Augmenting Vector Design Tools with Lazy Data Binding for Expressive
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
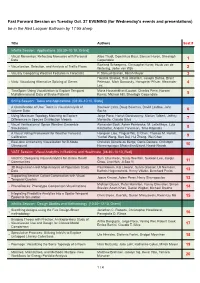
Tuesday's Evening Fast Forward Session
Fast Forward Session on Tuesday Oct. 27 EVENING (for Wednesday's events and presentations) be in the Red Lacquer Ballroom by 17:55 sharp Title Authors Seat # InfoVis Session: Applications [08:30–10:10, Grand] Visual Mementos: Reflecting Memories with Personal Alice Thudt, Dominikus Baur, Samuel Huron, Sheelagh - Data Carpendale 1 Roeland Scheepens, Christophe Hurter, Huub van de - Visualization, Selection, and Analysis of Traffic Flows Wetering, Jarke van Wijk 2 - Visually Comparing Weather Features in Forecasts P. Samuel Quinan, Miriah Meyer 3 Hendrik Strobelt, Bilal Alsallakh, Joseph Botros, Brant - Vials: Visualizing Alternative Splicing of Genes Peterson, Mark Borowsky, Hanspeter Pfister, Alexander 4 Lex TimeSpan: Using Visualization to Explore Temporal Mona Hosseinkhani Loorak, Charles Perin, Noreen - Multidimensional Data of Stroke Patients Kamal, Michael Hill, Sheelagh Carpendale 5 SciVis Session: Tasks and Applications [08:30–10:10, State] A Classification of User Tasks in Visual Analysis of Bireswar Laha, Doug Bowman, David Laidlaw, John - Volume Data Socha 6 Using Maximum Topology Matching to Explore Jorge Poco, Harish Doraiswamy, Marian Talbert, Jeffrey - Differences in Species Distribution Models Morisette, Claudio Silva 7 Visual Verification of Space Weather Ensemble Alexander Bock, Asher Pembroke, M. Leila Mays, Lutz - Simulations Rastaetter, Anders Ynnerman, Timo Ropinski 8 A Visual Voting Framework for Weather Forecast Hongsen Liao, Yingcai Wu, Li Chen, Thomas M. Hamill, - Calibration Yunhai Wang, Kan Dai, Hui Zhang, Wei -

Scientific Visualization
Report from Dagstuhl Seminar 11231 Scientific Visualization Edited by Min Chen1, Hans Hagen2, Charles D. Hansen3, and Arie Kaufman4 1 University of Oxford, GB, [email protected] 2 TU Kaiserslautern, DE, [email protected] 3 University of Utah, US, [email protected] 4 SUNY – Stony Brook, US, [email protected] Abstract This report documents the program and the outcomes of Dagstuhl Seminar 11231 “Scientific Visualization”. Seminar 05.–10. June, 2011 – www.dagstuhl.de/11231 1998 ACM Subject Classification I.3 Computer Graphics, I.4 Image Processing and Computer Vision, J.2 Physical Sciences and Engineering, J.3 Life and Medical Sciences Keywords and phrases Scientific Visualization, Biomedical Visualization, Integrated Multifield Visualization, Uncertainty Visualization, Scalable Visualization Digital Object Identifier 10.4230/DagRep.1.6.1 1 Executive Summary Min Chen Hans Hagen Charles D. Hansen Arie Kaufman License Creative Commons BY-NC-ND 3.0 Unported license © Min Chen, Hans Hagen, Charles D. Hansen, and Arie Kaufman Scientific Visualization (SV) is the transformation of abstract data, derived from observation or simulation, into readily comprehensible images, and has proven to play an indispensable part of the scientific discovery process in many fields of contemporary science. This seminar focused on the general field where applications influence basic research questions on one hand while basic research drives applications on the other. Reflecting the heterogeneous structure of Scientific Visualization and the currently unsolved problems in the field, this seminar dealt with key research problems and their solutions in the following subfields of scientific visualization: Biomedical Visualization: Biomedical visualization and imaging refers to the mechan- isms and techniques utilized to create and display images of the human body, organs or their components for clinical or research purposes. -

Teachingatrisk: Progress & Potholes
Teachingat Risk: Progress & Potholes FINAL REPORT SPRING 2006 The Teaching Commission LOUIS V. GERSTNER, JR. VARTAN GREGORIAN Chairman President The Teaching Commission The Carnegie Corporation of New York Former Chairman and CEO BEVERLY L. HALL IBM Superintendent Atlanta Public Schools ARLENE ACKERMAN Superintendent JAMES B. HUNT, JR. San Francisco Unified School District Former Governor North Carolina ROY E. BARNES Former Governor FRANK KEATING Georgia Former Governor Oklahoma RICHARD I. BEATTIE Chairman RICHARD KRASNO Simpson Thacher & Bartlett LLP Executive Director The William R. Kenan, Jr., Charitable Trust BARBARA BUSH ELLEN CONDLIFFE LAGEMANN KENNETH I. CHENAULT Charles Warren Professor of the History of Chairman and CEO American Education American Express Company Harvard University PHILIP M. CONDIT W. JAMES MCNERNEY, JR. Former Chairman and CEO Chairman, President, and CEO The Boeing Company The Boeing Company JOHN DOERR SCOTT E. PAINTER Partner AP Coordinator and Teacher Kleiner Perkins Caufield & Byers Project GRAD Atlanta and South Atlanta High School MATTHEW GOLDSTEIN Chancellor RICHARD W. RILEY The City University of New York Former U.S. Secretary of Education Former Governor South Carolina THE FINAL REPORT Teaching at Risk: Progress and Potholes THE TEACHING COMMISSION Infographics by Nigel Holmes © 2006 THE TEACHING COMMISSION All Rights Reserved 2 FINAL REPORT Dedicated to R. GAYNOR MCCOWN 1960-2005 AND SANDRA FELDMAN 1939-2005 Teachers, Reformers, and Leaders 3 THE TEACHING COMMISSION 4 About The Teaching Commission stablished and chaired by Louis V.Gerstner, Jr., the former chair- man of IBM, the Teaching Commission has sought to improve Estudent performance and close the nation’s dangerous achievement gap by transforming the way in which America’s public school teachers are prepared, recruited, retained, and rewarded. -

An Investigation Into the Graphic Innovations of Geologist Henry T
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2003 Uncovering strata: an investigation into the graphic innovations of geologist Henry T. De la Beche Renee M. Clary Louisiana State University and Agricultural and Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Education Commons Recommended Citation Clary, Renee M., "Uncovering strata: an investigation into the graphic innovations of geologist Henry T. De la Beche" (2003). LSU Doctoral Dissertations. 127. https://digitalcommons.lsu.edu/gradschool_dissertations/127 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. UNCOVERING STRATA: AN INVESTIGATION INTO THE GRAPHIC INNOVATIONS OF GEOLOGIST HENRY T. DE LA BECHE A Dissertation Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Philosophy in The Department of Curriculum and Instruction by Renee M. Clary B.S., University of Southwestern Louisiana, 1983 M.S., University of Southwestern Louisiana, 1997 M.Ed., University of Southwestern Louisiana, 1998 May 2003 Copyright 2003 Renee M. Clary All rights reserved ii Acknowledgments Photographs of the archived documents held in the National Museum of Wales are provided by the museum, and are reproduced with permission. I send a sincere thank you to Mr. Tom Sharpe, Curator, who offered his time and assistance during the research trip to Wales. -

Meisho Zue and the Mapping of Prosperity in Late Tokugawa Japan
Meisho Zue and the Mapping of Prosperity in Late Tokugawa Japan Robert Goree, Wellesley College Abstract The cartographic history of Japan is remarkable for the sophistication, variety, and ingenuity of its maps. It is also remarkable for its many modes of spatial representation, which might not immediately seem cartographic but could very well be thought of as such. To understand the alterity of these cartographic modes and write Japanese map history for what it is, rather than what it is not, scholars need to be equipped with capacious definitions of maps not limited by modern Eurocentric expectations. This article explores such classificatory flexibility through an analysis of the mapping function of meisho zue, popular multivolume geographic encyclopedias published in Japan during the eighteenth and nineteenth centuries. The article’s central contention is that the illustrations in meisho zue function as pictorial maps, both as individual compositions and in the aggregate. The main example offered is Miyako meisho zue (1780), which is shown to function like a map on account of its instrumental pictorial representation of landscape, virtual wayfinding capacity, spatial layout as a book, and biased selection of sites that contribute to a vision of prosperity. This last claim about site selection exposes the depiction of meisho as a means by which the editors of meisho zue recorded a version of cultural geography that normalized this vision of prosperity. Keywords: Japan, cartography, Akisato Ritō, meisho zue, illustrated book, map, prosperity Entertaining exhibitions arrayed on the dry bed of the Kamo River distracted throngs of people seeking relief from the summer heat in Tokugawa-era Kyoto.1 By the time Osaka-based ukiyo-e artist Takehara Shunchōsai (fl. -

Useful Junk? the Effects of Visual Embellishment on Comprehension and Memorability of Charts Scott Bateman, Regan L
CHI 2010: Graphs April 10–15, 2010, Atlanta, GA, USA Useful Junk? The Effects of Visual Embellishment on Comprehension and Memorability of Charts Scott Bateman, Regan L. Mandryk, Carl Gutwin, Aaron Genest, David McDine, Christopher Brooks Department of Computer Science, University of Saskatchewan, Saskatoon, Saskatchewan, Canada [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] ABSTRACT Despite these minimalist guidelines, many designers Guidelines for designing information charts often state that include a wide variety of visual embellishments in their the presentation should reduce ‘chart junk’ – visual charts, from small decorations to large images and visual embellishments that are not essential to understanding the backgrounds. One well-known proponent of visual data. In contrast, some popular chart designers wrap the embellishment in charts is the graphic artist Nigel Holmes, presented data in detailed and elaborate imagery, raising the whose work regularly incorporates strong visual imagery questions of whether this imagery is really as detrimental to into the fabric of the chart [7] (e.g., Figure 1). understanding as has been proposed, and whether the visual embellishment may have other benefits. To investigate these issues, we conducted an experiment that compared embellished charts with plain ones, and measured both interpretation accuracy and long-term recall. We found that people’s accuracy in describing the embellished charts was no worse than for plain charts, and that their recall after a two-to-three-week gap was significantly better. Although we are cautious about recommending that all charts be produced in this style, our results question some of the premises of the minimalist approach to chart design. -

EMILY JOHNSON/CATALYST SHORE Tue, Jun 17−Sun, Jun 22 Times and Locations Vary
Northrop Presents EMILY JOHNSON/CATALYST SHORE Tue, Jun 17−Sun, Jun 22 Times and Locations Vary Emily Johnson/Catalyst in SHORE. Photo © Cameron Wittig. WELCOME Dear Northrop Dance Lovers, Photo © James Everest We are pleased to share the world premiere of SHORE, the newest work NORTHROP PRESENTS from Emily Johnson/Catalyst, and the culmination of all of the events of our Northrop Grand Reopening. EMILY JOHNSON/CATALYST SHORE is the final work in a trilogy by this amazing Minnesota-based artist, and Northrop has been honored to present both The Thank-you Bar and Niicugni— the first two works in this trilogy—in our previous seasons. These have been SHORE thoughtful and provoking works by an artist who is truly pushing the boundaries Emily Johnson of what dance and performance can mean. Artistic Director Being able to present SHORE as the closing event of our season is a perfect Ain Gordon example of the transformation that Northrop has undergone. SHORE joins Director together Northrop’s resident partners in very meaningful ways: James Everest Emily Johnson is a 2013 McKnight Choreography Artist Fellow (housed within Lead Collaboration, Music and Sound Direction Northrop), as well as a fellow of the University of Minnesota’s Institute for Advanced Study (one of Northrop’s new resident partners). The IAS is also Aretha Aoki, Krista Langberg, Nona Marie Invie, Fletcher Barnhill, Julia Bither Northrop Director Christine Tschida. Collaborative Team Photo by Patrick O’Leary. home to the River Life Program, whose theme of the river and shore is one that Johnson’s work explores. Emily Johnson/Catalyst has also worked with another resident partner, the University Honors Program, on the volunteerism activities as part of SHORE. -

Data Visualization by Nils Gehlenborg
Data Visualization Nils Gehlenborg ([email protected]) Center for Biomedical Informatics / Harvard Medical School Cancer Program / Broad Institute of MIT and Harvard ISMB/ECCB 2011 http://www.biovis.net Flyers at ISCB booth! Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg A good sketch is better than a long speech. Napoleon Bonaparte Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg Minard 1869 Napoleon’s March on Moscow Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 4 I believe when I see it. Unknown Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg Anscombe 1973, The American Statistician Anscombe’s Quartet mean(X) = 9, var(X) = 11, mean(Y) = 7.5, var(Y) = 4.12, cor(X,Y) = 0.816, linear regression line Y = 3 + 0.5*X Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 6 Anscombe 1973, The American Statistician Anscombe’s Quartet Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 7 Exploration: Hypothesis Generation trends gaps outliers clusters - A large data set is given and the goal is to learn something about it. - Visualization is employed to perform pattern detection using the human visual system. - The goal is to generate hypotheses that can be tested with statistical methods or follow-up experiments. Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 8 Visualization Use Cases Presentation Confirmation Exploration Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 9 Definition The use of computer-supported, interactive, visual representations of data to amplify cognition. Stu Card, Jock Mackinlay & Ben Shneiderman Computer-based visualization systems provide visual representations of datasets intended to help people carry out some task more effectively.effectively. -

C 2013 EAFIT University. All Rights Reserved
. c 2013 EAFIT University. All rights reserved. 1 Geometry and Topology Extraction and Visualization from Scalar and Vector Fields John Congote EAFIT UNIVERSITY COLLEGE OF ENGINEERING DOCTORAL PROGRAM IN ENGINEERING MEDELLIN, COLOMBIA 2013 3 DOCTORAL PUBLICATION COPENDIUM ON Geometry and Topology Extraction and Visualization from Scalar and Vector Fields DOCTORAL STUDENT John Congote ADVISOR Prof. Dr. Eng. Oscar Ruiz CO-ADVISOR Dr. Eng. Jorge Posada DISSERTATION Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Engineering in the College of Engineering of the EAFIT University EAFIT UNIVERSITY COLLEGE OF ENGINEERING DOCTORAL PROGRAM IN ENGINEERING MEDELLIN, COLOMBIA JUNE 2013 5 Major Field of Study Computer Graphics Dissertation GEOMETRY AND TOPOLOGY EXTRACTION AND The College of Engineering of VISUALIZATION FROM SCALAR AND VECTOR FIELDS EAFIT University Dissertation Committee Chairperson announces the Prof. Dr. Ing. Oscar Ruiz. Universidad EAFIT, Colombia final examination of Directors of Dissertation Research John Edgar Congote Calle Prof. Dr. Ing. Oscar Ruiz. Universidad EAFIT, Colombia Dr. Ing. Jorge León Posada. VICOMTECH Institute, Spain for the degree of Doctor of Philosophy in Engineering Examining Committee Prof. Dr. Ing. Diego A. Acosta Universidad EAFIT, Colombia Friday, June 07, 2013 Dr. Ing. Aitor Moreno at 10:00 am VICOMTECH Institute, Spain Room 27 – 103 Prof. Dr. Ing. Juan G. Lalinde Medellin Campus Universidad EAFIT, Colombia President of the Board of the Doctoral Program in Engineering Dean Alberto Rodriguez Garcia COLOMBIA This examination is open to the public ABSTRACT This doctoral work contributes in several major aspects: (1) Doctoral Supervisor Prof. Dr. Eng. Oscar E. Ruiz Extraction of geometrical and topological information of 1- and Professor Oscar Ruiz (Tunja, Colombia 1961) obtained 2-manifolds present in static and video imaging. -

Pop-Out, Illusions, Interaction
Pop-Out, Illusions, Interaction DS 4200 FALL 2020 Prof. Cody Dunne NORTHEASTERN UNIVERSITY Slides and inspiration from Michelle Borkin, Krzysztof Gajos, Hanspeter Pfister, Miriah Meyer, Jonathan Schwabish, and David Sprague 1 CHECK-IN 2 PREVIOUSLY, ON DS 4200… 4 Color Vocabulary and Perceptual Ordering Darkness (Lightness) Saturation Hue ? ? Based on Slides by Miriah Meyer, Tamara Munzner 5 Color Deficiencies (Color Blindness) Based on Slides by Hanspeter Pfister, Maureen Stone 6 Check your images/colormaps for issues! http://www.vischeck.com/vischeck/vischeckImage.php https://www.color-blindness.com/coblis-color-blindness-simulator/ 7 Color Brewer http://colorbrewer2.org 8 Color Advice Summary Use a limited hue palette • Control color “pop out” with low-saturation colors • Avoid clutter from too many competing colors Use neutral backgrounds • Control impact of color • Minimize simultaneous contrast Use Color Brewer etc. for picking scales Don’t forget aesthetics! Based on Slides by Hanspeter Pfister, Maureen Stone 9 NOW, ON DS 4200… 10 POP-OUT EFFECTS 15 POP-OUT EFFECTS COLOR Healey, 2012 16 POP-OUT EFFECTS SHAPE Healey, 2012 17 POP-OUT EFFECTS “CONJUNCTION” (HARDER TO FIND RED CIRCLE!) Healey, 2012 18 POP-OUT EFFECTS MOTION Healey, 2012 19 POP-OUT EFFECTS Healey, 2012 20 POP-OUT EFFECTS Healey, 2012 21 Use these “popout” effects to help design effective visualizations! (E.g., draw viewer’s attention to main points, effective redundant encodings, etc.) Ware, VTFD 22 Discriminability and Separability The question of discriminability is: if you encode data using a particular visual channel, are the differences between items perceptible to the human as intended? Munzner, VAD 23 Textures easy hard Ware, VTFD 25 Textures: Interference Ware, VTFD 26 ILLUSIONS AND TRICKS 28 Visual Attention & Change Blindness 30 Visual Attention & Change Blindness Task: Identify the lumps/nodules in the patient’s lungs to look for cancer or abnormal growth. -

Nigel Holmes Characterizes the Opposite End of the Spectrum, Which Supports the Heavy Use of Illustration and Decoration to Embellish Information Design (Figure 1.5)
Contents Introduction A Brief History of Infographics The Purpose of This Book What This Book is Not A Note on Terminology How to Use This Book Chapter 1: Importance and Efficacy: Why Our Brains Love Infographics Varied Perspectives on Information Design: A Brief History Objectives of Visualization Appeal Comprehension Retention Chapter 2: Infographic Formats: Choosing The Right Vehicle For Your Message Static Infographics Motion Graphics Interactive Infographics Chapter 3: The Visual Storytelling Spectrum: An Objective Approach Understanding The Visual Storytelling Spectrum Chapter 4: Editorial Infographics What Are Editorial Infographics? Origins of Editorial Infographics Editorial Infographic Production Chapter 5: Content Distribution: Sharing Your Story Posting On Your Site Distributing Your Content Patience Pays Dividends Chapter 6: Brand-Centric Infographics “About Us” Pages Product Instructions Visual Press Releases Presentation Design Annual Reports Chapter 7: Data Visualization Interfaces A Case For Visualization in User Interfaces Dashboards Visual Data Hubs Chapter 8: What Makes A Good Infographic? Utility Soundness Beauty Chapter 9: Information Design Best Practices Illustration Data Visualization Chapter 10: The Future of Infographics Democratized Access to Creation Tools Socially Generative Visualizations Problem Solving Becoming A Visual Company Further Infographic Goodness Thank You Index Copyright © 2012 by Column Five Media. All rights reserved. Published by John Wiley & Sons, Inc., Hoboken, New Jersey. Published simultaneously -

Eurovis 2019 Eurographics / IEEE VGTC Conference on Visualization 2019
EuroVis 2019 Eurographics / IEEE VGTC Conference on Visualization 2019 Porto, Portugal June 3 – 7, 2019 Organized by EUROGRAPHICS THE EUROPEAN ASSOCIATION FOR COMPUTER GRAPHICS IEEE Visualization and Graphics Technical Committee General Chairs Alfredo Ferreira – INESC-ID, Instituto Superior Técnico, Universidade de Lisboa Joaquim A. Jorge – INESC-ID, Instituto Superior Técnico, Universidade de Lisboa Full Papers Chairs Michael Gleicher – University of Wisconsin Ivan Viola – KAUST Heike Leitte – TU Kaiserslautern STARs Chairs Robert S. Laramee – Swansea University Steffen Oeltze – Dept. of Neurology, University of Magdeburg Michael Sedlmair – Jacobs University Short Papers Chairs Jimmy Johansson – Linköping University Filip Sadlo – Heidelberg University G. Elisabeta Marai – University of Illinois at Chicago Posters Chairs João Madeiras Pereira – Universidade de Lisboa Renata Raidou – TU Wien DOI: 10.1111/cgf.13725 https://www.eg.org https://diglib.eg.org Eurographics Conference on Visualization (EuroVis) 2019 Volume 38 (2019), Number 3 M. Gleicher, H. Leitte, and I. Viola (Guest Editors) Organizers and Sponsors Eurographics Conference on Visualization (EuroVis) 2019 Volume 38 (2019), Number 3 M. Gleicher, H. Leitte, and I. Viola (Guest Editors) Preface EuroVis 2019, the 21th Eurographics / IEEE VGTC Conference on Visualization, was held in Porto, Portugal, on June 3-7, 2019. The proceedings are published as a special issue of the Eurographics Computer Graphics Forum journal. The conference, which started in 1990 as the Eurographics Workshop on Visualization in Scientific Com- puting and was called VisSym after 1999, has been known as EuroVis since 2005. EuroVis attracts contributions that broadly cover the field of visualization. Topics include visualization techniques for spatial data, such as volumet- ric, tensor, and vector field datasets, and for non-spatial data, such as graphs, text, and high-dimensional datasets.