: 1575212684 Benoît Marchal Publication Date: 6/25/97 Pages: 928 Benoît Marchal Table of Contents runs Pineapplesoft, a Save to MyInformIT consulting company that specializes in Internet applications — Now more than ever, it is imperative that users be able to protect their system particularly e-commerce, from hackers trashing their Web sites or stealing information. Written by a XML, and Java. In 1997, reformed hacker, this comprehensive resource identifies security holes in Ben co-founded the common computer and network systems, allowing system administrators to XML/EDI Group, a think discover faults inherent within their network- and work toward a solution to tank that promotes the use those problems. of XML in e-commerce applications. Table of Contents I Setting the Stage 1 -Why Did I Write This Book? 2 -How This Book Will Help You Featured Book 3 -Hackers and Crackers Sams Teach 4 -Just Who Can Be Hacked, Anyway? Yourself Shell II Understanding the Terrain Programming in 5 -Is Security a Futile Endeavor? 24 Hours 6 -A Brief Primer on TCP/IP 7 -Birth of a Network: The Internet Take control of your 8 -Internet Warfare systems by harnessing the power of the shell. III Tools 9 -Scanners 10 -Password Crackers 11 -Trojans 12 -Sniffers 13 -Techniques to Hide One's Identity 14 -Destructive Devices IV Platforms -

ED381174.Pdf
DOCUMENT RESUME ED 381 174 IR 055 469 AUTHOR Klatt, Edward C.; And Others TITLE Windows to the World: Utah Library Network Internet Training Manual. INSTITUTION Utah State Library, Salt Lake City. PUB DATE Mar 95 NOTE 136p. AVAILABLE FROMWorld Wide Web at http://www.state.lib.ut.us/internet.htm (available electronically) or Utah State Library Division, 2150 S. 3rd W., Suite 16, Salt Lake City, UT 84115-2579 ($10; quantity price, $5). PUB TYPE Guides Non-Classroom Use (055) EDRS PRICE MF01/PC06 Plus Postage. DESCRIPTORS Access to Information; *Computer Networks; Computer Software; Electronic Mail; *information Networks; *Information Systems; *Librarians; Online Catalogs; Professional Training; Telecommunications IDENTIFIERS *Internet; Utah ABSTRACT This guide reviews the basic principles of Internet exploration for the novice user, describing various functions and utilizing "onscreen" displays. The introduction explains what the Internet is, and provides historical information. The introduction is followed by a listing of Internet hardware and software (freeware and shareware), both lists including information fo: PC-compatibles and Macintosh computers. Users are introduced to and instructed in the use of the following Internet systems and services: EWAN telnet; OPACS (Online Public Access Catalogs); CARL (Colorado Alliance of Research Libraries; FirstSearch; UMI (University Microfilm Inc.); Deseret News; Pegasus E-Mail; Listservs; WinVN Newsreader; Viewers; Netscape; Mosaic; Gopher; Archie; and FTP (File Transfer Protocol). Over 100 computer screen reproductions help to illustrate the instruction. Contains 16 references and a form for ordering additional copies of this guide are provided. (MAS) *********************************************************************** Reproductions supplied by EDRS are the best that can be made from the original document. -
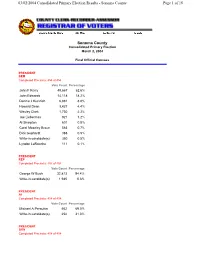
Consolidated Primary Election Results Summary
03/02/2004 Consolidated Primary Election Results - Sonoma County Page 1 of 18 Sonoma County Consolidated Primary Election March 2, 2004 Final Official Canvass PRESIDENT DEM Completed Precincts: 454 of 454 Vote Count Percentage John F Kerry 48,667 62.6% John Edwards 14,118 18.2% Dennis J Kucinich 6,881 8.8% Howard Dean 3,427 4.4% Wesley Clark 1,730 2.2% Joe Lieberman 921 1.2% Al Sharpton 601 0.8% Carol Moseley Braun 583 0.7% Dick Gephardt 388 0.5% Write-in candidate(s) 350 0.5% Lyndon LaRouche 111 0.1% PRESIDENT REP Completed Precincts: 454 of 454 Vote Count Percentage George W Bush 32,813 94.4% Write-in candidate(s) 1,945 5.6% PRESIDENT AI Completed Precincts: 454 of 454 Vote Count Percentage Michael A Peroutka 562 69.0% Write-in candidate(s) 252 31.0% PRESIDENT GRN Completed Precincts: 454 of 454 03/02/2004 Consolidated Primary Election Results - Sonoma County Page 2 of 18 Vote Count Percentage Peter Miguel Camejo 2,087 73.8% Lorna Salzman 307 10.9% Write-in candidate(s) 203 7.2% David Cobb 197 7.0% Kent Mesplay 34 1.2% PRESIDENT LIB Completed Precincts: 454 of 454 Vote Count Percentage Gary Nolan 330 54.0% Aaron Russo 141 23.1% Michael Badnarik 101 16.5% Write-in candidate(s) 39 6.4% PRESIDENT NAT Completed Precincts: 454 of 454 Vote Count Percentage Write-in candidate(s) 25 100.0% NO CANDIDATE HAS FILED 0 0.0% PRESIDENT PF Completed Precincts: 454 of 454 Vote Count Percentage Leonard Peltier 147 62.8% Walter F Brown 67 28.6% Write-in candidate(s) 20 8.5% PRESIDENT DEM DTS Completed Precincts: 454 of 454 Vote Count Percentage John F -

Usenet News HOWTO
Usenet News HOWTO Shuvam Misra (usenet at starcomsoftware dot com) Revision History Revision 2.1 2002−08−20 Revised by: sm New sections on Security and Software History, lots of other small additions and cleanup Revision 2.0 2002−07−30 Revised by: sm Rewritten by new authors at Starcom Software Revision 1.4 1995−11−29 Revised by: vs Original document; authored by Vince Skahan. Usenet News HOWTO Table of Contents 1. What is the Usenet?........................................................................................................................................1 1.1. Discussion groups.............................................................................................................................1 1.2. How it works, loosely speaking........................................................................................................1 1.3. About sizes, volumes, and so on.......................................................................................................2 2. Principles of Operation...................................................................................................................................4 2.1. Newsgroups and articles...................................................................................................................4 2.2. Of readers and servers.......................................................................................................................6 2.3. Newsfeeds.........................................................................................................................................6 -

3. Internet – Participating in the Knowledge Society
3. Internet – Participating in the knowledge society “Knowledge is power. Information is liberating. Education is the premise of progress, in every society, in every family.” Kofi Annan, former Secretary General of the United Nations, January 1997-December 2006 CHECKLIST FACT SHEET 10 – SEARCHING FOR INFORMATION Do you read the disclaimer when you are consulting a website? How can you be sure the information you find is factual and objective? Do you consult several websites to check your facts? CHECKLIST FACT SHEET 11 – FINDING QUALITY INFORMATION ON THE WEB Before downloading files, do you check that your anti-virus software is active? If you get your news from the Internet, do you seek multiple perspectives on the same story? Clean out your cookies from time to time to avoid being “profiled” by search engines. CHECKLIST FACT SHEET 12 – DISTANCE LEARNING AND MOOCs Choose a method of distance learning that is appropriate for you: determine what type of learning (synchronous, asynchronous, open schedule, hybrid distance learning) will best help you reach your goals. Before selecting a distance learning course, research the reviews – both from students and teachers. Take adequate precautions to ensure that your computer equipment and software is secure from hackers, viruses and other threats. CHECKLIST FACT SHEET 13 – SHOPPING ONLINE Do not make online purchases on unsecure Internet connections. Understand and agree to the key information provided about the product or service. Disable in-app purchases on your smartphone or tablet. Do not believe all user recommendations you see, creating “user” recommendations can also be a money-making business. Fact sheet 11 Finding quality information on the Web he original idea behind the creation of the Internet1 was to develop an electronic library for the Teasy access and distribution of information2. -

CONSOLIDATED PRIMARY ELECTION MARCH 2, 2004 Results As of 03/24/2004 Certified Election Results
CONSOLIDATED PRIMARY ELECTION MARCH 2, 2004 Results as of 03/24/2004 Certified Election Results PRECINCTS COUNTED - TOTAL Completed Precincts: 132 of 132 Reg/Turnout Percentage REGISTERED VOTERS - TOTAL 45,734 BALLOTS CAST - TOTAL 18,027 39.42% BALLOTS CAST - DEMOCRATIC 7,330 16.03% BALLOTS CAST - REPUBLICAN 9,031 19.75% BALLOTS CAST - AMERICAN INDEPENDENT 228 0.50% BALLOTS CAST - GREEN 29 0.06% BALLOTS CAST - LIBERTARIAN 43 0.09% BALLOTS CAST - NATURAL LAW 6 0.01% BALLOTS CAST - PEACE AND FREEDOM 2 0.00% BALLOTS CAST - DEM DECLINE TO STATE 119 0.26% BALLOTS CAST - REP DECLINE TO STATE 95 0.21% BALLOTS CAST - AI DECLINE TO STATE 17 0.04% BALLOTS CAST - NONPARTISAN 1,127 2.46% PRESIDENTIAL PREFERENCE DEMOCRAT AND DECLINE TO STATE Vote For: 1 Completed Precincts: 132 of 132 Candidate Name Vote Count Percentage JOHN F. KERRY 4,280 63.54% JOHN EDWARDS 1,616 23.99% HOWARD DEAN 276 4.10% JOE LIEBERMAN 122 1.81% CAROL MOSELEY BRAUN 120 1.78% AL SHARPTON 102 1.51% WESLEY CLARK 86 1.28% DICK GEPHARDT 62 0.92% DENNIS J. KUCINICH 55 0.82% LYNDON LAROUCHE 17 0.25% PRESIDENTIAL PREFERENCE DEMOCRATIC VOTERS ONLY Vote For: 1 Completed Precincts: 132 of 132 Candidate Name Vote Count Percentage JOHN F. KERRY 4,219 63.68% JOHN EDWARDS 1,578 23.82% HOWARD DEAN 271 4.09% JOE LIEBERMAN 122 1.84% CAROL MOSELEY BRAUN 118 1.78% AL SHARPTON 101 1.52% WESLEY CLARK 86 1.30% DICK GEPHARDT 62 0.94% DENNIS J. KUCINICH 51 0.77% LYNDON LAROUCHE 17 0.26% PRESIDENTIAL PREFERENCE DECLINE TO STATE VOTERS ONLY Vote For: 1 Completed Precincts: 132 of 132 Candidate Name Vote Count Percentage JOHN F. -

Newsreaders.Com: Getting Started: Netiquette
Usenet Netiquette NewsReaders.com: Getting Started: Netiquette I hope you will try Giganews or UsenetServer for your news subscription -- especially as a holiday present for your friends, family, or yourself! Getting Started (Netiquette) Consult various Netiquette links The Seven Don'ts of Usenet Google Groups Posting Style Guide Introduction to Usenet and Netiquette from NewsWatcher manual Quoting Style by Richard Kettlewell Other languages: o Voila! Francois. o Usenet News German o Netiquette auf Deutsch! Some notes from me: Read a newsgroup for a while before posting o By reading the group without posting (known as "lurking") for a while, or by reading the group archives on Google, you get a sense of the scope and tone of the group. Consult the FAQ before posting. o See Newsgroups page to find the FAQ for a particular group o FAQ stands for Frequently Asked Questions o a FAQ has not only the questions, but the answers! o Thus by reading the FAQ you don't post questions that have been asked (and answered) ad infinitum See the configuring software section regarding test posts (only post tests to groups with name ending in ".test") and not posting a duplicate post in the mistaken belief that your initial post did not go through. Don't do "drive through" posts. o Frequently someone who has an urgent question will post to a group he/she does not usually read, and then add something like "Please reply to me directly since I don't normally read this group." o Newsgroups are meant to be a shared experience. -

1 Republic Magazine Issue 3
Republic Magazine Issue 3 www.republicmagazine.com 1 Republic Publishing, LLC PO Box 10577 Newport Beach, CA 92658 tel: 714.436.1234 or 866.437.6570 fax: 714.455.2091 Volume I Issue 3 Publisher In This Issue George Shepherd Duty, Honor, Country 2007 Managing Editor An Open Letter to the New Generation of Military Officers Gary Franchi Serving and Protecting Our Nation Design/Layout Manager By Dr. Bob Bowman 4 Samuel Anthony Ettaro Constitiutional 6 Copy Editor Discipline Glenn Craven Militia By Michael Badnarik Contributing Writers Property of We The People 7 Jack Blood By Mark Gregory Keornke Michael Badnarik 10 Preserving the Mark Gregory Keornke 4th Estate Samuel Anthony Ettaro Barie Zwicker We Are The Media. G. Edward Griffin Salute to By Jack Blood Gary Franchi Aaron Russo Jelena Zanko Larry R. Bradley 18 By G. Edward Griffin George Shepherd Perspective Making alternative energies Advertising mainstream choices. George Shepherd Toll Free: 866.437.6570 By Samuel Anthony Ettaro email: 23 george @republicmagazine.com Interview A Discussion With Louder Constitutional Red Alert! Subscriptions/Bulk Than Words House passes Activist Orders By Jelena Zanko 25 www.republicmagazine.com 20 By Lee Rogers or call: 866.437.6570 Mail-In Orders When Your Party PO Box 10577 We Were Born 28 Fails You Newport Beach, CA 92658 30 Kings By Larry Bradley Cover Design By Samuel Anthony Ettaro By George Shepherd Republic Magazine is Published Bi-Monthly Publisher’s Disclaimer: The Republic Magazine staff and Republic Publishing, LLC have made every effort to ensure the accuracy of the infor- Advertise Your Business mation presented within these pages. -

Town of Becket Fx: 413-623-6036
557 Main Street, Becket, MA 01223 ph: 413-623-8934 Town of Becket fx: 413-623-6036 Presidential Primary Minutes 3/2/04 Pursuant to the foregoing warrant, the PRESIDENTIAL PRIMARY was held at the Becket Town Hall on March 2, 2004, from 7:00 a.m. to 8:00 p.m. Prior to opening, the Ballot Box was publicly opened, examined and found to be empty; the register was set at zero. The polls opened at 7:00 a.m. Results of the votes for the candidates of political parties are as follows: DEMOCRATIC VOTES Presidential Preference Blanks 0 Richard Gephardt 0 Joseph Lieberman 2 Wesley K. Clark 0 Howard Dean 17 Carol Moseley Braun 0 John Edwards 17 Dennis J. Kucinich 12 John F. Kerry 70 Lyndon H. LaRouche, Jr. 0 Al Sharpton 0 NO PREFERENCE 0 Write Ins: 0 TOTAL VOTES 118 State Committee Man Blanks 17 Peter G. Arlos 50 Matt L. Barron 51 Write Ins: 0 TOTAL VOTES 118 State Committee Woman Blanks 38 Margaret Johnson Ware 80 Write Ins: 0 TOTAL VOTES 118 Town Committee Blanks 3565 Albert Barvenik 58 Francis E. Barvenik 57 Giles (Gil) T. Falcone 71 Jane P. Falcone 65 Joan Samuels Kaiser 64 Judith A. Loeb 64 James Soluri 59 Sally M. Soluri 59 Maryellen D. Lake 65 Write Ins: 3 TOTAL VOTES 4130 (Town Committee) Group Blanks 64 GROUP 54 TOTAL VOTES 118 REPUBLICAN VOTES Presidential Preference Blanks 0 George W. Bush 6 NO PREFERENCE 1 Write Ins: 0 TOTAL VOTES 7 State Committee Man Blanks 7 Write Ins: 0 TOTAL VOTES 7 State Committee Woman Blanks 7 Write Ins: 0 TOTAL VOTES 7 Town Committee Blanks 70 Write Ins: 0 TOTAL VOTES 70 GREEN-RAINBOW VOTES Presidential Preference -
How Ro Download a File on Giganews How to Download Using Usenet
how ro download a file on giganews How to Download Using Usenet. wikiHow is a “wiki,” similar to Wikipedia, which means that many of our articles are co-written by multiple authors. To create this article, 16 people, some anonymous, worked to edit and improve it over time. The wikiHow Tech Team also followed the article's instructions and verified that they work. This article has been viewed 149,534 times. Just as we once debated between Blockbuster and Hollywood Video, we have many choices when it comes to downloading. One of the oldest and best downloading sites is Usenet. Usenet downloads from a single server, making it among the safest and fastest ways to download. It’s slightly more complicated than other options, and it does have a small price tag, but it’s worth it: Usenet has a wealth of media, it’s secure, and thanks to Usenet’s strict policies, the risk of piracy is low. The following article will guide you through the process downloading with Usenet and get you on your way to enjoying the vast Usenet community. So Your Download Is Incomplete? Alas, this is something every Usenet user goes through sometime in his career. You’ve found the file you were searching for, started downloading, and were already imagining watching the movie, listening to the piece of music or otherwise using it, and there it is, the whole, ugly truth: Your download is damaged beyond repair, no chance to do anything about it. Or is there? First, let us briefly explain what exactly happened here. -

Third Parties in the U.S. Political System: What External and Internal Issues Shape Public Perception of Libertarian Party/Polit
University of Texas at El Paso DigitalCommons@UTEP Open Access Theses & Dissertations 2019-01-01 Third Parties in the U.S. Political System: What External and Internal Issues Shape Public Perception of Libertarian Party/Politicians? Jacqueline Ann Fiest University of Texas at El Paso, [email protected] Follow this and additional works at: https://digitalcommons.utep.edu/open_etd Part of the Communication Commons Recommended Citation Fiest, Jacqueline Ann, "Third Parties in the U.S. Political System: What External and Internal Issues Shape Public Perception of Libertarian Party/Politicians?" (2019). Open Access Theses & Dissertations. 1985. https://digitalcommons.utep.edu/open_etd/1985 This is brought to you for free and open access by DigitalCommons@UTEP. It has been accepted for inclusion in Open Access Theses & Dissertations by an authorized administrator of DigitalCommons@UTEP. For more information, please contact [email protected]. THIRD PARTIES IN THE U.S. POLITICAL SYSTEM WHAT EXTERNAL AND INTERNAL ISSUES SHAPE PUBLIC PRECEPTION OF LIBERTARIAN PARTY/POLITICIANS? JACQUELINE ANN FIEST Master’s Program in Communication APPROVED: Eduardo Barrera, Ph.D., Chair Sarah De Los Santos Upton, Ph.D. Pratyusha Basu, Ph.D. Stephen Crites, Ph.D. Dean of the Graduate School Copyright © by Jacqueline Ann Fiest 2019 Dedication This paper is dedicated to my dear friend Charlotte Wiedel. This would not have been possible without you. Thank you. THIRD PARTIES IN THE U.S. POLITICAL SYSTEM WHAT EXTERNAL AND INTERNAL ISSUES SHAPE PUBLIC PRECEPTION OF LIBERTARIAN PARTY/POLITICIANS? by JACQUELINE ANN FIEST, BA THESIS Presented to the Faculty of the Graduate School of The University of Texas at El Paso in Partial Fulfillment of the Requirements for the Degree of MASTER OF ARTS DEPARTMENT OF COMMUNICATION THE UNIVERSITY OF TEXAS AT EL PASO May 2019 Table of Contents Table of Contents ...................................................................................................................... -

Between the Lines: Newsgroups As an Information Source for Social Historians
In: Zimmermann, Harald H.; Schramm, Volker (Hg.): Knowledge Management und Kommunikationssysteme, Workflow Management, Multimedia, Knowledge Transfer. Proceedings des 6. Internationalen Symposiums für Informationswissenschaft (ISI 1998), Prag, 3. – 7. November 1998. Konstanz: UVK Verlagsgesellschaft mbH, 1998. S. 123 – 136 Between the lines: Newsgroups as an information source for social historians Sylva Simsova Mrs Sylva Simsova DATA HELP, 18 Muswell Avenue, London N10 2EG tel/fax 0181 883 6351, [email protected] Contents 1 Introduction 2 Use of written material as a source of data 3 Mass-Observation methods 4 Oral history methods 5 Analysis of texts by the content analysis method 6 Analysis of texts by the qualitative research method 7 Methods chosen for this research 8 The sample 9 The classification of articles 10 UK material 11 Contributors 12 Contributions 13 Content analysis 14 Conclusion Summary The aim of this pilot study was to show the potential usefulness of Usenet discussions to future social historians and to explore possible methods for analysing the data. A survey of 42 Usenet newsgroups was made in November 1996 to explore the patterns of information formed by the contributors. The 5541 articles written by 2130 persons were analysed to identify UK participants and topics related to the UK; to measure the frequency of contributions and relate it to their authors' interests; to draw a comparison between moderated and non- moderated groups; and to indicate the most commonly discussed topics, using keywords taken from headers. A content analysis was used to check adherence to a point of netiquette and to find out to what extent two selected themes (the forthcoming election and violence in society) occupied the minds of contributors.